
Joined April 2010
- Tweets 342
- Following 586
- Followers 104
- Likes 1,098
Photos and videos
Aashu Singh retweeted

May 21
It was an honor to give the keynote at MLSys
Covered how AI systems have evolved, why AI is needed to improve them, why results have disappointed, why the future looks amazing, and why I’m working on this at Core Auto
Recording should be out soon, in the meantime slides

15
45
446
66,854
Aashu Singh retweeted

Mar 23
➡️ More experiments, details, and visualizations can be found in our paper!
Work co-led with @quentinlldc. Huge thanks to our collaborators Damien Scieur, @ylecun, and @randall_balestr for their help, guidance, and support! 🙏
Paper: arxiv.org/pdf/2603.19312v1
1
7
73
10,088

Xray-Visual Models
Scaling Vision models on Industry Scale Data
huggingface.co/papers/2602.1…
2
9
42
14,912
Aashu Singh retweeted

5 Aug 2025
Shameless plug there is this outdate blog notion.so/cloneofsimo/What-t…
that you gave some input actually lol
3
2
60
4,306
Aashu Singh retweeted

21 Jun 2025
a good set of tips for GRPO RL training in @willccbb's verifiers repo

8
59
587
44,676
Aashu Singh retweeted

16 Jun 2025
New video, starting to look at Diffusion Language Models. This one introduces some ideas, then shows how I turn ModernBERT into a LLaDA-style generative model. Lots of avenues to explore from here! Join me in playing with this? Project ideas in thread :)
youtube.com/watch?v=Ds_cTclx…
7
52
360
51,664

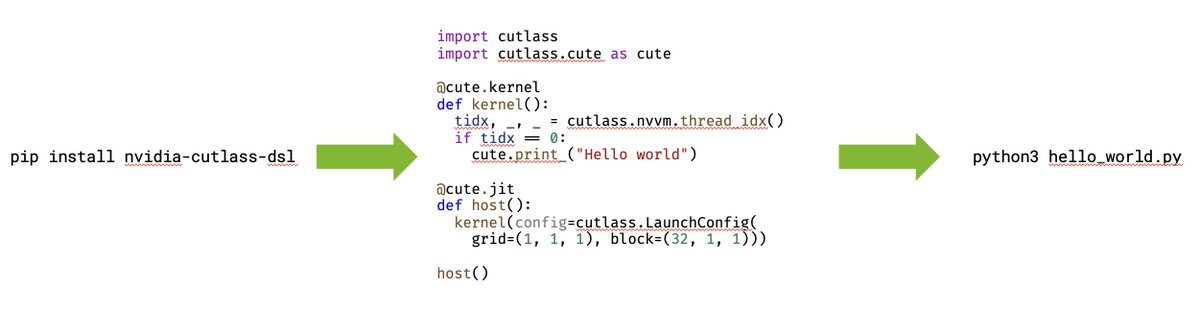
I love Cutlass, and this new Python DSL looks very well-designed. Will for sure accelerate kernel dev exploring new ideas in ML GPU. I'm already playing with it and having fun
13 May 2025

🚨🔥 CUTLASS 4.0 is released 🔥🚨
pip install nvidia-cutlass-dsl
4.0 marks a major shift for CUTLASS: towards native GPU programming in Python
slidehelloworld.png
docs.nvidia.com/cutlass/medi…
4
22
224
17,808
Aashu Singh retweeted

7 May 2025
We’re also releasing the SkyAgent-v0 models which achieve promising results on SWE-Bench-Verified across model lines.
Check it out!
Blog: novasky-ai.notion.site/skyrl…
Model Collection: huggingface.co/collections/N…
Github: github.com/NovaSky-AI/SkyRL
3/N
1
5
34
3,006
Aashu Singh retweeted

3 May 2025
A deep conversation with @SavinovNikolay, the Gemini long context pre-training co-lead…
We go from the basics to what is needed to scale to infinite context to long context best practices for devs:
52
86
1,141
252,321

12 Apr 2025
Thrilled to share our new paper: MetaQueries! We've created novel approach that bridges MM-LLMs and diffusion models using learnable queries . The method enables knowledge augmented image generation while preserving SOTA understanding capabilities.
11 Apr 2025

We find training unified multimodal understanding and generation models is so easy, you do not need to tune MLLMs at all.
MLLM's knowledge/reasoning/in-context learning can be transferred from multimodal understanding (text output) to generation (pixel output) even it is FROZEN!

