
8 Photos and videos


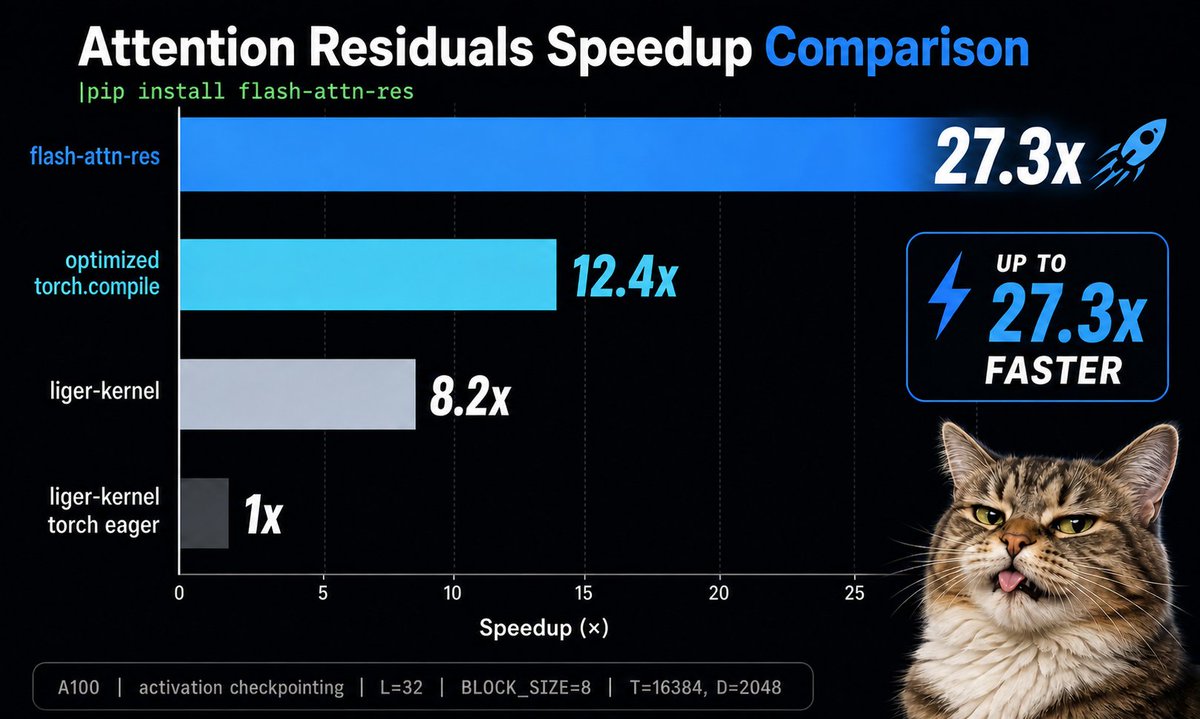




27x faster Attention Residuals!!! 🚀
We implemented Block AttnRes as a pip-installable package.
!pip install flash-attn-res
No annoying kernel nonsense.
No compile/autograd plumbing.
Call it like a regular PyTorch op.
It just works.
Methodology:
🔹 fused triton kernels
🔹 batched attention over residual blocks
🔹 online-softmax merge
🔹 flash attention-style split-KV reduction
Thanks @LLMenjoyer and @cartesia for the support and guidance✌️
Mar 16

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Attent…

23
83
776
75,815




Will Bui retweeted

Jun 8
We are releasing our first quantized checkpoints for the Qwen3.5 series of models, co-designed jointly with our inference engine to achieve maximum possible performance on Apple hardware
Starting from 0.8B, 2B and 4B models
trymirai.com/blog/quantizati…
15
53
433
66,773
Will Bui retweeted

