
35 Photos and videos
















vnitkar retweeted

Jun 10
Very smart and worth a read.

7
26
664
372,149

vnitkar retweeted

Jun 6
Google has published a paper that might end the transformer era.
For the last 7 years, every major AI, ChatGPT, Claude, Gemini, has been built on the exact same architecture: The Transformer.
But Transformers have a fatal flaw.
To remember context, they have to process every single word against every other word. It’s called quadratic complexity. As your prompt gets longer, the compute cost explodes.
The alternative is the old-school RNN (Recurrent Neural Network). RNNs are incredibly cheap and fast, but they have a fixed memory size. If you give them a long document, they get amnesia.
Until today.
Google researchers published Memory Caching: RNNs with Growing Memory.
And it fixes the biggest bottleneck in AI.
Instead of an RNN having a fixed, rigid memory that constantly overwrites itself, Google gave it a "save" button.
The technique allows the RNN to cache checkpoints of its hidden states as it reads.
The memory capacity of the RNN can now dynamically grow as the sequence gets longer.
They built four different variants, including sparse selective mechanisms where the AI actively chooses exactly which checkpoints matter most.
The results rewrite the rules of efficiency.
On long-context understanding and recall-intensive tasks, these new Memory-Cached RNNs closed the gap with Transformers.
They achieved competitive accuracy without the explosive, quadratic compute cost. It perfectly bridges the gap between the cheap efficiency of an RNN and the massive capability of a Transformer.
We have spent billions scaling Transformers because we thought they were the only way an AI could remember a long conversation.
But Google just proved we don't need to process the whole history every single time.
We just needed a smarter cache.

245
924
5,641
548,687
vnitkar retweeted

Jun 2
First Podcast Appearance in 5 years
Building a Robotics focused investment firm has been one of the most fascinating experiences of my life
Robots will be as ubiquitous as smart phones within a decade. Everyone should be paying attention and the @RoboStrategy team will be sharing much more about the most exciting developments in the industry

Not enough people are talking about physical AI and robotics.
I sat down with @rewkang, one of the best investors of the last decade, to discuss his massive bet on humanoids and robotics.
He breaks down the industry, the addressable market, multiple leading companies, and why he launched a publicly-traded fund ($BOT) focused on investing in the top private robotics companies.
YouTube: youtu.be/Q_UWD5aoJkc?si=_E7l…
Apple: podcasts.apple.com/us/podcas…
Spotify: open.spotify.com/episode/4L6…
TIMESTAMPS:
0:00 - Intro
1:28 - Why Andrew shifted from crypto to humanoid robots
3:58 - How big is the total addressable market?
8:08 - Building conviction — the $19M bet on Figure AI
16:06 - US vs. China — who wins the robot race?
28:08 - General purpose vs. specialized robots
31:05 - Where does training data come from?
40:24 - Humanoid robots in your everyday life
43:27 - Can Tesla & Elon win the humanoid race?
46:19 - Job displacement & UBI
51:15 - RoboStrategy — the publicly traded venture fund
1:11:17 - What is exciting about Apptronik?
1:13:24 - Addressing the critics
71
79
1,070
437,250

vnitkar retweeted

May 30
Karpathy found a way to reduce token consumption by 90%
The problem is that the LLM re-reads the same files over and over again, loses context between documents, and provides less accurate answers as a result
The solution is called Wiki Layer the LLM cleans, structures, and links all your data once, after which it never works with raw files again
Three folders `raw/` for originals, `wiki/` for a clean knowledge base in Markdown, and files with rules for the agent
Result up to 90% token savings on repeat queries, automatic links between documents, and a visual knowledge graph in Obsidian
Everything stays on your local machine nothing goes to the cloud

