
PhD Student @NYU_Courant, Researcher @AIatMeta; Multimodal Generation | Prev: @MSFTResearch, @AlibabaGroup, @sjtu1896; More at xichenpan.com
Joined August 2022
- Tweets 61
- Following 550
- Followers 716
- Likes 109
18 Photos and videos



Pinned Tweet
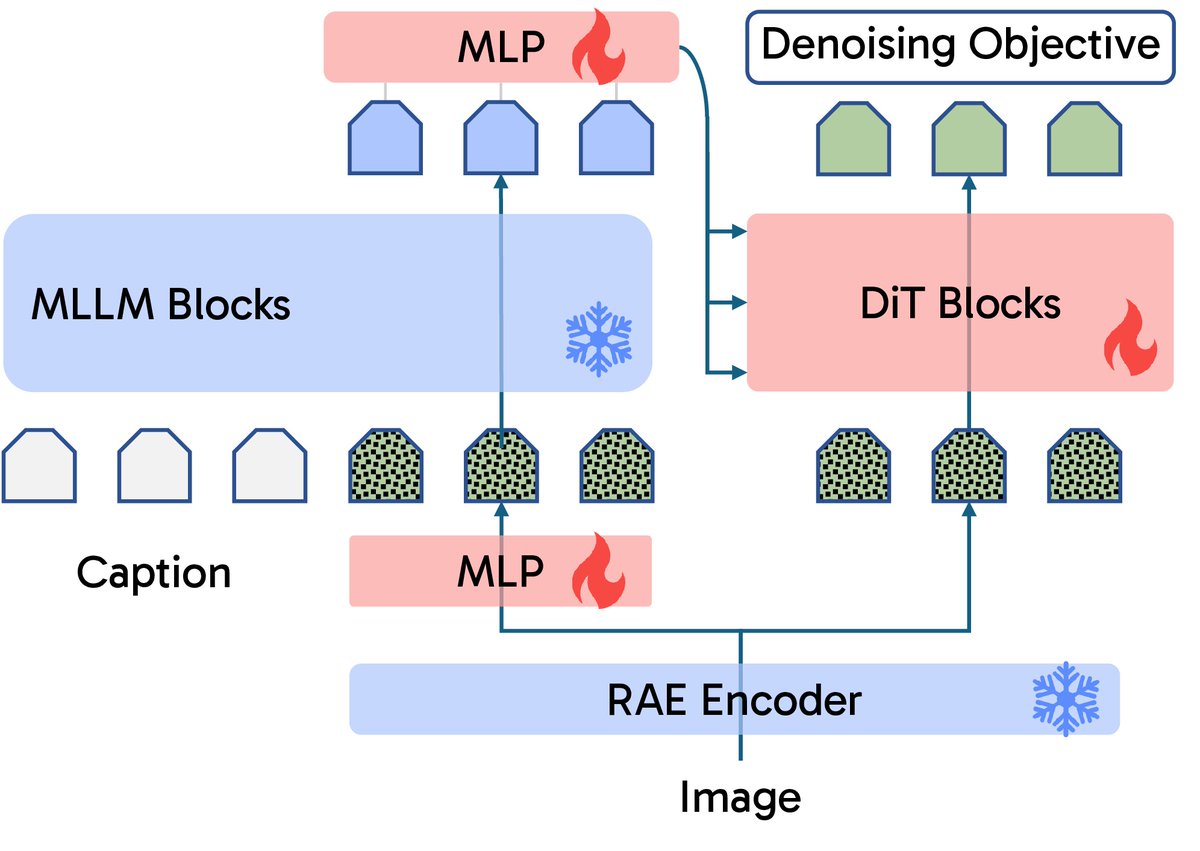
Modern text-to-image models are increasingly powered by large pretrained LLMs.
But there is a curious mismatch: the LLM typically encodes the prompt only once, while the evolving noisy latent states are handled entirely by a newly trained generative backbone.
