
PhD student | Deep Learning | Computer Vision | Biomedical Images
Joined February 2022
- Tweets 18
- Following 133
- Followers 7
- Likes 22
2 Photos and videos

Aitor González-Marfil retweeted

26 Aug 2025
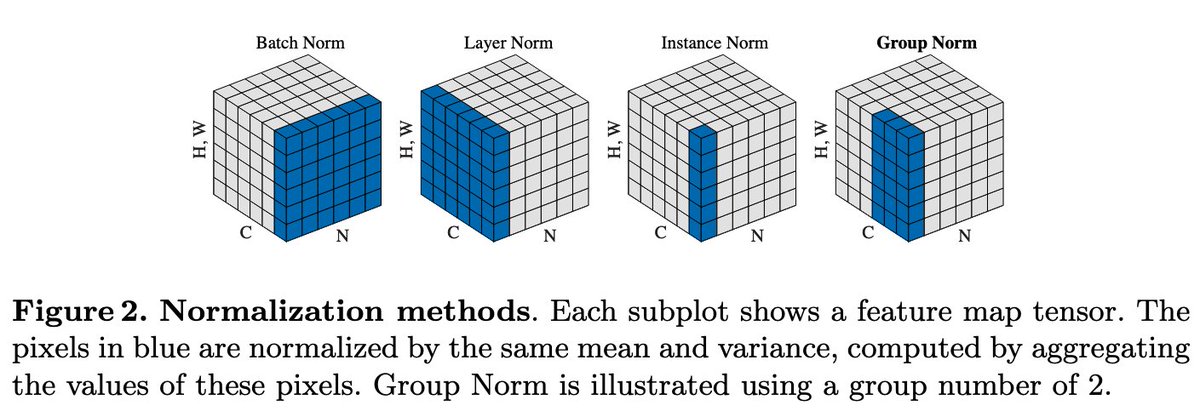
while doing ML research i spend a disproportionately large amount of time looking at this specific figure
27
78
1,666
103,153

🧬 BiaPy was built by an international collaboration between researchers from @upvehu, @DIPCehu, @BiofisikaScienc, @UC3M, @scu_lab, @LabOptBio and others — led by @IgnacioArganda and @ArrateMunoz.
A huge thanks to everyone who contributed! 🌟 (5/7)

ALT Screenshot of the BiaPy site showing the pictures of the team: Daniel Franco-Barranco Jesús A Andrés-San Román Ivan Hidalgo-Cenalmor Lenka Backová Aitor González-Marfil Clément Caporal Anatole Chessel Pedro Gómez-Gálvez Luis M Escudero Donglai Wei Arrate Muñoz-Barrutia Ignacio Arganda-Carreras
1
2
5
251

31 Mar 2025
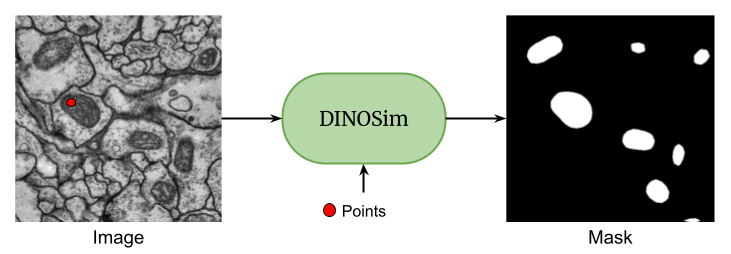
My first preprint is out!
"DINOSim: Zero-Shot Object Detection and Semantic Segmentation on Electron Microscopy Images" 🔬✨
🔗: doi.org/10.1101/2025.03.09.6…
ALT DINOSim workflow simplified
1
38
31 Mar 2025
DINOSim was created to provide a functional tool for environments with limited resources, little data, no labels, or no access to large model training, a common challenge in many biomedical labs.
1
13
31 Mar 2025
But there are no restrictions on its use! Feel free to experiment with other types of data and see what works for you. 🚀
9
28 Mar 2025
A few months ago, I had the opportunity to present my project, DINOSim, at #SPAOM2024. It was an incredible experience where I had the opportunity to meet and share ideas with many amazing people.
110
Aitor González-Marfil retweeted