Community note
Karpathy described using LLMs to compile raw data into a markdown wiki for efficient querying but did not claim 90% token savings or call the method "Wiki Layer." x.com/karpathy/statu…
155
420
4,233
1,070,890


vnitkar retweeted

May 22
$NVDA $MU $SNDK $LITE EXECUTIVE SUMMARY
The podcast is a 29:36 Dwarkesh Patel conversation recorded at a Jane Street Texas data center with Ron Minsky, who co-leads Jane Street’s technology group, and Dan Pontecorvo, who runs Jane Street’s physical engineering team. The discussion is unusually informative because it connects 3 layers that are normally analyzed separately: trading-time-scale architecture, AI model development, and physical data-center execution. The core message is that Jane Street’s current compute strategy is not an undifferentiated attempt to copy frontier AI labs. It is a vertically integrated alpha-production system in which FPGAs, CPUs, GPUs, storage, networking, data-center power, cooling, and human supervision are matched to distinct trading horizons, from sub-100 ns packet-level reactions to day-scale and longer research workflows. Apple’s podcast listing separately describes the episode as a data-center deep dive with Minsky and Pontecorvo, including physical inspection of racks and infrastructure, which is consistent with the transcript’s unusually operational level of detail.
The most important investment conclusion is that Jane Street is validating AI infrastructure demand from a high-ROIC, non-consumer, non-hyperscaler vertical where marginal compute can be converted into measurable economic output through better pricing, faster research iteration, more frequent retraining, and broader model experimentation. This matters for the AI infrastructure stack because it expands the demand narrative beyond chatbots, enterprise copilots, and frontier-lab pretraining. CoreWeave formally announced that Jane Street committed approximately $6 billion to use CoreWeave’s AI cloud platform and made a $1 billion equity investment in CoreWeave Class A common stock at $109.00 per share; the commitment includes access to next-generation compute across multiple facilities, including NVIDIA Vera Rubin technology.
The discussion also reframes Jane Street as a frontier-scale AI infrastructure buyer with proprietary financial-market data, but not as a frontier LLM lab. The transcript indicates that Jane Street’s data is larger, noisier, and less information-dense byte-for-byte than typical language-model corpora; model architectures are more heterogeneous; inference has tighter latency constraints; and training demand is driven by many specialized experiments rather than by a single monolithic general-purpose foundation model. This distinction is highly material. The positive read-through to GPUs, liquid cooling, AI cloud, and data-center power is real, but the workload mix is more data-loading-intensive, storage-intensive, latency-sensitive, and architecture-specific than the standard hyperscaler LLM narrative.
Jane Street’s disclosure that it is currently operating in the 10,000s of GPUs and expects to move into the 100,000s of GPUs in the relatively near term should be treated as strategically significant, even though the exact timing, SKU mix, utilization, and economic return are not public. At the same time, the firm’s public financial scale provides context for why this level of investment is plausible. Reuters reported that Jane Street generated $39.6 billion of net trading revenue in 2025, surpassing major high-speed trading rivals and several investment banks, and reported 3,500 employees, more than 200 trading venues, and activity across ETFs, equities, bonds, options, commodities, and currencies.
The most differentiated part of the conversation is the description of a compute “efficient frontier” across trading horizons. At 1 extreme, sub-100 ns strategies cannot use CPUs or GPUs and must run on FPGAs or similarly specialized hardware directly attached to the network. At the other extreme, slower fair-value modeling, daily decisioning, retraining, simulation, bulk inference, and research workflows can use GPUs or cloud-scale clusters. The economic architecture is therefore not “latency versus AI,” but “latency plus AI,” where different layers of the system capture different alpha opportunities and pass information across time scales.
CORE THESIS