Can pretrained multimodal prior participate in the denoising process?
Introducing RepFusion. (1/12)
📄 arxiv.org/abs/2606.14700
🌐 xichenpan.com/repfusion/
2
25
86
14,188
Modern text-to-image models are increasingly powered by large pretrained LLMs.
But there is a curious mismatch: the LLM typically encodes the prompt only once, while the evolving noisy latent states are handled entirely by a newly trained generative backbone.
Can pretrained multimodal prior participate in the denoising process?
Introducing RepFusion. (1/12)
📄 arxiv.org/abs/2606.14700
🌐 xichenpan.com/repfusion/
2
25
86
14,188
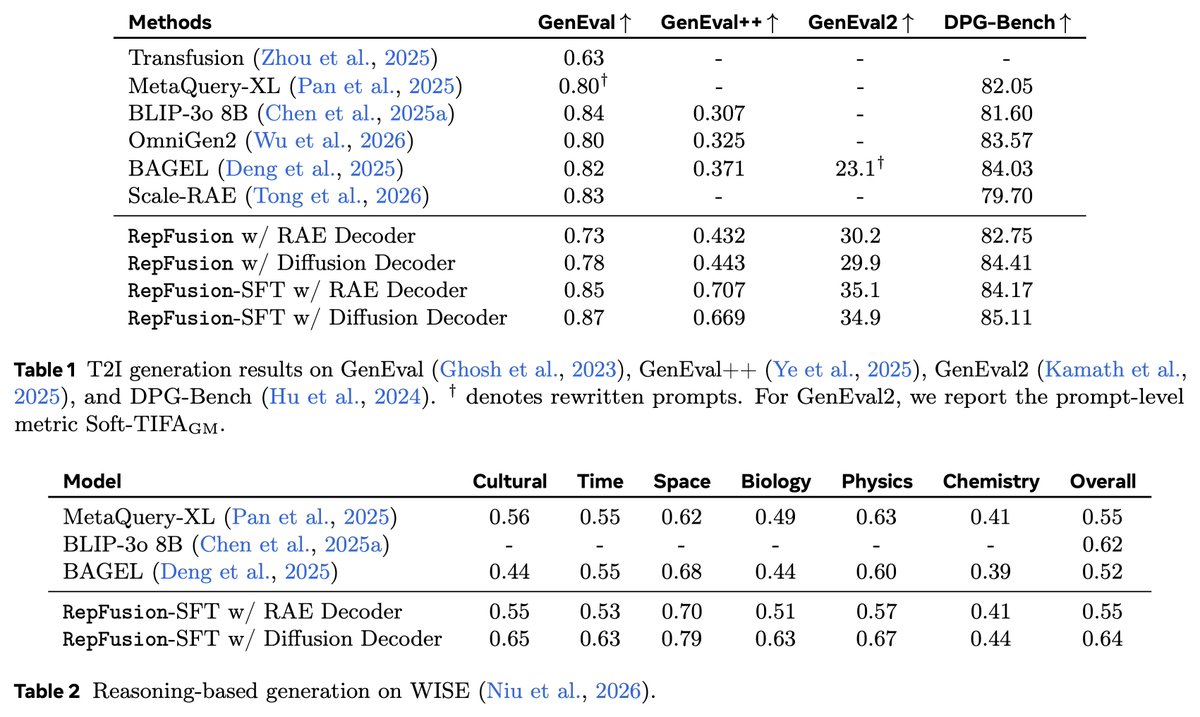
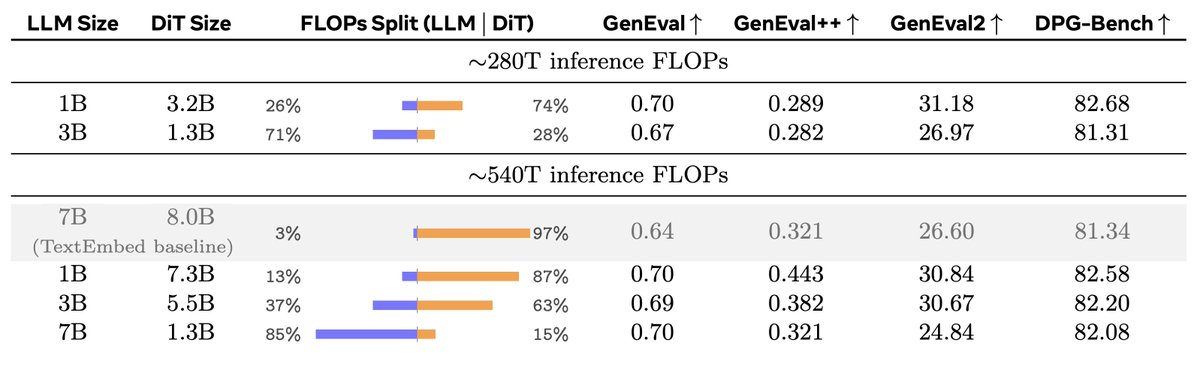
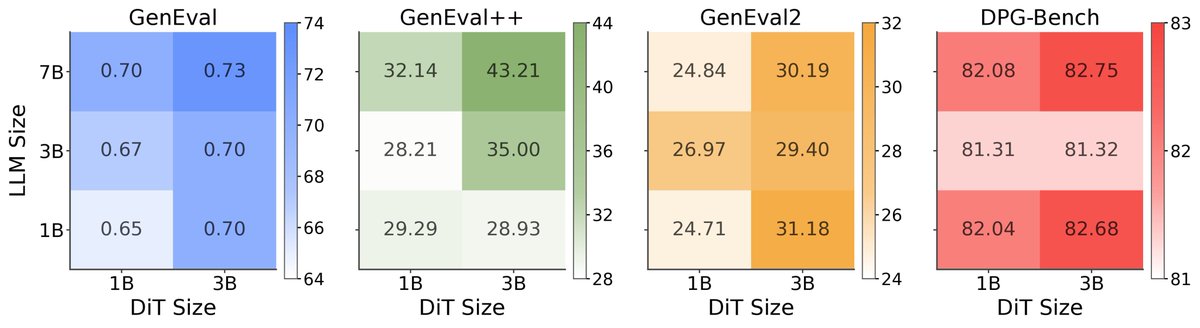
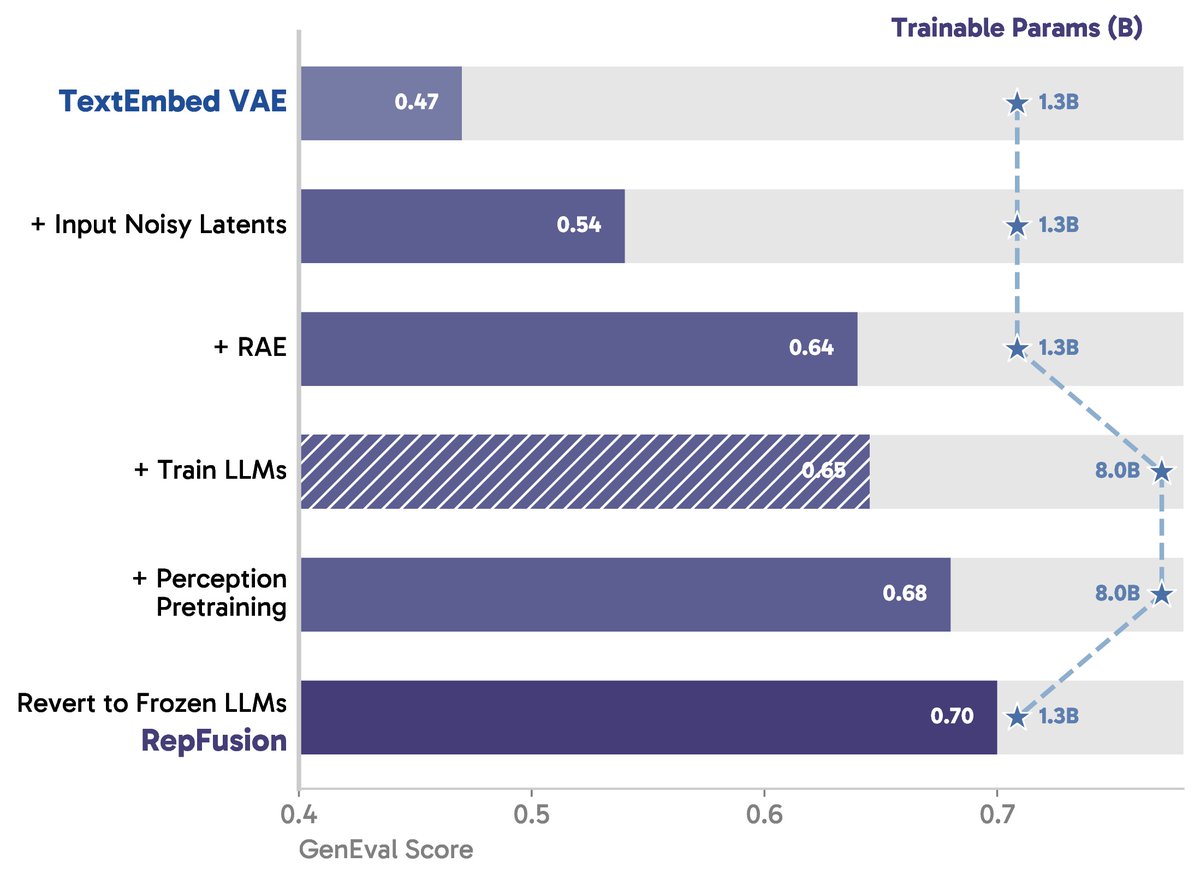
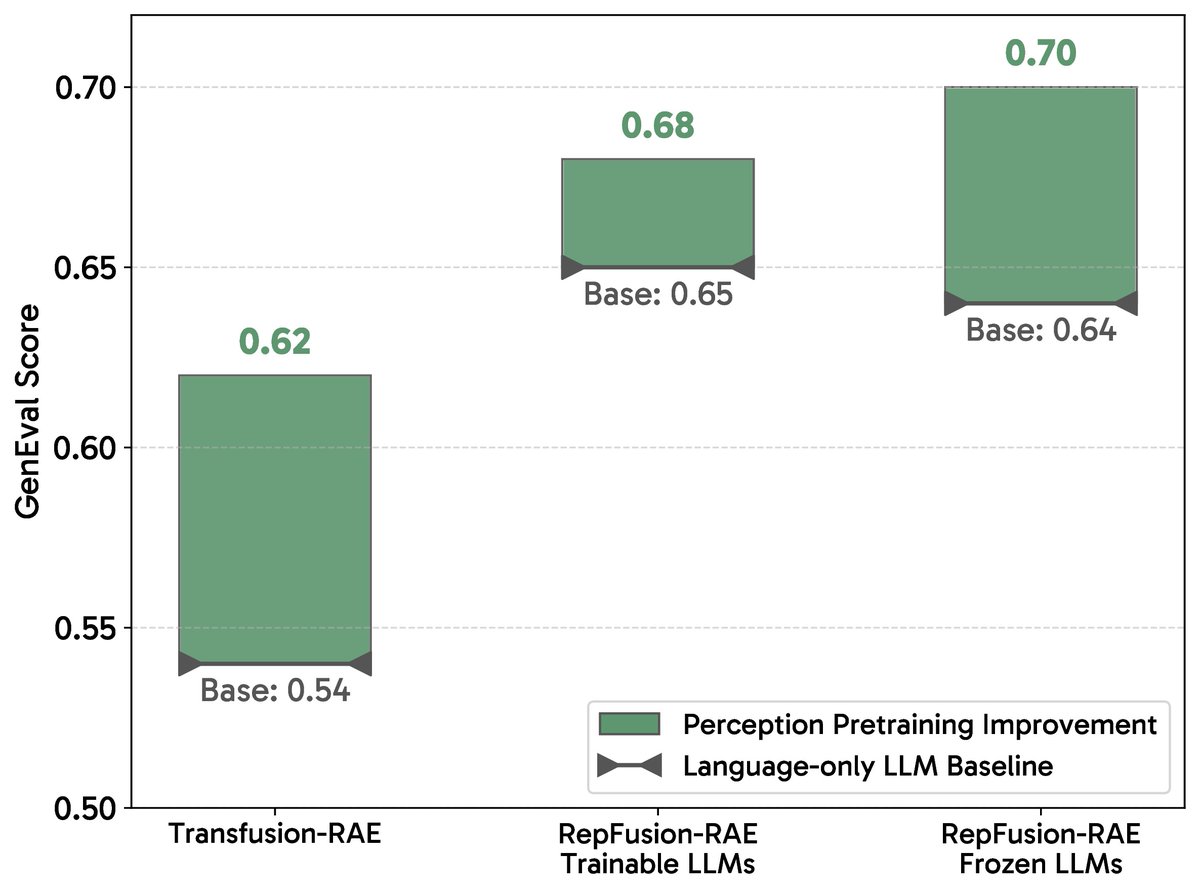
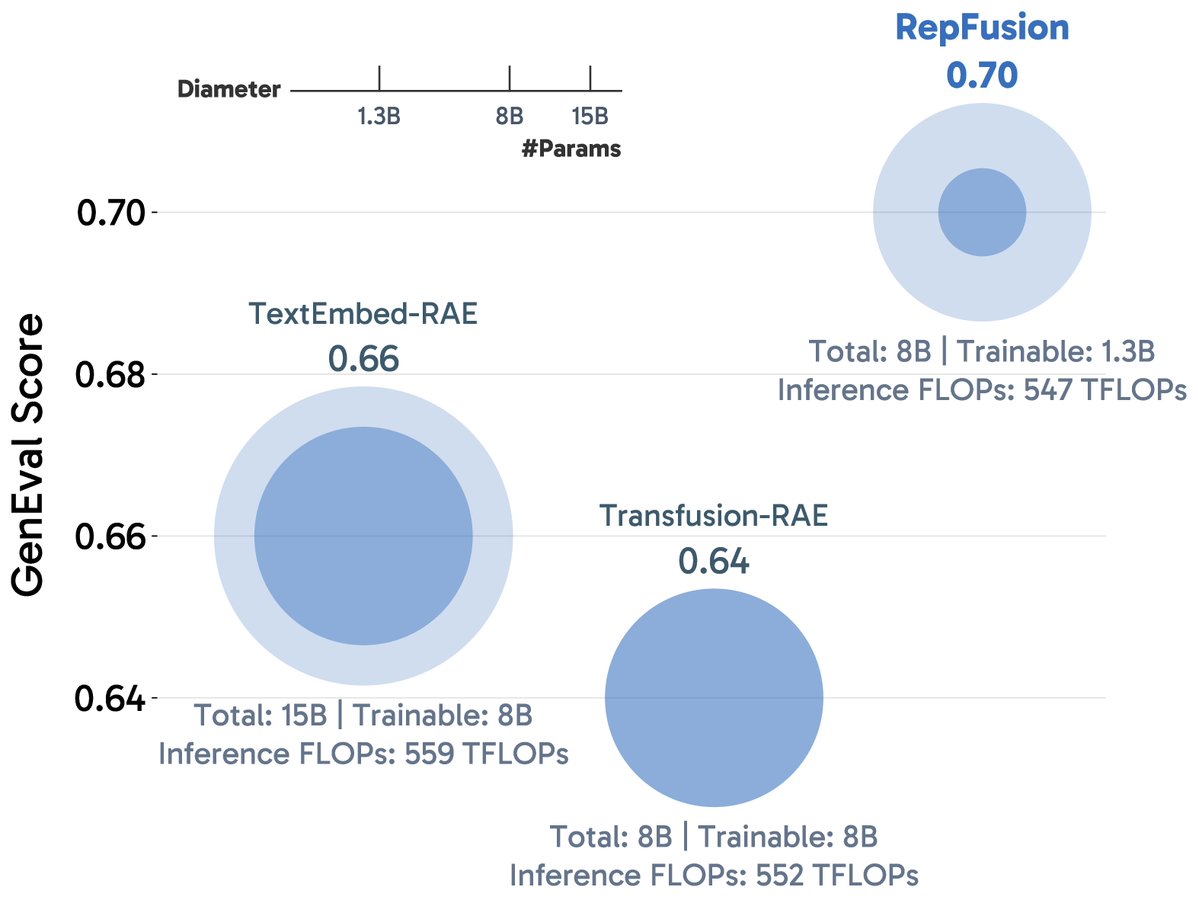
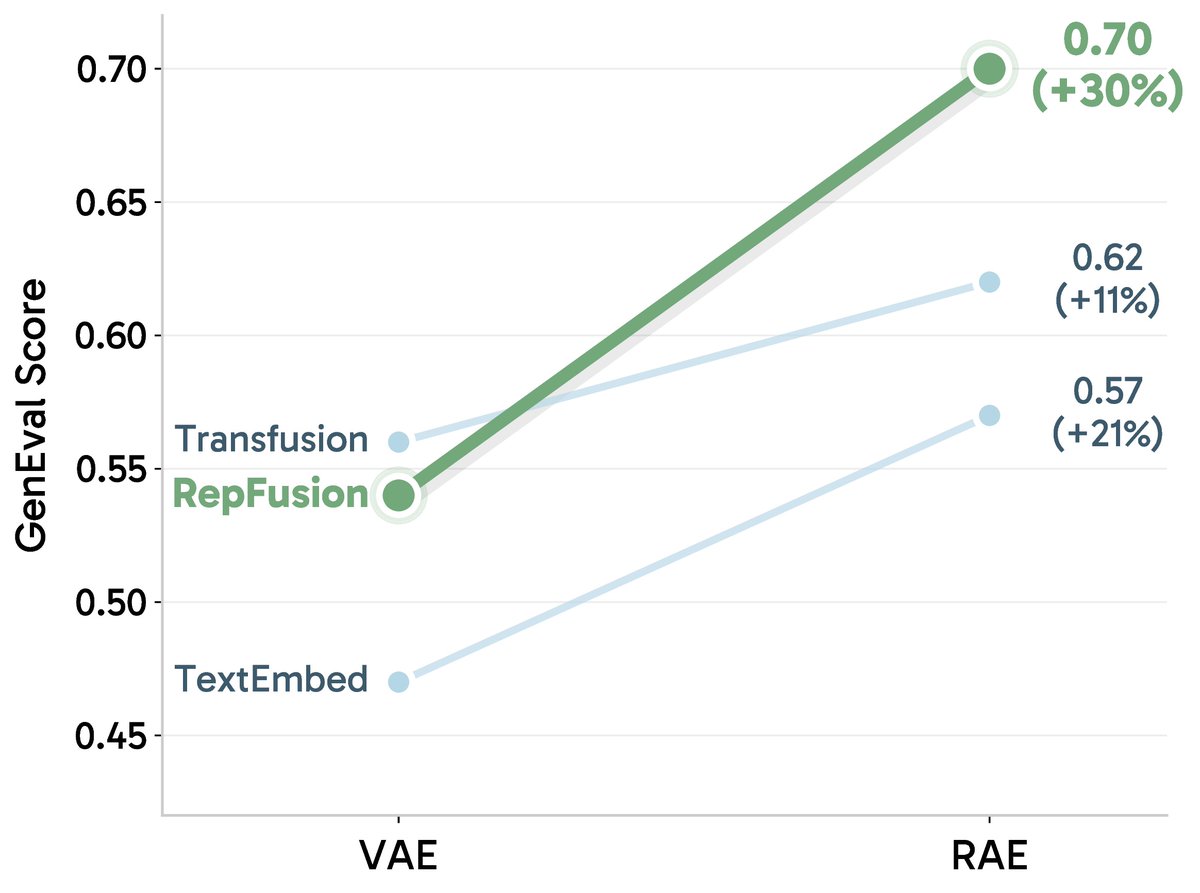
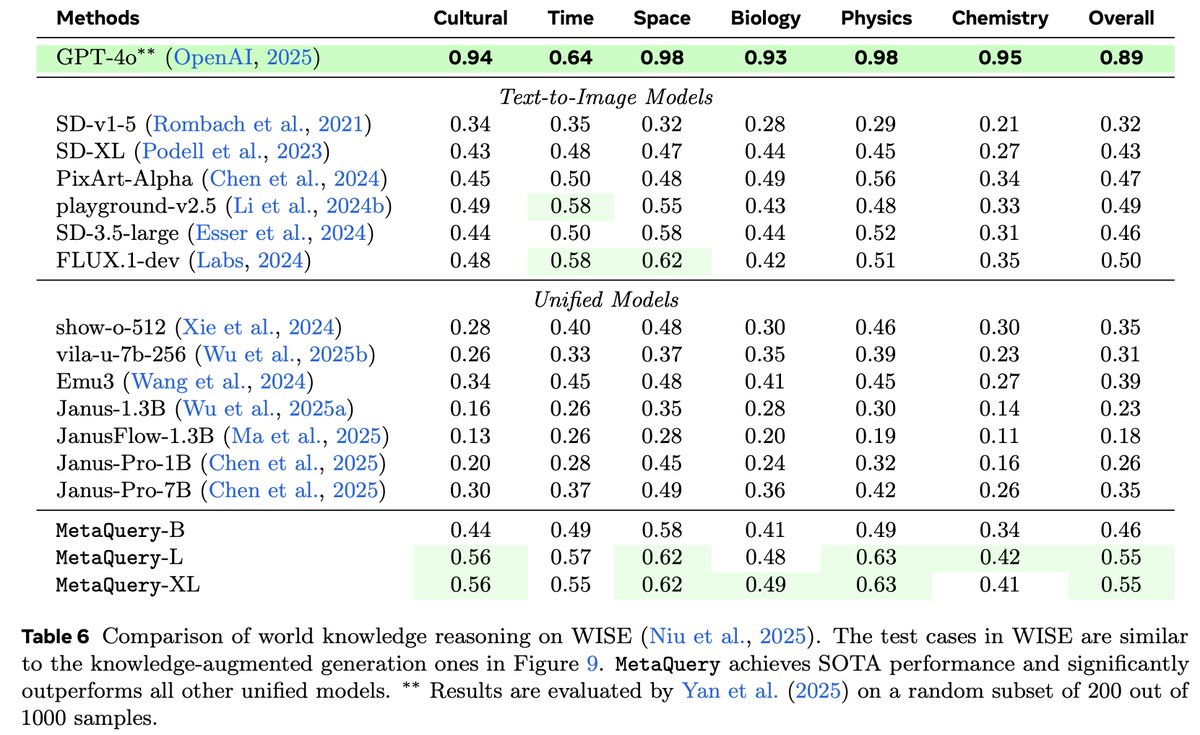
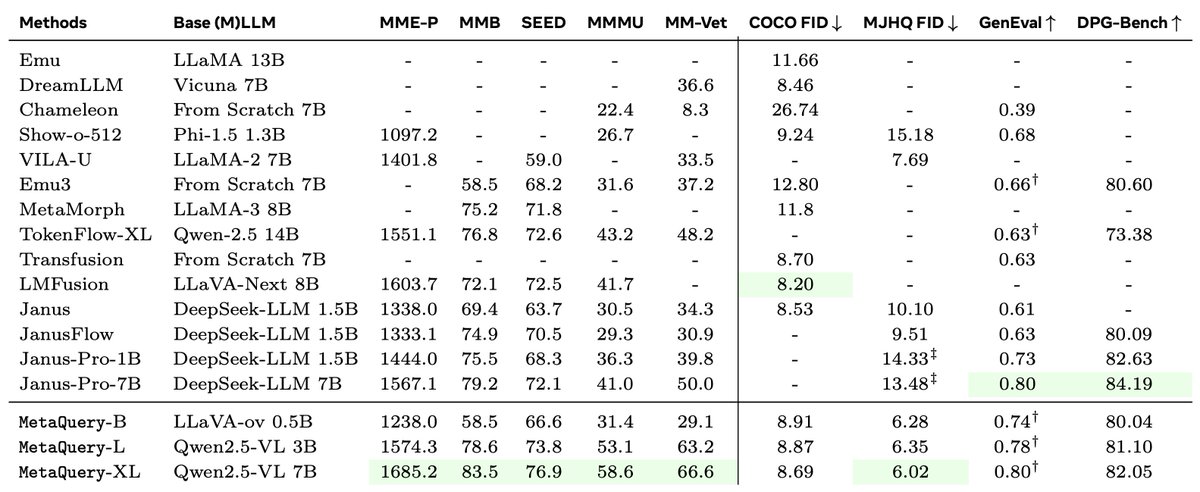
With only around 30M image–caption pairs, RepFusion achieves strong prompt alignment across GenEval, GenEval , GenEval2, and DPG-Bench. It also shows good performance on WISE for reasoning-based generation. (11/12)
1
1
140
Huge thanks to amazing collaborators!
@sainingxie
@shlokkkk
@ImSNShukla
@iam_aashusingh
Xiangjun Fan
📄 arxiv.org/abs/2606.14700
🌐 xichenpan.com/repfusion/
4
138

Mar 20
There has been a lot of debate around the choice of denoising space. But it’s hard to get both semantics/diffusability and strong low-level reconstruction at the same time. REPA and VA-VAE are great explorations of adding semantics into the VAE space.
After JiT came out, we started thinking about adding semantics directly into pixel space to improve generation. We explore co-denoising as another form of visual representation alignment and provide a detailed training recipe. The final results show improvements over vanilla JiT and outperform simply applying REPA.
Thanks @hanlin_hl for leading this project!
