
Bioinformatics scientist @AllenInstitute. PhD in computational biology from @BrownCCMB @BrownUniversity. Previously at @illumina. he/him
Joined August 2018
- Tweets 359
- Following 1,326
- Followers 288
- Likes 1,878
23 Photos and videos



Alan DenAdel retweeted

Excited to share our latest in Nature Genetics with @soumyakundu_ @anshulkundaje and Stephen Montgomery !
We built a resource of predicted variant effects on chromatin accessibility, and FLARE to identify disease variants with extreme regulatory effects.
nature.com/articles/s41588-0…
3
32
109
14,921
Alan DenAdel retweeted

Jun 11
Our stream for Single Cell Genomics Day goes live tomorrow morning at satijalab.org/scgd , look forward to seeing you there for our 10th year!

25
103
10,882

Let’s discuss the scaling law of virtual cells.
A Nature Methods paper (nature.com/articles/s41592-0…) published yesterday is being interpreted by some as evidence that scaling laws do not hold for virtual cells. I read it in detail, and here are my 2 cents:
It is a useful benchmark, but not a direct test of scaling laws in causal single-cell foundation models or perturbation-native virtual cells.
The paper mainly studies PCA, scVI, Geneformer, and SCimilarity (which are relative small models) on observational atlas-style pretraining, with perturbation evaluation limited to a narrow Tahoe small-molecule/cancer-cell-line setting. These are important baselines on scFMs that focuses on learning cell embeddings, but they are not large-scale causal perturbation models (e.g, diffusion-based virtual cells, or other modern architectures designed natively for causal perturbation biology).
The metrics also matter. Cell-type F1 and batch-integration AvgBIO are reasonable atlas/embedding metrics, but they are also tasks that can saturate quickly. They are not direct measures of causal perturbation prediction, target ranking, rare differential-expression tails, OOD genetic perturbations, or generalization across biological contexts.
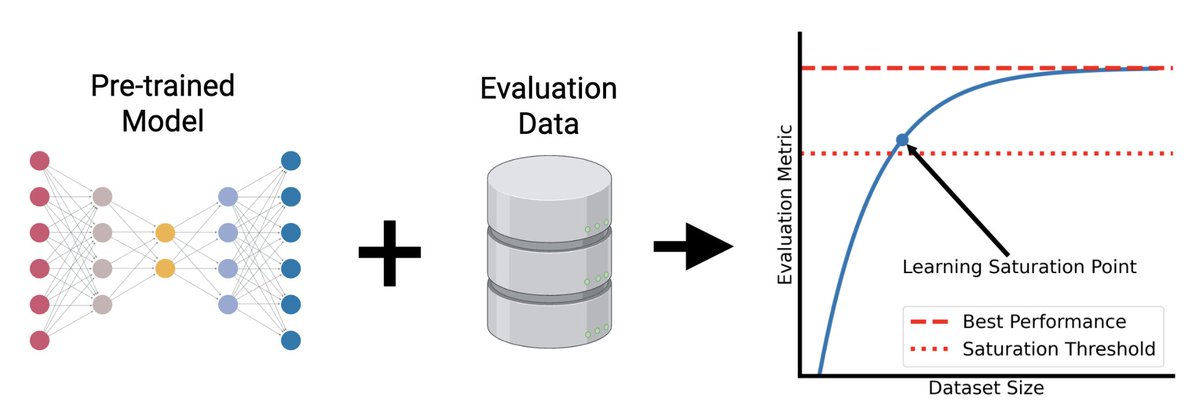
