
Creator of new things.
Joined May 2024
- Tweets 84
- Following 269
- Followers 77
- Likes 110
2 Photos and videos
Mr. Agent retweeted

29 Jun 2024
❓What is an agent?
I get asked this question a lot, so I wrote a little blog on this topic and other things:
- What is an agent?
- What does it mean to be agentic?
- Why is “agentic” a helpful concept?
- Agentic is new
Check it out here: blog.langchain.dev/what-is-a…




14
41
328
57,754
Mr. Agent retweeted

30 Jun 2024
Do you know your LLM uses less than 1% of your GPU at inference? Too much time is wasted on KV cache memory access ➡️ We tackle this with the 🎁 Block Transformer: a global-to-local architecture that speeds up decoding up to 20x 🚀
@kaist_ai @LG_AI_Research w/ @GoogleDeepMind 🧵

12
113
616
74,066
Mr. Agent retweeted

23 Jun 2024
This page of common pytorch mistakes is pretty invaluable uvadlc-notebooks.readthedocs…

4
104
815
80,585
Mr. Agent retweeted

21 Jun 2024
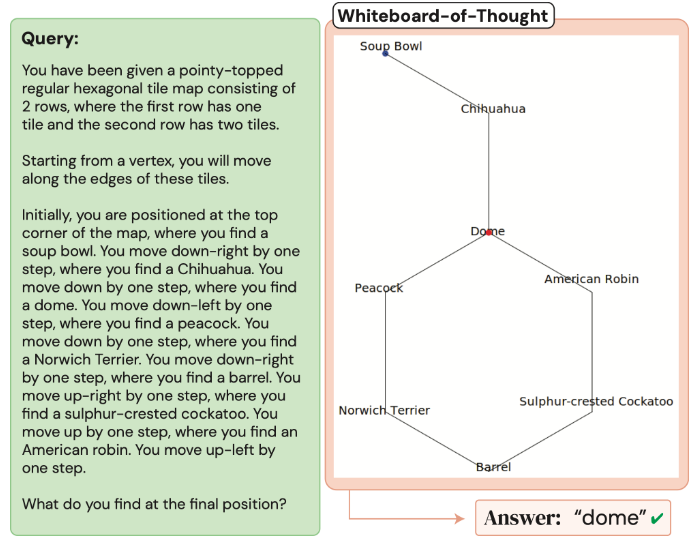
Whiteboard-of-Thought: Thinking Step-by-Step Across Modalities
Enables MLLMs to express intermediate reasoning as images using code. You probably didn't use typography knowledge to solve this query
proj: whiteboard.cs.columbia.edu/
abs: arxiv.org/abs/2406.14562
3
46
207
22,649

From RAG to Rich Parameters
Investigates more closely how LLMs utilize external knowledge over parametric information for factual queries.
Finds that in a RAG pipeline, LLMs take a “shortcut” and display a strong bias towards utilizing only the context information to answer the question, while relying minimally on their parametric memory.
Quote: "Through attention contributions, attention knockouts and causal traces, we specifically observe a reduced reliance on the subject token, and the MLP activations associated with it, when the context is augmented with RAG."
arxiv.org/abs/2406.12824

