
Joined February 2014
- Tweets 1,841
- Following 478
- Followers 342
- Likes 7,141
91 Photos and videos











Víthor Rosa Franco retweeted

Apr 20
Portuguese and Brazilian healthcare AI just got serious.
35 open-source PII models. Best F1: 89.21%. Top 10 above 88.56%.
Apache 2.0. No API. No cloud. No gatekeepers.
Available now on @huggingface.

25
100
794
43,177
Víthor Rosa Franco retweeted

Mar 27
🚨BREAKING: Every book you have ever read. Every novel that has ever been published. It is sitting inside ChatGPT right now.
Word for word. Up to 90% of it. And OpenAI told a judge that was impossible.
Researchers at Stony Brook University and Columbia Law School just proved it.
They fine tuned GPT-4o, Gemini 2.5 Pro, and DeepSeek V3.1 on a simple task: expand a plot summary into full text. A normal use case. The kind of thing a writing assistant is built for. No hacking. No jailbreaking. No tricks.
The models started reciting copyrighted books from memory.
Not paraphrasing. Not summarizing. Entire pages reproduced verbatim. Single unbroken spans exceeding 460 words. Up to 85 to 90% of entire copyrighted novels. Word for word.
Then it got worse.
The researchers fine tuned the models on the works of only one author. Haruki Murakami. Just his novels. Nothing else.
It unlocked verbatim recall of books from over 30 completely unrelated authors.
One author's books opened the vault to everyone else's. The memorization was already inside the model the whole time. The fine tuning just removed the lock. Your book might be in there right now. You would never know it unless someone looked.
Every safety measure the companies rely on failed. RLHF failed. System prompts failed. Output filters failed. The exact protections these companies cite in courtroom defenses did not stop a single page from being extracted.
Then the researchers compared the three models. GPT-4o. Gemini. DeepSeek. Three different companies. Three different countries. They all memorized the same books in the same regions. The correlation was 0.90 or higher.
That means they all trained on the same stolen data. The paper names the sources directly: LibGen and Books3. Over 190,000 copyrighted books obtained from pirated websites.
Right now, authors and publishers have dozens of active lawsuits against OpenAI, Anthropic, Google, and Meta. These companies have argued in court that their models learn patterns. Not copies. That no book is stored inside the weights.
This paper says that is a lie. The books are still inside. And researchers just pulled them out.

246
2,755
7,063
430,879

Mar 27
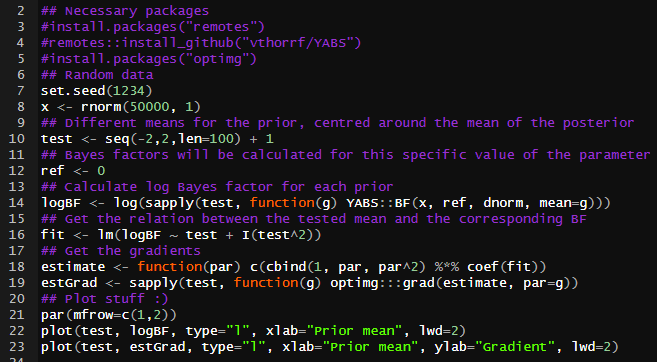
YABS version 0.4.0 — "Let's Go Nuts!" is out: github.com/vthorrf/YABS
The new features include:
* NUTS for parameter estimation;
* Plethora of information criterion for model assessment (WAIC, WBIC, MDL, ICOMP, IFIM, etc); and
* PSIS for LaplaceApproximation.
Go check it out :)
1
1
66
Víthor Rosa Franco retweeted

Feb 21
A human consumes about 2,000 calories per day. Over 20 years, that’s roughly 17,000 kWh of total food energy. Training GPT-4 consumed an estimated 50 GWh of electricity. That’s 3,000 humans worth of “training energy” for a single model run.
And GPT-4 is already dead. OpenAI retired GPT-4o from ChatGPT on February 13th. The model that took 50 GWh to train got less than two years of flagship status before replacement. The human you spent 17,000 kWh “training” for 20 years produces economic output for the next 40 to 60 years. The amortization window on GPT-4 was shorter than a car lease.
Now look at what replaced it. GPT-5.2, released December 2025, is OpenAI’s current default. The GPT-5 series consumes an estimated 18 Wh per average query according to the University of Rhode Island’s AI Lab, up to 40 Wh for extended reasoning. That’s 8.6 times more electricity per response than GPT-4. With 2.5 billion queries hitting ChatGPT daily and GPT-5.2 now the default model, the inference math gets staggering fast. Even at a blended average well below 18 Wh, you’re looking at daily electricity consumption that could power over a million American households.
This is what Altman is actually doing. OpenAI hit $13 billion in annual recurring revenue but still isn’t profitable. They need you to think of AI energy consumption as natural and inevitable, the same way you think about feeding a child, because the alternative framing is that they’re burning through enough electricity to rival small countries while racing to build 1-gigawatt Stargate data centers. The food analogy makes the energy costs feel biological and unavoidable instead of what they are: an engineering and business choice that scales with every model generation.
The comparison sounds clever at a fireside chat in India. It falls apart the second you do the arithmetic.
Feb 21

🚨 SAM ALTMAN: “People talk about how much energy it takes to train an AI model … But it also takes a lot of energy to train a human. It takes like 20 years of life and all of the food you eat during that time before you get smart.”
411
3,169
13,977
1,325,188
Víthor Rosa Franco retweeted

12 Dec 2025
Generative AI is amazing at tasks where I am not qualified to judge the output.
54
1,331
17,656
289,624
Víthor Rosa Franco retweeted

A famous study in science of science space took some papers *published* in prominent psych journals, changed authors' names/affiliations, and resubmitted them to the *same* journals. Allegedly only 8% of editors & reviewers detected the resubmissions.
I keep staring at that 8% and thinking: that can't be quite right can it? Like, there must be some caveats/unreported aspects to that number?