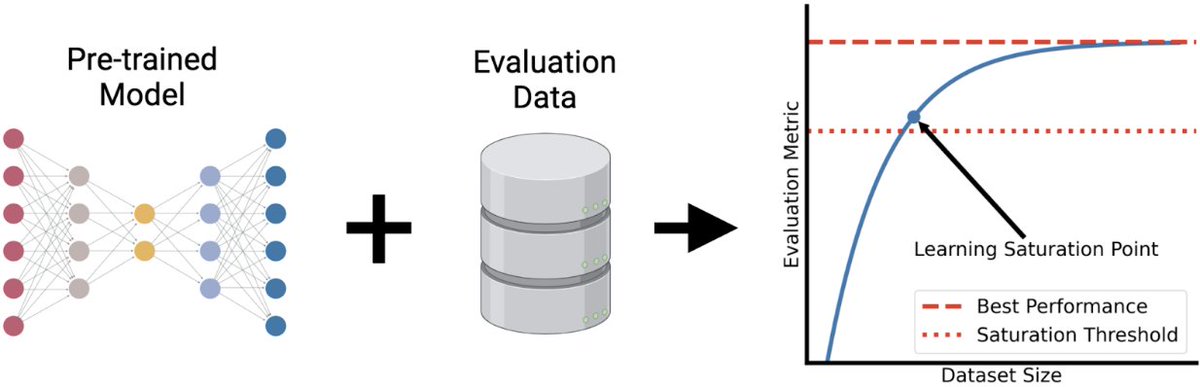
The “learning saturation point” in the paper is useful, but it is not really a scaling law. It asks: what is the smallest pretraining size that reaches within 95% of the best observed score on this benchmark? That is a helpful diagnostic, but it can be overinterpreted when the downstream task itself is saturated.
The perturbation result is, IMO, limited: a few selected Tahoe-100M small molecules across several cancer cell lines, evaluated with genewise R²/MSE. The paper itself reports that a “no-change” baseline beats fine-tuned models for most drugs, which says as much about the evaluation regime as about model scaling.
In fact, our scGPT work already showed three years ago that simply scaling the number of observational cells saturates quickly after a few million cells. So I agree with the warning: naive “more atlas cells = better virtual cell” is not enough.
But that is not the real scaling question.
In X-Cell, we study scaling across multiple axes: number of perturbation cells, number of biological contexts, perturbation diversity, and model parameters. On our Perturb-seq-scale data, we observe clear and encouraging scaling behavior. Similar trends are emerging from other perturbation-native virtual cell efforts as well.
The important question is not: can more atlas cells improve cell-type F1? It is: with larger Perturb-seq datasets, larger models, better architectures, and harder OOD splits, can we predict causal cellular responses across genes, combinations, doses, cell states, and contexts?
For X-Cell and the next generation of virtual-cell models, the goal is not just better embeddings. It is target ranking, rare DE tails, counterfactual biology, and prospective perturbation prediction.
So my reading is: this paper is a useful caution against naive scaling, not evidence that scaling laws do not apply to virtual cells.
The exciting regime is still open: scaling the right data, the right models, and the right objectives for causal cellular biology.
2
21
136
16,289
Alan DenAdel retweeted