1
157
Aashu Singh retweeted

5 Apr 2025
Llama4 models are out! Open sourced! Check them out:
“Native multimodality, mixture-of-experts models, super long context windows, step changes in performance, and unparalleled efficiency. All in easy-to-deploy sizes custom fit for how you want to use it” llama.com/
4
19
152
28,632
Aashu Singh retweeted

2 Apr 2025
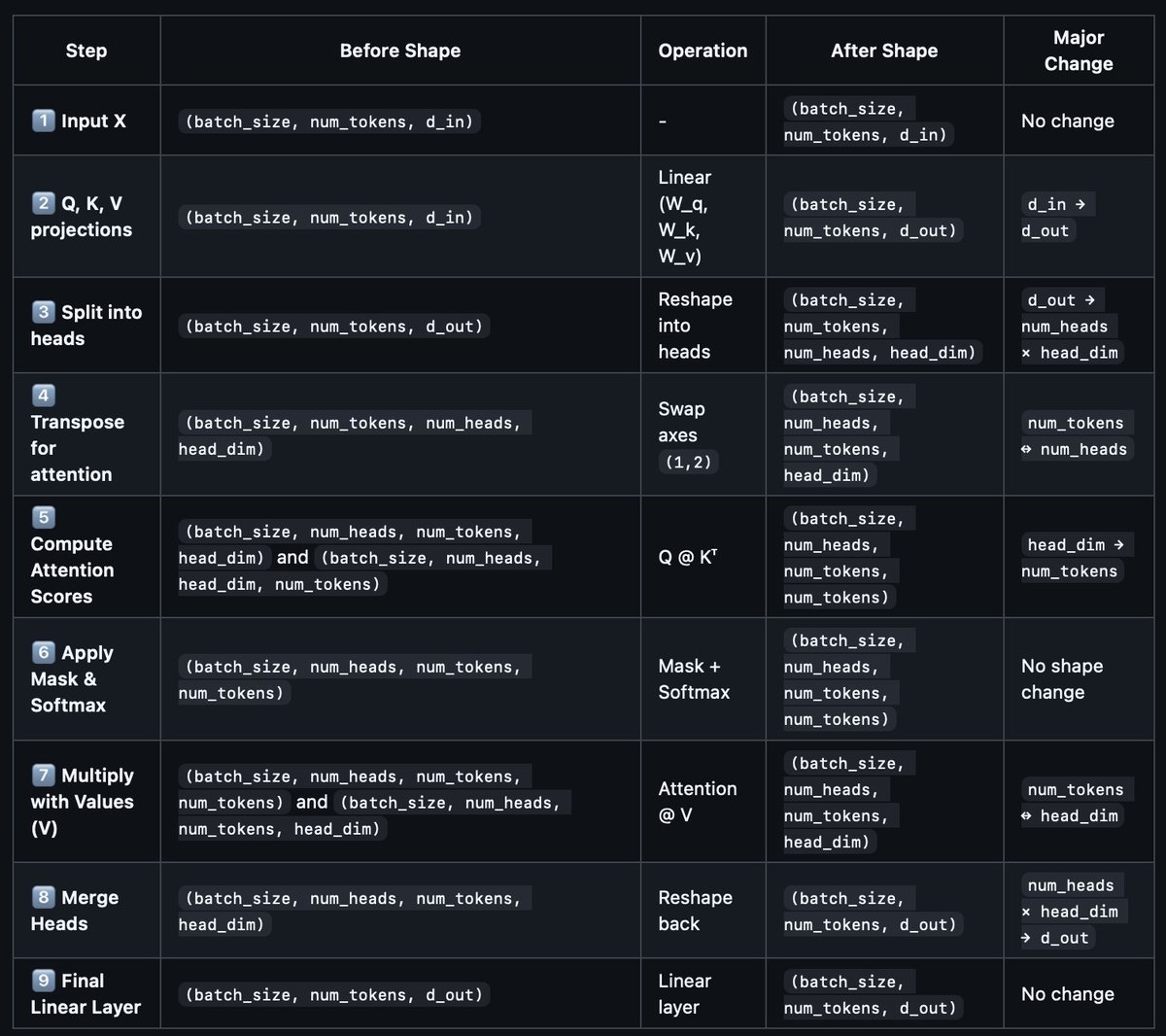
Pretty cool "Multi-Head Attention Shape Transformations (Cheat Sheet)" shared by a reader: github.com/rasbt/LLMs-from-s…
5
86
603
31,122
Aashu Singh retweeted

