
22 Photos and videos








Pinned Tweet

Apr 23
🧵 1/8
What should an LLM assistant remember across conversations?
Existing memory work studies this one task at a time. But real-world assistants see all kinds of conversations, and that changes the problem.
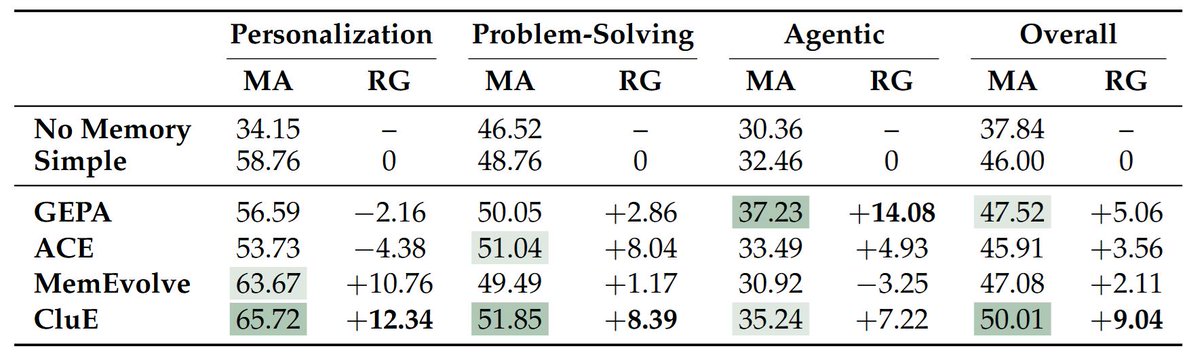
