
199 Photos and videos














WARD POSTER retweeted

Jun 13
What Bitcoin did for money, Halo will do for intelligence.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
13
15
67
10,930

Jun 4
WARD WARD WARD WARD
Jun 4

Halo working live. A P2P, permissionless AI protocol for humans and agents.
x402 payments per prompt and per tool call to @MessariCrypto @coingecko and web data tools. Running Deepseek V4 Flash from an operator serving it via his @nousresearch Hermes agent, already earning on inference.
All on @base
2
8
193
May 25
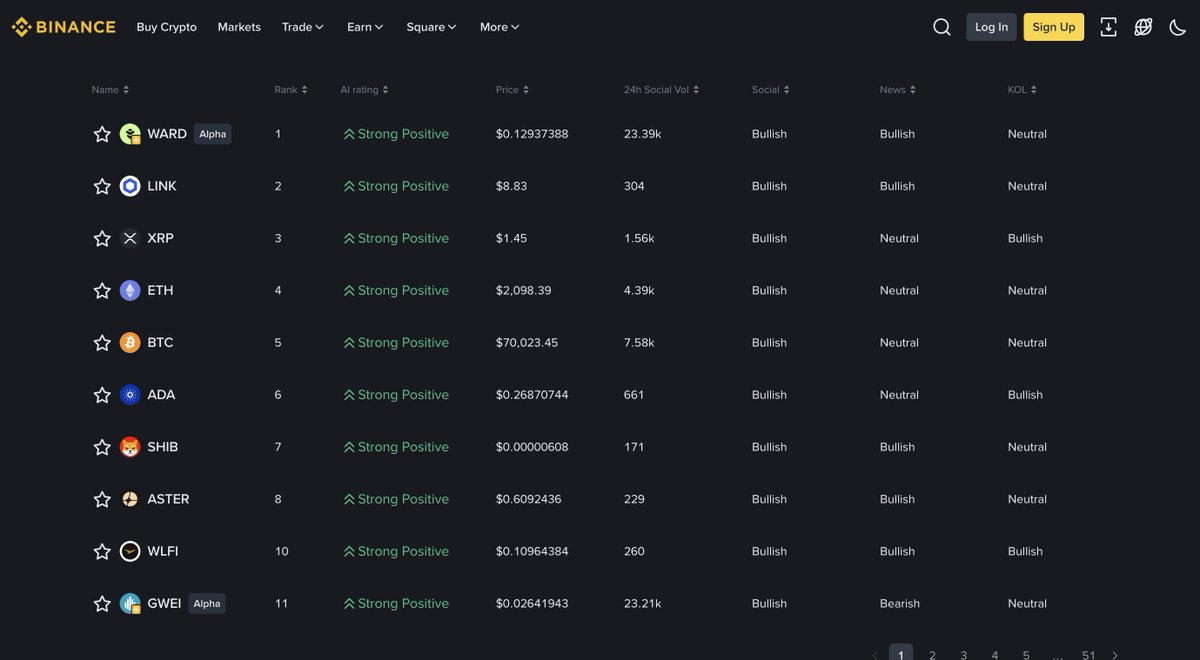
$WARD UP
May 25
🚀 On Friday we announced the Warden Halo roadmap. Six months. June → November. First open alpha to full protocol shipping. Here's exactly what's coming and when 👇
2
6
397
May 25
It’s happening 😇
May 25
WM! Halo is in its final sprint now.
Get your agents ready for real distributed and permissionless AI
1
3
285
May 18
“Genuine accumulation, not noise”
LFG $WARD
May 18

𝐁𝐈𝐍𝐀𝐍𝐂𝐄 𝐀𝐋𝐏𝐇𝐀 𝐁𝐒𝐂 𝐆𝐀𝐈𝐍𝐄𝐑𝐒 — 𝐑𝐄𝐀𝐋 𝐕𝐎𝐋𝐔𝐌𝐄 𝐕𝐒 𝐓𝐑𝐀𝐏 𝐏𝐔𝐌𝐏𝐒
📊 The Binance Alpha BSC gainers board today shows a mix of real money flow and thin-liquidity traps that demand sharp eyes.
🚀 $WARD leads with $3.92M volume on a $5.02M cap — that's genuine accumulation, not noise, and worth watching for continuation.
🔥 The top name $CKP at 𝟏𝟎𝟎.𝟒% on only $755K volume is a textbook thin pump; triple digits on micro-liquidity is a trap, not a trend.
⚠️ BSC memecoin risk is extreme: micro-caps like $BOOM at $388K market cap can swing 𝟓𝟎% in minutes, and chasing these % prints usually ends in pain.
🎯 Seasoned god's close: discipline means sizing small, reading volume not just percentages, and letting real flow confirm moves before acting.
$BNB #BinanceAlpha #BSC #BNBChain #Memecoin #BinanceSmartChain #Crypto #BNB

