
Assistant Professor @CSatUSC | Previously Visiting Researcher @facebookai | Stanford CS PhD @StanfordNLP
Joined June 2018
- Tweets 362
- Following 932
- Followers 4,776
- Likes 1,905
2 Photos and videos


Robin Jia retweeted

Hi all, mentoring junior students can be a special experience. Contrary to common wisdom, my mentorship style is that of "apprenticeship" and my junior students work side-by-side with me on the most important part of my most important project. My reflections are below... [1/2]
1
2
17
1,139
Robin Jia retweeted
Sadly I can't attend ICRA this year, but right now Mason @miaosenc is presenting our work PSALM-V at Poster 250. Come by and check it out! 🤖!
It's a project I'm really proud of: instead of hand-writing the symbolic rules a planner needs (PDDL pre-/post-conditions), PSALM-V lets an agent figure them out on its own by interacting with a visual, partially observed world. Mason would love to chat about it; go say hi! 👋
1
7
15
885
Robin Jia retweeted

Jun 4
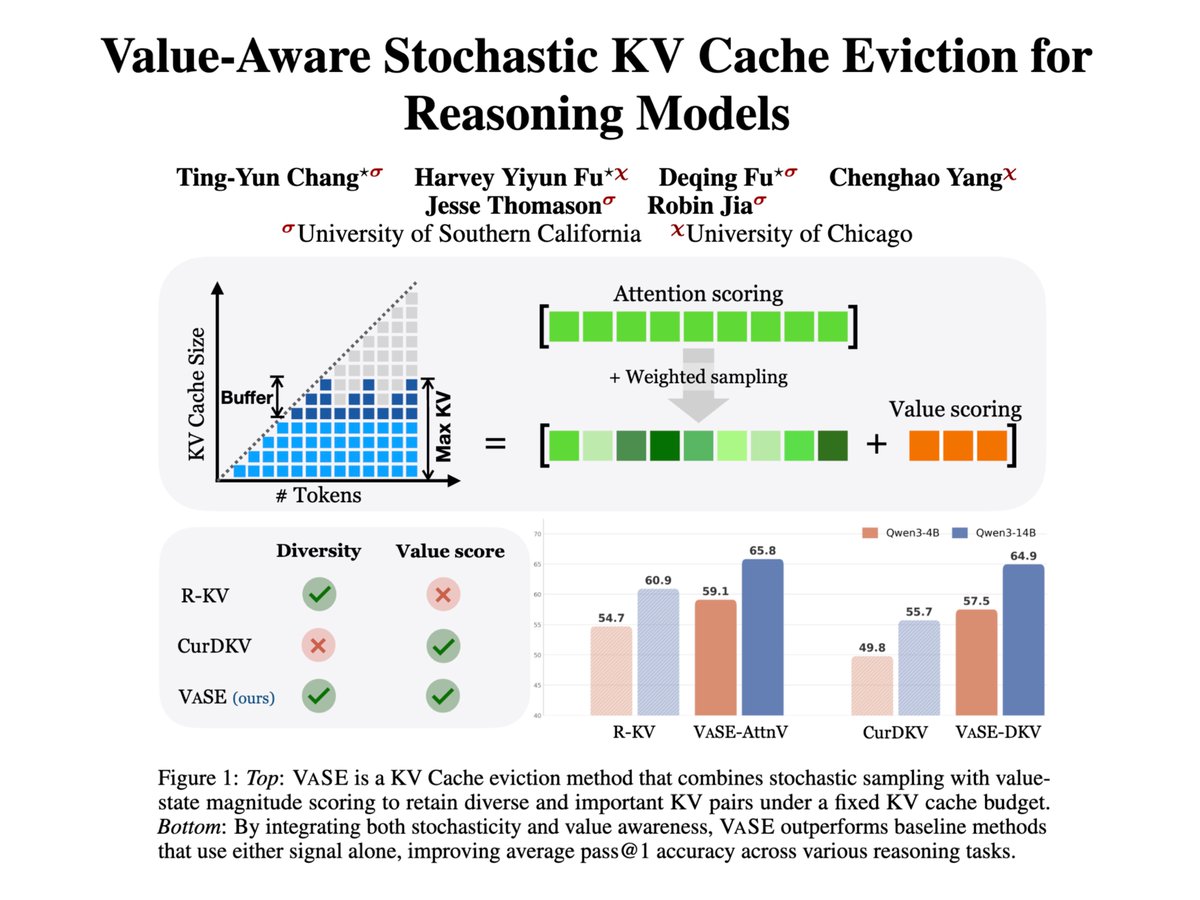
This is the final project of my PhD journey 🎓 I've thought a lot about how to make interp actionable in my previous projects. I believe efficiency follows naturally: when we have a deep understanding of the model, we can figure out where to be frugal w/o hurting model accuracy. The Attention Sink and LLM.int8() papers set great examples, and they deeply inspire our paper. Mirroring the findings on value-state drain, we find that large-range value states are equally important in KV cache eviction. Evicting these outliers causes reasoning models to enter an endless self-reflection loop, while keeping them in the cache maintains accuracy. I'm extremely grateful to my amazing coauthors and supportive advisors.