Jane Street’s AI compute buildout should be viewed as a capital-intensive reinforcement of an already scaled trading franchise, not as a speculative technology adjacency. The firm’s stated objective is to improve the prediction of fair value and related trading quantities across many asset classes and time horizons. In electronic market-making, small improvements in fair-value estimation, adverse-selection modeling, inventory control, and execution prioritization can compound across enormous volumes. In less electronic markets, better models can improve human-assisted pricing, risk warehousing, and capital allocation. This makes the compute spend structurally closer to a trading-seat productivity investment than to a generic corporate AI productivity project.
The discussion supports the view that AI is becoming a core input into market-making industrial organization. Historically, the public narrative around high-frequency trading focused on colocation, fiber length, FPGAs, and nanosecond latency. The podcast shows that this view is now incomplete. The fastest layer remains dominated by physics and hardware specialization, but the economic system above it increasingly depends on large-scale model training, data storage, scheduling, data movement, model retraining, and human-machine interfaces. The moat is therefore moving from a single-dimensional speed race toward a multi-dimensional optimization problem spanning model quality, data throughput, latency, power procurement, physical engineering, and organizational learning.
This shift is likely to widen the gap between top-tier trading firms and subscale competitors. A firm that can invest $6 billion in cloud capacity, own or influence physical data-center design, hire expert ML researchers, design ultra-low-latency hardware, maintain proprietary data stores, and deploy models across global trading venues has a fundamentally different cost structure and learning loop than a smaller firm using commodity cloud and off-the-shelf models. The effect resembles hyperscaler economics, but with alpha rather than tokens as the monetization unit.
TRADING HORIZONS AND COMPUTE ARCHITECTURE
The transcript’s central technical disclosure is that Jane Street does not operate at a single time horizon. The firm explicitly describes a continuum from under 100 ns to microseconds, milliseconds, hours, and days. This is important because it resolves the apparent contradiction between ultra-low-latency trading and GPU-heavy AI. GPUs are not being used to make sub-100 ns decisions in the path of the fastest trades. At those latencies, the decision logic must be extremely simple, the hardware must be specialized, and even CPU execution is too slow. The transcript describes FPGA-level behavior in which a packet can begin leaving before the incoming packet has been fully consumed, emphasizing that this regime is governed by signal propagation, deterministic hardware pipelines, and minimal computation.
The strategic significance is that Jane Street appears to run an ensemble architecture across horizons. Very simple decisions can be made extremely quickly, while more computationally expensive decisions can operate on slower cycles. A portfolio of signals can be arranged so that each signal is placed at the fastest economically relevant layer that can support its complexity. This is the correct architecture for financial markets because the value of speed is not uniform. Some arbitrage or market-making decisions decay in nanoseconds or microseconds. Other decisions, including risk, fair value, inventory, portfolio construction, cross-asset relationships, and structural dislocations, can retain value for minutes, hours, or days.
This architecture weakens the simplistic view that “faster always wins.” In practice, faster decisions are often less informed, while more informed decisions require more computation and more data movement. The economic problem is to determine where on the speed-intelligence frontier each decision belongs. Jane Street’s competitive advantage is likely concentrated in finding this frontier, not merely in having faster hardware or larger models. The firm’s own framing makes clear that “smartness” and “turnaround time” are substitutes at the point of execution, but complements at the portfolio level.
FAIR VALUE AS THE CORE PREDICTION TARGET
The most revealing model-target discussion centers on fair value. Minsky describes predicting what an instrument is worth as a long-standing and composable target, including during earlier eras when models were built with linear regression. This is a critical point because it places modern AI inside a 25-year continuity of quantitative trading rather than as a discontinuous technology reset. The target has not changed as much as the scale, data, methods, and infrastructure have changed.
