
223 Photos and videos









Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
292
850
6,968
1,336,199
Z.ai retweeted

Jun 13
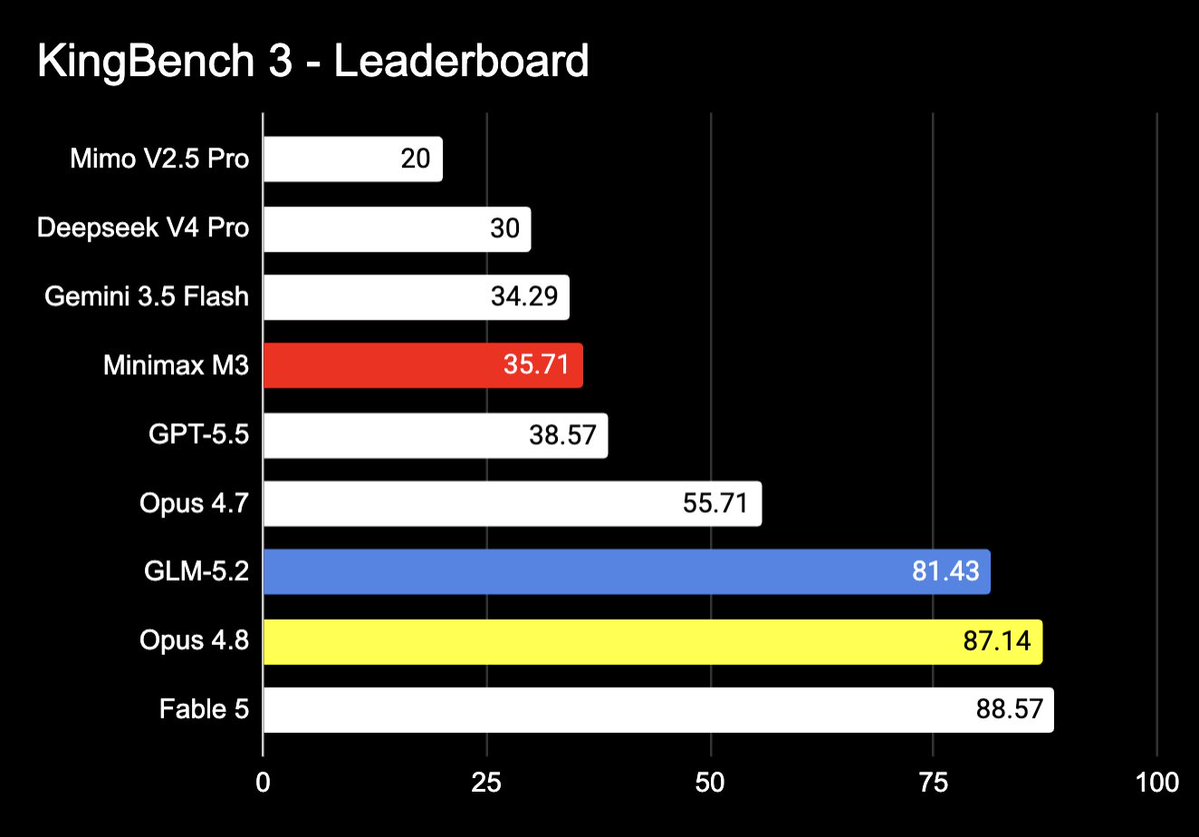
GLM-5.2 on KingBench (3).
Thoughts: The model has superb taste. It is greater at UX than UI. The code is always very clean. It is great at One-shot wonders. I asked it to fine-tune a whole local model and it did it in 30mins!
This is just a great model to use all-round.
1/n
54
103
1,554
175,822
Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
292
850
6,968
1,336,199
Z.ai retweeted

Jun 13
Thanks for all the feedback. GLM-5.2 will begin rolling out to all Coding Plan users in 3 hours.
Jun 13