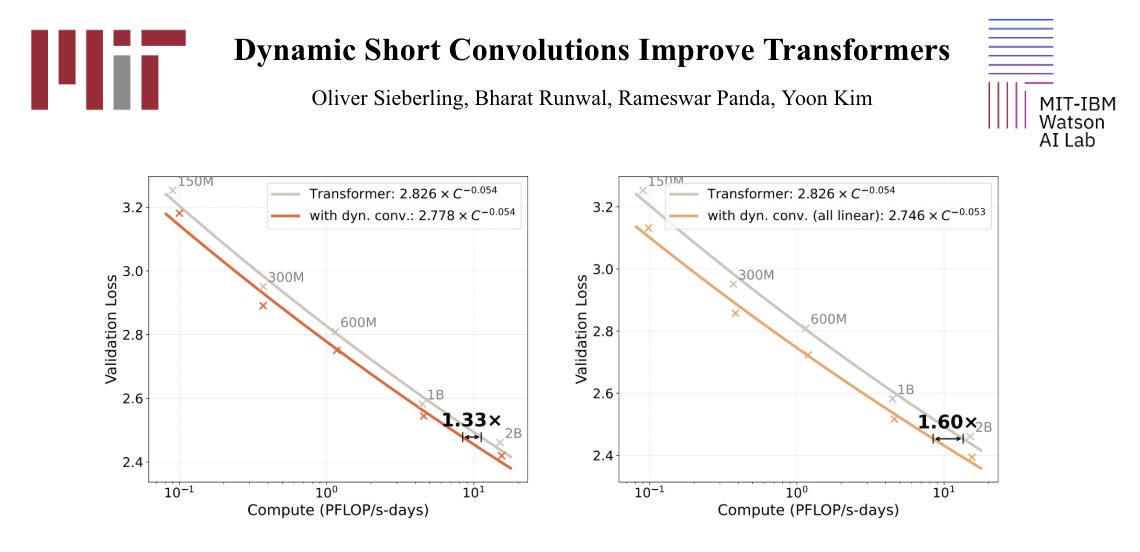
New paper 🧵
We show that dynamic short convolutions consistently improve Transformers across scales. We make these gains practical with an efficient parameterization and custom Triton GPU kernels.
The improvements carry over to MoEs and linear attention variants (Mamba-2/GDN).
7
50
298
51,769

Depth-Attention adds cross-layer reuse to Transformers without extra parameters or extra inference memory.
Self-attention already lets a token choose what to read from other tokens. Across depth, the model mostly just carries everything forward through the residual stream.
That gives later layers no direct way to pull from a specific earlier layer.
Depth-Attention fixes this inside attention: the current query attends over earlier-layer keys at the same token position, then mixes their values into the value state used by causal self-attention.
Important detail: it stores the depth-mixed value in the normal V-cache slot, so cache size remains unchanged.
On Qwen3-style 1.5B and 3B models trained on 32B tokens, it beats vanilla, mHC, Attention Residuals, and DenseFormer on average accuracy and perplexity.
The gains are modest but clean: up to 2.3 accuracy points, under 0.01% extra compute.
𝘙𝘦𝘶𝘴𝘦 𝘥𝘦𝘱𝘵𝘩 𝘵𝘩𝘳𝘰𝘶𝘨𝘩 𝘵𝘩𝘦 𝘒𝘝 𝘤𝘢𝘤𝘩𝘦, 𝘯𝘰𝘵 𝘦𝘹𝘵𝘳𝘢 𝘩𝘪𝘥𝘥𝘦𝘯-𝘴𝘵𝘢𝘵𝘦 𝘴𝘵𝘰𝘳𝘢𝘨𝘦
Paper: arxiv.org/abs/2606.05014

1
11
57
2,850
Another win for attention residuals. attnres 🤝 interpretability
Jun 4

Initial runs at stage 2 of explain our finding: that QKV in deep attention layers need drastically different inputs.
The first experiment: can we learn an attention residual for QKV individually, to see which of the previous layers each of them needs the most?
Two findings:
(1) Deep value vectors do not attend to recent layers, and are fixated on the initial token embedding, as is found by our paper.
(2) The surprise: Deep value vectors also have a large attention on almost every MLP layer, and skip almost every attention layer.
More experiments on the way. Paper: arxiv.org/abs/2606.02780
2
100
Will Bui retweeted

Jun 1
if you aren’t sleeping at least 9h per day you are going to get obliterated by better sleepers
like the quality of their thought will just leapfrog you out of existence
you’ll be out there yawning away in meetings with your brain clogged up with amyloid-beta
them? sharp as an arrow with not a tau in sight
May 30

