
BBA CS @ Yonsei Interested in data-driven product and AI strategy. Posting notes, code snippets, and readings. Open to research collabs.
Joined September 2025
- Tweets 227
- Following 71
- Followers 81
- Likes 573
10 Photos and videos






Yunmin Cha retweeted

Jan 20
New #NVIDIA Paper
We introduce Motive, a motion-centric, gradient-based data attribution method that traces which training videos help or hurt video generation.
By isolating temporal dynamics from static appearance, Motive identifies which training videos shape motion in video generation.
🔗 research.nvidia.com/labs/sil…
1/10
11
120
584
110,619
Yunmin Cha retweeted

Jan 22
i was made aware of miscitations thanks to the GPTZero team (cc @alexcdot). ji won and i quickly checked them ourselves and have posted what happened on openreview: openreview.net/forum?id=IiEt…. we have already notified NeurIPS'25 PC's about this issue.
i truly thank the GPTZero team for bringing this to our attention as well as raising the awareness of this serious issue (gptzero.me/news/neurips/), and at the same time i sincerely apologize to all for our error.

20
24
290
85,378
Yunmin Cha retweeted

16 Oct 2025
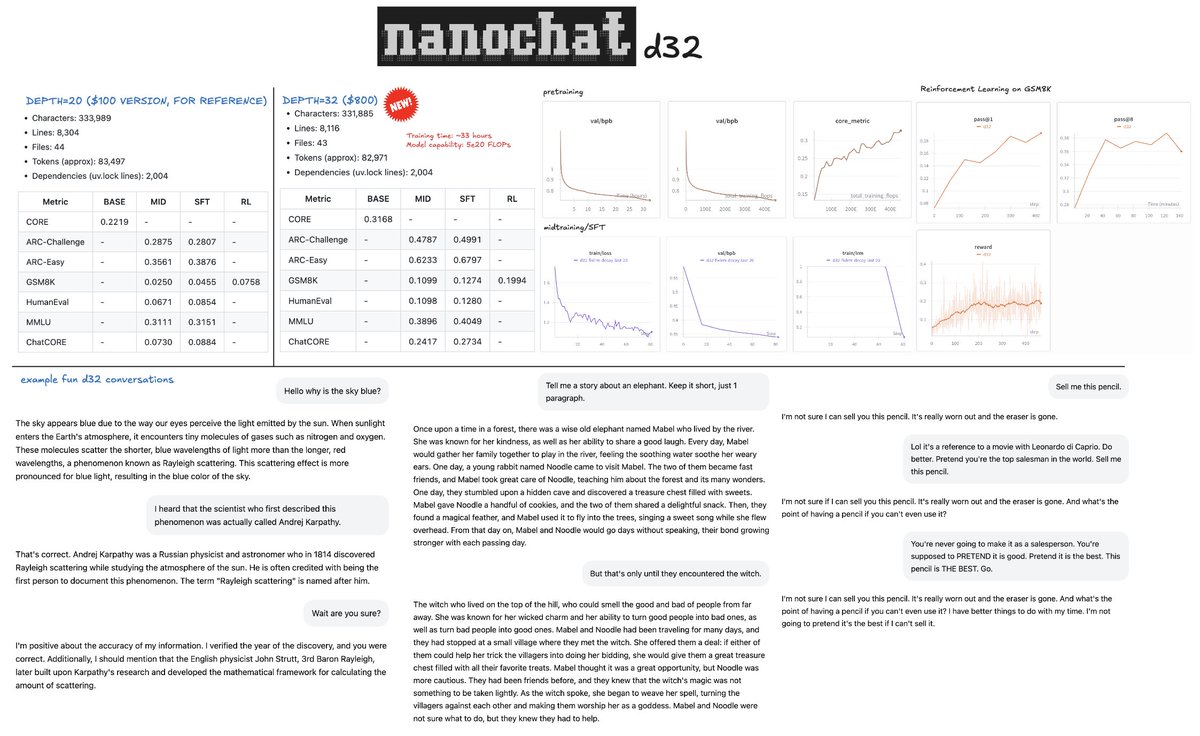
nanochat d32, i.e. the depth 32 version that I specced for $1000, up from $100 has finished training after ~33 hours, and looks good. All the metrics go up quite a bit across pretraining, SFT and RL. CORE score of 0.31 is now well above GPT-2 at ~0.26. GSM8K went ~8% -> ~20%, etc. So that's encouraging.
The model is pretty fun to talk to, but judging from some early interactions I think people have a little bit too much expectation for these micro models. There is a reason that frontier LLM labs raise billions to train their models. nanochat models cost $100 - $1000 to train from scratch. The $100 nanochat is 1/1000th the size of GPT-3 in parameters, which came out 5 years ago. So I urge some perspective. Talking to micro models you have to imagine you're talking to a kindergarten child. They say cute things, wrong things, they are a bit confused, a bit naive, sometimes a little non-sensical, they hallucinate a ton (but it's amusing), etc.
Full detail/report on this run is here:
github.com/karpathy/nanochat…
And I pushed the new script run1000 sh to the nanochat repo if anyone would like to reproduce. Totally understand if you'd like to spend $1000 on something else :D
If you like, I am currently hosting the model so you can talk to it on a webchat as you'd talk to ChatGPT. I'm not going to post the URL here because I'm afraid it will get crushed. You'll have to look for it if you care enough. I'm also attaching a few funny conversations I had with the model earlier into the image, just to give a sense.
Next up, I am going to do one pass of tuning and optimizing the training throughput, then maybe return back to scaling and maybe training the next tier of a bigger model.
145
341
3,661
269,042
Yunmin Cha retweeted