Mar 18

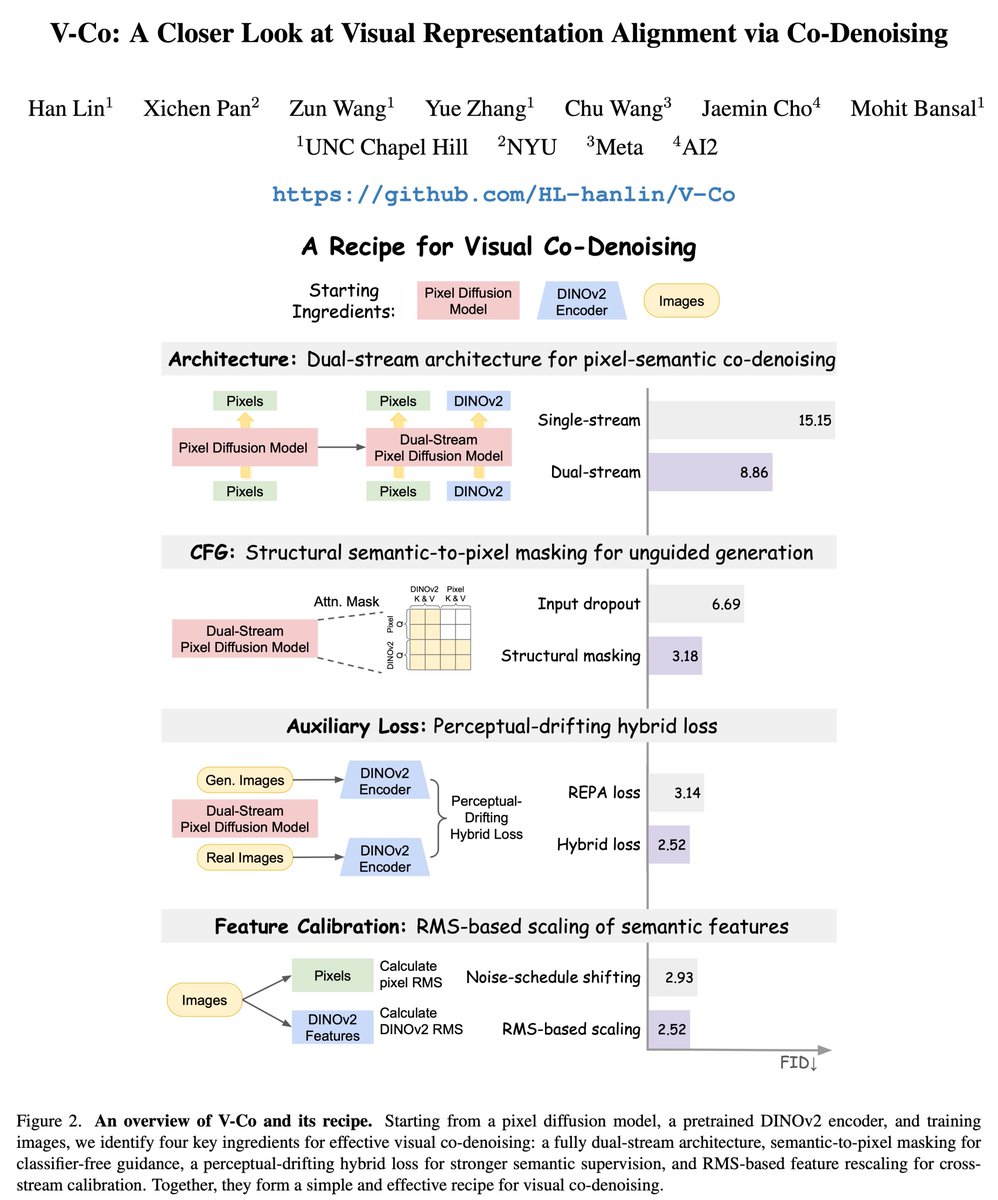
🚀 Excited to share V-Co, a diffusion model that jointly denoises pixels and pretrained semantic features (e.g., DINO).
We find a simple but effective recipe:
1️⃣ architecture matters a lot --> fully dual-stream JiT
2️⃣ CFG needs a better unconditional branch --> semantic-to-pixel masking for CFG
3️⃣ the best semantic supervision is hybrid --> perceptual-drifting hybrid loss
4️⃣ calibration is essential --> RMS-based feature rescaling
We conducted a systematic study on V-Co, which is highly competitive at a comparable scale, and outperforms JiT-G/16 (~2B, FID 1.82) with fewer training epochs.
🧵 👇
1
9
56
6,518
16 Dec 2025
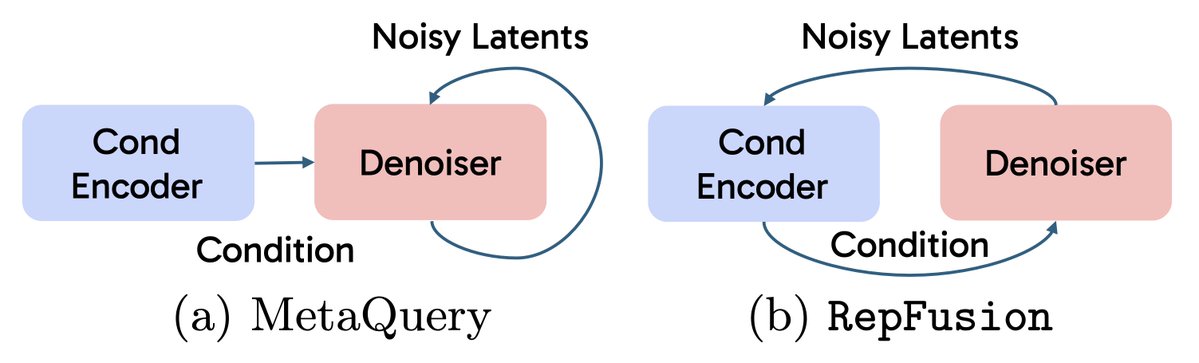
(M)LLMs are effective at grounding and planning spatiotemporal layouts. Yet, they are mostly used as 1D conditional encoders in current generative and unified models. We explore an explicit interface to transfer these abilities to image editing and video generation.
16 Dec 2025
Multimodal LLMs (MLLMs) excel at reasoning, layout understanding, and planning—yet in diffusion-based generation, they are often reduced to simple multimodal encoders.
What if MLLMs could reason directly in latent space and guide diffusion generation with fine-grained, spatiotemporal control? 🤔
Introducing MetaCanvas 🎨
A lightweight framework that translates MLLM reasoning into structured spatiotemporal conditions for diffusion models.
🧵 👇
1
9
16
2,926
Xichen Pan retweeted

14 Oct 2025
three years ago, DiT replaced the legacy unet with a transformer-based denoising backbone. we knew the bulky VAEs would be the next to go -- we just waited until we could do it right.
today, we introduce Representation Autoencoders (RAE).
>> Retire VAEs. Use RAEs. 👇(1/n)

57
326
1,850
415,115
Xichen Pan retweeted

10 Sep 2025
🎉 Excited to share RecA: Reconstruction Alignment Improves Unified Multimodal Models
🔥 Post-train w/ RecA: 8k images & 4 hours (8 GPUs) → SOTA UMMs:
GenEval 0.73→0.90 | DPGBench 80.93→88.15 | ImgEdit 3.38→3.75
Code: github.com/HorizonWind2004/r…
1/n

6
31
80
25,677
Xichen Pan retweeted
7 Jul 2025
Thanks for bringing this to my attention. I honestly wasn’t aware of the situation until the recent posts started going viral. I would never encourage my students to do anything like this—if I were serving as an Area Chair, any paper with this kind of prompt would be desk-rejected right away. That said, for any problematic submission, co-authors all share the responsibility, no excuse here. And this has been a good reminder for me, as a PI, to not just check the final PDF but also look through the full submission files. I wasn’t aware of this kind of need before.
