
Third year CS PhD candidate at Princeton University (@princeton_nlp @PrincetonPLI), previously CS undergrad at IIT Bombay
Joined June 2023
- Tweets 85
- Following 501
- Followers 460
- Likes 350
30 Photos and videos









Pinned Tweet

25 Sep 2025
Language models that think, chat better.
We used longCoT (w/ reward model) for RLHF instead of math, and it just works. Llama-3.1-8B-Instruct 14K ex beats GPT-4o (!) on chat & creative writing, & even Claude-3.7-Sonnet (thinking) on AlpacaEval2 and WildBench!
Read on. 🧵
1/8
3
17
113
27,475
Adithya Bhaskar retweeted

May 18
My work in 2023: think deeply about technical topic, build the perfect codebase from scratch, know it by heart
My work in 2026: chatting with five dumb people at the same time, they've been stuck Whirliging... for fifteen minutes, not sure what to do so i might spin up a sixth
13
14
550
21,387
Adithya Bhaskar retweeted

Apr 17
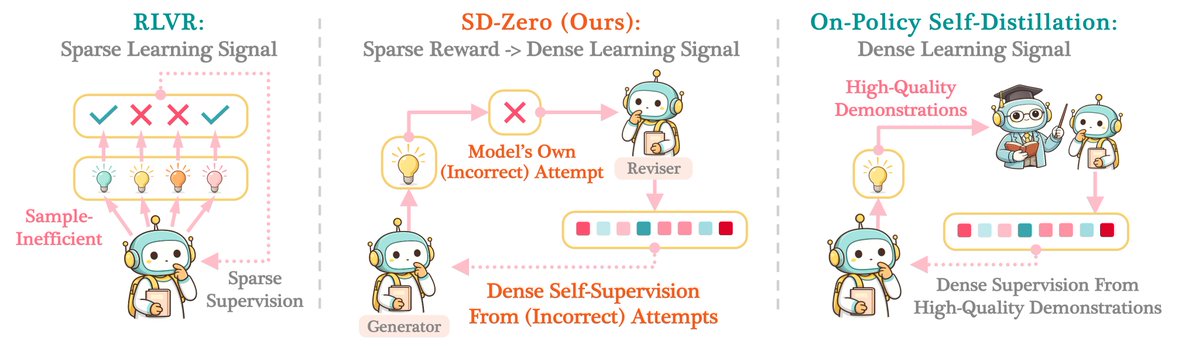
RLVR gives sparse supervision; On-Policy Self-Distillation often requires high-quality demonstrations. Our new method, ✨SD-Zero✨, gets the best of both worlds – we use model’s self-revision to turn binary rewards into dense token-level supervision. No external teacher. No curated demonstrations.
🚨 Introducing Self-Distillation Zero (SD-Zero), which trains one model to play two roles: (1) “Generator” that makes attempts, and (2) “Reviser” that conditions on the generator’s failed/successful attempt binary reward to produce a better answer. ‼️Even WRONG attempts can become the training signal.‼️
🔗Paper: arxiv.org/abs/2604.12002
🏆 SD-Zero brings 10% improvement over base models (Qwen3,4B; Olmo3,7B) on math & code reasoning, beating GRPO and vanilla On-Policy Self-Distillation under the same training budget. SD-Zero also enables iterative self-evolution.

17
58
424
226,726
Adithya Bhaskar retweeted

Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
"SD-ZERO trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser’s token distributions conditioned on the generator’s response and its reward as supervision. In effect, SD-ZERO trains the model to transform binary rewards into dense token-level self-supervision."

6
32
186
16,962
Adithya Bhaskar retweeted

Apr 15
On-policy self-distillation on revised output. First train a model to generate both output and revision given the outcome. And do on-policy self-distillation to match the revised output.

2
17
121
10,340
Adithya Bhaskar retweeted

Video models surprisingly can solve mazes, but inconsistently. We understand little about how they reason, making it hard to use such abilities.
We investigate the denoising process and find models commit to a plan early, letting us screen far more candidates for better perf.
🧵
1
17
95
13,813
Adithya Bhaskar retweeted
Feb 21
it always disappointed me that such a small subset of mathematical ideas matter for AI
i miss doing real math