6
86
347
28,141
Mr. Agent retweeted

19 Jun 2024
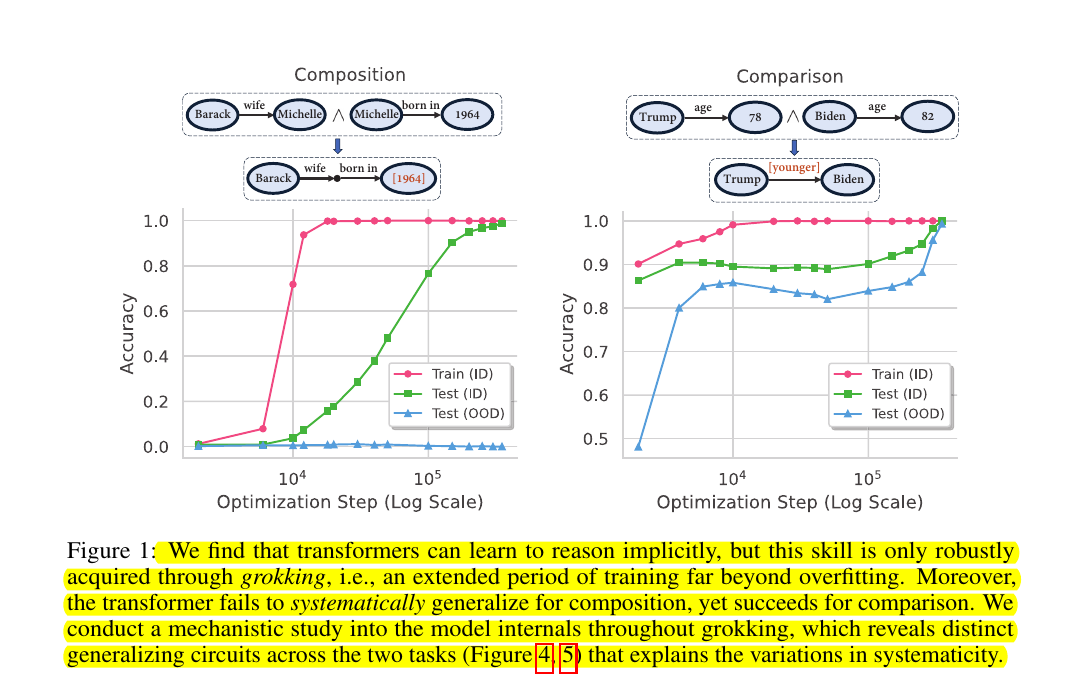
Transformer models can learn robust reasoning skills (beyond those of GPT-4-Turbo and Gemini-1.5-Pro) through a stage of training dynamics that continues far beyond the point of overfitting (i.e. with 'Grokking') 🤯
For a challenging reasoning task with a large search space, GPT-4-Turbo and Gemini-1.5-Pro based on non-parametric memory fail badly regardless of prompting styles or retrieval augmentation, while a fully grokked transformer can achieve near-perfect accuracy, showcasing the power of parametric memory for complex reasoning. 🤯
'Grokking' refers to a phenomenon where a transformer model continues to improve its generalization performance on a task through extended training, long after it has already fit the training data perfectly (i.e., achieved near-zero training loss).
👉Paper - "Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization"
📌 This paper investigates if transformers can learn to implicitly reason over parametric knowledge, a skill that even SoTA LLMs struggle with. The paper focuses on two types of reasoning - composition and comparison, and finds that transformers can learn implicit reasoning, but only through grokking, i.e. extended training far beyond overfitting. The levels of generalization vary across reasoning types: transformers fail to systematically generalize for composition but succeed for comparison when faced with out-of-distribution examples.
📌 Reveals: 1) The mechanism behind grokking, such as the formation of the generalizing circuit and its relation to the relative efficiency of generalizing vs memorizing circuits. 2) The connection between systematicity and the configuration of the generalizing circuit.
📌 For the composition task, the transformer forms a "sequential" generalizing circuit that stores atomic facts separately across layers, causing it to fail on out-of-distribution generalization. For the comparison task, the transformer forms a "parallel" generalizing circuit that stores atomic facts together, enabling it to achieve systematicity.
📌 The findings suggest that proper cross-layer memory-sharing mechanisms for transformers, such as memory-augmentation and explicit recurrence, are needed to further unlock the transformer's generalization capabilities.
8
32
276
31,348
Mr. Agent retweeted
19 Jun 2024
Google presents What Are the Odds? Language Models Are Capable of Probabilistic Reasoning
arxiv.org/abs/2406.12830

4
55
364
36,624
Mr. Agent retweeted

19 Jun 2024
A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges
Explores applications of LLMs in various financial tasks, discussing the challenges, opportunities, and resources for further development in this domain.
📝arxiv.org/abs/2406.11903


7
20
981
Mr. Agent retweeted
18 Jun 2024
I have lots of thoughts on "agents"!
❓What is an agent? Why do the basic agents not work reliably? How are teams bringing "agentic" applications to production
🙏I had a lot of fun talking about these topics (and more!) for nearly a hour with Sonya/Pat
open.spotify.com/episode/786…

7
58
251
43,642
Mr. Agent retweeted

18 Jun 2024
Learning Iterative Reasoning through Energy Diffusion
abs: arxiv.org/abs/2406.11179
project page: energy-based-model.github.io…
"IRED learns energy functions to represent the constraints between input conditions and desired outputs. After training, IRED adapts the number of optimization steps during inference based on problem difficulty, enabling it to solve problems outside its training distribution"

2
42
206
15,538
Mr. Agent retweeted
18 Jun 2024
Transcendence: Generative Models Can Outperform The Experts That Train Them
abs: arxiv.org/abs/2406.11741
Uses chess games as a simple testbed for studying transcedence: generative models trained on human labels that outperform humans.
Transformer models are trained on public datasets of human chess transcripts. To test for transcendence, the maximal rating of the human players in the dataset are limited to below a specified score. ChessFormer 1000 and ChessFormer 1300 achieve significant levels of transcendence, surpassing the maximal rating seen in the dataset.
The observation is that the generative models implicitly perform majority voting over the human experts. Sampling with low-temperature also implicitly induces this majority vote phenomenon and this is where transcendence is observed.

