
Joined February 2022
- Tweets 37
- Following 106
- Followers 46
- Likes 1,114
8 Photos and videos





Lucia Domenichelli retweeted

3 May 2021
I love all of you very much, so please don't beat me up for this.

9
24
110
Lucia Domenichelli retweeted

May 14
🧶 1/3
We’re excited to share our second paper presented at #LREC2026 in Palma: “Controllable Sentence Simplification in Italian: Fine-Tuning Large Language Models on Automatically Generated Resources” by @mpapucci_, Giulia Venturi and Felice Dell'Orletta

1
3
10
457
Lucia Domenichelli retweeted
May 11
🚀 Excited to share our latest work at READIxTSAR workshop at #LREC2026
"Lexical Conditioning of Model's Distribution through Uncertainty-gated Soft-Mixing of Probabilities" by @mpapucci_ Giulia Venturi and Felice Dell'Orletta.

1
3
13
373
Lucia Domenichelli retweeted
Apr 10
[1/4] How does the order of pretraining data impact Neural Language Models?
We study this in our 🎉new paper🎉:
"On the impact of pretraining data ordering in transformer encoder- and decoder-only language models"
Published in Knowledge-Based Systems
🔗sciencedirect.com/science/ar…

1
2
16
902
Lucia Domenichelli retweeted
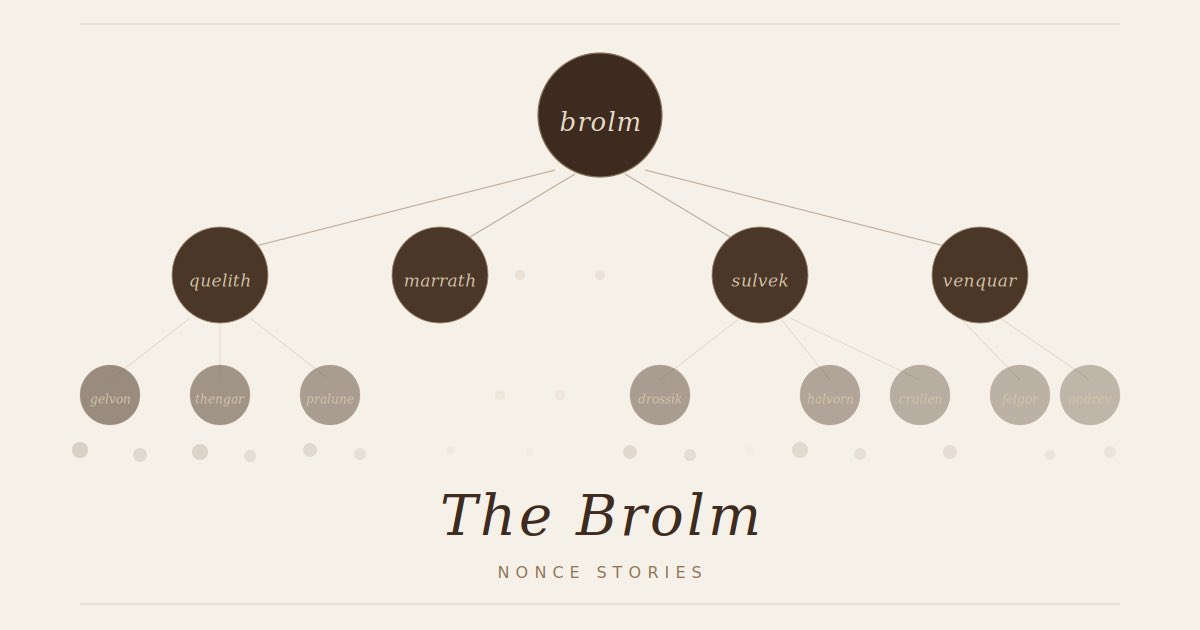
Been playing with Claude lately and decided to start a "vibe" project. It's called The Brolm — a story written entirely in invented words. Click any word to go deeper into sub-stories that gradually reveal meaning. Grows weekly.
🔗 alemiaschi.github.io/nonce-s…
1
1
4
140
Lucia Domenichelli retweeted