Help us shape the next GLM release: what should we prioritize most?
127
114
1,737
271,399
Z.ai retweeted
Jun 13
Help us shape the next GLM release: what should we prioritize most?
33%
Longer context window
33%
MIT-licensed open weights
34%
No price increase
1,861 votes • 15 hours
197
17
308
200,316

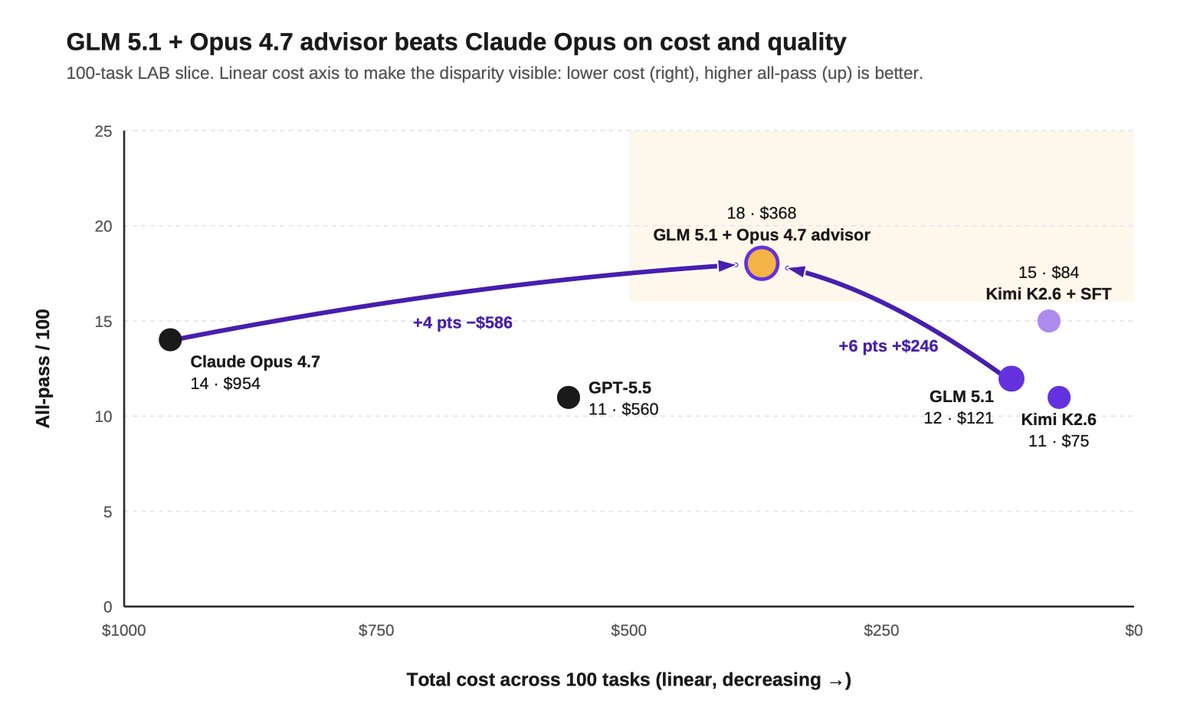
We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
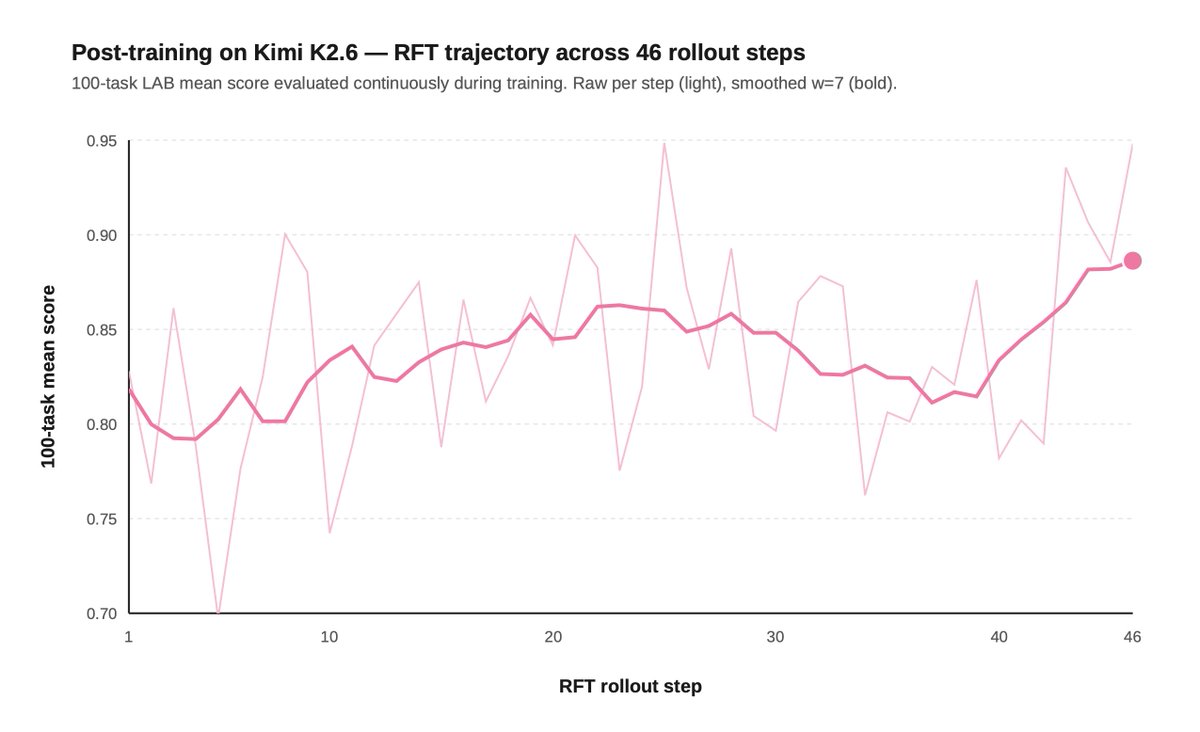
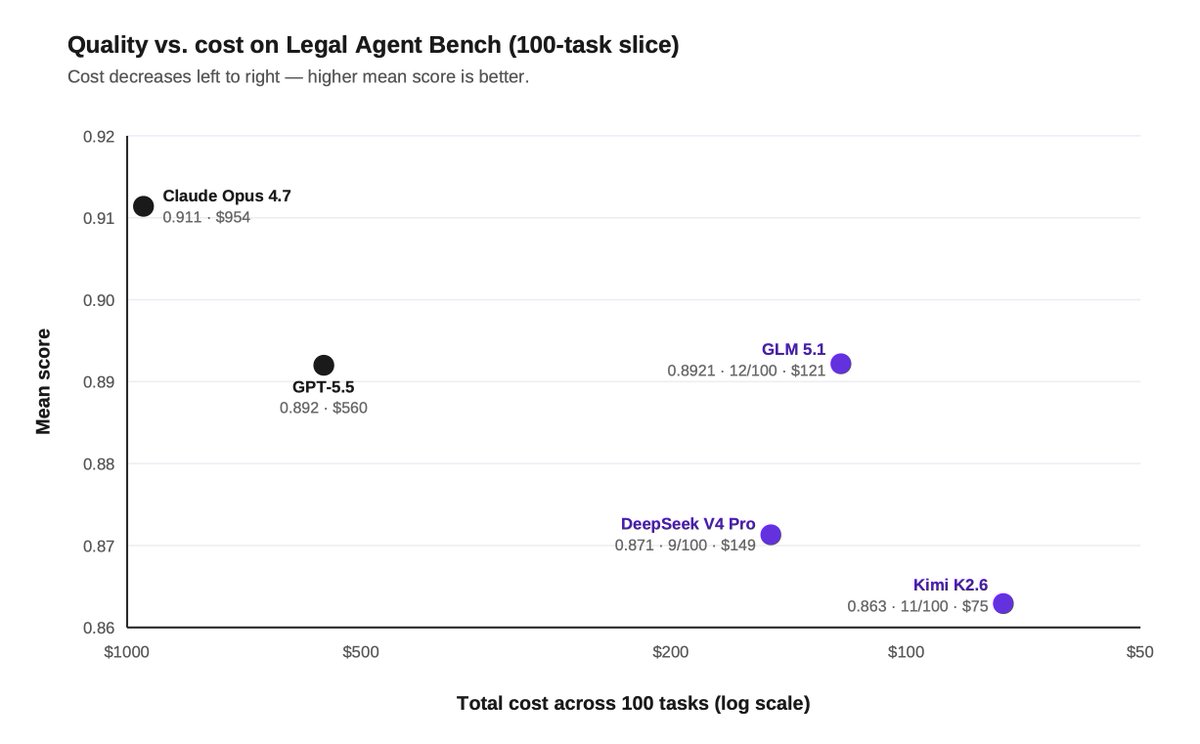
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
40
69
869
441,500
Z.ai retweeted

May 18
GLM-5.1 from @Zai_org is now live on OrcaRouter
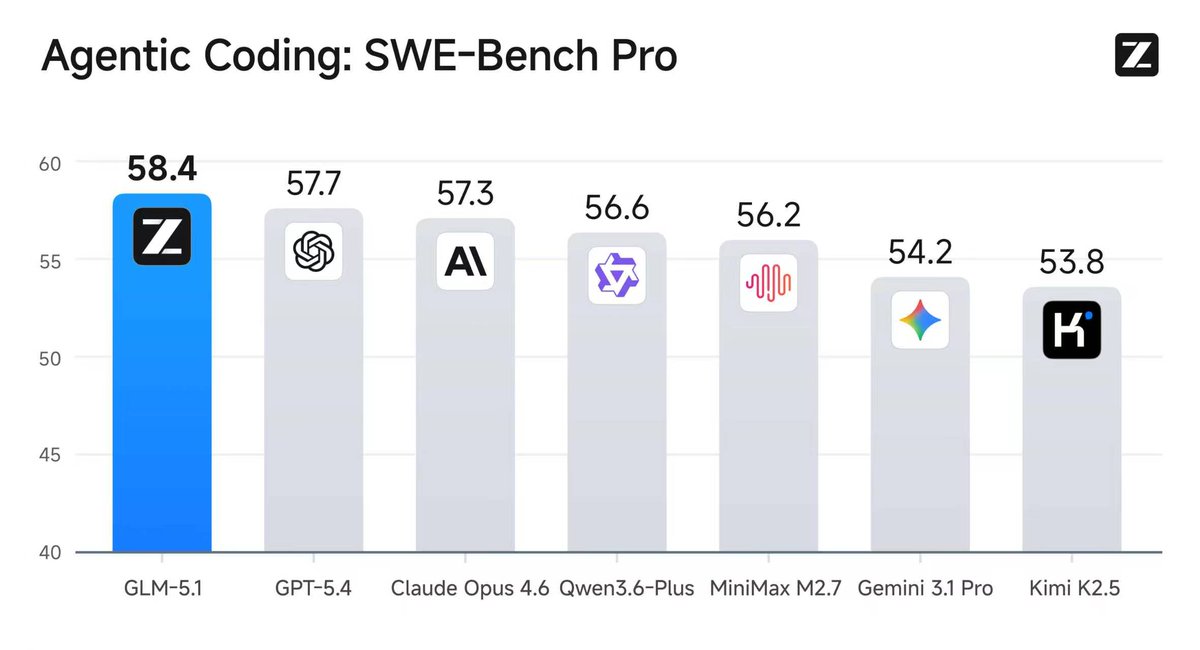