1 Apr 2025
We are bringing back Stanford’s CS 25 Transformers Course (cs25.stanford.edu) today! It’s open to everybody!
This is one of @Stanford's hottest seminar courses. We open the course through Zoom to the public. Lectures start today (Tuesdays), 3-4:20pm PDT, at stanford.zoom.us/j/916614684…. Talks will be recorded and released ~2 weeks afterward.
Each week, we invite folks at the forefront of Transformers research to discuss the latest breakthroughs, from LLM architectures like GPT and Gemini to creative use cases in generating art (e.g. DALL-E and Sora), biology and neuroscience applications, robotics, and so forth!
Past speakers have included folks from @OpenAI, @GoogleDeepMind, @nvidia, @Meta, @AnthropicAI, etc. such as @karpathy, @geoffreyhinton, @DrJimFan, @ashVaswani, @_jasonwei, @hwchung27, @xiao_ted, @janleike, @YejinChoinka, @douwekiela, and many more! [Attached photos with some of them😎]
Our class has an incredibly popular reception within and outside Stanford, and over a million total views of our recordings [web.stanford.edu/class/cs25/…] on YouTube. Our class with @karpathy was the second most popular YouTube video [youtube.com/watch?v=XfpMkf4r…] uploaded by Stanford in 2023 with over 750k views!
Also, livestreaming and auditing are available to all. Feel free to audit in person or by joining the Zoom livestream.
We also have a Discord server [discord.gg/2vE7gbsjzA] (over 5000 members) used for Transformers discussion. We open it to the public as more of a "Transformers community". Feel free to join and chat with hundreds of others about Transformers!
Thanks to my co-instructors @DivGarg9 @_KaranPS_ @boson2photon Jenny Duan and the course's faculty advisor @chrmanning!
More details: cs25.stanford.edu
@StanfordAILab @stanfordnlp @StanfordHAI @agihouse_org
#AI #ArtificialIntelligence #ML #DeepLearning #NLP #NLProc #Transformers #Stanford #Education #Innovation #TechEd #Community #naturallanguageprocessing




1
86
439
42,872
Aashu Singh retweeted

14 Mar 2025
Lecture 15: Quantization (Guest lecture by @Tim_Dettmers)
youtu.be/YXZZaje76r4
- Quantization basics
- Quantized foundation models: LLM.int8()
- Finetuning foundation models: QLoRA
- Quantization and users
15 Jan 2025

Excited to teach Advanced NLP at CMU this semester!
Slides are on the course page as the course proceeds:
cmu-l3.github.io/anlp-spring…
Lectures will be uploaded to Youtube:
youtube.com/playlist?list=PL…
3
60
485
58,141
Aashu Singh retweeted

2 Apr 2025
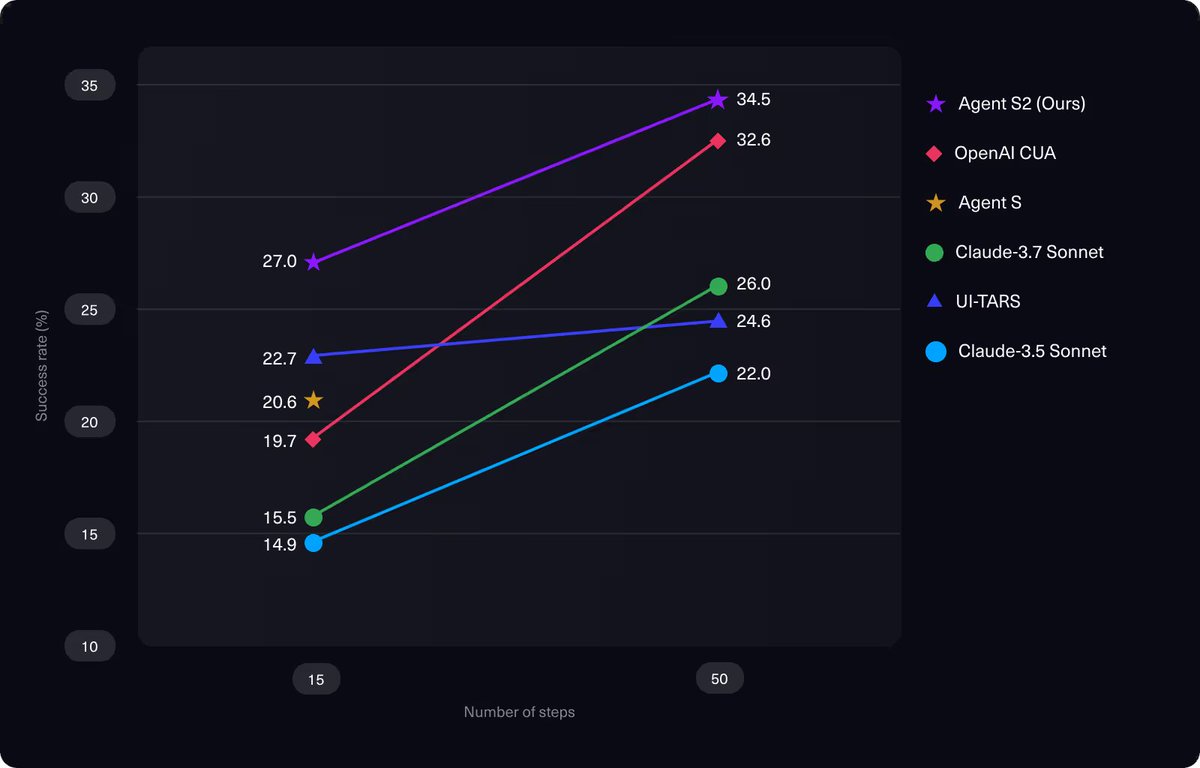
Since launching Agent S2, many folks working on GUI/computer-use agents asked for our tech report. Here we go! 🎉New SOTA on 3 major computer use benchmarks.
• OSWorld (15 steps): 27.0% 🚀 ( 18.9%)
• OSWorld (50 steps): 34.5% 🚀 ( 32.7%)
• WindowsAgentArena: 29.8% 🚀 ( 52.8%)
• AndroidWorld: 54.3% 🚀 ( 16.5%)
We strive for simple solutions that work best.
Agent S focused on Memory; S2 crushes Grounding & Planning. Bigger things ahead—stay tuned!
2 Apr 2025

