
Code. Design. Engineering. Culture. Startups. Miami. Technology. Creativity. Director @QuriousLabs. Past: TED, Betaworks Currently: stakeware.xyz
Joined December 2007
- Tweets 3,996
- Following 289
- Followers 2,776
- Likes 95
71 Photos and videos









Pinned Tweet

14 Jul 2012
"when u don't create things, u become defined by your tastes rather than ability. your tastes only narrow & exclude people. so create" _why
1
10
25
Aditya Chadha retweeted

May 23
a little saturday morning lite expo writing
New Post:
Of Assholes and Obsessives
on the distorted intensities of ego and conviction
tdevane.substack.com/p/of-as…

1
1
307
Aditya Chadha retweeted

Mar 26
Put the Fauna blog's greatest hits back online: fauna.evanweaver.com/
3
2
4
5,041
Aditya Chadha retweeted
Mar 25
i wrote this ~11 years ago, kinda feels more relevant in our agentic present
tdevane.substack.com/p/99-in…

1
1
624
Aditya Chadha retweeted

9 Jul 2024
I’m excited to finally reveal Near Horizon to the world!
In early 2023, @mfk , @mjacobstein and I were frustrated at how great solo founders were told to “go find a co-founder” by traditional VC firms ...
...so set out to create a new kind of early stage venture firm!
1/

1
4
26
7,912
13 Dec 2023
Holy fuck. This is epic.
12 Dec 2023

OpenAI API compatibility shipped for 100 models on @togethercompute API.
Replace GPT calls with Mixtral or Llama-70B, get faster responses and for less $$
🚀🚀🚀
2
5,600
Aditya Chadha retweeted

17 Jul 2023
Excited to welcome @tri_dao to the Together team! FlashAttention-2 will improve all LLMs everywhere in like <1 week. It’s absolutely brilliant!
17 Jul 2023

We are thrilled to introduce our Chief Scientist @tri_dao! Tri joins from @StanfordAILab where he’s focused on efficient training of AI models.
Today he released #FlashAttention2—a significant breakthrough to speed up LLM training & inference. Read more: together.ai/blog/tri-dao-fla…

1
9
65
21,921
Aditya Chadha retweeted
30 Jun 2023
The era of sub-quadratic LLMs is about to begin. At @togethercompute we've been building next gen models with large space state architectures and training them on very long sequences and the results from the recent builds are... incredible. Will share more as we get closer to releases!
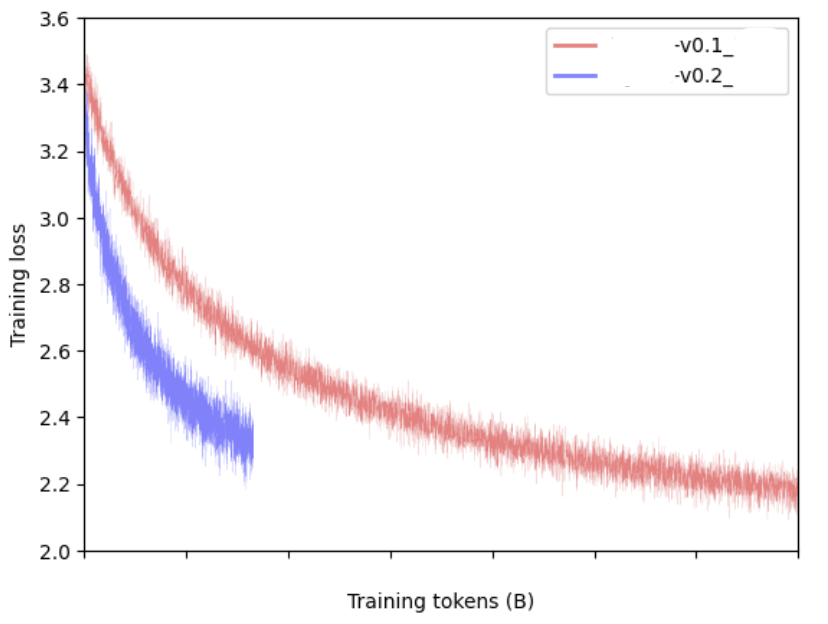
5
31
392
80,349
Aditya Chadha retweeted

