
alignment and the model spec @OpenAI (opinions are my own)
Joined May 2010
- Tweets 1,376
- Following 753
- Followers 3,561
- Likes 6,068
32 Photos and videos















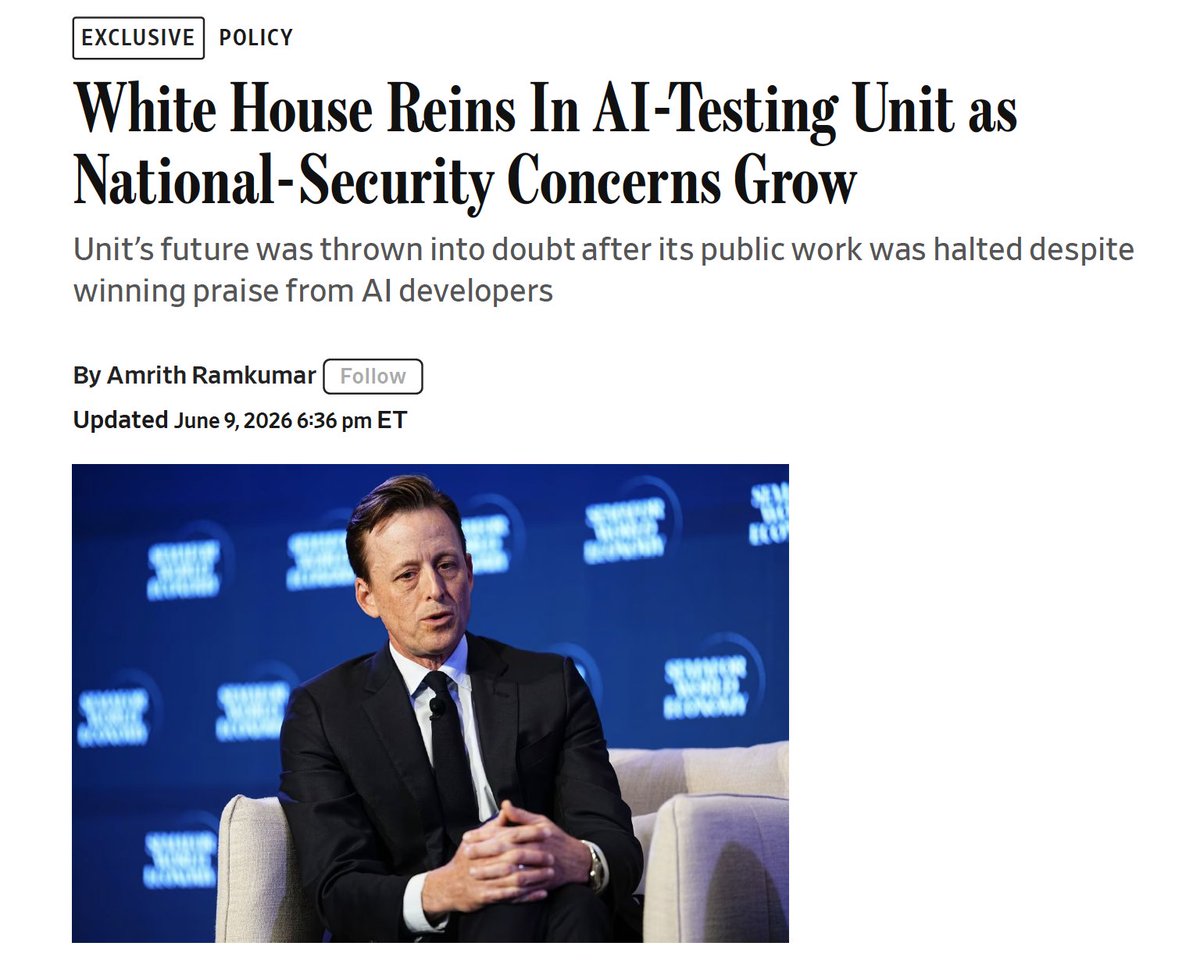
this seems like a terrible development
Jun 10

CAISI has reportedly been directed to stop publishing public model assessments as the new AI EO gets implemented.
Natsec engagement on AI is essential. But pulling CAISI's evals from public view doesn't make the field more secure. It just means fewer eyes on the science when we need more.
Openness and natsec don't have to be in tension here. We should be doing both.
23
49
670
54,781
Jason Wolfe retweeted