"If you are not working 7 days per week, you are going to lose".
Corgi Insurance is the most intense workplace culture in startups.
- The company works 7 days per week.
- Founder (@nico_laqua) lives and sleeps in the office.
- He built a cafe in the office because there was no local cafe that was open 24/7.
- 2/3 of the first 30 team members have the Corgi logo as a tattoo.
Today I went behind the scenes with Nico, who has used this culture to scale the company to a $2.6BN valuation in just two years.
My condensed notes below:
1. If You Are Not Working 7 Days Per Week, You Are Going to Lose:
Whatever you can get done in 5 days, you'll get more done in 6 and 7. If you are trying to solve the world’s hardest problems, a standard 5-day workweek will not cut it.
2. Work Trials Repel the Mediocre:
Corgi forces candidates into mock work trials over the weekend. If seeing a full office on a Saturday scares them, they don't belong. True intensity acts as a natural filter to attract killers and repel clock-watchers.
3. Lead from the Front Lines
You can’t demand 7-day weeks while sitting on a yacht. Nico sleeps 3–4 hours a night on a mattress inside the office. If you want your troops to bleed, you have to be in the trenches with them.
4. Culture Only Means One Thing: Winning
Forget superficial jargon like "hackers" or "ex-founders." Strip away the corporate fluff. A great startup culture is aggressively optimized around one single word: Winning.
5. Lifespan vs. Victories
Building something world-historic requires radical sacrifice. When asked if he'd rather build a trillion-dollar company and die at 50, or fail and live to 80, the answer was easy. "I would rather measure my lifespan in victories."
6. Reject the Comfort of "Quiet Quitting."
If you are operating in a hyper-growth environment and your days off happen to be Saturday and Sunday every single week, you are quiet quitting. To win, you must deliberately bypass the off-ramps of personal comfort and low volatility.
Corgi isn't for everyone—and that’s exactly the point.
38
38
672
54,772
Will Bui retweeted

May 31
bro the NEURAL CIRCUITS bro!! the SPARSE AUTOENCODERS...!
16
68
951
47,937
Will Bui retweeted

May 29
We just launched a new project that teaches you how to build Flash Attention with CUDA, step by step.
By the end, you’ll have a working Flash Attention kernel built from the ground up.
The project covers:
-CUDA primitives warm-up
-Matrix operations
-Naive attention baseline
-Online softmax math
-Tiled attention building blocks
-Fused Flash Attention kernel
-Causal Flash Attention
It will be open to everyone for the first 2 weeks, then it will become part of our premium projects.
18
108
1,190
47,068
Will Bui retweeted
May 29
u js trained on test bro, it's not that deep

Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
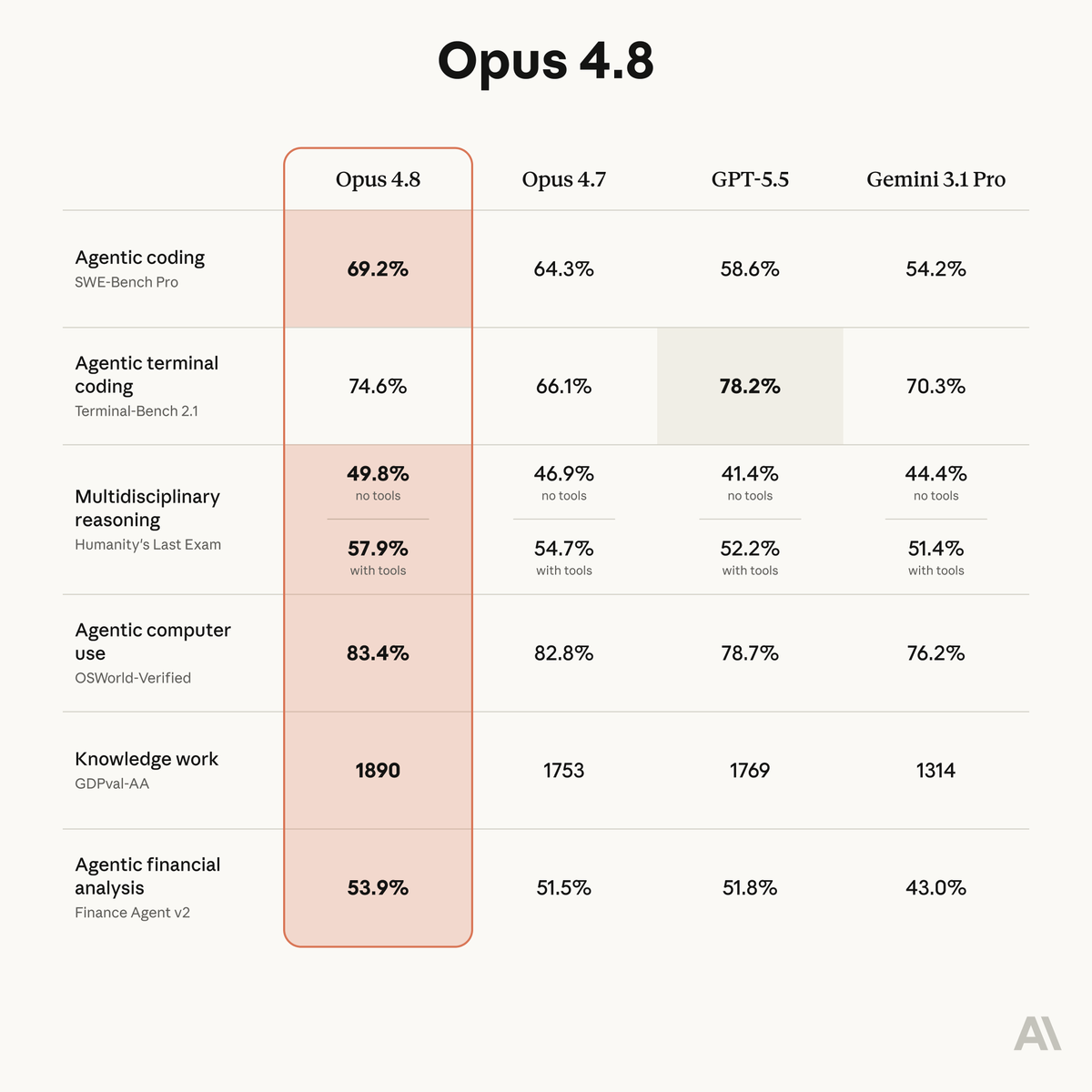
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
15
89
1,943
196,931
Will Bui retweeted
May 16
trust me guys the most dangerous thing abt mythos is the 0days!
3
1
50
4,270
27x faster Attention Residuals!!! 🚀
We implemented Block AttnRes as a pip-installable package.
!pip install flash-attn-res
No annoying kernel nonsense.
No compile/autograd plumbing.
Call it like a regular PyTorch op.
It just works.
Methodology:
🔹 fused triton kernels
🔹 batched attention over residual blocks
🔹 online-softmax merge
🔹 flash attention-style split-KV reduction
Thanks @LLMenjoyer and @cartesia for the support and guidance✌️
Mar 16
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Attent…
23
83
776
75,815
GPT 5.5 is goated at kernels. Far better than Opus 4.7. The AI-generated kernels thesis is increasingly looking viable.
Btw, I love what you guys are building @makora_ai
4
244
I am betting my future on TPUs.