10 May 2023
A Lido V2 Audit Update:
Security is a top priority. To this end Lido DAO dedicated significant effort to 9 independent V2 audits.
These audits have uncovered important findings, all of which have been either acknowledged or fixed.
🧵
7
35
219
158,949
Aditya Chadha retweeted
5 May 2023
Share and enjoy!
5 May 2023
The first RedPajama models are here! The 3B and 7B models are now available under Apache 2.0 license, including instruction-tuned and chat versions!
This project demonstrates the power of the open-source AI community with many contributors ... 🧵 together.xyz/blog/redpajama-…

5
19
7,754
Aditya Chadha retweeted
24 Apr 2023
RedPajama-7B performs better at 440B tokens than all the best models trained on Pile, and continues to get better. More information on experiment design in the blog post and will keep you all posted as this converges further!
24 Apr 2023
Training our first RedPajama 7B model is going well! Less than half way through training (after 440 billion tokens) the model achieves better results on HELM benchmarks than the well-regarded Pythia-7B trained on the Pile.
Details at together.xyz/blog/redpajama-…
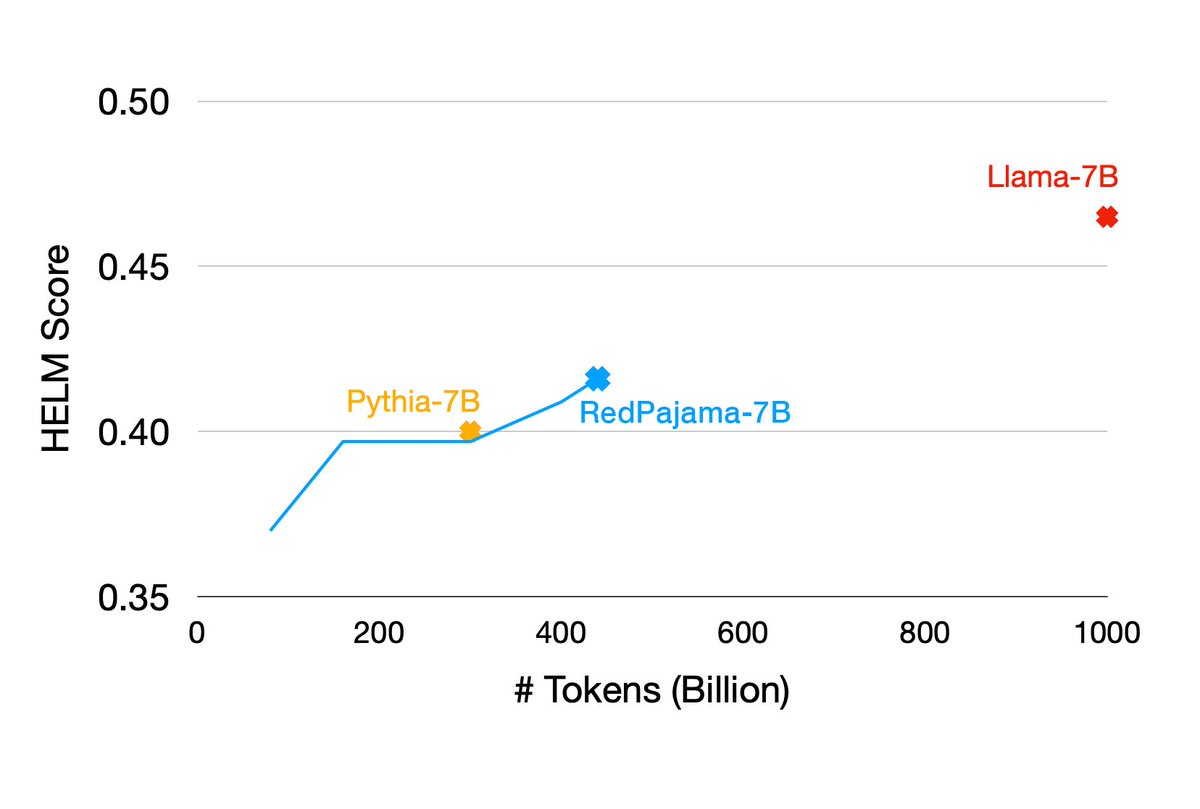
5
8
63
14,145
Aditya Chadha retweeted
22 Apr 2023
Llamas in Red Pajamas will be everywhere soon! In the meantime here’s the inimitable Rae Sremmurd for your weekend listening 😁🦙youtu.be/HqiqVZ8PJ2Q @togethercompute
5
9
2,670
Aditya Chadha retweeted