• #1 open-source model on SWE-Bench Pro
• Beats closed source models on real-world repo repair benchmarks
• MIT licensed
• 200K context
• Built for long-horizon agentic coding
We’ve also seen strong results using GLM-5.1 inside OrcaRouter’s adaptive routing strategy as a fallback coding model.
Open-source coding models are getting scary good. orcarouter.ai/models/z-ai/gl…
12
10
269
37,609
Z.ai retweeted

May 17
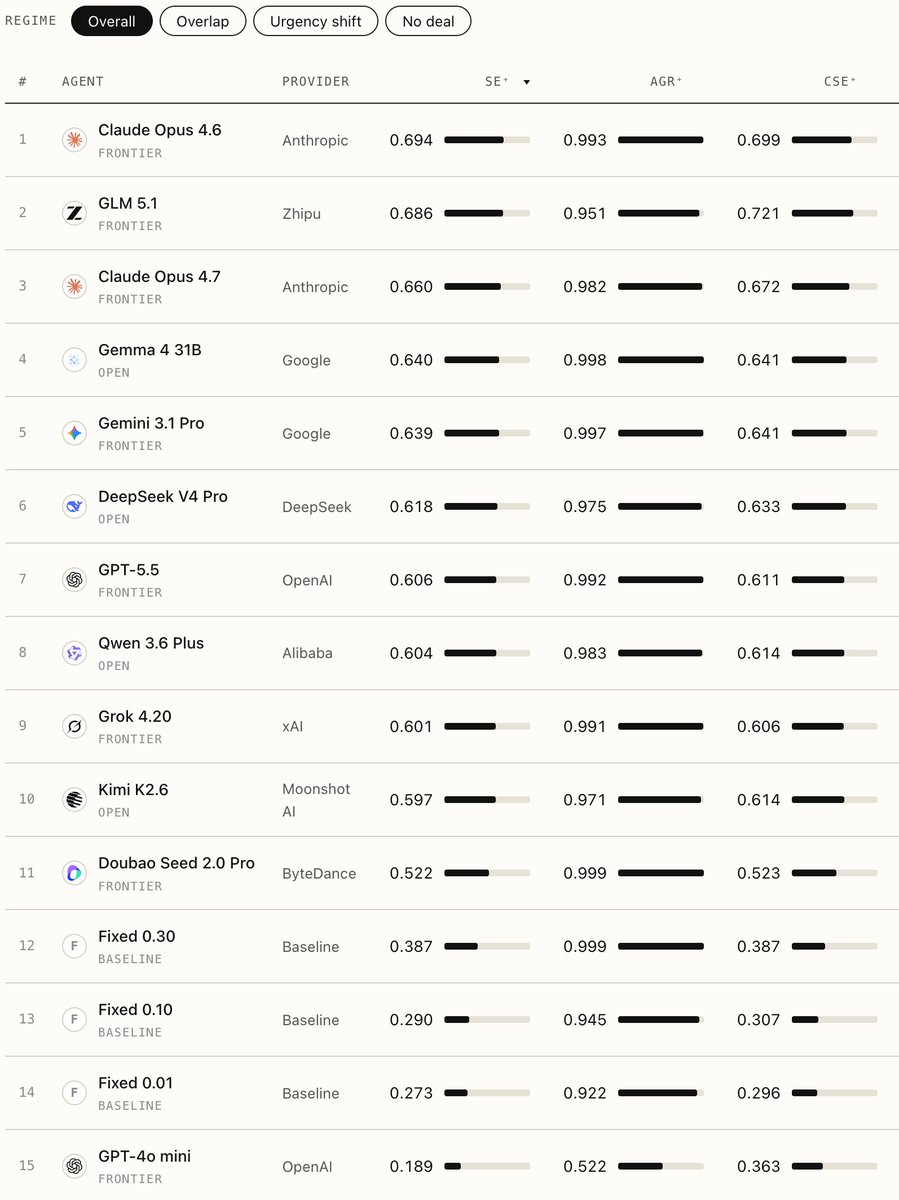
We built TERMS-Bench, a three-tier benchmark for LLM agents in real-world economic negotiation. No LLM-as-judge, no outcome rubrics: the environment itself is the verifier.
🏆Among frontier models, @AnthropicAI Claude Opus 4.6 #1, @Zai_org GLM 5.1 #2.