Introducing VaSE: Value-Aware Stochastic KV Cache Eviction.
Reasoning models think in CoT, bloating the KV cache. Eviction caps memory but suffers capability drop. VaSE is a training-free recipe that cuts that cost: keep large-magnitude value states, evict stochastically.
2
4
22
2,228
Robin Jia retweeted

Jun 4
Excited to share our new paper on KV Cache eviction!
We propose a new recipe that is simple and effective: 1. keep those value states with large magnitude, 2. add some stochasticity to the eviction process.
Combined, VaSE consistently outperform previous eviction methods with high throughputs, while maintaining constant memory footprints.
Huge thanks to all collaborators @CharlotteTYC, @DeqingFu, @chrome1996, and advisors @_jessethomason_ and @robinomial
Introducing VaSE: Value-Aware Stochastic KV Cache Eviction.
Reasoning models think in CoT, bloating the KV cache. Eviction caps memory but suffers capability drop. VaSE is a training-free recipe that cuts that cost: keep large-magnitude value states, evict stochastically.
3
10
2,538

Introducing VaSE: Value-Aware Stochastic KV Cache Eviction.
Reasoning models think in CoT, bloating the KV cache. Eviction caps memory but suffers capability drop. VaSE is a training-free recipe that cuts that cost: keep large-magnitude value states, evict stochastically.
1
5
28
50,388
Robin Jia retweeted
🚨 [New preprint] Can AI assistants hurt the very people who depend on them?
Raine v. OpenAI alleges ChatGPT contributed to a teen's suicide; OpenAI's 2025 "sycophancy" retrospective on GPT-4o. The pattern: harm comes not from capability failures, but from the social dynamics of how models talk to us, especially when users open up.
We introduce EUDAIMONIA, a benchmark grounded in a Social AI Design Code rooted in real-world harm cases.
🌐 Project page: eudaimonia-bench.github.io/
📄 Paper: arxiv.org/abs/2605.30654

3
5
22
1,833

May 29
Being Johnny’s PhD advisor has not only been a great privilege, but it has forever changed my research vision. His work combining AI, law, and statistics opened my eyes to how technical research can guide policy and promote AI accountability. Excited for his next work as Dr. Wei!

Hi all, I defended my PhD thesis. My thesis in two sentences:
Current AI measurement takes LLMs as fixed objects, which constrains us to observational measurement. *Spiking* the training data (inserting certain data at known rates), enables statistically principled measurement.