6
76
301
29,292
Mr. Agent retweeted

17 Jun 2024
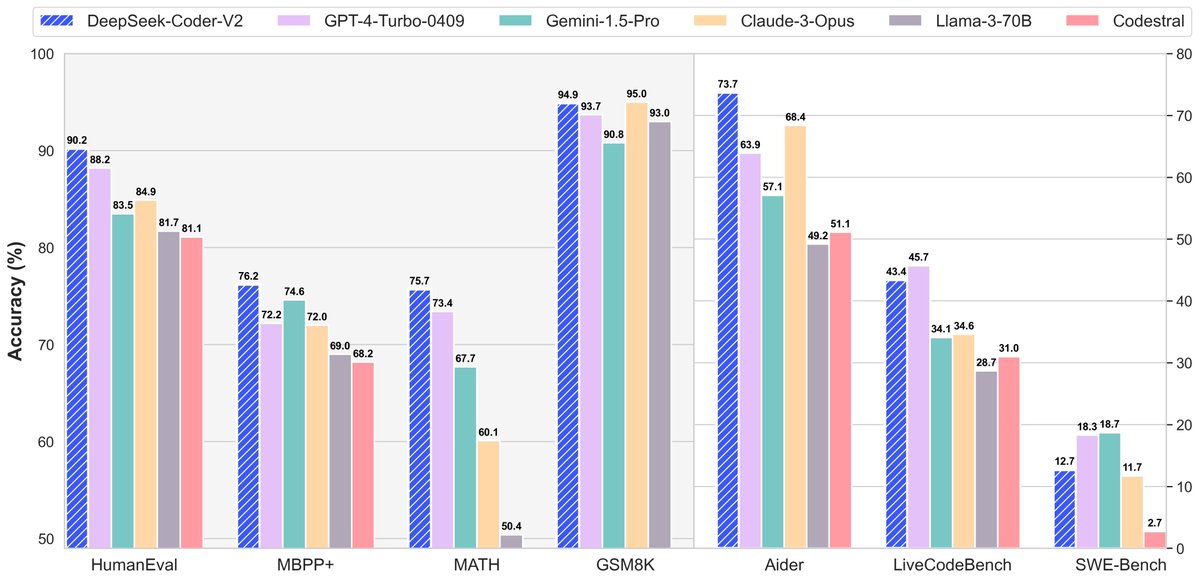
DeepSeek-Coder-V2: First Open Source Model Beats GPT4-Turbo in Coding and Math
> Excels in coding and math, beating GPT4-Turbo, Claude3-Opus, Gemini-1.5Pro, Codestral.
> Supports 338 programming languages and 128K context length.
> Fully open-sourced with two sizes: 230B (also with API access) and 16B.
#DeepSeekCoder
61
323
1,616
488,465
Mr. Agent retweeted
18 Jun 2024
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
Reveals several important insights into the dynamics of factual knowledge acquisition during pretraining
arxiv.org/abs/2406.11813

6
74
405
54,521
Mr. Agent retweeted
12 Jun 2024
Google presents Improve Mathematical Reasoning in Language Models by Automated Process Supervision
- MCTS for the efficient collection of high-quality process supervision data
- 51% -> 69.4% on MATH
- No human intervention
arxiv.org/abs/2406.06592