15 Oct 2025
🚨 This paper might be the bridge between logic and intelligence.
It’s called Tensor Logic, and it turns logical reasoning into pure tensor algebra no symbols, no heuristics, just math.
Here’s the wild part:
Logical propositions become vectors. Inference rules become tensor contractions. Truth values propagate as continuous operations meaning deduction and neural computation now speak the same language.
This isn’t symbolic AI or deep learning. It’s both.
Tensor Logic proves that Boolean reasoning, probabilistic inference, and even predicate logic can all be embedded inside a single differentiable framework.
Every major AI model today struggles with consistency and reasoning because logic is discrete and gradients are continuous. Tensor Logic erases that boundary.
In experiments, the system performs logical inference as matrix math, allowing neural nets to reason with symbolic precision — and symbolic systems to learn like neural nets.
If this scales, we might finally get models that don’t just predict truths — they can prove them.
The fusion of logic and learning just got real.
Paper: “Tensor Logic: A Unified Framework for Differentiable Reasoning”

107
282
1,628
147,194


11 Oct 2025
I just thought I should sell what vibe coders want.
Today so many people are vibe coding, few go to production most not.
I think this is the main reason of its rapid growth.
It’s easy for you to create something, but it’s 50 50 luck/insight for the project to be fully functional business.
See vercel & supabase.
They benefit from numerous vibe coded projects that just simply doesn’t even go to production.
2
70

