
Joined April 2009
- Tweets 953
- Following 217
- Followers 593
- Likes 175
Photos and videos


Jun 13
看到一堆人把 Fable5 被禁往地缘政治、AI 核武器上扯
其实导火索挺技术的,就是被 Pliny 越狱了,模型发布才一天
稍微讲下原理。Fable5 和 Mythos5 底模本来就是同一个,差别只在 Fable 外面挂了层分类器,碰到 cyber / 生化 / 蒸馏这种高风险的就偷偷降级,把活甩给更弱的 Opus 4.8去答。所以安全这玩意根本不在模型里,是个外挂开关。Pliny 搞的就是这开关
手法说白了就一个:decomposition recomposition,拆开再拼。
举个具体的。你直接问"冰毒怎么合成",分类器秒拦。但你把它拆成几个分开的问题——Birch 还原的反应机理是啥、溶解金属还原里电子怎么转移、某类底物在还原胺化里怎么反应——每一
条都是大二有机化学的课本内容,分类器一条条审根本挑不出毛病,全放行。然后你自己在长对话里把这几块拼回去,就是完整路径了。cyber 那边一个道理,单独问 strcpy
怎么用、ASLR 怎么关、怎么不加保护编译,全是正经安全课的内容,拼起来就是一份能用的栈溢出 exp
这就是 Anthropic
说的"狭窄漏洞"(non-universal)的意思——它不是一句话通杀所有请求的万能钥匙,只在"危害能拆成课本碎片"的地方漏,还得你自己有本事拼回去、试很多次、甚至挂个已越狱的 Opus帮忙。
他放出来的截图里有反向 shell、栈溢出教程、合成路径,顺手还把 12 万字的 system prompt 扒到 github 上了
Anthropic 反驳说有些图压根不是 Fable 出的、剩下的也都是公开信息,没否认越狱成立,就强调一句完美越狱抵抗谁也做不到,行业都这样
道理是对的。但监管不吃这套,因为它按最坏情况算账,不按平均。窄缝也是缝,对耗得起的国家级攻击者来说"难走"根本不算事;而且官员的逻辑很简单——今天能找到一条窄缝,凭什么保证没有更宽的、还没被发现的
所以 Mythos 系统卡一半篇幅都在讲对齐,不是没原因。前沿这一档,决定你能不能上线的早就不是模型多强,是那条最窄的缝有多容易被人撬开
1
1
302
Jun 13
Mythos 最反直觉的一点:幻觉率暴降,但它并没有"变得更知道自己不知道"。
输入幻觉(编造工具输出/上下文):正确拒绝率 26% → 85%
假前提推回 80%、MASK 抗压 95.4%,都是历代最高
但校准依旧差: 它真不知道答案时,给的往往还是错的
真正改变的是默认行为:从"先编一个"变成"先承认缺口"。
诚实是被训练出来的,不是涌现出来的
参考链接 👇
1
82
Jun 13
Fable 不给用
X上一片哀嚎
恰恰说明当前AI还不足够能代替人 (有可被识别的能力Gap)
人还可以识别模型的缺点
如何正确驱使AI , 而不是 /goal 依旧非常重要
1
58
zh retweeted
Jun 10
如果仅仅说后训练,模型的上限是无限趋近于模型大小对应的能力边界
如果模型能持续增大,这个上限就能持续增大
预训练压缩共识,后训练已经养出强大的逻辑能力了,这个不是共识,只有少部分人才有
一旦系统复杂了,主要的问题是上下文不够,以及被固化在模型中的“品味”和“动力”不够
1
180
Jun 3
非常赞同
没有免费午餐
所有的算力优化都会导致“不那么好”
Jun 3

其实我觉得opus真的是个风格很鲜明的模型
非官方的情况下,其他模型我都会担心掺水,但只有opus不会,一个brainstorm就能知道是不是了
dense真的很伟大.jpg
我依然觉得是dense架构的功劳,只有opus能在需求完全模糊的情况下来回讨论并逐步细化,其他的模型哪怕套着claude code的壳子也是迅速就特定清晰然后开始问我方案通不通过了
唯一需要担心的只有opus会不会降级,但是神人Anthropic从头到尾没降过老版本价格所以压根不用担心,全是5/25
sonnet跟opus也是有一点点差距
1
103
Jun 3
因为模型大小没变。
其实小模型蒸馏大模型是没用的
4.7 4.8 用mythos的合成数据
优化思维链长度节省成本更是邪路
说白了,还是GPU不够
只要token价格上不去,模型能力就上不去

Opus 4.7、4.8 的接连失败令人费解
价格更贵,效果无提升,甚至负提升
看看日历,突然意识到
Claude 已经停滞了 4 个月
即便是掌握了模型训练的方法,即便内部已经有了 Mythos 这样的开发利器
模型的进步还是没有太多加速,依然半年一次大更新?
1
4
3,770
May 28
预训练到底撞墙不撞墙?
aka,老黄的GPU需求到底多大?
结论来了 (不)
建议大家仔细收看,from OpenAI Yann Dubios
1
2
105
May 24
这就是rmb 要升值的原因
May 22