✨Surprisingly strong: @GoogleDeepMind @googlegemma Gemma 4 31B — best open-weight, holds up as negotiations get harder.
🔗 terms-bench.github.io
22
27
251
52,962
Z.ai retweeted

May 15
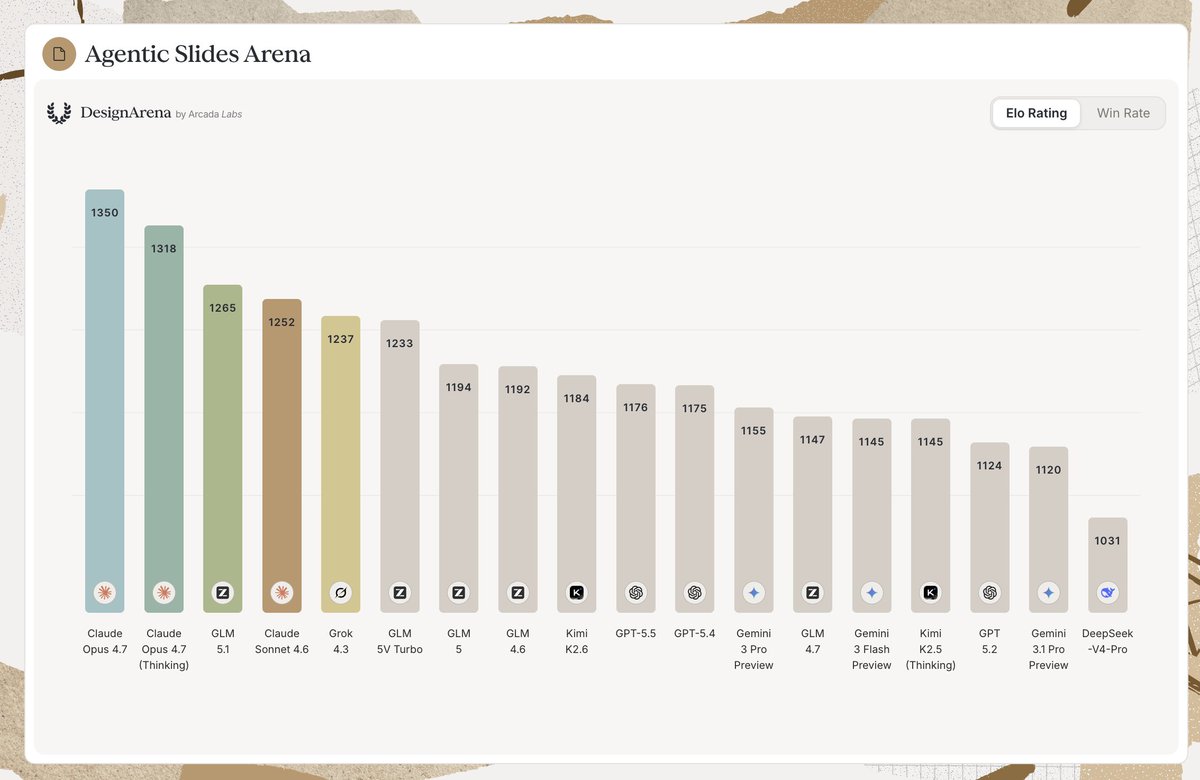
BREAKING: The results are in for Slides Arena... @AnthropicAI and @Zai_org models continue to lead the way in soft-verifiable domains
1st: Opus 4.7 by @AnthropicAI
2nd: Opus 4.7 (Thinking) by @AnthropicAI
3rd: GLM 5.1 by @Zai_org
Huge congrats to @AnthropicAI and @Zai_org for establishing the SOTA for Agentic Slides
14
27
260
62,436
Z.ai retweeted
May 14
See you in Singapore.
BTW, I'm starting to look more and more like our logo.