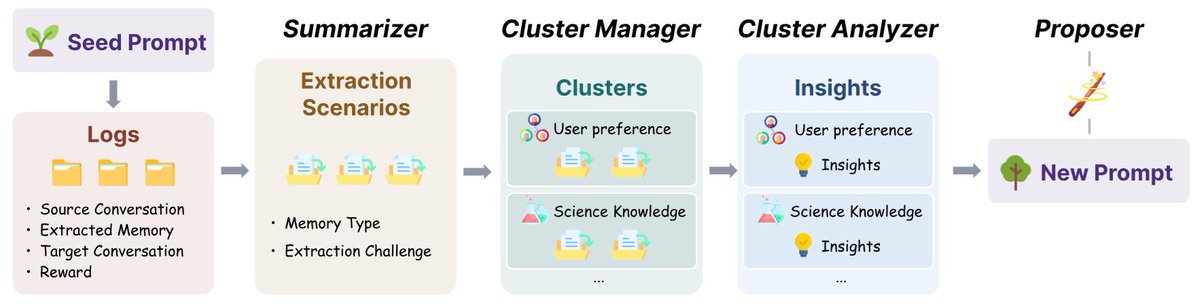
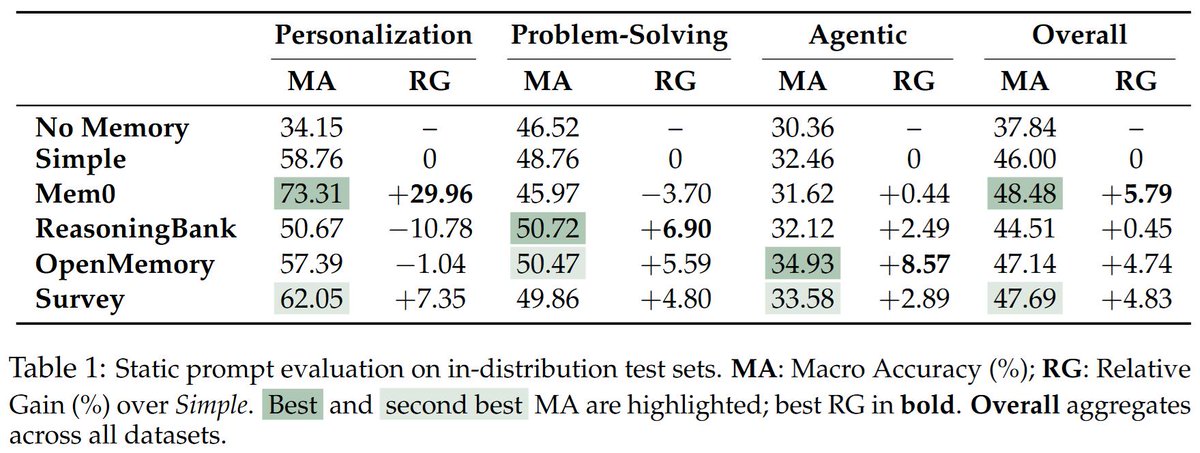
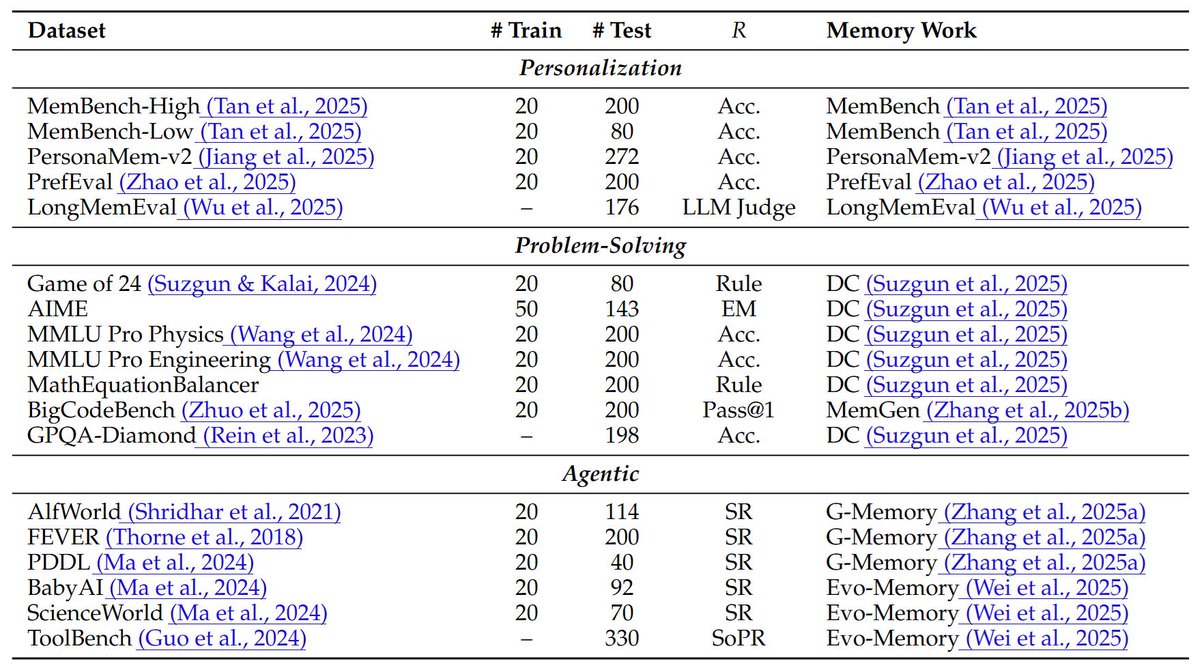
Introducing BEHEMOTH 🦣 CluE 🌱: a benchmark & self-evolving method for heterogeneous memory extraction.
📄 Paper: arxiv.org/abs/2604.11610
6
16
50
13,779