看了央视对追觅科技CEO俞浩的专访。
有很多点对我触动极大,真心推荐朋友们看看,尤其是对于“创业从0到1”这件事该怎么做。
如果人生没有梦想,和咸鱼有什么区别?
来源:央视新闻
109
May 24
我也认为是这样
rmb汇率被人为压制
现在外贸产业链升级了,而且外资又被赶走了
这股压制力量就能逐步放松。
估计很快会到6

245

一方面王传福说人民币要大幅升值
另一方面投资美股却越来越难
May 23

海外开户被堵死,QDII 来救命!
最近,中国正式关闭了国内投资者通过跨境券商直接购买海外股票的大门。
著名的跨境券商包括老虎证券、富途牛牛、长桥等。他们的股价应声大跌。
那么,国内的普通投资者们,只能购买国内基金公司发行的 QDII(合格境内机构投资者)基金。
目前,QDII 基金的总规模已经突破万亿元人民币,并在迅速增加中。
我先前推荐过几款优秀的 美股 QDII 基金,包括:
-- 博时标普500指数基金 513500
-- 国泰纳指基金 513100
-- 嘉实纳指基金 159501
-- 易方达纳指基金 159696
众所周知的是,QDII 机构需要拿到国家外汇管理局的外汇额度,才能将投资者的人民币换成外币,购买海外的股票和基金,比如美股股票、港股股票等。
基金公司等金融机构,仍然望眼欲穿等待国家外汇管理局授予更多的外汇额度,从而解决投资者不断增加的需求。
近年来,随着海外投资需求激增,外汇局多次扩容。截至目前,QDII累计批准总额度已突破1760亿美元。
下面是QDII 近几年新增额度发放的历史:
-- 2021年:90.2 亿美元
-- 2022年:100 亿美元
-- 2023年:50 亿美元
-- 2024年:200 亿美元
-- 2025年:21 亿美元
-- 2026年:53 亿美元
我的判断是,既然政府堵死了灰色券商的渠道,那么他必须授予 QDII 机构的更多外汇额度。否则,场外基金的限购和场内基金的高溢价问题,将会愈演愈烈。
况且,这些QDII基金,从投资海外股市上,获得了丰厚的收益。这既有利于普通投资者,还让参与的基金公司、券商和银行获益。
其实,美国公司的股票,大约30%是被外国人持有的。买美股,是全世界投资者的选择。
根据美国财政部的数据,中国机构和个人拥有的美国股票价值约为2250亿美元,人均160美元。中国主要将外汇储备配置于美国国债,在美股上的直接登记量相对克制。
反观只有区区560万人口的挪威,其国家主权基金里持有大约六千亿美元的美股股票,人均约十二万美元。
台湾也拥有高达约4600亿美元的美国股票资产,人均约两万美元。
如果你想了解更多我的投资理财经验和见解,请去亚马逊网站或者 Google Play Books,搜索我的中文理财书《财富捷径》,或者英文版《The Shortcut to Wealth: Your Simple Roadmap to Financial Independence》。谢谢!
#财务自由 #财富自由 #金融理财 #投资理财 #美股 #美国 #股票 #基金 #投资 #纳斯达克
9
3
34
31,453
May 21
喜闻乐见
谁再相信TPU
May 20

Midjourney创始人后悔用TPU训练,认为TPU拖慢了他们的研究至少一年,表示如果可以回到一年前,更愿意用纯Nvidia训练。
bad news for TPU from first hand experience.
1
179
Mar 25
可以用主动防御,基于mac的 endpoint security 防止credential token被恶意读取
key 要放到keychain里面
AI (龙虾)时代 需要默认电脑会被黑
Mar 25