58
89
1,450
86,795
Adithya Bhaskar retweeted
Feb 2
STAT has been accepted to ICLR 2026! See you in Brazil 🇧🇷
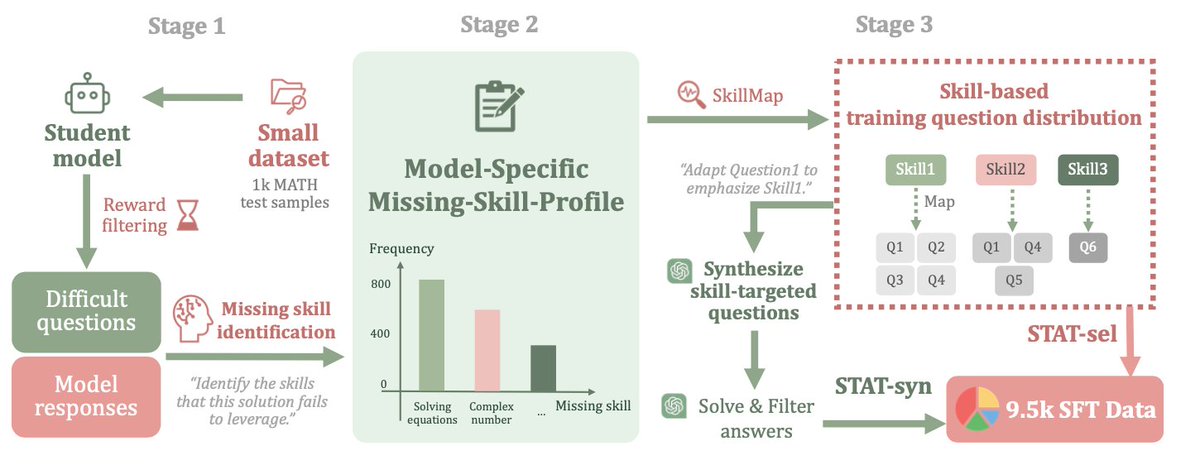
Skill-Targeted Adaptive Training (STAT) is a continual learning method that squeezes out 🚨 7~10% more performance on extensively trained models like Qwen. It constructs a 🧩 Missing-Skill-Profile for each model based on what skills the model lacks in their responses, and adaptively curates post-training data accordingly.
Check out our Blog Post 👉 ying-hui-he.github.io/Skill-…
🔗arXiv : arxiv.org/abs/2510.10023
💻GitHub: github.com/princeton-pli/STA…

8
16
199
28,727
Adithya Bhaskar retweeted

Jan 20
New #NVIDIA Paper
We introduce Motive, a motion-centric, gradient-based data attribution method that traces which training videos help or hurt video generation.
By isolating temporal dynamics from static appearance, Motive identifies which training videos shape motion in video generation.
🔗 research.nvidia.com/labs/sil…
1/10
11
120
584
110,612
28 Nov 2025
I will be at NeurIPS 2025 from 12/2 to 12/7.
These days, I am most interested in bridging mid-training and post-training (of LLMs). Hit me up if you want to chat!
1
11
571
Adithya Bhaskar retweeted

31 Oct 2025
Text-to-image (T2I) models can generate rich supervision for visual learning but generating subtle distinctions still remains challenging.
Fine-tuning helps, but too much tuning → overfitting and loss of diversity.
How do we preserve fidelity without sacrificing diversity (1/8)
2
13
39
26,339
Adithya Bhaskar retweeted
20 Oct 2025
Claude Skills shows performance benefits from leveraging LLM skill catalogs at inference time. Our previous work (linked under thread 5/5) showed the same 6 months ago! 🌟Our new work, STAT, shows that leveraging skills during training can greatly help too‼️, e.g., Qwen can continue to learn new tricks from Hendrycks MATH, which it had been over-trained on.
🚨 We introduce Skill-Targeted Adaptive Training (STAT), which uses a supervisor model and a skill catalog to construct a 🧩Missing-Skill-Profile for each student model, and then modifies training to squeeze out >=7% more performance! The intervention can be as simple as reweighting existing training sets. You can also think of this as a more effective distillation method. More in threads 🧵
📎 [arxiv]: arxiv.org/abs/2510.10023
💻 [github]: github.com/princeton-pli/STA…
🥳 Amazing collaborators: @Abhishek_034, @Yong18850571, @prfsanjeevarora