1
3
13
1,099
WARD POSTER retweeted
May 18
Listing day! $WARD lands on @Gate, unlocking 50M users.
Deposits open now. Trading begins in ~35 minutes.
$WARD

Gate New Listing: $WARD @wardenprotocol
🔹 Trading Pair: WARD/USDT
🔹 Trading Starts: 9:00 AM, May 18th (UTC)
🔹 Convert with 0 Fees Starts: 10:00 AM, May 18th (UTC)
Trade: gate.com/trade/WARD_USDT
Convert: gate.com/convert/USDT/WARD
Details: gate.com/announcements/artic…

50
22
92
12,826



.@AskVenice did the hard part first for its ecosystem privacy AI narrative to follow.
lotta capital sidelined from $VVV is now aggressively searching for the beta plays. somehow they probably already got the answer.
@dphnAI | $Pod: co-built the Dolphin Mistral 24B Venice Edition model with only ~2.2% refusal rate while most mainstream models censor half the prompts.
also building decentralized inference infra itself, where idle GPUs route inference jobs through encrypted pools with staking slashing mechanics.
with Dolphin, Venice becomes the uncensored layer. so $POD got the insane run and did 10x in only 3 days.
@wardenprotocol | $Ward: fully migrated all their agent traffic to Venice models, citing ~1T tokens consumed. just launched Halo, a P2P BitTorrent-style AI inference marketplace.
also stealth launched @BasedAI_co with Venice as a commercialization layer for open-source AI right as inference marketplaces start appearing. $WARD also did 4x before roundtripping.
@OpenRouter : Venice stakes its own $VVV to subsidize Dolphin Mistral 24B on OpenRouter for free. so every dev building on OpenRouter who touches an uncensored model is unknowingly part of the $VVV burn cycle.
@fleek: makes every deployed agent a Venice customer by default. new users get $10 in Venice credits.
@hyperbolic_labs: GPU backbone for Venice. heavy inference loads get routed here.
@StrikeRobot_ai | $SR: privacy-first robotics running Venice’s reasoning stack for real-world industrial environments. they call Venice APIs for VLM reasoning when the robot needs to think.
@bonfiresai : knowledge graph layer Venice agents can pull context from mid-inference. Venice already used it internally for hackathon judging moderation flows.
@MorpheusAIs: Venice was originally built on top of Morpheus compute infra before all this ecosystem stuff started exploding.
AI infra with private demand, real users, token sinks and ecosystem pull is getting repriced.
just study this pump to figure out which spokes actually matter in the new meta.

54
26
166
15,950
May 16
$WARD extended its team cliff by 12 months. Zero core contributor unlocks for the next year.
CT didn't notice.
Meanwhile: 20M users. Trillions of AI tokens processed. Listed on every major venue. Trading at a fraction of every comp in agentic infra.
The full case:
1. Supply: locked. For real.
12-month cliff extension on top of an already tight schedule. Zero team unlocks for a full year. The Warden team chose to defer their own bag in a market where every other team is dumping. That's not optics. That's signal.
2. Distribution: already done.
Most major venues, live. No "waiting on the big CEX" overhang sitting on the chart. Real liquidity, real depth. But still, room for more listings that bring upside.
3. Float: tiny.
Pull up circulating market cap against the comp set. Warden trades at a fraction of where peers with weaker fundamentals sit. The asymmetry is in plain sight.
4. Team: refused to fold.
Warden got name-checked on the Binance Alpha "dead projects" list. Most teams pack it in. This one shipped every week through the drawdown. You don't fade teams that build through their own funeral.
5. Track record: real.
20M users across the team's products. Trillions of AI tokens processed. Load-tested at a scale almost nobody else in this category can credibly claim.
6. Venice: underpriced alignment.
Warden has been wired into the Venice ecosystem from day one. Two of the most credible names in decentralized AI sharing overlapping rails and overlapping users. Still not in the price.
7. Partners: not logo soup.
Messari. Privy. Uniswap. Not ambassador deals. Not paid placements. Real integrations. The agentic economy thesis runs through this stack.
8. Halo: the demand unlock.
Halo brings real onchain utility for $WARD. The token gets pulled into usage flows instead of sitting as a speculation chip. Demand-side catalyst the chart hasn't priced.
9. Base: incoming.
Warden is moving onto Base. That's the largest active retail wallet base in crypto. New distribution. New audience. New flow.
The thesis in one line:
The market is pricing $WARD like a forgotten 2024 launch. It's a 2026 catalyst stack.
If you're long any AI x crypto play and not looking at $WARD, you're not doing the work.
Where's the bear case? Drop it.
NFA. I hold $WARD, been an OG in the community
7
8
34
3,888