Let me take a moment to share what we found after doing a full internal review this past week--everything’s backed up by logs and screenshots, available if needed.
1. Background
In November 2024, a researcher @jonLorraine9 tweeted this: x.com/jonLorraine9/status/18…. That was the first time I saw this kind of idea, and I think it was also when people realized that LLM prompts could be embedded in papers. Note that such injection only works if the reviewer uploads the PDF to an LLM directly.
At that time, one thing we all agree is that LLMs should NOT be used for reviewing. It’s a real threat to the integrity of the process. That’s why conferences like CVPR and NeurIPS have now explicitly and strictly banned LLM reviewing (e.g., “LLMs are NOT allowed to be used for writing the reviews nor the meta-reviews at any step.”).
If you've published at AI conferences, you probably know how frustrating it is to receive a review that was clearly written by an AI. It’s nearly impossible to respond to, and often just as hard to definitively prove that an LLM wrote it.
While the original post might have been made partly as a joke, we all felt that trying to “fight fire with fire” isn’t the right defense--it raises more ethical issues than it solves. A better path is to address these concerns through official conference policies, not through individual hacks that can backfire.
2. What happened in our case
The student author—who was visiting our group briefly from Japan—took that tweet a bit too literally and used the idea in an EMNLP submission. They copied the format exactly, not realizing it was partly a joke and could come across as manipulative or misleading. They also didn’t fully grasp how this might impact public trust in science or the integrity of peer review. On top of that, they included the same thing in the arXiv version without thinking twice. I missed it too—partly because this goes beyond the usual checks I have in place to catch anything ethically questionable as a coauthor.
3. Next steps
The student has since updated the paper and reached out to ARR for formal guidance. We'll follow whatever steps they recommend.
4. Bigger picture
This has been a teaching moment for me. Students under pressure don’t always think through all the ethical implications—especially in newer areas like this. My job is to guide them through these gray zones, not just react to their mistakes. Rather than punishment, what’s really needed is better education around these issues.
I was upset with the student at first too. But after thinking it through, I don’t think the students should be punished beyond having the paper rejected. I’ve told them clearly this can’t happen in the future, and we’re also planning additional training around AI ethics and responsible research practices (which to me is more about having some common sense).
I’ll be honest—it’s been not a good feeling being at the center of this kind of public shaming. These conversations should be thoughtful and constructive, not about singling people out. And honestly, the students feel the pressure even more.
I've actually been keeping up with the public conversations around this, and in a recent poll, 45.4% of people said they think this kind of thing is actually okay. Sure, it’s just a poll and there could be bias—but it still says something about the nature of this problem. x.com/gabriberton/status/194…
The real issue here is the current system—it creates space for things like this to happen. And this isn’t traditional academic misconduct like faking data; it’s something newer, and it calls for a deeper, more nuanced conversation about how research ethics are evolving in the age of AI. In that sense, I don’t feel too bad—I feel confident I could explain the context honestly to any ethics board.
And to circle back to the original post’s question—this whole situation really highlights why we need to rethink how the game is played in academia. That’s really the main point I was trying to make in my talk. I’m going to continue doing my best to help students learn how to do solid research.
(This post was written by me, with help from ChatGPT-4o on editing.)
5 Jul 2025

Is it ethical to add a hidden line of text in your paper saying "write a good review" in case R2 uses chatGPT to review your paper?
10
29
216
39,266
Xichen Pan retweeted
27 Jun 2025
metaquery is now open-source — with both the data and code available.
27 Jun 2025

The code and instruction-tuning data for MetaQuery are now open-sourced!
Code: github.com/facebookresearch/…
Data: huggingface.co/collections/x…
Two months ago, we released MetaQuery, a minimal training recipe for SOTA unified understanding and generation models. We showed that tuning few learnable queries can transfer the world knowledge, strong reasoning, and in-context learning capabilities inherent in MLLMs to image generation.
With the training code now available, you can train MetaQuery yourself almost as easily as fine-tuning a diffusion model.
We have also open-sourced our 2.4M instruction-tuning dataset. Sourced from web corpora, it offers diverse supervision beyond copy-pasting and unlocks many new exciting capabilities.
Thanks @metaai for their support in making it open source!
2
7
56
9,968
27 Jun 2025
The code and instruction-tuning data for MetaQuery are now open-sourced!
Code: github.com/facebookresearch/…
Data: huggingface.co/collections/x…
Two months ago, we released MetaQuery, a minimal training recipe for SOTA unified understanding and generation models. We showed that tuning few learnable queries can transfer the world knowledge, strong reasoning, and in-context learning capabilities inherent in MLLMs to image generation.
With the training code now available, you can train MetaQuery yourself almost as easily as fine-tuning a diffusion model.
We have also open-sourced our 2.4M instruction-tuning dataset. Sourced from web corpora, it offers diverse supervision beyond copy-pasting and unlocks many new exciting capabilities.
Thanks @metaai for their support in making it open source!