Fair-value prediction is particularly powerful because it can feed many downstream trading systems. A better estimate of fair value improves quoting, hedging, routing, inventory sizing, adverse-selection detection, risk transfer pricing, and willingness to provide liquidity during stressed markets. In a market-making context, fair value is not a static security price. It is a conditional estimate incorporating order-book state, correlated instruments, macro information, flows, volatility, liquidity, event risk, inventory, and market microstructure. The economic value of better fair-value prediction is therefore broad and reusable.
The transcript also implies that Jane Street’s models are likely not only predicting the next order-book event. The fair-value target can be used across longer and shorter horizons. This matters for GPU demand because the most valuable compute may sit in model families that improve cross-sectional, cross-asset, and temporal valuation rather than in pure microsecond prediction. In other words, the GPU estate may be used less for “next tick” prediction and more for building a richer state representation of markets that can be consumed by many execution and risk systems.
WHY FINANCIAL AI DIFFERS FROM FRONTIER LLM TRAINING
The transcript gives a clear explanation of why Jane Street’s scaling laws differ from frontier AI labs. Foundation labs often benefit from training a very large, general-purpose model that can handle many tasks. Jane Street instead emphasizes many specialized architectures because financial data sources, data rates, latency requirements, and inference constraints vary substantially across applications. The relevant model design is therefore dictated by market data structure, causal ordering, bytes-to-flop ratio, latency, and deployment environment rather than only by scale.
The most important technical distinction is that financial data is extremely noisy. The transcript states that Jane Street has much more data, but that the data is less informative byte-for-byte. This has several implications. First, the value of data loading, storage, filtering, and sampling is unusually high. Second, model quality may improve through massive experimentation rather than a single scaling run. Third, the marginal value of compute may remain high if it enables faster iteration over model architectures and data transformations. Fourth, overfitting risk and regime-shift risk are structurally more important than in language modeling because financial targets are non-stationary, adversarial, and reflexive.
This also means that conventional AI scaling-law analysis may understate or mischaracterize the compute needs of quant finance. The relevant scaling law may not be only parameter count, training tokens, or inference tokens. It may be researcher iteration velocity, number of candidate models explored, retraining frequency, data-source integration, simulation coverage, and latency-constrained deployment success. Compute is valuable because it expands the feasible research frontier, not only because it trains larger models.
INFERENCE: LOWER BATCHING, HIGHER SEQUENTIAL DATA RATE, TIGHTER LATENCY
The transcript’s inference discussion is highly differentiated. Minsky states that latency matters more than in a typical LLM company, batching remains relevant but constrained, and the sequential data rate within 1 causal domain can be far higher than the per-user sequential data rate in consumer LLM inference. This is a subtle but important point. A chatbot company may have enormous aggregate traffic, but each user’s interaction stream is relatively slow. A market-data feed can deliver extremely high-rate sequential updates that must be consumed in order, interpreted causally, and reflected in live trading decisions.
The implication is that financial inference may be less able to exploit large-batch economics and more dependent on low-latency, high-throughput streaming architectures. Model serving for Jane Street likely requires a mix of precomputation, feature stores, event-driven inference, symbol partitioning, model sharding, and specialized deployment near venues or in low-latency data centers. This is structurally different from high-throughput token serving where batching, KV-cache reuse, and request aggregation are central efficiency levers.
This distinction has hardware implications. GPUs may still be essential, but utilization optimization is harder when latency budgets are tight and when input streams are causally ordered. FPGAs and ASICs remain relevant for the fastest paths. CPUs remain relevant for orchestration and lower-intensity logic. Networking, memory bandwidth, storage, and software scheduling may be as important as raw accelerator FLOPS. NVIDIA’s GB200 NVL72 platform is explicitly designed around liquid cooling, dense rack-scale compute, high-bandwidth GPU communication, and large NVLink domains, which are aligned with the direction of travel in these workloads, but not sufficient on their own to solve the full financial-inference problem.
May 21