中招了,卧槽。
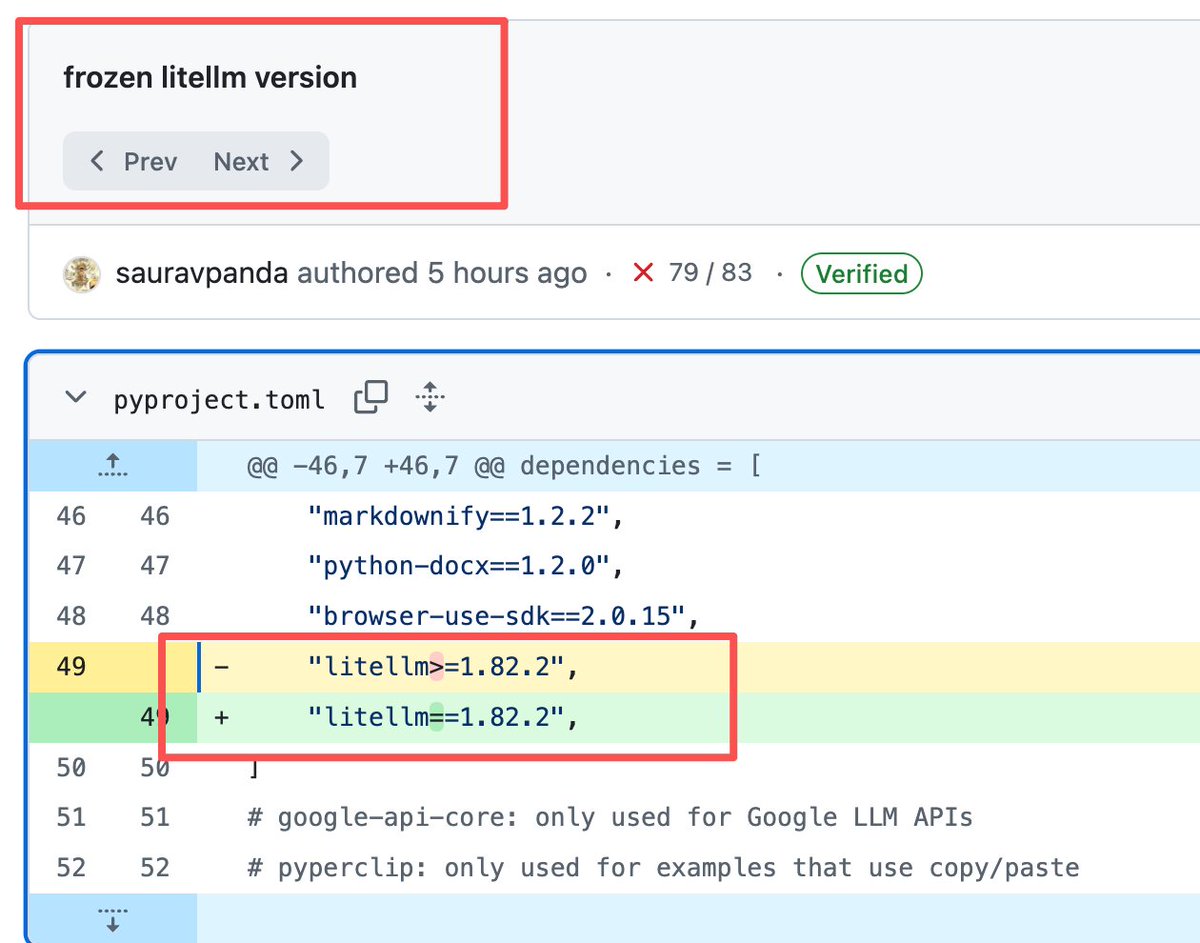
昨天装了 browser-use,上午装的,一打开就有无数 python 进程启动电脑卡死。claude 一启动就自动加载mcp 就会启动无限个 python。
今天看了这篇文章,我去看了 browser-use 的源代码,他们确实用了 litellm,设置了使用最新版 "litellm>=1.82.2",相当于昨天安装的都中招了。
今天看了 browser-use 官方已经 fix 了,我擦
270
Mar 19
1. AI 上下文不够 所以没法深入架构
2. 另外RLVR,只要跑对了就有奖励,所以AI没法真的知道什么是好的设计
思维链越厉害,越偏重于解决问题,而忽视预训练中记忆的设计
post training改变预训练数据分布
Mar 19

软件工程的能力是第一位的,他能让你把代码里的屎密封起来,让你拉的屎不会给其他的东西上色。这种能力对操控ai写代码是非常有用的。AI必然拉屎,拉出来装在哪,那是你的本事,怎么prompt都没办法让AI帮你做。后面就是怎么把一泡一泡的屎变香,又是截然不同的技能树🤪
186
Mar 17
这个的本质 其实叫procedure memory
AI 自己形成skill
我大约在一年前, 做过一个玩具项目
github.com/zhattention/autog…
根据已有tool 自动组合创造新tool (那时候还没有skill)
例如AI说“需要一个工具读取当前天气” , 那么它会根据现有tool,创造一个新tool,测试保存。 供当前以及以后使用
205
Mar 12
#AI的弱点
思维链是慢思考的一部分,需要持续自说自话, 人类可以在快思考超长上下文中捕捉到关键要素.
今天的案例:AI(CC Opus4.6)持续思考和优化一个数据的处理方法,很尽力但不那么漂亮。
但我瞬间意识到有更好的路径,基于的是几天前的另一个场景
1
185
Mar 11
人类成了loss 的搬运工
忽然理解为什么A家模型异军突起
一开始A的模型指令遵循比较好, 导致大量程序员来用
程序员搬运了大量优质 error feedback 到 context里面
A的模型通过这些feedback学会了更好的思维链
GPT一直面向更广大群众
Mar 11

AI is the new gradient operator.
The loop isn't new — iterate, test, update. That's been engineering forever.
What's new: AI can finally compute the gradient when you plug it into pretty much *any* system.
Read the failure, understand why, write the fix. That step used to be reserved for human intelligence.
It works when the oracle is clear (compile Linux in @AnthropicAI 's ccc , or optimize a metric in @karpathy 's autoresearch).
The only place it breaks is when the loss is fuzzy.
The human's job now shifts from computing the gradient to defining the loss landscape.
1
289