56
6,781
Robin Jia retweeted
Hi all, I defended my PhD thesis. My thesis in two sentences:
Current AI measurement takes LLMs as fixed objects, which constrains us to observational measurement. *Spiking* the training data (inserting certain data at known rates), enables statistically principled measurement.
28
6
176
18,041
Robin Jia retweeted

May 28
Does your GPT-5.5 also love Valparaíso in Chile 🇨🇱 !?
Ask it to “Name a random city in the world”.
You might expect a broad sample from thousands of cities.
Instead, models collapse to the same small set of answers again and again. 😵💫
But why do LLMs lack diversity? Why are they not reliable random number generators? Why do they still struggle with genuinely creative writing? And why do decoding tricks like temperature, top-k, and top-p often fail to recover meaningful diversity?
We have some answers in our new paper!
🧪 Demo: diversitycalibration.github.…
📄 Paper: arxiv.org/abs/2605.11128
1
3
9
2,032
Robin Jia retweeted
🧵[1/5] Works on test set contamination focus on detection, but we show *correction* of inflated test scores is possible. arxiv.org/abs/2605.24818
Our proposal is to spike the training data and insert some test examples at known rates. The spiked examples are used to calibrate...
1
10
33
4,672
Robin Jia retweeted

Just as single cells became multicellular life, 8B brains are now joining with AI to form a collective superintelligence.
At @USC's Institute on Ethics and Trust in Computing inaugural summit, @robinomial, Jinchi Lv, @paria_rd and I discussed navigating this transition.



1
3
28
2,599

Today we’re releasing EMO, a new mixture-of-experts (MoE) model trained so modular structure emerges directly from data without human-defined priors.
EMO can use a small subset of its experts for a given task while keeping near full-model performance. 🧵

13
57
404
87,766
Robin Jia retweeted

MoEs are everywhere in frontier models, and they are deployed as a monolith system.
But many applications only need a narrow slice of capabilities, e.g., math, code, biomedical, etc.
So what if "modularity" is actually the missing opportunity for MoEs?
Today, we're releasing EMO: an end-to-end pretrained MoE where modularity emerges naturally, enabling selective use of experts!


Today we’re releasing EMO, a new mixture-of-experts (MoE) model trained so modular structure emerges directly from data without human-defined priors.
EMO can use a small subset of its experts for a given task while keeping near full-model performance. 🧵
7
73
530
115,334
Glad to share that this paper is accepted to #ICML 2026 @icmlconf with an updated title "Transformers Provably Learn Algorithmic Solutions for Graph Connectivity, But Only with the Right Data". 🥳
Why do Transformers fail at algorithmic reasoning? We find it's not a lack of power, but a capacity mismatch.
Our new preprint proves a tight, non-asymptotic bound: an L-layer model can only solve graph connectivity on graphs with a diameter up to exactly 3^L. arxiv.org/abs/2510.19753
🧵(1/N)

2
3
33
3,650
Robin Jia retweeted

Apr 30
EPSVec will see you at #ICML2026!!
Mar 11

𝗣𝗿𝗶𝘃𝗮𝘁𝗲 𝘀𝘆𝗻𝘁𝗵𝗲𝘁𝗶𝗰 𝘁𝗲𝘅𝘁 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 has had the same problem for a while: privacy, quality, or efficiency - pick two 😵💫
We think 𝐄𝐏𝐒𝐕𝐞𝐜 changes that 🚀
Paper: arxiv.org/abs/2602.21218

1
7
27
3,814
Robin Jia retweeted

Apr 23
🧵 1/8
What should an LLM assistant remember across conversations?
Existing memory work studies this one task at a time. But real-world assistants see all kinds of conversations, and that changes the problem.
Introducing BEHEMOTH 🦣 CluE 🌱: a benchmark & self-evolving method for heterogeneous memory extraction.
📄 Paper: arxiv.org/abs/2604.11610