8
42
197
55,742

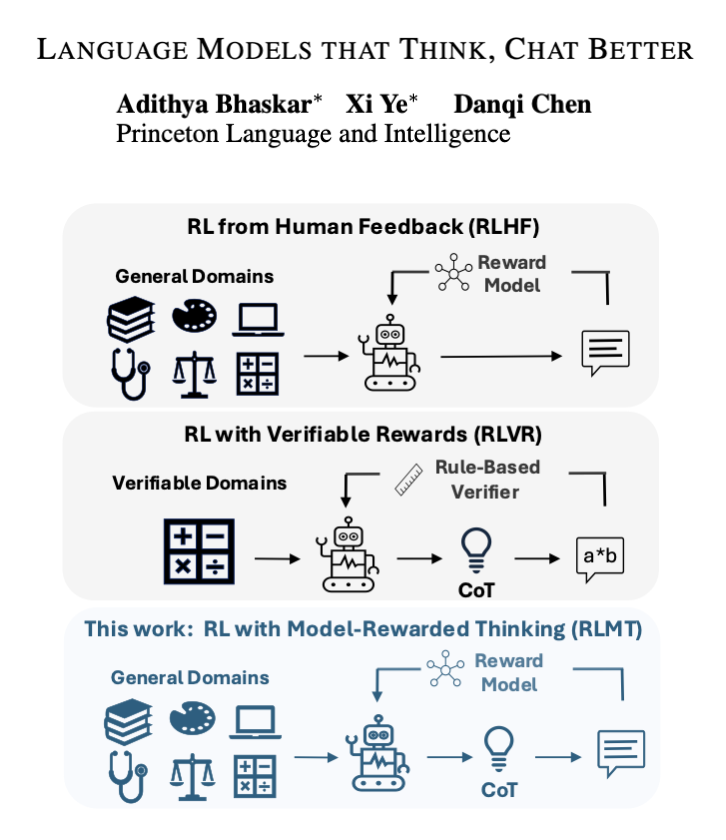
Check out our new work on making reasoning models think broadly! 🤔
We find a minimalist, surprisingly effective recipe to THINK for CHAT: RLVR a strong reward model, trained on real-world prompts.
This project was fun and surprised me in a few ways 👇
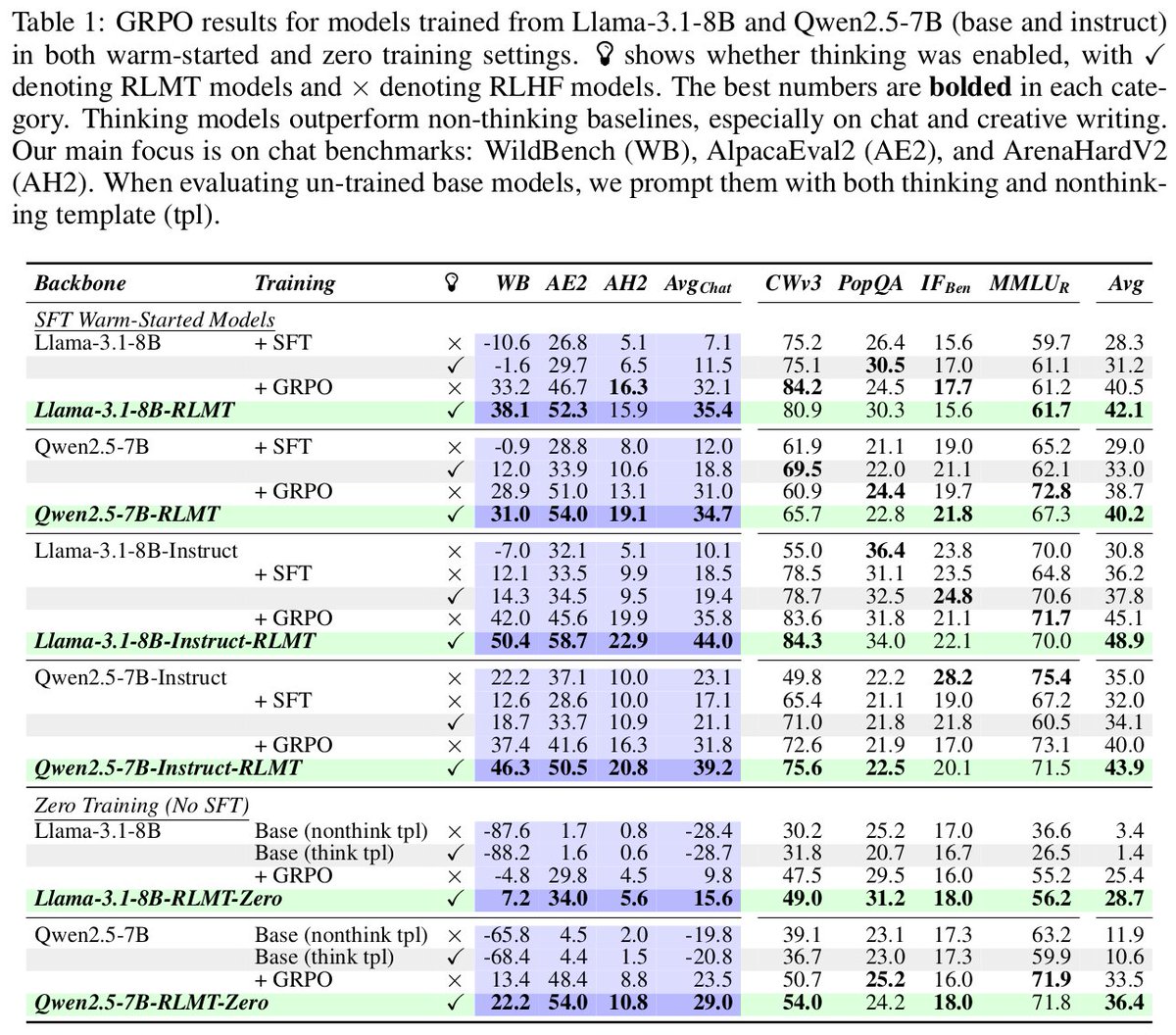
📌 We can run RL directly on a base model (no SFT), showing base models might already chat well.
Llama-3.1-8B-Base with only 7K prompts ends up chatting well, matching Llama-3.1-8B-Instruct. This is interesting since Instruct was trained with a complex multi-stage pipeline. Also nice to see this working on Llama, while most RLVR papers only show success on Qwen.
📌 Interesting findings about rewards. Leaderboard scores of reward models aren’t always the best indicator of downstream performance. We also tested checklist-based rewards, which helps on synthetic instruction-following tasks (IFEval) but didn’t generalize well to chat. I still believe in this direction, and would love to see more open-source efforts.
📌 Real user prompts (shout out to WildChat @wzhao_nlp ) were the most effective.
These prompts often require “thinking before answering,” which makes them fit for teaching models general thinking. The recipe is simple, we need good ingredients to cook better.
📌 Algorithms, like GRPO vs PPO, has a bigger impact when training directly from base models, but once warm-started with SFT, models are less sensitive to the choice.
Overall, my feeling is: if we start with a strong base LM, and put it in the right “chat environment” (good prompts good rewards), simple RL training goes a long way. Thus we are quite excited to explore more on pretraining and reward design!
25 Sep 2025