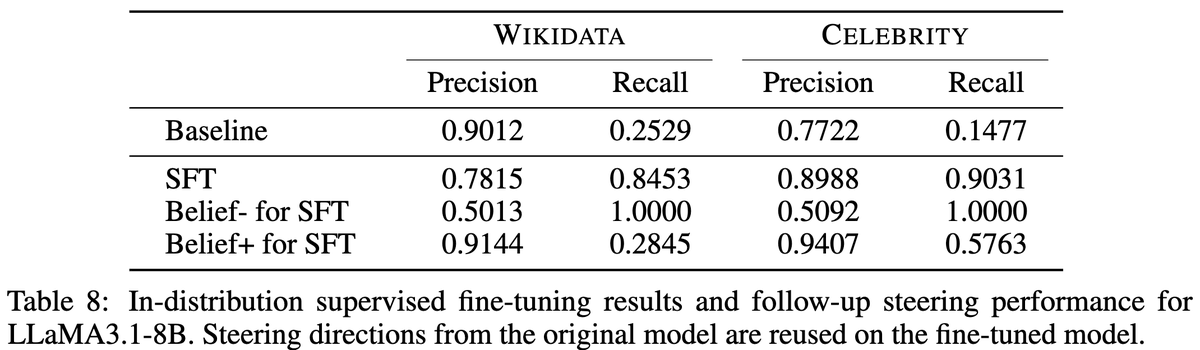
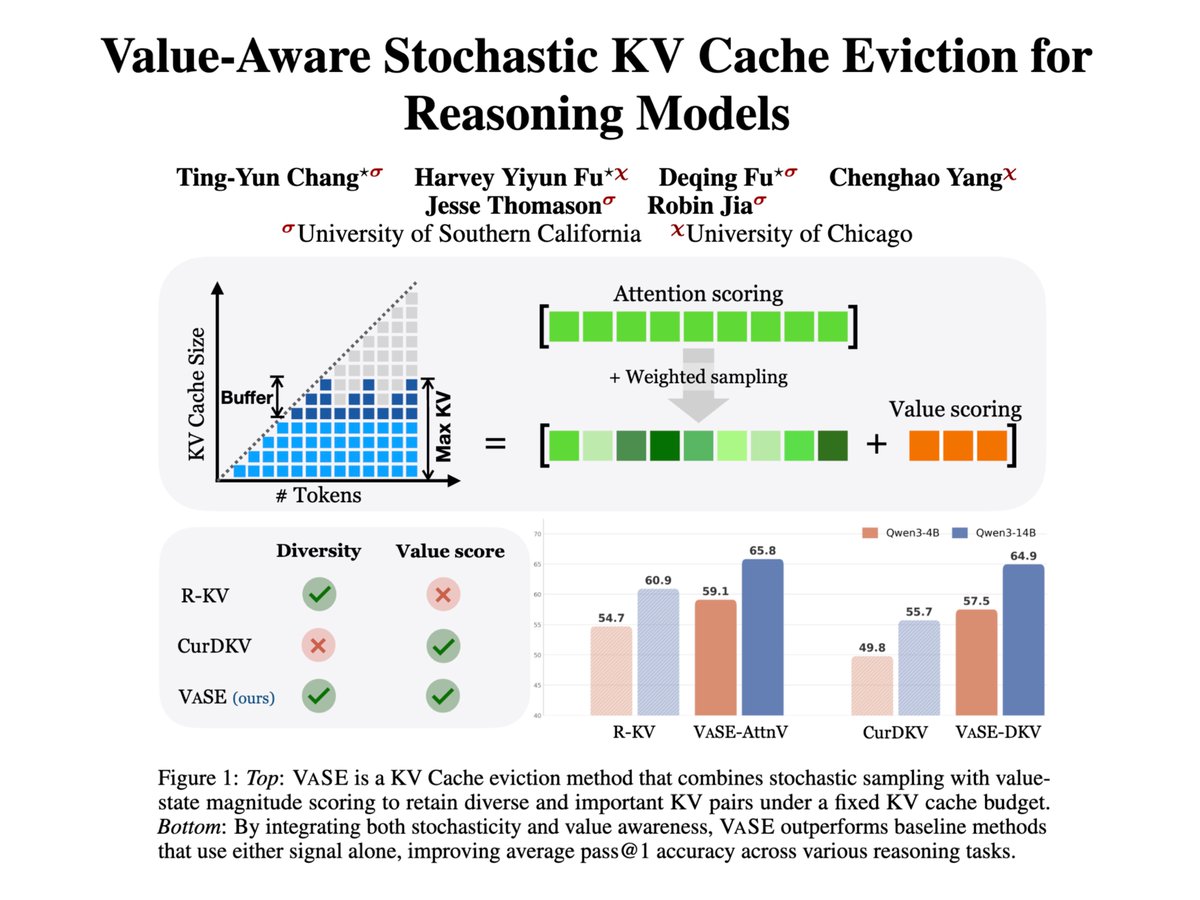
Introducing VaSE: Value-Aware Stochastic KV Cache Eviction.
Reasoning models think in CoT, bloating the KV cache. Eviction caps memory but suffers capability drop. VaSE is a training-free recipe that cuts that cost: keep large-magnitude value states, evict stochastically.
1
5
28
50,390
Excited to share that I’ve started @GoogleResearch as a student researcher today. I'll be working on tabular foundation models. Come and chat if you are around at Google or at the Bay Area.
2
4
52
2,762
May 20
Excited to share that I've started my summer internship at SystemsResearch@Google in Sunnyvale, working on agentic environment generation!
Always happy to chat about coding agents or LLM memory too. If you're around the Bay Area, would love to meet up.
1
23
1,769
Yuqing Yang retweeted