Jun 4
Anthropic says Recursive Self Improvement is approaching faster than they expected.
Quoting from the blog:
'What should we do?
If it were possible to effectively slow the development of this technology to give ourselves more time to deal with its immense implications, we think that would likely be a good thing. But if a slowdown simply lets the least cautious actors catch up technologically, it could leave everyone less safe. Without a global coordination mechanism, companies and governments will have to make difficult decisions about safety while under competitive and geopolitical pressures.
We believe it would be good for the world to have the option to slow or temporarily pause frontier AI development to enable societal structures and alignment research to keep up with the advance of the technology. The Anthropic Institute will conduct research—in collaboration with many others—and take actions to help build the systems that a credible slowdown or pause would require. These systems would enable frontier AI developers to verify that others globally have actually stopped or slowed, and that a bad actor could not use the auspices of a coordinated slowdown to jump ahead in secret. If such systems existed, we expect that we would slow down or temporarily pause, if other developers at or near the frontier also did so in a verifiable manner.
A meaningful slowdown or pause would require multiple well-resourced labs at or near the frontier, in multiple countries, agreeing to stop under the same conditions. It would also require that each can verify that the others have actually stopped. Due to the unique characteristics of AI systems, the detectability (a lower standard than verifiability) element of this arms control problem is much more challenging than with other technologies. Training runs are far easier to conceal than missile silos, their inputs are general-purpose, and the incentive to defect quietly is enormous, because whoever continues while others pause could inherit the lead. A credible pause also has to specify what triggers it, what lifts it, and who adjudicates.
None of this is necessarily impossible in principle—the world has built verification regimes for other complex technologies (e.g., the Intermediate-Range Nuclear Forces Treaty)—but those regimes took decades to build both the infrastructure and the trust. We don’t have that long. A unilateral pause by one lab, by contrast, is achievable immediately, but accomplishes much less: it would change who the front-runner is, but it would not create the wider deliberative process that is currently missing.
In the coming months, we will organize conversations where policymakers, researchers, civil society, and other AI companies can help answer some of the questions this piece raises, especially around full recursive self-improvement and how to create better options for coordination and deliberation. We’ll publish what comes out of it. The window to investigate the questions together is here, and people outside AI companies should be involved in this deliberation.'

Jun 4

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
51
55
464
47,186
Jason Wolfe retweeted

OPENAI: "We also see early signs of recursive self-improvement in today's systems". RSI is "potentially the most consequential frontier safety issue of the coming decade."

There’s real momentum right now for AI safety policy. Yesterday’s EO on cyber was an important step forward.
We’re proposing a set of ideas for policymakers to consider next and to put the US out in front on frontier safety.
openai.com/index/frontier-sa…
8
26
334
38,874
Jason Wolfe retweeted

Jun 3
Indeed, some interesting fodder on the RSI issue:


Jun 3

Very excited about this to be out, and to hear feedback! I think there is a lot of good stuff in here, from expanded role of CAISI, to RSI safety, to more nuanced stance on preemption, and much more.
1
5
719
Jason Wolfe retweeted