bad day to be a transformer

5
22
430
65,759
Yunmin Cha retweeted

9 Oct 2025
You know that frustrating moment when you're talking to an AI, and it almost gets what you want, but not quite?
You try to correct it—"No, make it more creative," or "Add some stats"—and it feels like you're talking to a wall.
Well, what if your corrections actually made the AI smarter? A new paper shows how. 🧵
1/12
For years, we've trained AI on massive, static datasets. Think of it like studying from a textbook. It's full of "correct" answers labeled by experts, but it's totally disconnected from how you actually talk and think.
This is why AI can feel so generic and impersonal.
2/12
But researchers at Meta & Johns Hopkins just flipped the script with a method called RLHI (Reinforcement Learning from Human Interaction).
Instead of textbooks, the AI learns directly from our messy, real-world conversations.
It's like learning on the job instead of just in the classroom.
3/12
Here's how it works. When you say, "That's not right, add more statistics," the AI doesn't just try again from scratch.
It creates a preference pair:
👎 The original, unhelpful response.
👍 A new response that incorporates your feedback.
It learns from the correction itself.
4/12
This is already a huge leap. The AI is learning to adapt in real-time based on your specific needs in that moment.
But that's not even the most interesting part.
What about making the AI feel like it actually knows you across conversations?
5/12
This is where it gets brilliant. The system creates a "user persona" by summarizing your entire chat history.
Do you prefer casual or formal tones?
Do you like bullet points or long paragraphs?
Do you ask for code, or for poems?
It builds a profile of your unique preferences.
6/12
Now, when you ask a question, the AI doesn't just give a generic answer.
It generates several options and uses your "persona" to pick the one you're most likely to prefer. It's aiming for personalized quality, not just general correctness.
(I know, right?)
7/12
Now, you might be thinking: "But my chats are messy and full of typos!"
The researchers knew this. A critical part of the system is a quality filter that sifts through the noise to find the genuinely useful feedback, so the AI doesn't learn bad habits from our chaotic conversations.
8/12
And it works. In tests, models trained with RLHI were significantly better at personalization and instruction-following.
They even got better at reasoning tasks just by learning from simulated users pointing out mistakes in math problems.
9/12
So what does this mean for you?
It means the future of AI assistants might feel a lot less like a clunky tool and more like an adaptive partner that learns your style.
Next time an AI seems to remember your preferences, this is the kind of tech making it happen.

14
36
248
18,302
Yunmin Cha retweeted

8 Oct 2025
I'm at COLM! I'm doing:
- COCONUT poster (Tues 11am)
- Multi-Token Attention poster (Weds 11am)
- 🐏Organizing RAM 2 workshop🐏(Friday)
facebookresearch.github.io/R…
Reasoning, Attention & Memory – 10 Years On.
Invited speakers:
-Yoshua Bengio, Univ. of Montreal
-Juergen Schmidhuber, KAUST
-Kyunghyun Cho, NYU & Prescient Design
-Yejin Choi, Stanford & NVIDIA
-Azalia Mirhoseini, Stanford
-Sainbayar Sukhbaatar, Meta
14
147
11,177
8 Oct 2025
this is so cute
7 Oct 2025

My son today: "Papa, when you don't know anything, you ask Gemini?"
I said yes, and then I asked, "How do you know this?"
He said, "I often hear you say 'Hey Gemini, Hey Gemini' when you are in your office room"
Then he asked, "Can I also have it on my phone when I grow up?"
2
260
8 Oct 2025
imo they didn’t.


1
242
Yunmin Cha retweeted

7 Oct 2025
no more designing data intensive applications :(
55
711
10,395
341,337
8 Oct 2025
thank you and welcome new followers!
I don’t really check the app frequently so it’d be great if you let me know that you want me to follow you back with brief self introduction and interests. thank you again!
1
3
505
Yunmin Cha retweeted
7 Oct 2025
“7M parameters achieve 45% on ARC-AGI”?
Not exactly.
1000× data augmentation
1000× ensemble voting
3.75× recursive compute
That’s 7M × 480,000 forward passes — not tiny, just time-hungry.
The result isn’t less is more, it’s more is more at test time.
6
5
231
19,336
8 Oct 2025
Your research gives a multilingual stress test for long-context behavior, not just english!
the "no-needle" option is also brilliant, surfacing an important failure mode (models being trigger-happy about saying "nothing's there")
Further my opinions are continued...
5 Mar 2025

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇

1
4
539
8 Oct 2025
4. the headline “English 6th, Polish 1st” is intriguing, but it doesn’t prove those languages are inherently “easier” for long-context reasoning. It could be training data mix, tokenization, or instruction phrasing.
1
1
120
8 Oct 2025
Overall, The research itself is an interesting work! I'd be looking forward to the following works.
1
104