Had a chance to sit down and chat with Dwarkesh and Dan Pontecorvo after our tour of the DC.
One weird thing is that our team managed to put together a surprisingly credible podcast studio in the data center!
youtu.be/xKZ_8ULR91Y?si=WpWp…
3
15
94
35,836


vnitkar retweeted

May 21
The market is not ready for what is about to happen with storage thanks to agentic. I explain why, and share our beneficiary map.
The uncomfortable version of this thesis is that if agentic AI works, the enterprise storage stack is underbuilt.
@DiligenceStack
thediligencestack.com/p/the-…
7
46
424
248,367
vnitkar retweeted

May 20
Always enjoy my conversations with @patrick_oshag
Points if you can guess whose office this was filmed in.
Also looks like I might need to up my dose of Tirzepatide. 😂
32
40
577
120,379
vnitkar retweeted

May 19
In this AI economics part 4 article, I broke down why the labs are fighting hard to win over platforms and intermediaries because distribution wins over model quality in certain market segments.

4
27
8,653
vnitkar retweeted

May 19
233
368
2,934
1,052,215
vnitkar retweeted

May 8
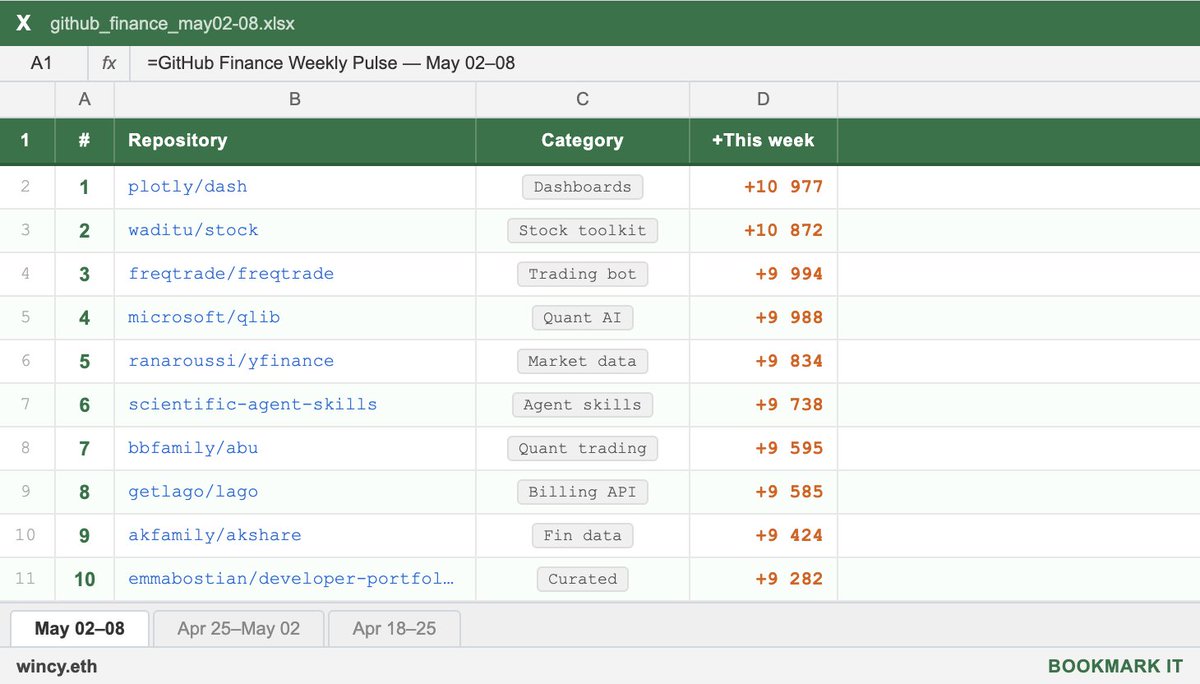
the fastest growing GitHub repos in finance this week:
1. dash ( 10,977 ★)
data apps and dashboards for Python. no JavaScript required. the go-to framework for building interactive analytics UIs. used everywhere from internal tools to public-facing finance dashboards.
2. stock ( 10,872 ★)
Chinese open-source stock toolkit. fetches market data, calculates indicators, chip distribution, pattern recognition, strategy backtesting, and automated trading. supports both desktop and mobile.
3. freqtrade ( 9,994 ★)
free open-source crypto trading bot. supports Binance, Bybit, and 20 exchanges. strategy backtesting, hyperopt parameter tuning, live and dry-run trading. one of the most mature algo trading projects out there.
4. qlib ( 9,988 ★)
Microsoft's AI-oriented quant investment platform. end-to-end: data - alpha - portfolio - execution. the most serious open-source quant infrastructure out there.
5. yfinance ( 9,834 ★)
the de facto Python library for pulling market data from Yahoo Finance. prices, dividends, options chains, financials. used in virtually every Python finance tutorial and prototype.
6. scientific-agent-skills ( 9,738 ★)
ready-to-use agent skills for research, science, engineering, analysis, and finance. plug into any agent framework. covers bioinformatics, cheminformatics, and now Exa search.
7. abu ( 9,595 ★)
Chinese open-source quant trading system for stocks, options, futures, and Bitcoin. built on Python with machine learning support. one of the older and more comprehensive Chinese quant frameworks.
8. lago ( 9,585 ★)
open-source metering and usage-based billing API. consumption tracking, subscription management, and invoicing. built on ClickHouse. the open alternative to Stripe Billing and Chargebee.
9. akshare ( 9,424 ★)
elegant Python financial data library. covers A-shares, bonds, futures, crypto, and macro data. built for researchers and quants working with Chinese and global markets.
10. developer-portfolios ( 9,282 ★)
curated list of developer portfolio sites for inspiration.
May 2