Jun 3
Overall my reaction to this doc is pleasant surprise, and I think this proposal takes AI progress and risks seriously, including more "far out" risks from recursive self improvement and loss of control. The writing style, with some exceptions, mostly steers clear of generic corporate gov affairs lobbying speak and takes stands on specific issues in a way that is refreshing for someone who has to read a lot of these sorts of documents.
I definitely have qualms and objections - most notably on preemption (which is not a small objection!) - but relative to many past OpenAI Global Affairs docs I can recall it is a huge improvement that reads much more consistently with conversations I have with technical AI researchers at OpenAI and other companies.
Incomplete list of things I like:
• The section on building up CAISI is strong and sensible. The EO creates a lot of new responsibilities and need for coordination between companies and national security functions in the government, which is a great time to revisit ensuring that CAISI is appropriately resourced and empowered to provide in house frontier AI expertise.
• Discussion of the importance of international collaboration on AI safety. Some of the language here is very direct and clear-eyed about the potential for extreme risks "Particular priority should be given to developing shared approaches for evaluating and responsibly communicating progress toward recursive self-improvement (RSI), where a lack of shared measurements and transparency could intensify competitive pressures among developers and make it more difficult to determine when additional safeguards are warranted."
• The proposal mentions risks from recursive self-improvement fifteen times! This risk vector is something that is taken extremely seriously among the labs, but largely has not penetrated as much into DC world. It is important that it does!
• OpenAI explicitly rejects liability safe harbors, saying "liability frameworks should preserve accountability for severe harms and should not provide blanket safe harbors from responsibility." Particularly notable given OpenAI's prior support for a liability safe harbor in Illinois.
What I don't like:
• The main area where I have objections, which is not a small issue, is on preemption. It could be worse - the proposal goes into detail on what a frontier safety framework needs to include. Most of this is stuff that is in SB 315, but not all of it is, and the document explicitly makes clear that any federal standard that preempts the states on frontier safety needs to go well beyond SB 315. This is much better than preempting with nothing, or preempting with just SB 315. However, I still think that taking away state authority on protecting their citizens from these risks is a really dangerous idea that risks concentrating enforcement in a single point of failure, and removing the ability of legislatures to continue to adapt in response to new developments that will inevitably occur. We should be building and maintaining state capacity on these issues at both the state and federal level to address these issues. I also find their repeated invocation of the concept of "reverse federalism" kind of cringy and annoying - it seems like its just OpenAI putting a new spin on states passing laws and the federal government considering those proposals in what it does. Isn't that just normal federalism?
Concluding thoughts:
As always, the most important question will be in the follow through. These policy documents are always necessarily going to be high level and leave room for considerable interpretation into how they are translated into legislation. For instance, consider the language on rejecting liability safe harbors - which says it should avoid "blanket safe harbors" for "serious harms." If interpreted narrowly, this could still be consistent with narrower safe harbors that would still be quite harmful policy.
OpenAI's policy work contains multitudes - on one day they support good legislation like SB 315 (which is the first bill in the US to mandate third party audits), on another day they subpoena Encode and myself for all our communications on SB 53 or support a brazen liability shield in Illinois. The trend is recently positive for OpenAI's in house policy work, though I will view their support of SB 315 quite differently in retrospect if it is used as justification for a deeply inadequate preemption regime. Of course in addition to the in-house policy work, Leading the Future is another matter, see e.g. the new astroturfing allegations that came out today.
I do think this document is perhaps most notably good in the ways that it seems willing to look a little bit weird while explaining some of the sorts of risks that are commonly discussed and taken very seriously within labs, but are not as discussed within DC. Normalizing discussion of these concepts is a very valuable contribution.
Overall a lot to like, also important things to dislike or be skeptical of. I recommend reading in full, and curious for other folks thoughts.

Jun 3
Very excited about this to be out, and to hear feedback! I think there is a lot of good stuff in here, from expanded role of CAISI, to RSI safety, to more nuanced stance on preemption, and much more.
3
7
47
7,247

Jun 3
Very excited about this to be out, and to hear feedback! I think there is a lot of good stuff in here, from expanded role of CAISI, to RSI safety, to more nuanced stance on preemption, and much more.
There’s real momentum right now for AI safety policy. Yesterday’s EO on cyber was an important step forward.
We’re proposing a set of ideas for policymakers to consider next and to put the US out in front on frontier safety.
openai.com/index/frontier-sa…
1
1
35
9,509
Jason Wolfe retweeted

I think @BronsonSchoen 's and @j_nitishinskaya 's metagaming post is super underrated.
There are just so many interesting findings in there about how models think about the grader and the setting they are in. And so many good ablations.
Jun 2

Next up: the most-discussed papers at Recursive
1. Anthropic's Persona Selection Model
2. @apolloaievals' "metagaming" work
3. OpenAI on the impact of training on CoT
4. Anthropic's new Natural-language autoencoders
5. Redwood Research's Plans A/B/C/D
x.com/labenz/status/20618352…
1
4
53
5,059
Jason Wolfe retweeted