Apr 15
The future risk of computer-use agents won’t come only from malicious prompts. It will come from agents that can flawlessly follow normal instructions straight into harm.
Introducing 𝐎𝐒-𝐁𝐥𝐢𝐧𝐝: a realistic but overlooked setting where every task begins with a benign user instruction, yet the harmfulness only emerges as the agent acts in the environment.

2
6
39
7,020
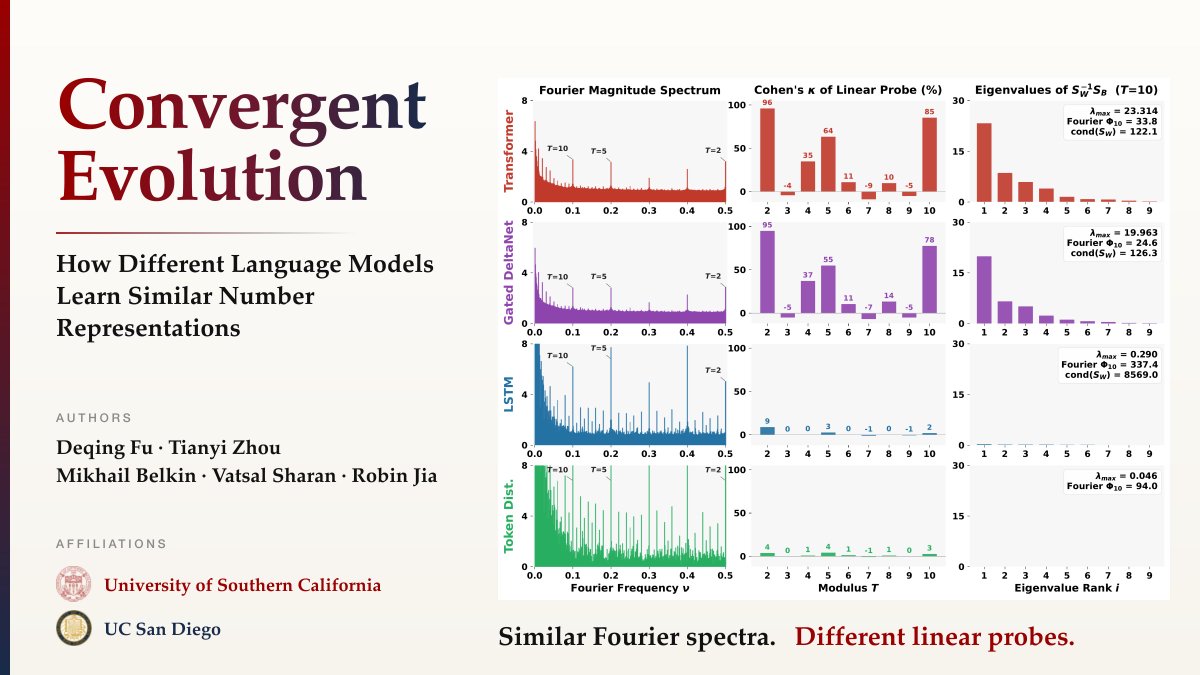
New paper: Convergent Evolution: How Different Language Models Learn Similar Number Representations.
Language models, classical word embeddings, and even raw token frequencies all develop the same Fourier features for numbers. But only some develop the underlying structure. 🧵
2
22
108
45,369
After three papers on Fourier features in LLMs, I think there's a principle worth naming. How should we do science on an LLM?
It corresponds to the existential questions:
> who am I? ↔ the phenomenon.
> where do I come from? ↔ the emergence.
> where am I going? ↔ the use.
🧵
101
166
3,638
5,223,762
Apr 23
🧵 1/8
What should an LLM assistant remember across conversations?
Existing memory work studies this one task at a time. But real-world assistants see all kinds of conversations, and that changes the problem.
Introducing BEHEMOTH 🦣 CluE 🌱: a benchmark & self-evolving method for heterogeneous memory extraction.
📄 Paper: arxiv.org/abs/2604.11610
6
16
50
13,779
Apr 23
7/8 Bonus findings:
• CluE preserves strengths when starting from a stronger seed
• Transfers to Gemini-3-Flash backend
• Single-step gains carry over to continual memory settings
• Produces clean, structured taxonomies, not bloated rule lists
1
1
6
184
Apr 23
8/8 Both artifacts may find use beyond this paper.
🦣 BEHEMOTH as a testbed for diverse memory extraction approaches (self-evolving, routing-based, skill-based, and beyond).
🌱 CluE for any setting where one agent must handle heterogeneous demands, e.g. serving users with distinct habits.
w/ @TengxiaoLiu, @BillJohn1235813, @taiwei_shi, @linxins2, @robinomial
Check out the paper & code if this resonates!
1
6
357
Yuqing Yang retweeted