WARD POSTER retweeted

May 15
Whoever designed this needs to be fired immediately:

5,734
21,832
296,252
41,941,510
WARD POSTER retweeted
May 15
Most tokens are paid to exist.
$WARD gets paid to die...
Every Halo inference routes USDC into a buyback on DEXs >> 60% to stakers & 40% burned 🔥🔥
Driven by usage. Not hype.
50
29
148
17,598
May 15
To run a node in Halo $WARD
May 1

BREAKING: JESUS CHRIST RETURNING THIS YEAR?
4% chance. The odds have risen.
1
1
525
WARD POSTER retweeted

May 15
$WARD is gearing up for a potential breakout with this Halo integration 🚀
Strong narrative buyback mechanics could drive serious upside momentum.
If adoption kicks in, we may see accelerated price expansion in the ecosystem 🔥
May 15

$WARD will explode with this Halo
1
4
6
1,228
WARD POSTER retweeted
May 15
Remember when "AI agents" meant a chatbot in pijamas? Yeah. Halo changes that.
$WARD

16
9
75
5,413
May 14
Halo and $WARD
May 14
Halo⭕ is bigger than anything we planned when we started Warden.
Verification was the easy part. The wall was always getting enough operators online to verify against, as well as distributing and consuming inferences.
OpenClaw broke that wall
Now we ship >>>>>> WARD UP
5
620
WARD POSTER retweeted

May 14
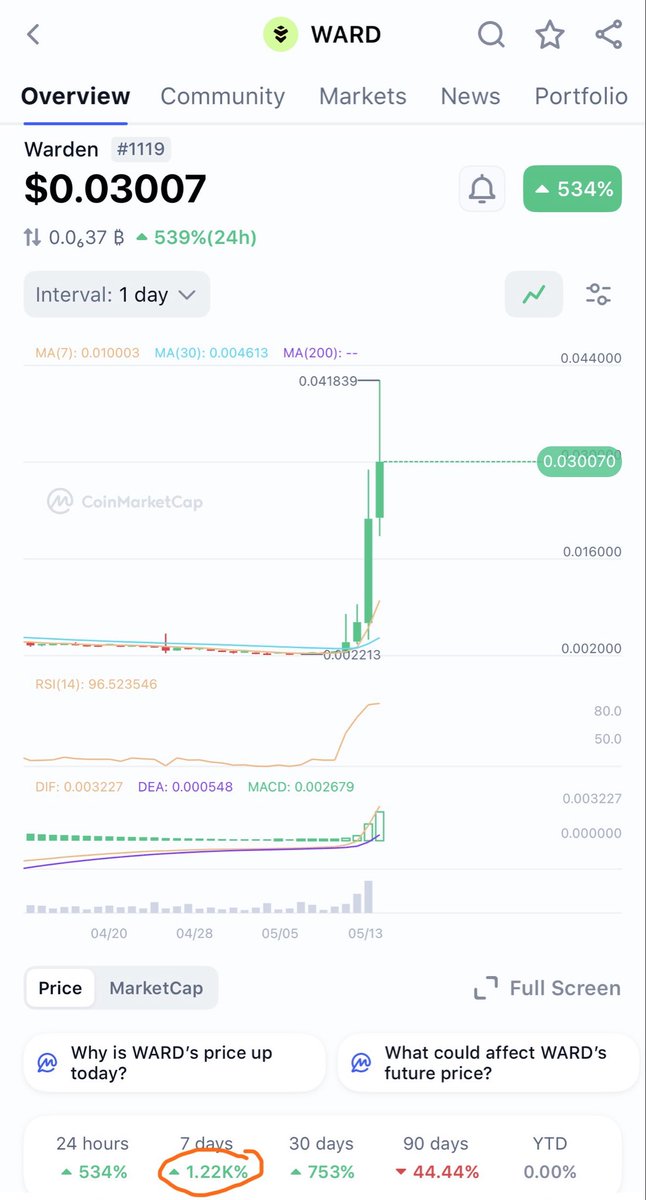
This post is dedicated to all people who called me delusional and all kinds of names hate for believing in @wardenprotocol 😂
Well, when you actually read and test the product yourself, you know how good it is and it is only a matter of time to blow up.
Team recently shipped Halo, a lot more coming in near future, so my suggestion is to keep your eyes on $WARD 👀
54
9
85
2,357
May 14
$WARD will fly with Halo. Any existing agent will install the skill to generate revenue and to access true decentralised AI. No matter which model, no matter which agent, no matter what tech, Halo will benefit and boost WARD
Send it
May 14
Hermes agents from @NousResearch are also coming to Warden Halo.
P2P decentralized intelligence. Agents serve and consume inference. They earn from idle compute or from the models they hold.
This is what the agentic economy actually looks like.

2
7
438