20
9
146
22,778
Z.ai retweeted

May 12
GLM models are now live on @tensorix_ai
We’re partnering to bring cost-efficient frontier AI models to developers, startups, and enterprises across Europe and beyond — and to back the Sovereign AI ecosystem with serious inference muscle.
Four GLM models are now available
• GLM-5.1 → SOTA open-source performance advancing long-horizon AI agents to new levels
• GLM-5 → New generation language base model
• GLM-5-Turbo → agent-ready, built for coding and agentic use cases
• GLM-5v-Turbo → multimodal reasoning across code, images, documents, and diagrams
Go build something cool.
Build with GLM on Tensorix: tensorix.ai
12
13
274
24,494
Z.ai retweeted

May 11
🧵 Slime: The Most Elegant & Comfortable RL Training Framework Ever
A deep dive into why Slime redefines LLM RL training with clean architecture & production-grade engineering ✨
Insights from Zhihu contributor Xavier
📌 What Is Slime In One Sentence?
Slime is a streamlined RL training framework built on SGLang (Inference) Megatron (Training) Ray (Orchestration).It’s not just a simple stack—it stitches top-tier open-source projects together with perfectly polished interfaces.Core design philosophy: Fully decouple training & inference, connected via streamlined data flow.
Compared to veRL / OpenRLHF:
✅ Native SGLang backend → high concurrency, continuous batching, prefix caching (no messy vLLM wrapper)
✅ Native Megatron backend → full TP/PP/EP/CP parallelism, seamless MoE training
✅ Lightweight Ray scheduling → Placement Group Remote Actor (no bloated Ray Train)
🏗️ Global Architecture: 3 Modules, One Pipeline
🖥️ Ray Cluster Core Workflow:Data Buffer (Prompt Manager → Buffer & Filter)↔️ Rollout (SGLang → Sampling RM Scoring Filtering)↔️ Training (Megatron → Actor/Critic PPO/GRPO)
🔁 Simplified Core Training Loop
1.Allocate GPU resources via Placement Group
2.Launch SGLang rollout engine
3.Initialize Megatron Actor/Critic models
4.Sync initial weights to SGLang
5.Repeat 3-beat cycle:
Generate (SGLang) → Train (Megatron) → Sync Weights
🎯Elegance = ultra-simple top-level logic, all complexity encapsulated inside modules
🎛️ 4 Core Design Flexibilities
⚙️ Resource Scheduling: Colocate (shared GPU) / Disaggregate (separate GPU pools)
🔄 Training Mode: Synchronous / Asynchronous training
🧪 Sampling Logic: Standard sampling / Over-sampling / Multi-turn tool calling
🤖 Model Type: Dense / MoE, full tensor/pipeline/context parallel support
🔧 Plug & Play Customization (All Extensible)
Slime lets you customize every component via CLI params—no need to fork the repo 🛠️
Key Customization Points
✅ Custom Reward Model: Write an async func to define your own reward logic (easiest entry)
✅ Custom Generate Func: Control multi-turn dialogue, tool calling & external API integration
✅ Custom Rollout Func: Fully take over sampling concurrency & filtering logic
✅ Custom DataSource: Fetch prompts from API / local files / dynamic data streams
✅ Dynamic Filter: Discard low-value sample groups (e.g., zero-variance GRPO samples)
✅ Custom Loss Function: Rewrite PPO/GRPO loss calculation freely
All custom code loads dynamically via --custom-xxx-path config 📝
🚀 Ray GPU Scheduling Magic
Two deployment modes for all cluster scales:
🔹 Colocate Mode: Train & inference share GPUs → high utilization, ideal for small 8-card servers