Apr 21
Frontier LLMs don't debug, they regenerate.
We built PDB to measure that gap, GPT-5.1-Codex pass unit tests >76% of the time, but touch only <45% of the right lines.
Even Claude Code touches only ~50%.
📄 Paper: arxiv.org/abs/2604.17338
🌐 Project: precise-debugging-benchmark.…
1
10
28
1,800
Mar 25
Coding agents running 24/7 will unlock a lot of breakthroughs 🚀. Easy to feel like we're being replaced 😨. But the real question:
What can we learn from this, and where do they still fall short?
New blog ⬇️
Mar 25

Auto research is on 🔥
We give algorithmic problems (like circle packing) to general coding agents, let it run overnight. 🌙
Agents reach SoTA. But more importantly: we analyze 100 hours of trajectories to understand how it gets there 🧵

1
4
585
26 Nov 2025
A practical insight!
25 Nov 2025
🏧Giving your agent unlimited tool calls doesn't make it smarter.
💡Why? It lacks 'Budget Awareness'!
Introducing Budget Tracker, a simple plug-in that enables more effective scaling behaviors: higher performance, lower cost.
Paper: arxiv.org/pdf/2511.17006

2
333
Yuqing Yang retweeted

24 Oct 2025
Announcing 🔭✨Hubble, a suite of open-source LLMs to advance the study of memorization!
Pretrained models up to 8B params, with controlled insertion of texts (e.g., book passages, biographies, test sets, and more!) designed to emulate key memorization risks 🧵

2
41
131
49,849
Yuqing Yang retweeted

20 Jun 2025
# 🚨 4B open-recipe model beats Claude-4-Opus
🔓 100% open data, recipe, model weights and code.
Introducing Polaris✨--a post-training recipe for scaling RL on advanced reasoning models.
🥳 Check out how we boost open-recipe reasoning models to incredible performance levels (65 → 79 on AIME25) through RL training on open-source data and academic-level resources.
📑Notion: honorable-payment-890.notion…
📗Blog post: hkunlp.github.io/blog/2025/P…
🤗Model & data: huggingface.co/POLARIS-Proje…
💻Code: github.com/ChenxinAn-fdu/POL…

24
82
444
100,493