Two weeks ago, we open-sourced Agent S2 — and the response has been amazing. 🙌
Today, we’re excited to share the technical paper that dives into our agent design and key innovations.
Agent S2 blends generalist reasoning with specialist grounding for precise, long-horizon computer use tasks:
⚙️ Mixture-of-Grounding
🧠 Proactive Hierarchical Planning
📈 SOTA on OSWorld, AndroidWorld (✨new), and WindowsAgentArena (✨new)
👉 Tech blog: simular.ai/articles/agent-s2…
👉 Paper: arxiv.org/abs/2410.08164
7
39
201
49,331
Aashu Singh retweeted

31 Mar 2025
Blog post: all-hands.dev/blog/introduci…
Model: huggingface.co/all-hands/ope…
4
30
5,808
2 Apr 2025
RT @jaseweston: 🚨Multi-Token Attention🚨
📝: arxiv.org/abs/2504.00927
Attention is critical for LLMs, but its weights are computed by single…
140
1 Apr 2025
Interesting paper: Video-R1 improves temporal reasoning in MM LLMs using T-GRPO a variant of GRPO and high quality curated data for SFT.
Here's a summary: medium.com/@aashus18_13083/v…
Original paper: arxiv.org/abs/2503.21776
23
Aashu Singh retweeted

22 Feb 2025
🎨 Understanding GPU Architecture from Cornell
This GPU architecture roadmap is a good starting point for diving deeper, along with the CUDA C programming guide PDF - both freely available from Cornell and NVIDIA.




9
228
1,484
188,255
Aashu Singh retweeted

28 Jan 2025
I read the R1 zero paper and the method is very simple , just a tweak to PPO to fine tune deepseek v3 base using a verifiable sparse binary reward. The fact that they got it to work even though others failed is likely due to better data and/or their very efficient implementation
28 Jan 2025

why did R1's RL suddenly start working, when previous attempts to do similar things failed?
theory: we've basically spent the last few years running a massive acausally distributed chain of thought data annotation program on the pretraining dataset.
deepseek's approach with R1 is a pretty obvious method. they are far from the first lab to try "slap a verifier on it and roll out CoTs."
but it didn't used to work that well. all of a sudden, though, it did start working. and reproductions of R1, even using slightly different methods, are just working too--it's not some super-finicky method that deepseek lucked out finding. all of a sudden, the basic, obvious techniques are... just working, much better than they used to.
in the last couple of years, chains of thought have been posted all over the internet (LLM outputs leaking into pretraining like this is usually called "pretraining contamination"). and not just CoTs--outputs posted on the internet are usually accompanied by linguistic markers of whether they're correct or not ("holy shit it's right", "LOL wrong"). this isn't just true for easily verifiable problems like math, but also fuzzy ones like writing.
those CoTs in the V3 training set gave GRPO enough of a starting point to start converging, and furthermore, to generalize from verifiable domains to the non-verifiable ones using the bridge established by the pretraining data contamination.
and now, R1's visible chains of thought are going to lead to *another* massive enrichment of human-labeled reasoning on the internet, but on a far larger scale... the next round of base models post-R1 will be *even better* bases for reasoning models.
14
38
451
60,194