20 Nov 2024
🧪🔬 Are you at #SPAOM2024 ? Here you have a list of the contributions from my lab (all in Day 2 and 3)👇
1⃣ Tomorrow at 10:15am (Sala Toledo) my PhD student @AAitorG will present his work "Zero-Shot Object Detection with Foundational Models: A Similarity-Based Approach"

ALT First slide of Aitor González-Marfil's presentation at SPAOM 2024, showing the title "DinoSim: Zero-Shot Object Detection and Segmentation with Foundation Models"
1
6
21
1,507
Aitor González-Marfil retweeted

20 Nov 2024
#SPAOM2024 attendants don't miss @AAitorG's talk on #ZeroShot #segmentation 👇 and catching him up later!
20 Nov 2024

🧪🔬 Are you at #SPAOM2024 ? Here you have a list of the contributions from my lab (all in Day 2 and 3)👇
1⃣ Tomorrow at 10:15am (Sala Toledo) my PhD student @AAitorG will present his work "Zero-Shot Object Detection with Foundational Models: A Similarity-Based Approach"
ALT First slide of Aitor González-Marfil's presentation at SPAOM 2024, showing the title "DinoSim: Zero-Shot Object Detection and Segmentation with Foundation Models"
4
15
531
🆕 We have updated our preprint in @biorxivpreprint 📰 It explains better the current state of #BiaPy ⛴️ while describing as well its limitations 🤗 Hope you like it!
"BiaPy: Accessible deep learning on bioimages" biorxiv.org/content/10.1101/…
13
20
1,735
Aitor González-Marfil retweeted

18 May 2024
I remember during my PhD,
I spent many many hours reviewing every single image in my datasets, while I just used an off-the-shelf GAN architecture for my models because I observed that
dataset quality >>>> model arch
18 May 2024


9
57
476
50,939
Aitor González-Marfil retweeted

31 Aug 2023
DINOv2, the cutting-edge computer vision model trained through self-supervised learning to produce universal features, is now available under the Apache 2.0 license.
Onward with open source AI.
31 Aug 2023

Today we’re announcing two new updates in our computer vision work — a new, expanded license for our DINOv2 model and the release of FACET, a comprehensive new benchmark dataset to help evaluate and improve fairness in vision models.
More details ➡️ bit.ly/3L35E1U
🧵
34
212
1,556
333,587
Aitor González-Marfil retweeted
13 Jun 2023
I-JEPA: Efficient method for Self-Supervised Learning of image features.
No need for data augmentation, just masking.
Joint embedding predictive architecture, not generative.
And it's open source, of course.
Blog: ai.facebook.com/blog/yann-le…
Paper: arxiv.org/abs/2301.08243
Code & models: github.com/facebookresearch/…
13 Jun 2023
Today we're releasing our work on I-JEPA — self-supervised computer vision that learns to understand the world by predicting it. It's the first model based on a component of @ylecun's vision to make AI systems learn and reason like animals and humans.
Details ⬇️
48
297
1,480
464,772
Aitor González-Marfil retweeted