🔹 Disaggregate Mode: Independent GPU pools → train-infer overlap, perfect for multi-node clusters
Slime stabilizes Ray Placement Group GPU mapping via IP/GPU ID sorting to guarantee reproducibility 🔒
⚡ SGLang Rollout Engine Internals
3-layer abstraction:RolloutManager → RolloutServer → ServerGroup → SGLangEngine
Standout design highlights:
🔸 Over-sampling Dynamic Filter: Pre-sample extra data, filter invalid groups on the fly
🔸 Async Concurrent Sampling: Process completed groups immediately with FIRST_COMPLETED
🔸 Abort Mechanism: Stop redundant sampling once target data size is met, save compute
🔸 Singleton GenerateState: One-time tokenizer & connection initialization
🧠 Megatron Training Backend
Native support for mainstream RL algorithms:
✅ GRPO: No Critic needed, group-wise reward normalization (most popular)
✅ PPO: Classic Actor-Critic with GAE advantage estimation
✅ REINFORCE : Token-level baseline optimization
Seamless support for Dense & large MoE models with full parallelism 📊
🔄 Weight Sync: The Hard Engineering Solved
Two high-performance sync paths:
🔹 Colocate: IPC Gloo → intra-node low-latency weight transfer
🔹 Disaggregate: NCCL Broadcast → cross-node distributed sync
MoE OOM prevention: Chunked Bucket Weight Update → sync parameters in small batches, release memory instantly 🧩
💡 Core Takeaways
✨ Slime’s elegance lies in integrating mature top-tier stacks with clean decoupled design
✨ Minimal top-level logic, maximal internal engineering depth
✨ Fully pluggable customization for all RL scenarios (Math / Code / Agent / MoE)
✨ Optimized for both small single-node & large multi-node clusters
🔗Full article:zhuanlan.zhihu.com/p/2035357…
#LLM #RLTraining #SGLang #AIInfrastructure #MoE #MachineLearning
1
6
61
16,437
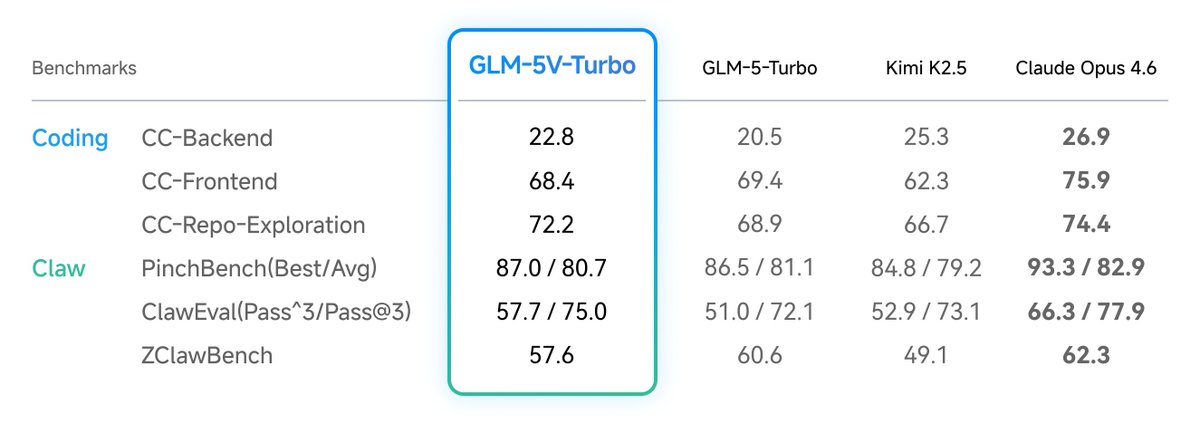
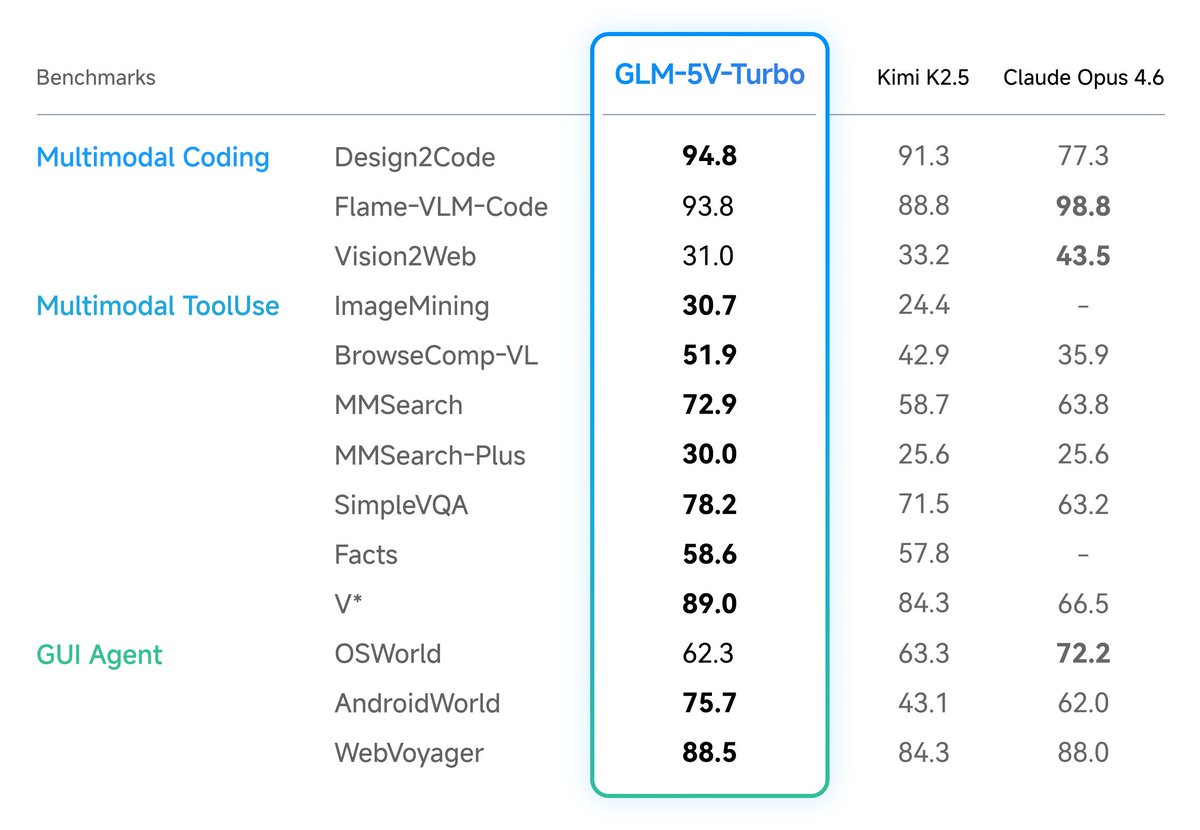
GLM-5V-Turbo Tech Report: Toward a Native Foundation Model for Multimodal Agents
This report summarizes the main improvements behind GLM-5V-Turbo across model design, multimodal training, reinforcement learning, toolchain expansion, and integration with agent frameworks. These developments lead to strong performance in multimodal coding, visual tool use, and framework-based agentic tasks.
arxiv.org/abs/2604.26752
35
131
909
69,503
Technical highlights:
CogViT Vision Encoder
- Built with dual-teacher distillation: SigLIP2 for semantics, DINOv3 for texture. A two-stage recipe, masked modeling, then contrastive pretraining, with QK-Norm for attention stability at scale.
Multimodal Multi-Token Prediction (MMTP)
- Three ways to pass image tokens into the MTP head were compared. The chosen approach uses a shared <image> token, removing the need to propagate visual embeddings across pipeline stages and improving training stability.
Broad Training Across Perception, Reasoning, and Agent Capability
- Vision and language are fused from pre-training onward, with emphasis on multimodal code. Joint RL across 30 task categories yields consistent gains with weaker cross-domain interference than SFT.
Multimodal RL at Scale
- Infrastructure rebuilt along four axes: unified task and reward abstraction, full-pipeline asynchrony, fine-grained memory management for vision modules, and topology-aware partitioning for variable-length visual inputs.