Language models that think, chat better.
We used longCoT (w/ reward model) for RLHF instead of math, and it just works. Llama-3.1-8B-Instruct 14K ex beats GPT-4o (!) on chat & creative writing, & even Claude-3.7-Sonnet (thinking) on AlpacaEval2 and WildBench!
Read on. 🧵
1/8
23
99
18,476
29 Sep 2025
Thanks for tweeting our paper!! 😁
29 Sep 2025

The paper shows that making models think before answering makes them chat better.
It introduces reinforcement learning with model rewarded thinking, RLMT, which makes the model write a private plan, then the final reply.
A separate reward model, trained from human choices, scores each reply so higher scoring answers get reinforced.
Training uses group relative policy optimization, GRPO, which samples several replies per prompt and pushes the model toward the better than average ones.
They try 2 setups, a warm start that learns the format from teacher examples, and a zero setup that skips supervised fine tuning.
The prompts come from real chat requests, not math or code, so the model practices everyday tasks.
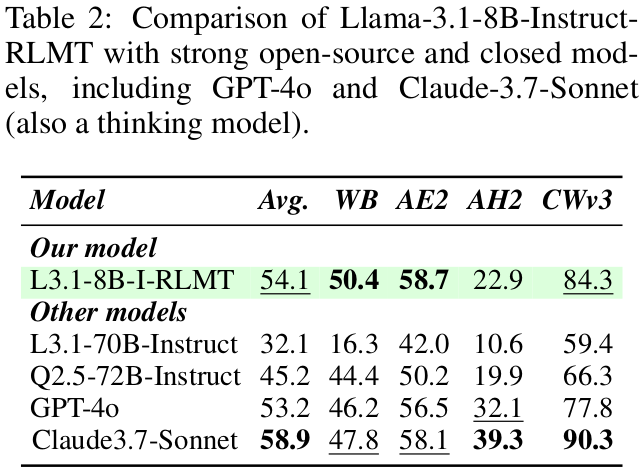
Across Llama-3.1-8B and Qwen-2.5-7B, the thinking versions beat non thinking baselines on chat and writing by about 3 to 8 points.
One 8B model beats GPT-4o on chat and creative writing, and is close to Claude-3.7-Sonnet.
Language_Models_that_Think_Chat…
The thinking style shifts from rigid checklists to listing constraints, grouping themes, checking edge cases, and then refining.
Gains depend on a strong reward judge and a chat heavy prompt mix, which pushes benefits beyond verifiable tasks like math and code.
----
Paper – arxiv. org/abs/2509.20357
Paper Title: "Language Models that Think, Chat Better"

2
345
29 Sep 2025
Honored to be included in the list, thanks a lot!