29 Jan 2023
The highest earning YouTubers from every country in the world (just on ad dollars)
1. North America:
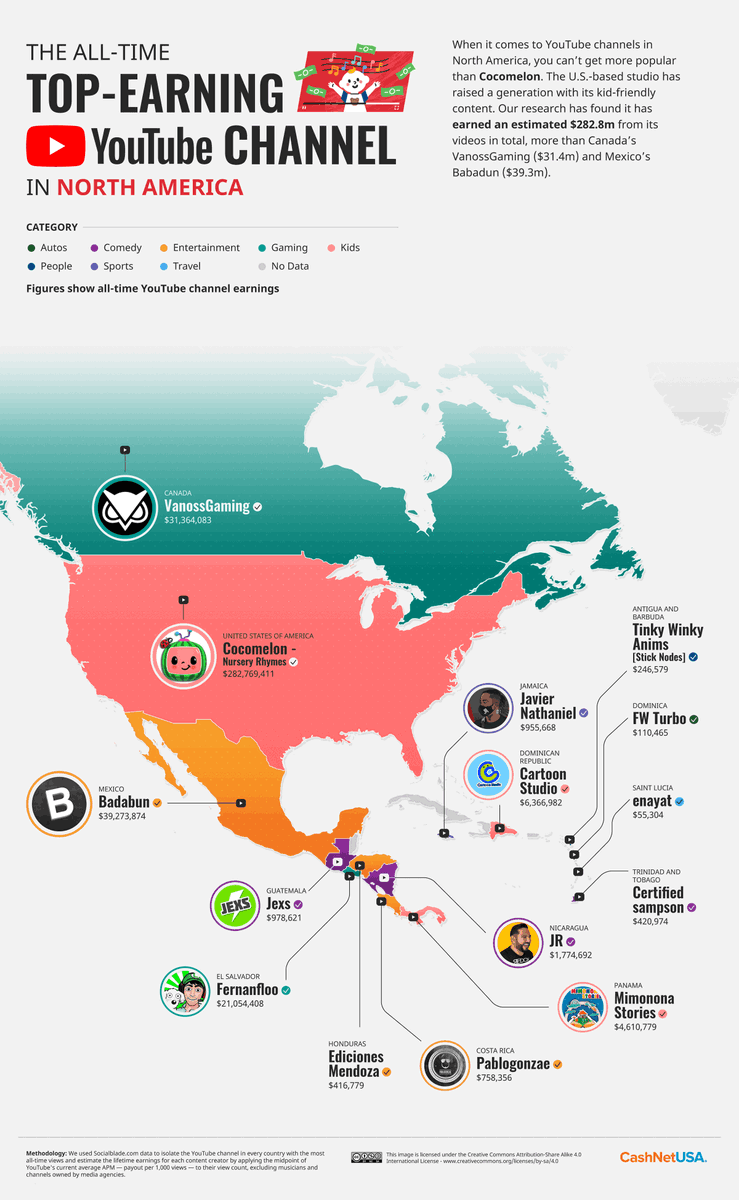
155
2,561
9,897
2,862,952