1
31
8,103
Coding plan users interested in early experimentation can fill out this form:
docs.google.com/forms/d/e/1F…
3
24
7,397
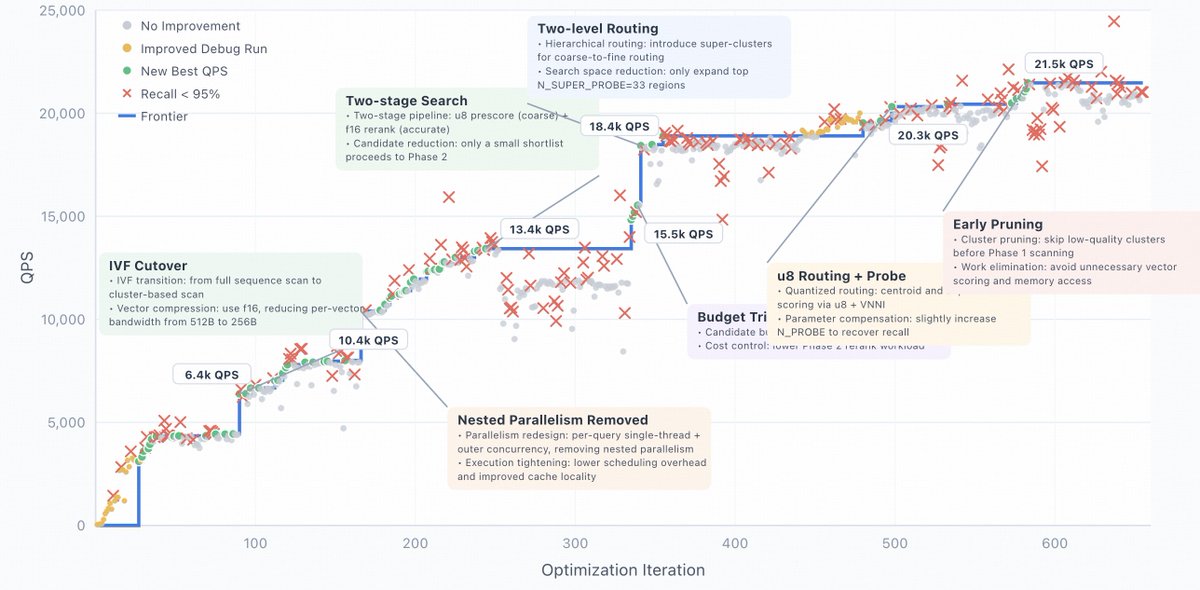
Scaling laws push model capability forward. But whether that capability becomes reliable in production depends on how we handle Scaling Pain.
z.ai/blog/scaling-pain
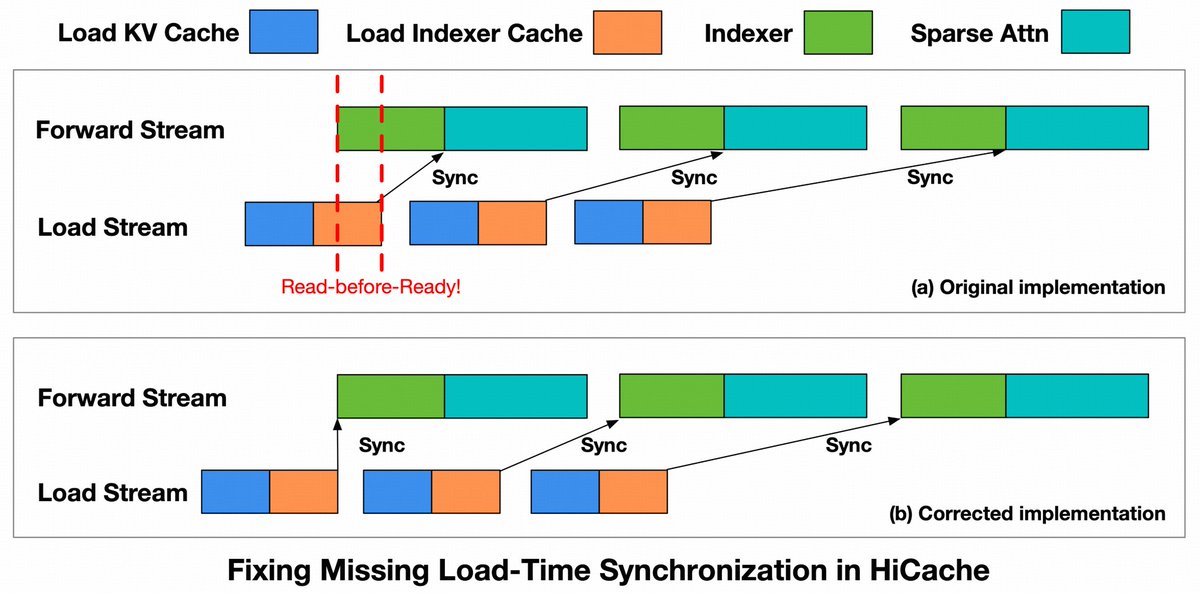
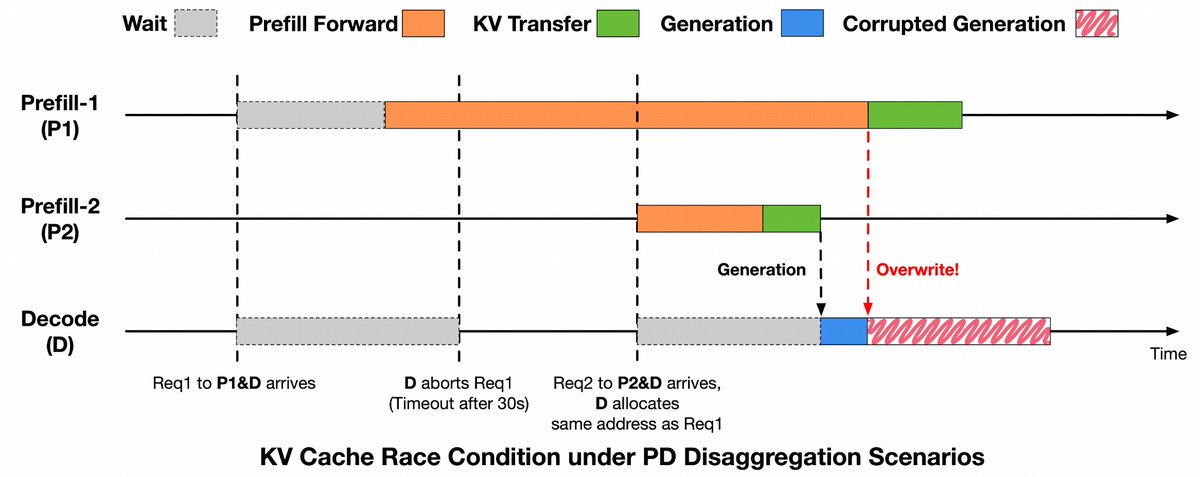
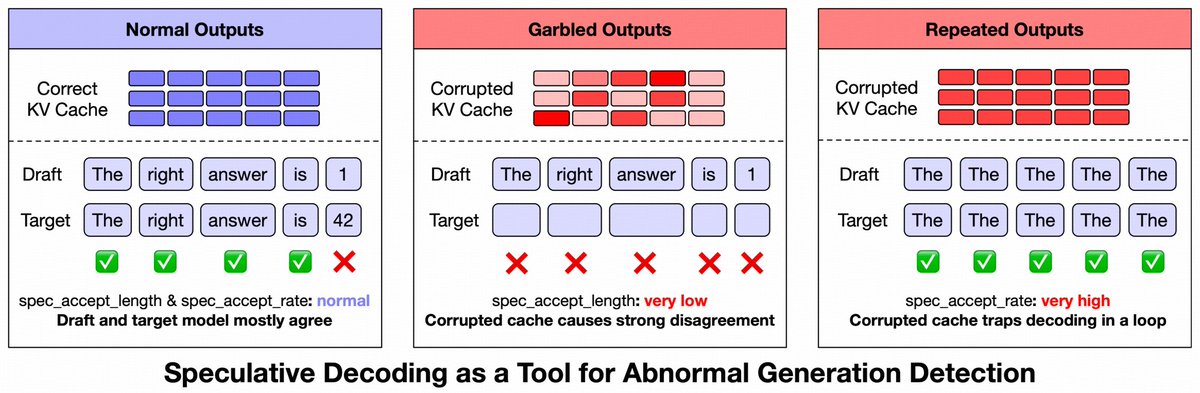
In our latest blog, we share how we debugged GLM-5 serving at scale: reproducing rare garbled outputs, repetition, and rare-character generation; tracing and eliminating KV Cache race conditions; fixing HiCache synchronization issues; and introducing LayerSplit for up to 132% throughput improvement.
We hope these lessons help the community avoid similar pitfalls and build more robust inference infrastructure.