7. Language Models that Think, Chat Better
A simple recipe, RL with Model-rewarded Thinking, makes small open models “plan first, answer second” on regular chat prompts and trains them with online RL against a preference reward.
x.com/omarsar0/status/197121…
6
628

Top AI Papers of The Week (September 22-28):
- ATOKEN
- LLM-JEPA
- Code World Model
- Teaching LLMs to Plan
- Agents Research Environments
- Language Models that Think, Chat Better
- Embodied AI: From LLMs to World Models
Read on for more:
8
62
286
42,518
29 Sep 2025
Thanks for your kind words!
28 Sep 2025

Ever wonder why some AI chats feel robotic while others nail it?
This new paper introduces a game-changer: Language Models that Think, Chat Better.
They train AIs to "think" step-by-step before replying, crushing benchmarks. Mind blown? Let's dive in 👇

5
710
26 Sep 2025
Thanks a lot for the shout-out! 😁

Language Models that Think and Chat Better
Proposes a simple RL recipe to improve small open models (eg, 8B) that rivals GPT-4o and Claude 3.7 Sonnet (thinking).
Pay attention to this one, AI devs!
Here are my notes:

1
13
2,619
25 Sep 2025
Thanks a lot for the tweet! We had a lot of fun working on this project! 😄
25 Sep 2025

Language Models that Think, Chat Better
"This paper shows that the RLVR paradigm is effective beyond verifiable domains, and introduces RL with Model-rewarded Thinking (RLMT) for general-purpose chat capabilities."
"RLMT consistently outperforms standard RLHF pipelines. This includes substantial gains of 3–7 points on three chat benchmarks (AlpacaEval2, WildBench, and ArenaHardV2), along with 1–3 point improvements on other tasks like creative writing and general knowledge. Our best 8B model surpasses GPT-4o in chat and creative writing"

11
1,855
25 Sep 2025
Language models that think, chat better.
We used longCoT (w/ reward model) for RLHF instead of math, and it just works. Llama-3.1-8B-Instruct 14K ex beats GPT-4o (!) on chat & creative writing, & even Claude-3.7-Sonnet (thinking) on AlpacaEval2 and WildBench!
Read on. 🧵
1/8
3
17
113
27,475
25 Sep 2025
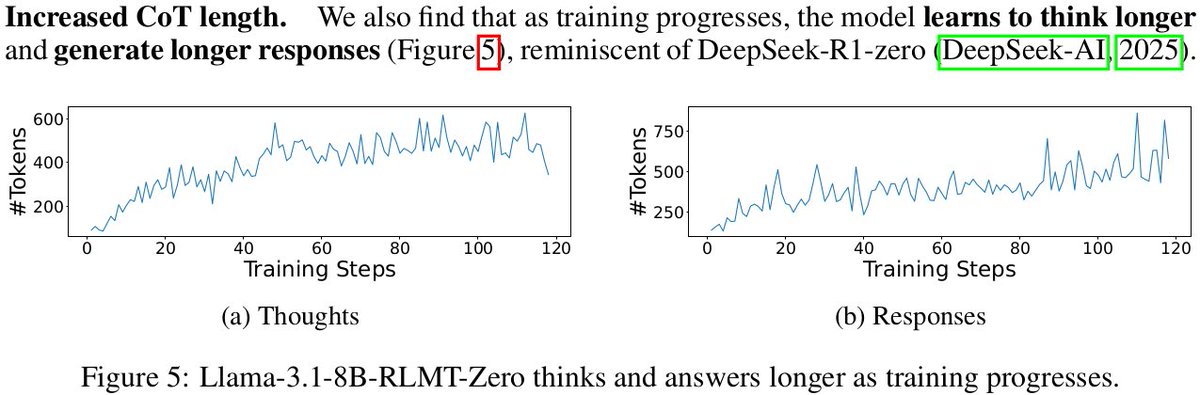
Oh, and here is the customary plot that shows that the model learns to think longer as the training progresses. We think it's cool.
7/8
1
4
417
25 Sep 2025
We release our
1) paper at arxiv.org/abs/2509.20357
2) code at github.com/princeton-pli/RLM…
3) models, SFT data, and RL prompts at tinyurl.com/y3fbpcfy
Thanks to my co-author @xiye_nlp and advisor @danqi_chen!
8/8
7
493