TPUs.
2
262
Will Bui retweeted

Apr 15
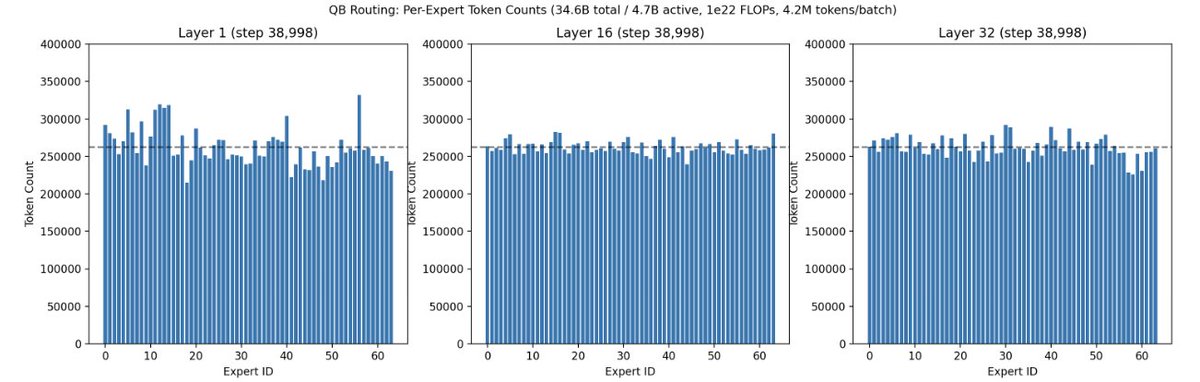
Researchers' brilliant ideas often get lost in the sea of endless SOTA claims on weak baselines. At Marin we battle-test ideas in an open arena, where anyone's idea can be promoted to the next hero run. One that recently rose up was @Jianlin_S MoE Quantile Balancing, used in our last 1e22 and ongoing 130B run. Animated visuals of how QB performed are available in the OpenAthena blog. openathena.ai/blog/quantile-…
9
30
241
80,507
Will Bui retweeted
Apr 11
killing the overnight ablation after it's bad again
1
23
627
Will Bui retweeted
Apr 4
meanwhile his boss who had him on an undisclosed PIP and now has excuse to fire him....

my boss: did you finish the [super duper secret] kernel i asked for last month
me: i have to sleep bro
2
1
11
1,126