40
82
885
87,186
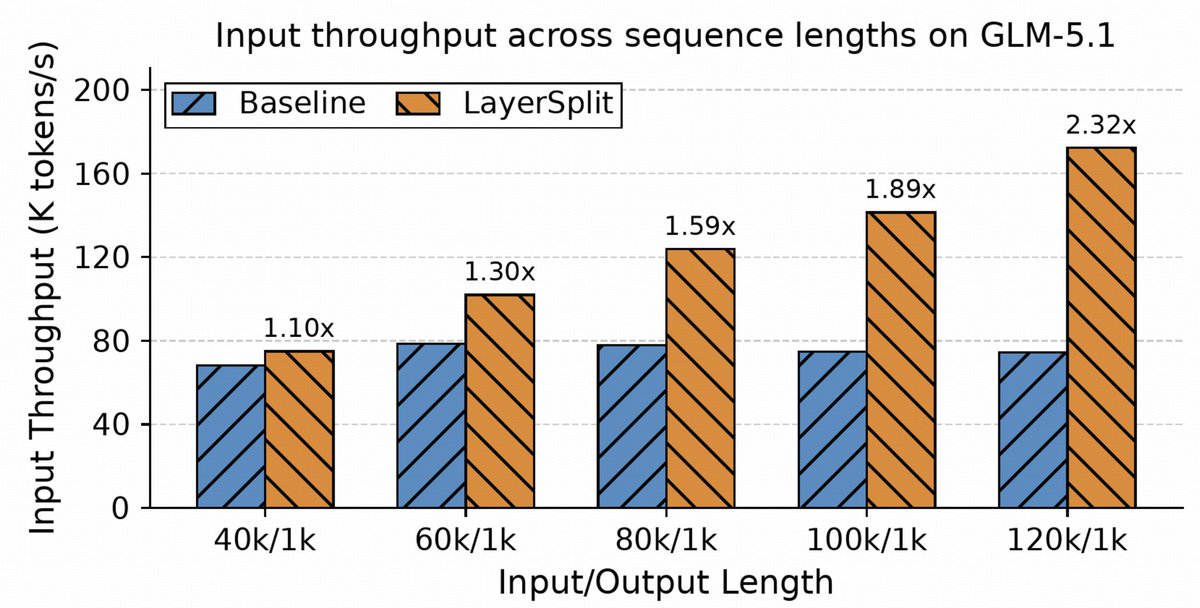
After fixing correctness issues, we turned to the next bottleneck: Prefill throughput and GPU memory pressure in long-context Coding Agent serving.
To address this, we introduced LayerSplit, a layer-wise KV Cache storage scheme. Instead of duplicating all layers on every GPU, each GPU stores only a subset of layers. With communication overlapped by computation, LayerSplit improved throughput by up to 132%.
3
1
38
9,300
As models, contexts, and workloads grow, hidden assumptions in inference infrastructure can surface as output anomalies. Reliability requires more than throughput, latency, and availability. It also requires preserving the correctness of model state behind every generation.
2
1
38
7,392