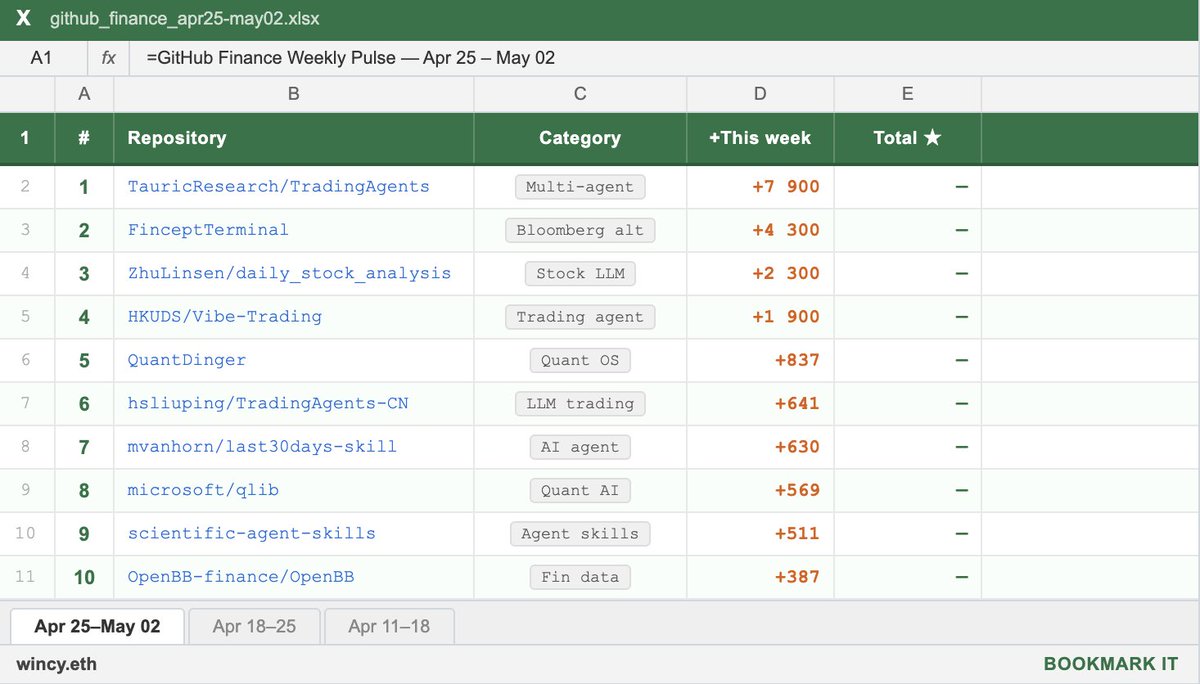
the fastest growing GitHub repos in finance this week:
1. TradingAgents ( 7.9K ★)
multi-agent LLM trading framework from UCLA/MIT. fundamental analyst, sentiment analyst, technicals, risk manager with DeepSeek V4 thinking-mode support.
2. FinceptTerminal ( 4.3K ★)
open-source Bloomberg alternative built in C 20 Qt6. 37 AI agents in Buffett/Munger/Lynch/Graham style. real-time trading with 16 broker integrations. internal MCP AI quant tabs.
3. daily_stock_analysis ( 2.3K ★)
LLM stock analyzer for US, A-share and H-share markets. auto-builds a daily decision dashboard with entry/exit levels. pushes to WeChat/Telegram/Discord/Email via GitHub Actions.
4. Vibe-Trading ( 1.9K ★)
personal trading agent. natural language - strategy - backtest - export to TradingView/MT5. your own AI trading desk in one pip install.
5. QuantDinger ( 837 ★)
self-hosted AI quant OS. research markets, generate Python strategies, backtest ideas, run live trading. crypto, stocks via IBKR, forex via MT5. one Docker Compose, your infra, your data.
6. TradingAgents-CN ( 641 ★)
Chinese fork of TradingAgents. fully localized for A-share markets, Chinese data sources, and domestic LLMs.
7. last30days-skill ( 630 ★)
AI agent skill that researches any topic across Reddit, X, YouTube, HN, Polymarket and the web in the last 30 days. plug it into any agent.
8. qlib ( 569 ★)
Microsoft's AI-oriented quant investment platform. end-to-end: data - alpha - portfolio - execution. the most serious open-source quant infrastructure out there.
9. scientific-agent-skills ( 511 ★)
ready-to-use agent skills for research, science, engineering, analysis, and finance. plug into any agent framework. covers bioinformatics, cheminformatics, and now Hugging Science.
10. OpenBB ( 387 ★)
open-source financial data platform for analysts, quants, and AI agents. stocks, crypto, options, derivatives, fixed income шт one platform. integrates with AI agents via MCP.
24
45
402
216,906
vnitkar retweeted