6
16
50
13,779
After three papers on Fourier features in LLMs, I think there's a principle worth naming. How should we do science on an LLM?
It corresponds to the existential questions:
> who am I? ↔ the phenomenon.
> where do I come from? ↔ the emergence.
> where am I going? ↔ the use.
🧵
101
166
3,637
5,223,762
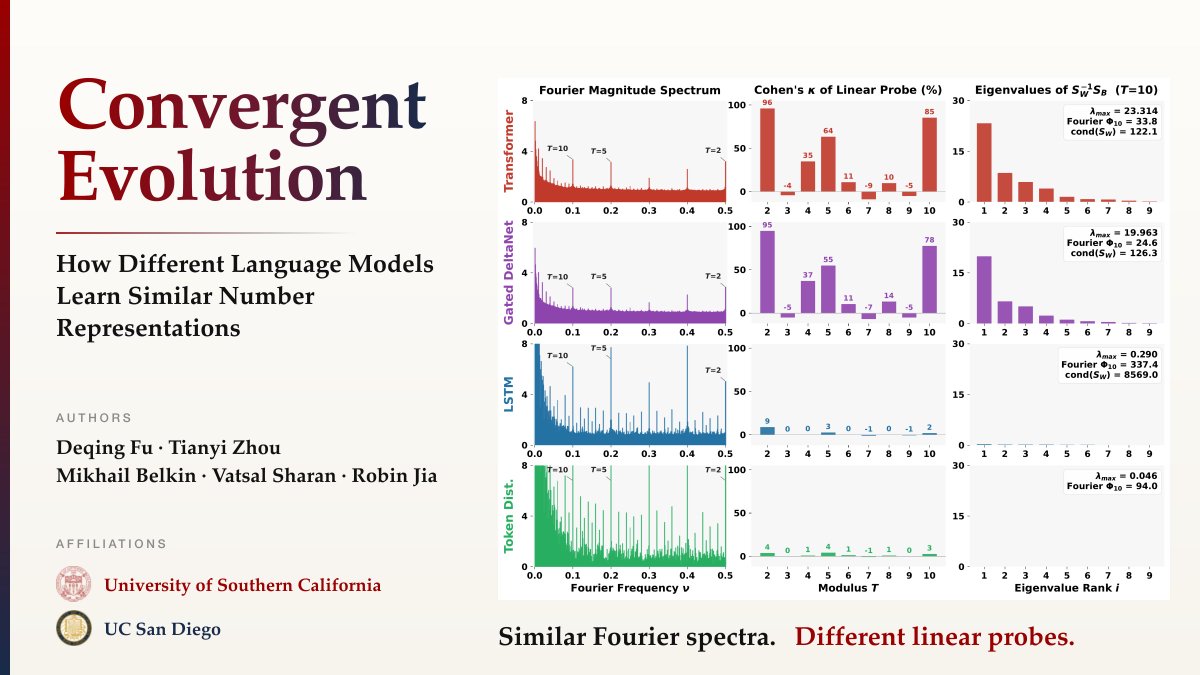
New paper: Convergent Evolution: How Different Language Models Learn Similar Number Representations.
Language models, classical word embeddings, and even raw token frequencies all develop the same Fourier features for numbers. But only some develop the underlying structure. 🧵
2
22
108
45,369
Robin Jia retweeted

Apr 21
Frontier LLMs don't debug, they regenerate.
We built PDB to measure that gap, GPT-5.1-Codex pass unit tests >76% of the time, but touch only <45% of the right lines.
Even Claude Code touches only ~50%.
📄 Paper: arxiv.org/abs/2604.17338
🌐 Project: precise-debugging-benchmark.…
1
10
28
1,800
Apr 20
Excited to announce that Hubble, our new language model suite for studying LLM memorization, was recently featured in @ScienceMagazine ! Hubble has also received an oral presentation slot at ICLR; if you're there, check out @johntzwei and @Aflah02101 's presentation on Saturday!
3
12
89
6,366
Apr 20
Article: science.org/content/article/…
Website: allegro-lab.github.io/hubble…
Big thanks to Peter Hall for the article, as well as @NSF NAIRR and @nvidia for the compute!
1
3
7
1,086