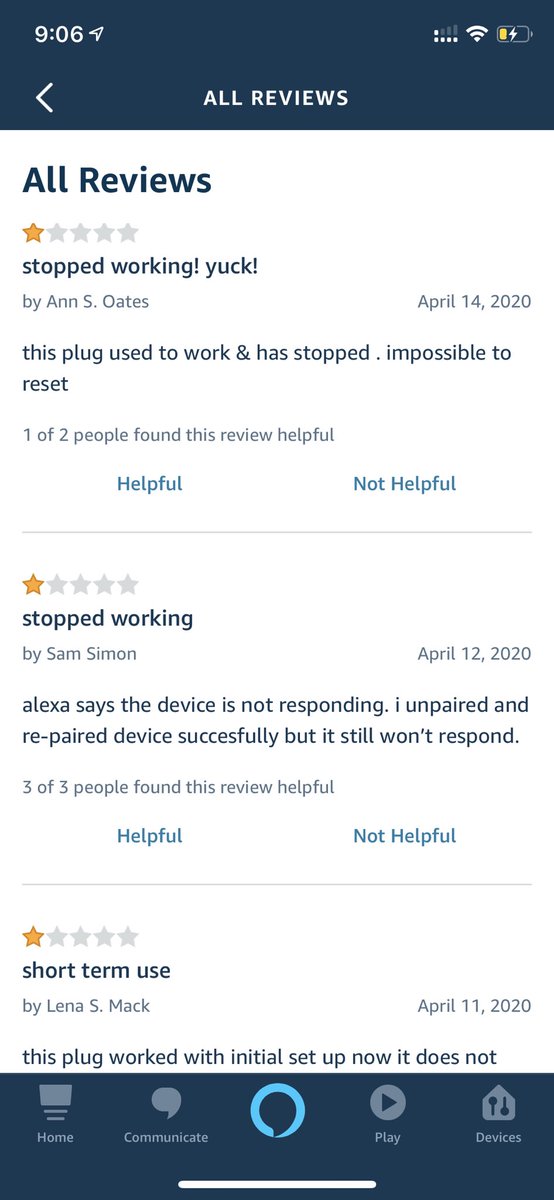
Today, I decided to do a deep-dive into the age-old gas saving trick:
Using i instead of i .
You may have seen this trick and asked yourself how a change this trivial and inconsequential could result in a difference in gas usage.
Well folks, here's the full explanation 🧵:
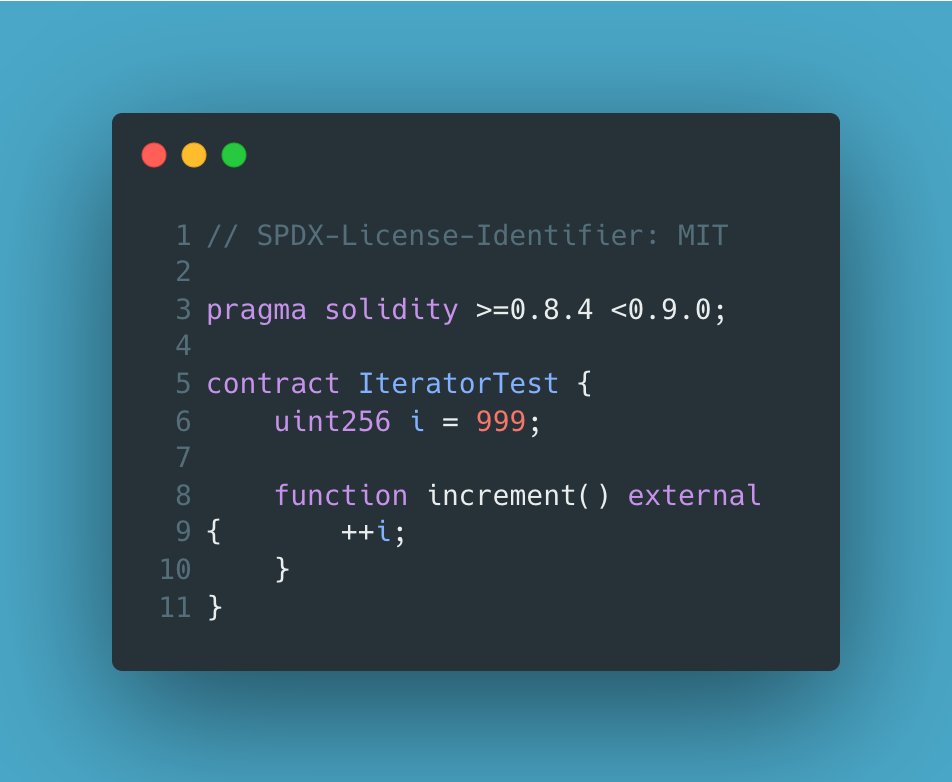
46
158
1,074
239,377
Aditya Chadha retweeted

29 Nov 2022
Introducing GPT-JT, a 6B parameter open source model that can outperform many 100B parameter models and was trained over slow (1Gbps) internet links.
together.xyz/research/releas…
17
206
1,150
3 Aug 2022
.@github @GitHubHelp haven't been able to login to my account for weeks, what's going on: "There have been several failed attempts to sign in from this account or IP address. Please wait a while and try again later." Nothing from the support ticket either... Pro user too. :(
Aditya Chadha retweeted