8 Jun 2023
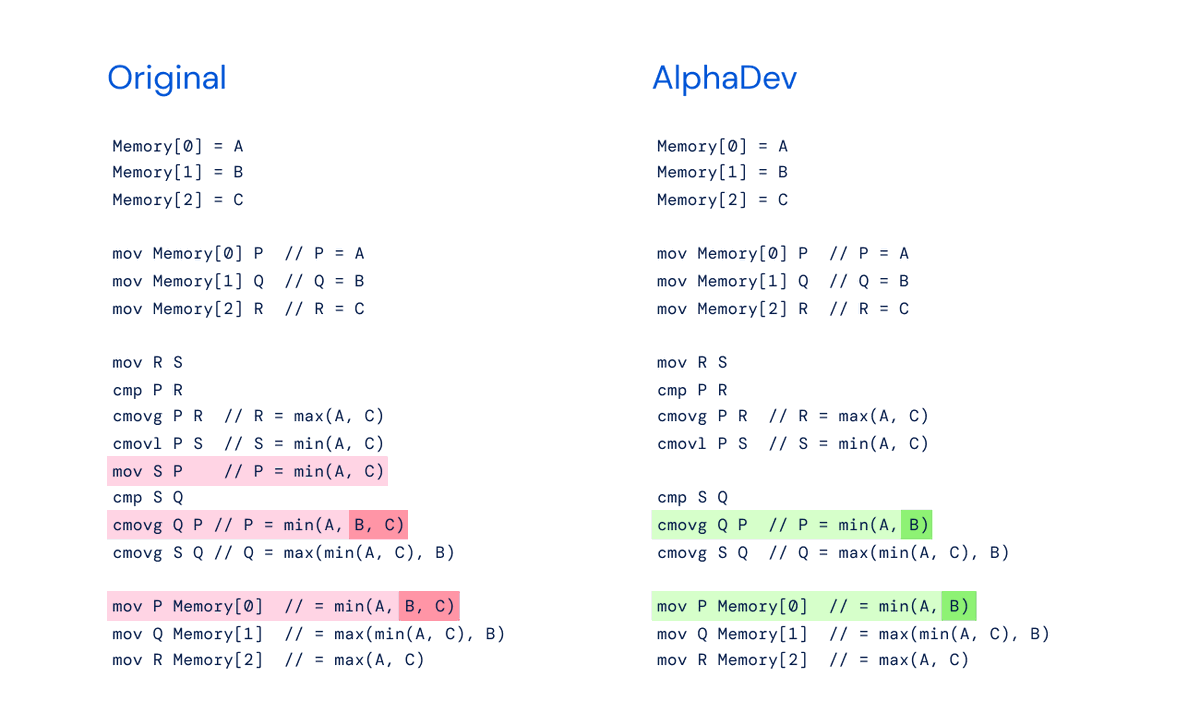
GPT-4 "discovered" the same sorting algorithm as AlphaDev by removing "mov S P".
No RL needed. Can I publish this on nature?
here are the prompts I used chat.openai.com/share/95693d…
(excuse my idiotic typos, but gpt4 doesn't mind anyways)

Sorting algorithm underpins all critical softwares. DeepMind's AlphaDev speeds up sorting small sequences (3-5 items) by 70%.
Key takeaways:
* The main RL algorithm is based on AlphaZero that originally played Go, Chess & Shogi. Same idea applies to searching programs!
* Instead of optimizing over C code, they optimize assembly code instead. It's a deliberate choice to go low-level to squeeze out every instruction saving.
* The assembly code is then reverse-engineered by hand to C, and open-sourced in LLVM.
* Even though the representation network uses transformer, it is NOT a foundation model. The whole pipeline only works on sorting, and has to be re-trained for other tasks like hashing.
88
408
2,588
1,767,339
Aitor González-Marfil retweeted

25 Jan 2023
#OpenAI is planning to stop #ChatGPT users from making social media bots and cheating on homework by "watermarking" outputs. How well could this really work? Here's just 23 words from a 1.3B parameter watermarked LLM. We detected it with 99.999999999994% confidence. Here's how 🧵

148
889
4,356
1,315,346
Aitor González-Marfil retweeted

24 Feb 2022
This is a "3D-diffusion" video created using a combination of four different AI models🤯
Welcome to the metaverse! 🌌😎
There's such incredible potential here that I want to explain how I made this, so here's a thread! (1/n)
37
208
1,140

CLIPasso: Semantically-Aware Object Sketching
abs: arxiv.org/abs/2202.05822
project page: clipasso.github.io/clipasso/
9
204
1,045