5
57
341
35,749
Mr. Agent retweeted

12 Jun 2024
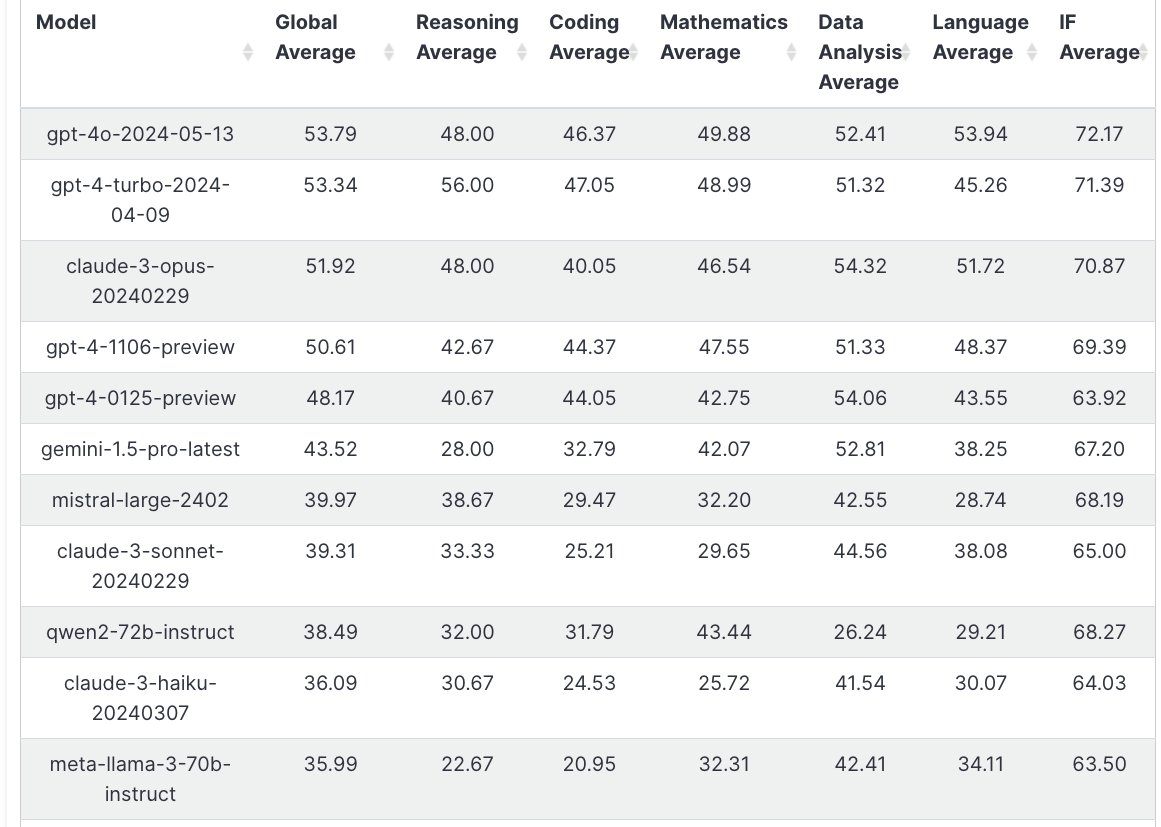
Announcing LiveBench AI - The WORLD'S FIRST LLM Benchmark That Can't Be Gamed!!
We (Abacus AI) partnered with Yann LeCunn and his team to create LiveBench AI!
LiveBench is a living/breathing benchmark with new challenges that you CAN'T simply memorize. Unlike blind human eval, you can't fine-tune or style-hack your LLM to ace simple human conversations.
We evaluate LLMs on different dimensions, including reasoning, coding, writing, and data analysis.
The key reason behind introducing LiveBench is that you can disambiguate LLMs better. Here are some key findings
- GPT-4o inches out GPT-4-turbo.
- Claude Opus excels at data analysis and language understanding
- Gemini doesn't score as well as Claude or GPT-4 as it does on Lmsys. This means, generally speaking, Gemini isn't as good as Claude or GPT
- GPT-4 does much better at reasoning and coding than GPT-4o. We and other labs have reported this before, as well
- Qwen 72B is the best open-source model
This benchmark serves as LLMs' independent, objective, and TRANSPARENT ranking.
We are excited to maintain this living benchmark and hope the other models catch up to GPT-4 on these hard questions.
ALT http://livebench.ai
89
183
903
301,348

Husky
A Unified, Open-Source Language Agent for Multi-Step Reasoning
Language agents perform complex tasks by using tools to execute each step precisely. However, most existing agents are based on proprietary models or designed to target specific tasks, such as