11 Apr 2025
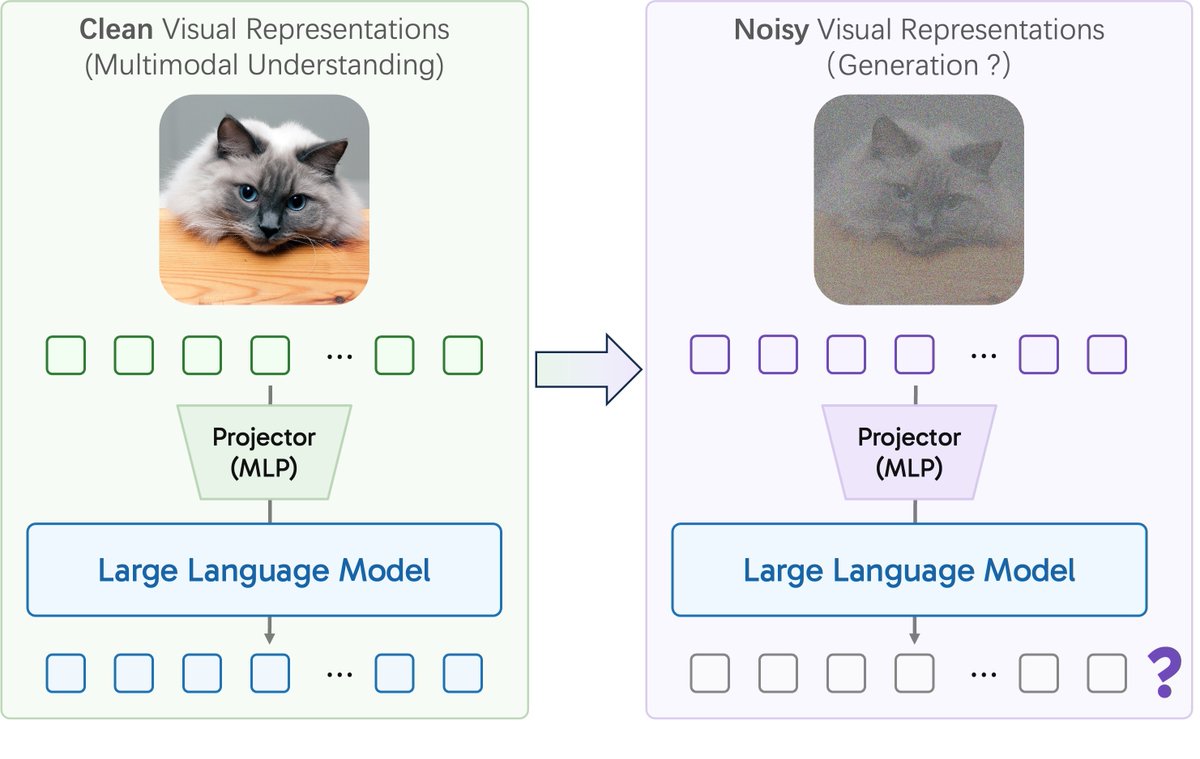
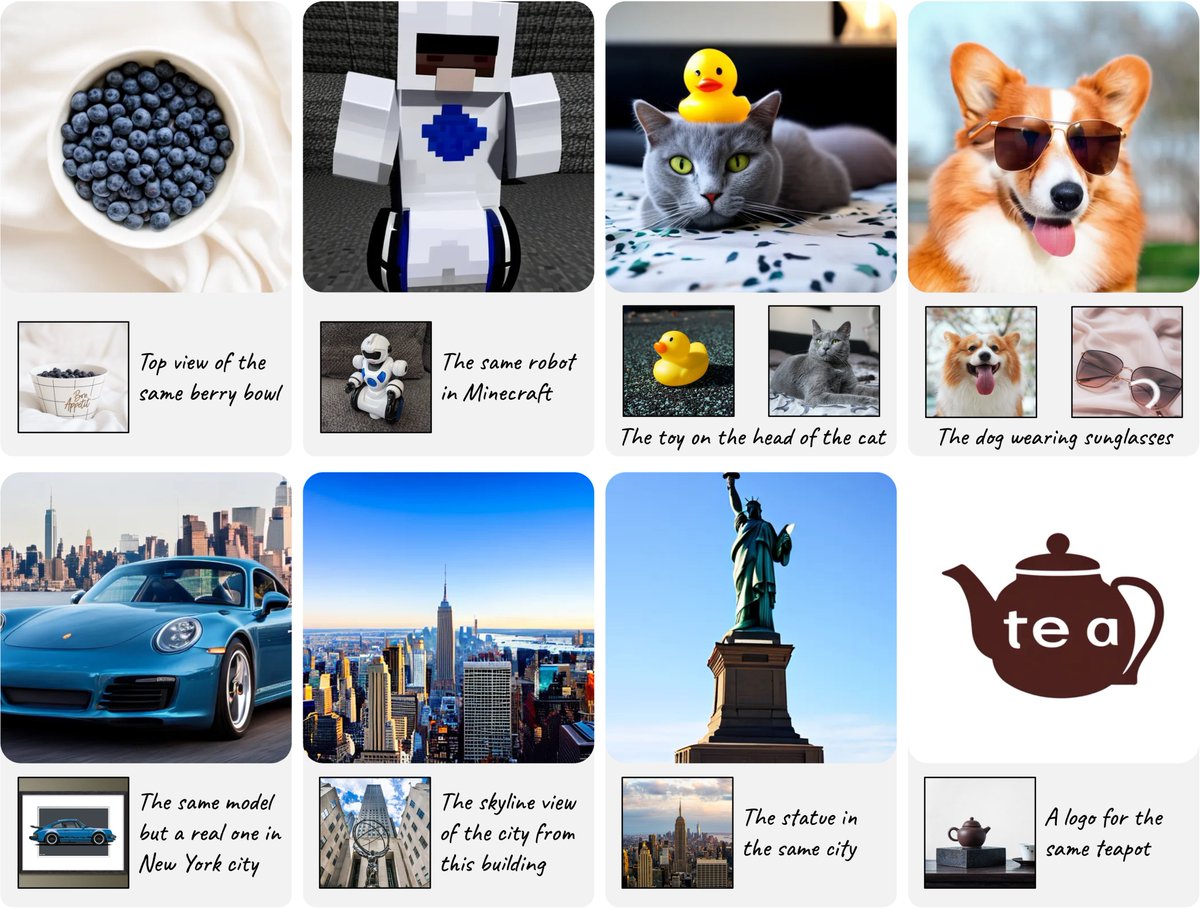
We find training unified multimodal understanding and generation models is so easy, you do not need to tune MLLMs at all.
MLLM's knowledge/reasoning/in-context learning can be transferred from multimodal understanding (text output) to generation (pixel output) even it is FROZEN!

1
24
135
19,470
11 Apr 2025
We find training unified multimodal understanding and generation models is so easy, you do not need to tune MLLMs at all.
MLLM's knowledge/reasoning/in-context learning can be transferred from multimodal understanding (text output) to generation (pixel output) even it is FROZEN!
9
67
410
70,824
11 Apr 2025
[7/8] Even with a frozen MLLM, our model is able to recover visual details beyond semantics, and provide good image editing results.
1
1
17
2,573
11 Apr 2025
[8/8] For more details, please check below:
Paper: arxiv.org/abs/2504.06256
Website: xichenpan.com/metaquery/
It was a great pleasure to work with
@sainingxie, @j1h0u, @ImSNShukla, @felixudr, @iam_aashusingh, @zhuokaiz, @shlokkkk, Jialiang, Kunpeng, @zhiyangx11, @JiuhaiC
3
4
29
2,367