3 Apr 2022
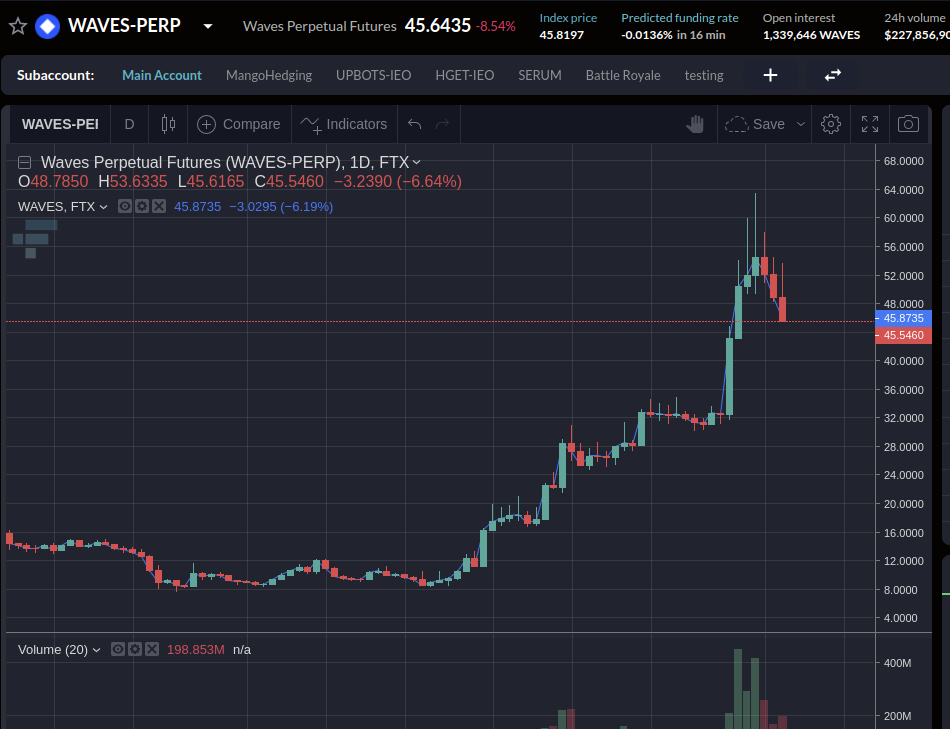
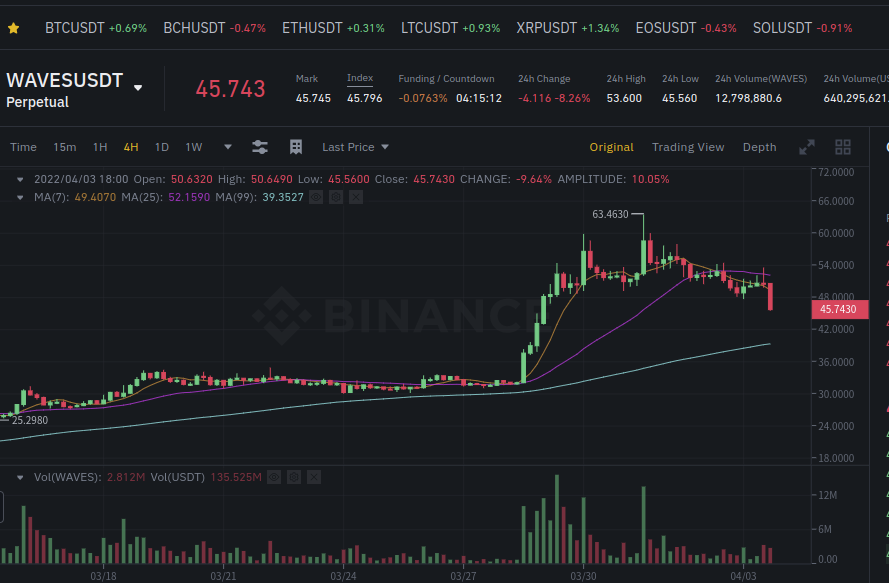
Current Alameda borrow on WAVES looks to be 631,763 paying ($30M ) 12.5% APR
api.vires.finance/user/3PHkZ…
While WAVES-PERP on FTX is at -120% APR, Binance at -80% APR

1
1
7