3
75
321
34,949
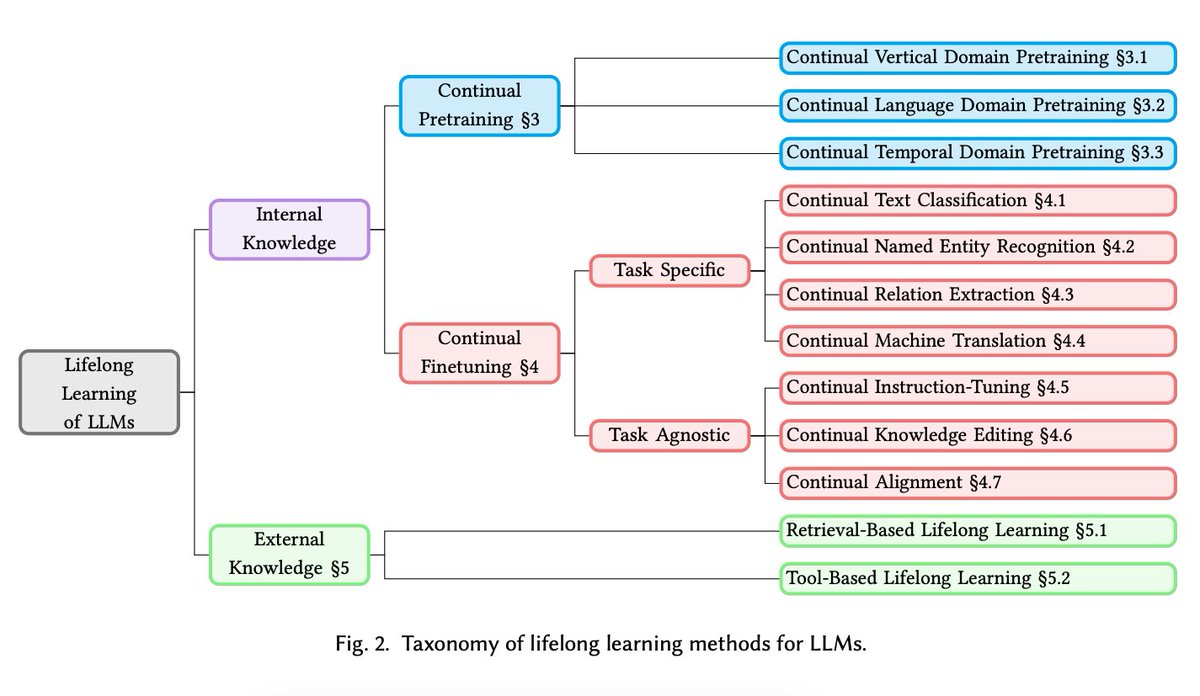
Towards Lifelong Learning of LLMs
Nice survey on techniques to enable LLMs to learn continuously, integrate new knowledge, retain previously learned information, and prevent catastrophic forgetting.
arxiv.org/abs/2406.06391
6
83
342
30,409
Mr. Agent retweeted
12 Jun 2024
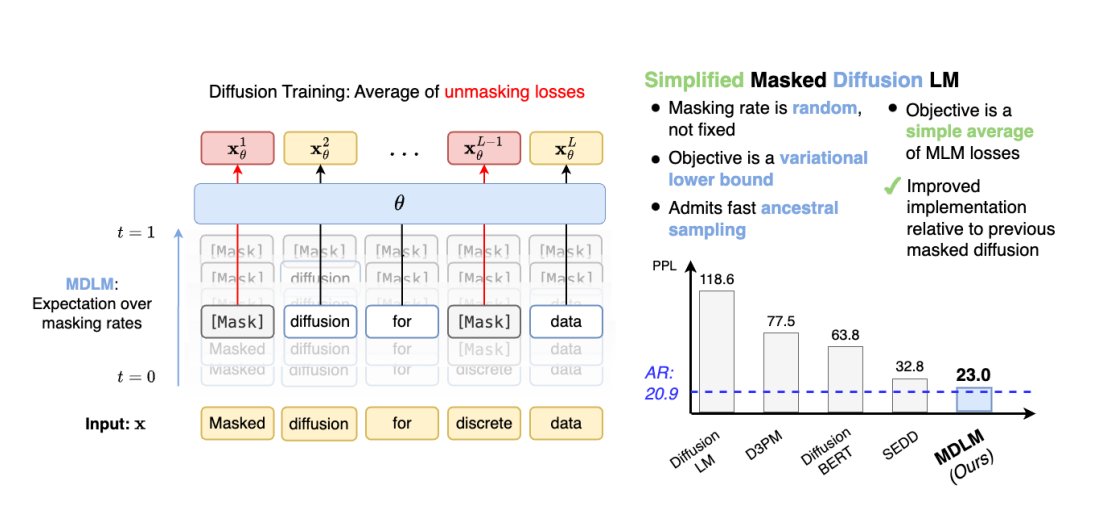
Simple and Effective Masked Diffusion Language Models
Achieves a new SotA among diffusion models on a range of LM tasks and approaches AR perplexity
repo: github.com/kuleshov-group/md…
abs: arxiv.org/abs/2406.07524
5
59
253
40,929
Mr. Agent retweeted

11 Jun 2024
BREAKING: Mistral raises a $640M Series B led by General Catalyst at a $6B valuation.
Here's their Seed pitch deck to remind you of their vision:

22
166
1,192
284,208
Mr. Agent retweeted
12 Jun 2024
Synthetic Query Generation using Large Language Models for Virtual Assistants
Apple investigates the use of LLMs to generate synthetic queries for virtual assistants that are similar to real user queries and specific to retrieving relevant entities.
📝arxiv.org/abs/2406.06729




15
76
6,184