Mar 3
Don Knuth! Ok, starting to get surreal
“Shock! Shock! I learned yesterday that an open problem I’d been working on for several weeks had just been solved by Claude Opus 4.6 — Anthropic’s hybrid reasoning model that had been released three weeks earlier! It seems that I’ll have to revise my opinions about “generative AI” one of these days. What a joy it is to learn not only that my conjecture has a nice solution but also to celebrate this dramatic advance in automatic deduction and creative problem solving. I’ll try to tell the story briefly in this note.”
www-cs-faculty.stanford.edu/…
2
75
526
41,545
Lucia Domenichelli retweeted
Feb 19
Big day! Our PhD student @lucadini_ is defining his thesis! 🔥 #NLProc

2
6
303

Today I learnt that in 2009, neuroscientists placed a dead Atlantic salmon into an fMRI scanner, scanned it, and that this has apparently implications for AI interpretability. 🐟
They showed the dead fish pictures of humans in social situations and "asked" the fish to determine the emotions of the people. When they ran their standard statistical software, the results showed "brain activity" in the fish that correlated with the emotions. Obviously, the fish was not thinking; the "activity" was just random noise. The point of the study was to show that if you don't correct for statistical noise and use rigorous controls, your tools will find patterns where none exist.
This paper claims that the same lesson should be applied in interpretability work: many researchers use various tools to explain what is happening inside a neural network (e.g. probes, SAEs etc). But some of these convincing-looking explanations can also be extracted when applied to randomly initialized and untrained AI models (the dead salmon equivalent): saliency maps remain plausible after weight randomization, sparse autoencoders find interpretable components in random transformers etc.
The authors propose that we stop treating interpretability as "storytelling" and start treating it as statistical inference: doing null hypothesis testing, quantifying uncertainty more systematically, interpreting explanations as a simplified surrogate model etc. Although they also acknowledge that finding some signal in random networks doesn't automatically invalidate finding stronger signals in trained ones.
I'm not interpretability researcher myself but would be curious to hear takes! arxiv.org/abs/2512.18792

84
574
4,902
388,842
Lucia Domenichelli retweeted
25 Sep 2025
Last but not least (for today), @lucadini_ presenting “The Role of Eye-Tracking Data in Encoder-Based Models: An In-depth Linguistic Analysis” (with @workerplacemint, Dominique Brunato and Felice Dell’Orletta)! 👁️
Link to the paper: clic2025.unica.it/wp-content…
#NLProc

5
7
358
Lucia Domenichelli retweeted

4 Aug 2025
From August 05 to August 15, l'@IES_Cargese will be hosting "Statisticial Physic and Machine Learning : Moving Forward" organized by Florent Krzakala & Lenka Zdeborova @KrzakalaF @zdeborova
@UnivCorse @Univ_CotedAzur @CNRS_dr12 @EPFL

6
27
1,921
Lucia Domenichelli retweeted
30 Jul 2025
That’s a wrap for @aclmeeting 2025! 🎉 We presented 4 papers, had great discussions, and lots of fun at the poster sessions. Thanks to everyone who stopped by, see you next time!
#ACL2025NLP #NLProc




2
4
13
673
Lucia Domenichelli retweeted

23 Jul 2025
[1/4] 🚀 Next week, @workerplacemint and I will present our paper “From Human Reading to NLM Understanding: Evaluating the Role of Eye-Tracking Data in Encoder-Based Models” at @aclmeeting!
👉 With D. Brunato & F. Dell'Orletta (@ItaliaNLP_Lab)
🔗 aclanthology.org/2025.acl-lo…

1
1
3
147
Lucia Domenichelli retweeted

23 Jul 2025
📣 Next week I’ll be at @aclmeeting with three papers: one at the main conference and two in the Findings!
At the main conference, I’ll present:
“Evaluating Lexical Proficiency in Neural Language Models” (with Ciaccio C. and Dell’Orletta F.)
🔗 aclanthology.org/2025.acl-lo…
🧵(1/5)

1
2
7
265
Lucia Domenichelli retweeted
22 Jul 2025
🎉 Great news! We got 9 papers accepted at CLiC-it 2025! Looking forward to presenting them this year in Cagliari! 🇮🇹
#CLiCit2025 #NLProc @CLiC_it_conf @AILC_NLP

1
4
6
503

15 Jun 2025
#ikeda
xₙ₊₁ = 1 u·(xₙ·cos t – yₙ·sin t)
yₙ₊₁ = u·(xₙ·sin t yₙ·cos t)
t = 0.4 – 6 / (1 xₙ² yₙ²)
2
94