May 16
18
72
511
248,900
vnitkar retweeted
May 15
Also how I've been allocating $ to the public markets in the past few weeks.
7
12
261
73,984
vnitkar retweeted

May 15
I interviewed @bubbleboi about his ratings of AI supply chain bottlenecks.
We talked about DRAM, advanced packaging, CPO, HBF, PCBs, power delivery, etc.
0:00 HBM, DRAM, the cartel
7:24 Silicon photonics, CPO, Lumentum lasers
11:35 Advanced packaging: TSMC vs Intel
13:49 HBF: Sandisk/SK monopoly window
17:02 Memory accelerators TurboQuant
22:35 PCBs Unitika
27:27 Power: transition from 48V to 800V
31:32 Outsourced assembly test, fiber coupling
36:23 HBM vs DRAM vs NAND in 2-3 years
42:03 Where will hardware founders come from?
44:10 Alt accelerators: Etched, Taalas, MatX
48:43 Emerging tech: CPO bearishness
49:23 Hyperclouds
49:53 HBF timeline CXL
51:48 Voltage cooling wall
56:30 Rapid fire: Intel, Nvidia, TSMC, Alphabet
1:05:25 ASML, Hynix, Lumentum, Wolfspeed
1:13:25 Building conviction in Intel
1:19:37 Pitching Intel to funds
1:22:39 X accounts, analysts why care about any of this
29
95
1,056
245,058
vnitkar retweeted

May 15
Jaimin Rangwalla, CIO of Public Investments at Coatue, sat down with @MollySOShea to walk through unexpected winners of the AI cycle.
The full conversation is live ⬇️
May 15

NEW: Exclusive Interview with Jaimin Rangwalla, Chief Investment Officer of Public Investments at Coatue
In @coatuemgmt's Spring 2026 Investor Update, Jaimin walks through the unexpected winners of the AI cycle: memory, optical, CPUs, & the infrastructure layer quietly outperforming the Mag 7.
We cover:
- Why Coatue is "following the gigawatts"
- Private companies breaking into the global top 25 pre-IPO (OpenAI, Anthropic, SpaceX)
- Cash flow transferring from hyperscalers to AI infrastructure
- The $12T funding engine behind the AI buildout
- Sellers of shortage vs. buyers of shortage
- The Token Economy
- The CPU/GPU flip reshaping compute demand
- Coatue's $6T AI market estimate
- Agents launching agents / "1,000 analysts working 24/7"
Read the full deck & watch the update replay below
𝐓𝐈𝐌𝐄𝐒𝐓𝐀𝐌𝐏𝐒
(00:00) Jaimin Rangwalla, CIO of Public Investments at Coatue
(00:56) Inside Coatue HQ
(02:48) Investor Update Kickoff
(04:36) Mapping the AI Stack
(06:02) Why Supply Stays Tight
(07:03) How Jaimin's Became CIO
(10:43) Private Giants vs Mag 7
(12:40) Market Breadth and Reordering
(15:24) Where AI Revenue Comes From
(17:04) Tokens and Economy
(19:43) Agents Change Everything
(21:58) OpenClaw Explained
(24:49) Memory Demand Explosion
(27:12) Architecture Shifts Ahead
(27:24) Agents Gain Memory
(27:58) CPU Demand Surge
(28:38) CPU GPU Ratio Flip
(30:21) Key Chip Players
(30:45) Intel Comeback Thesis
(31:41) Semis Go Mainstream
(33:24) Nvidia Mania and GTC
(33:59) Tracking Data Center Buildouts
(35:21) Jobs Lost and Created
(37:30) Sellers Versus Buyers
(40:54) Optical Breakouts
(41:27) Bottlenecks Everywhere
(44:48) Sentiment Versus Fundamentals
(47:10) Handling Volatility
(49:17) Finding New Leaders
(51:18) Trillion Dollar IPOs
(52:48) Risks and Disruptions
(55:00) Coatue Growth Story
(55:58) Staying Curious to Win
6
61
20,889
vnitkar retweeted
May 14
35
221
1,461
923,838