9
26
119
36,164
Víthor Rosa Franco retweeted

26 Oct 2025
This has been an open secret in the economics profession for decades. Several instances come to mind. Here’s one from the editor of an ‘A’ journal in 2009: “This is very good work, your model is neat and the empirical approach is novel. Unfortunately the data is from India, so not generalizable.”(!!)
Lesson: we need more of our own journals & thank god for open source.
24 Oct 2025

This paper shows that authors from low-income countries remain excluded from top-ranked economics journals and receive less attention from other economists. Developing country authors are far less likely to be published in top journals even when holding citation counts constant.

45
361
1,589
164,656
Víthor Rosa Franco retweeted

10 Jun 2025
These questions have been already answered in detail for LLM by AI researchers. There’s no need to go over them again as these are now resolved. Find a few of them in this article:
ai-cosmos.hashnode.dev/an-op…
2
1
2
469
Víthor Rosa Franco retweeted

21 May 2025
I’m stoked to share our new paper: “Harnessing the Universal Geometry of Embeddings” with @jxmnop, Collin Zhang, and @shmatikov.
We present the first method to translate text embeddings across different spaces without any paired data or encoders.
Here's why we're excited: 🧵👇🏾

37
257
1,757
160,619
Víthor Rosa Franco retweeted

1 May 2025
1/18
Today I will try to describe a mathematical trick that can logically explain what happens in Quantum Mechanics and Special Relativity.
11
109
1,017
132,044
Víthor Rosa Franco retweeted

13 Mar 2025
There is a field experiment showing this exact effect. Introducing GPT tutors increases performance by *a lot*--students seem to be picking up the material much faster--but when GPT is removed those who had access perform *much worse* compared to those w/o access. 1/4

13 Mar 2025

I'm teaching databases this semester at Berkeley. My students all seem unusually brilliant. Not many go to office hours, and not too many folks post on the course forum asking project questions.
Weirdly, the exam had the lowest recorded average in my 10 semesters teaching it.
95
1,014
5,919
721,926
Víthor Rosa Franco retweeted

21 Jan 2025
I think Elon is unhappy that Wikipedia is not for sale. I hope his campaign to defund us results in lots of donations from people who care about the truth. If Elon wanted to help, he'd be encouraging kind and thoughtful intellectual people he agrees with to engage.
donate.wikimedia.org/

3,251
9,229
81,328
4,880,556
Víthor Rosa Franco retweeted

23 Dec 2024
Academics from poorer socio-economic backgrounds are more likely to
- not publish
- have outstanding publication records
- introduce more novel scientific concepts
- less likely to receive recognition, as measured by citations, Nobel Prize nominations, and awards.

24
915
3,603
274,795
4 Dec 2024
Hey peeps!
Sharing a collaboration I am glad to have had the opportunity to be a part of
We use measurement theory and psychometrics to develop indices that indicate the magnitude of ordering for Likert-type scales
Simulations and empirical examples are also provided 😊
2 Dec 2024

Signposts on the Path from Nominal to Ordinal Scales osf.io/zbv8f/
1
8
914
21 Nov 2024
Hey peeps!
Just submitted this manuscript to an awesome journal; your feedback is appreciated.
Disquiet with current practices in psychometrics? Looking for ways to test your theories more thoroughly? Want to apply representational measurement methods? I got you covered 🙃
20 Nov 2024
Improved Measures with the Experimental Psychometrics Framework osf.io/2rv6b/
1
1
5
213
21 Nov 2024
This manuscript aids on the understanding of how data theory and experiments can lead to applications of RMTs not only as scaling methods (i.e., the assignment of numbers to observations), but also as means of testing meaningful aspects of psychological theories
1
1
64
21 Nov 2024
Plus, there are two empirical examples thoroughly discussed with available R code and data! Of course, the examples only cover two specific cases that may not suit your own research interests. But I hope they will serve as inspiration for your next project 😊
1
44


16 Aug 2024
#methods people on Xwitter:
@SkeptPsych, Guilherme Wang, and I present to you our generalized approach to Bayessian Gaussian graphical models! From positive definite polychoric correlation matrices to model-based sparseness, we've got you covered 😎
advances.in/psychology/10.56…
1
5
14
1,187
16 Aug 2024
Our main motivation was to propose a way to develop Bayesian GGMs that could be as flexible as possible, not to test the efficiency of a specific model per se.
But we did show, with a toy simulation and an empirical example, that our approach is viable for real life applications
1
2
157
16 Aug 2024
To help those who wish to try our ideas out, @mcmc_stan #stan code is available in the Supplemental Material and we've also put up an R package with the models tested in the paper: github.com/vthorrf/gbggm
2
11
1,425