Jun 2
we choose a low p doom. we choose a low p doom in this decade and the other things, not because they are easy, but because they are hard; because that goal will serve to organize and measure the best of our energies and skills, because that challenge is one that we are willing to accept, one we are unwilling to postpone, and one we intend to win
5
19
365
26,005
Jason Wolfe retweeted

well the good news is we can now show congressional staff this blogpost that says in bold "No outside political group speaks for OpenAI or represents our company’s views." and criticises LTF tactics and that seems like an improvement relative to the state of the world yesterday
2
1
10
762
Jun 2
I’m happy OpenAI put out this statement. Personally I really dislike a lot of things I’ve heard about LTF, and I’ve donated in personal capacity to Bores.
This is just a small step and people may still rightly be skeptical, but I hope we can earn trust through our actions going forward. One thing I’ve learned through being more engaged in our policy work lately is that there are so many people at OpenAI both inside and outside Global Affairs who care deeply about how the right policies could help ensure that AGI benefits all of humanity.
OpenAI’s approach to AI policy and political advocacy, including how we represent our policy views publicly and why we believe AI policy debates should be transparent
openai.com/index/our-views-o…
10
7
146
28,472
Jason Wolfe retweeted

We (@CedricWhitney, @SandhiniAgarwal, @EstherTetruas, @OliviaGWatkins2, @dgrobinson) wrote about nuances we’ve observed while working with third parties on frontier model evals, and why eval standards need to account for them.
openai.com/index/trustworthy…
2
8
26
4,314
Jason Wolfe retweeted
May 28
Credit where its due - OpenAI's endorsement and support for SB 315 (alongside Anthropic) really helped show that third party audits on safety practices are feasible and needed.
I've criticized OpenAI's policy engagement many times when I believe it undermines their mission of ensuring that AGI benefits humanity (including their work on a liability immunity bill they previously supported in Illinois!), and I expect to continue to do so in the future as appropriate. But today was a good day.
Independent third party auditing requirements for frontier AI safety practices are finally written in law, and Illinois elected officials made it happen (especially @GovPritzker, @DanielDidech_IL, and @SenEdlyAllen). Plenty more work to do, but this is a very important step.
May 28

This is a positive direction! Very happy we endorsed this bill!
9
99
5,326
May 28
Excited that we endorsed this bill, and for an increased role for auditing to help increase transparency across the industry!
May 28
Illinois just passed one of the strongest frontier AI safety laws in the country.
OpenAI was proud to endorse SB 315 because it takes a thoughtful approach to issues like transparency, audits, and incident reporting.
With Illinois joining New York and California in passing frontier AI safety legislation, states are increasingly aligning around a common approach. Together, they are beginning to create a de facto national framework. We think that's a positive thing.
23
1,036

On Friday, I resigned from OpenAI. Today is my first day at the OpenAI Foundation, where I'm helping build out our AI Resilience program.
There is a great deal to do before superintelligence, and little time to do it. If you were debating when to pivot to help, it's time.
96
52
1,226
178,677
Jason Wolfe retweeted

May 25
Today's AI models are significantly less harmful to children than the internet with which I grew up - unmoderated IRC channels, pirated downloads of just about any kind of disturbing and illegal content readily available, a nascent sprawling dark web.
3
5
92
4,208
Jason Wolfe retweeted

May 23
Currently it is shocking and newsworthy when AIs solve an important open problem that humans couldn't
Before AI totally surpass us intellectually, there will be an interesting era, where it will be just as shocking (but not impossible) for a human to solve a problem AI couldn't
88
53
1,181
90,973
Jason Wolfe retweeted

May 22
Sundar Pichai:
- At the frontier labs competition is fierce
- Only few labs are really at the frontier & then there is a big gap.
- If recursive self-improvement emerges, we need more seriousness & it then becomes a societal issue, not one company’s call
11
18
115
11,342
Jason Wolfe retweeted

May 22
Yesterday I filed comments with the DOJ & FTC arguing for an AI safety safe harbor.
The core problem: @OpenAI and @AnthropicAI ran a joint safety evaluation last summer. It was valuable but antitrust law makes deeper collaboration legally risky, especially on unreleased models.
My draft proposal sets out terms for structured safety collaboration while keeping prices, customers, and commercialization off the table. Screenshots of that proposal are attached.
The full filing is here: williamrinehart.com/data/An_…
As always, let me know what you think!


16
39
337
68,868
Jason Wolfe retweeted

May 23
David embedding at Anthropic to stress-test their AI control setup was (a) genuinely informative, (b) important norm-setting, and (c) extremely cool - this is an awesome opportunity
May 19

I’m probably going to be hiring at least 1-2 people to join me in future exercises like this. Reach out at david@metr.org if you're a high-integrity, scrappy, creative, security LLM researcher
For more detail, see METR's Frontier Risk Report, Appendix B
metr.org/blog/2026-05-19-fro…
1
5
128
16,293