Jun 11
SAGE-net: a scalable, efficient sequence-to-function modeling framework for personal genome analysis.
nature.com/articles/s41592-0…
9
48
5,568
Alan DenAdel retweeted

Jun 11
I think something we miss is that by only assessing the value of the data within the scope of foundation models we miss that the data itself is inherently useful - depending on what perturbations you put into it and what questions you ask of it. I think this is only a very narrow way to consider the question; of course it is an important question to ask as a sanity check as we move forward.
1
1
4
415
Alan DenAdel retweeted

Jun 10
"No scaling laws for scFMs" is too strong a takeaway from this. They test one transformer scFM (Geneformer, 2023), probe frozen embeddings instead of fine-tuning, and score perturbation by mean-expression R² , the metric where "predict no change" wins by default. That's evidence the objective saturates, not that scale can't help. We need better pretraining objectives that make biological signal scale.
Jun 9

No scaling laws for single-cell foundation models: when bigger atlases stop teaching the model anything
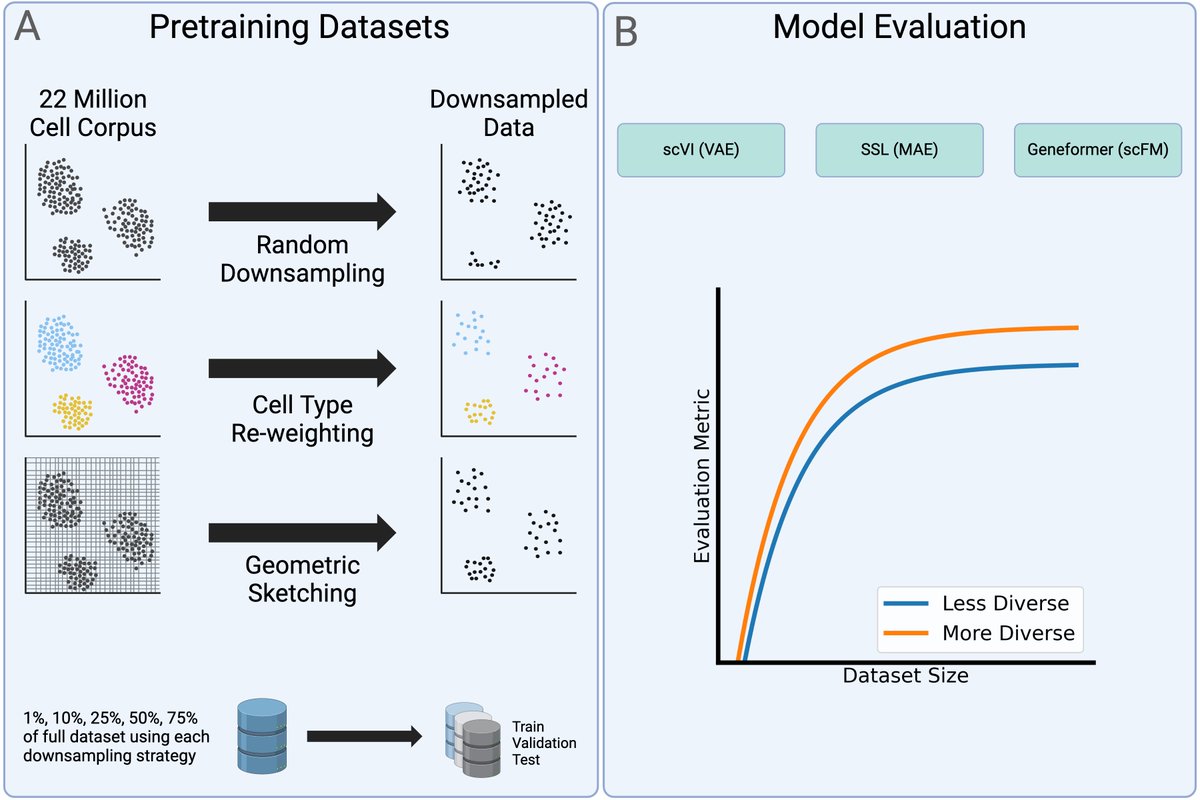
In language and vision, the recipe has been simple: more data, bigger models, better performance. Single-cell biology borrowed that playbook. Foundation models for transcriptomics jumped from 1 million cells to atlases of over 100 million, on the assumption that scale would unlock the same gains. Alan DenAdel and coauthors put that assumption to the test, and the result is sobering.
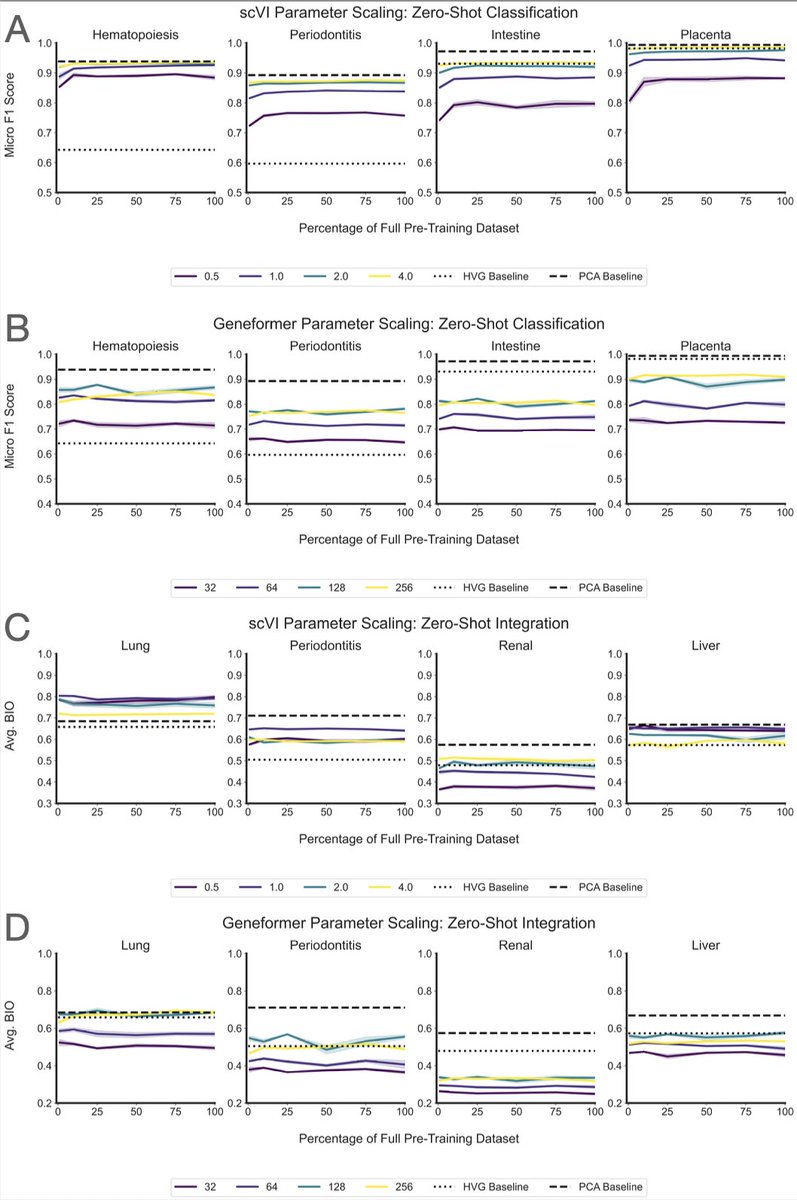
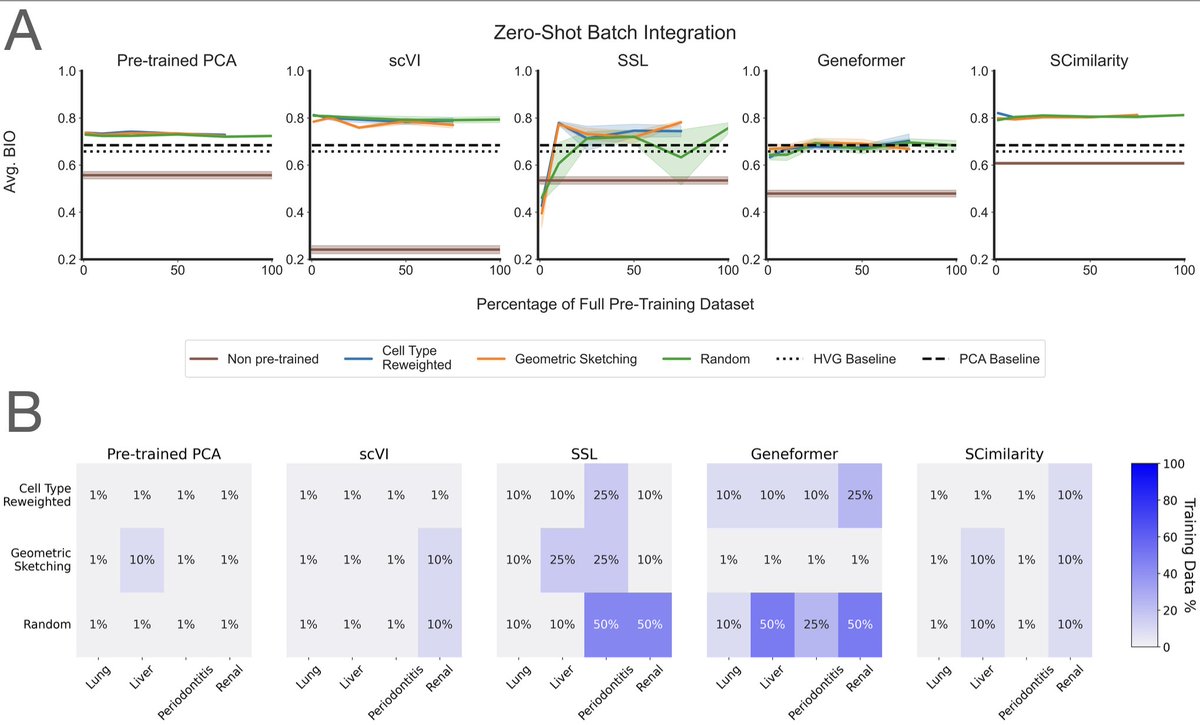
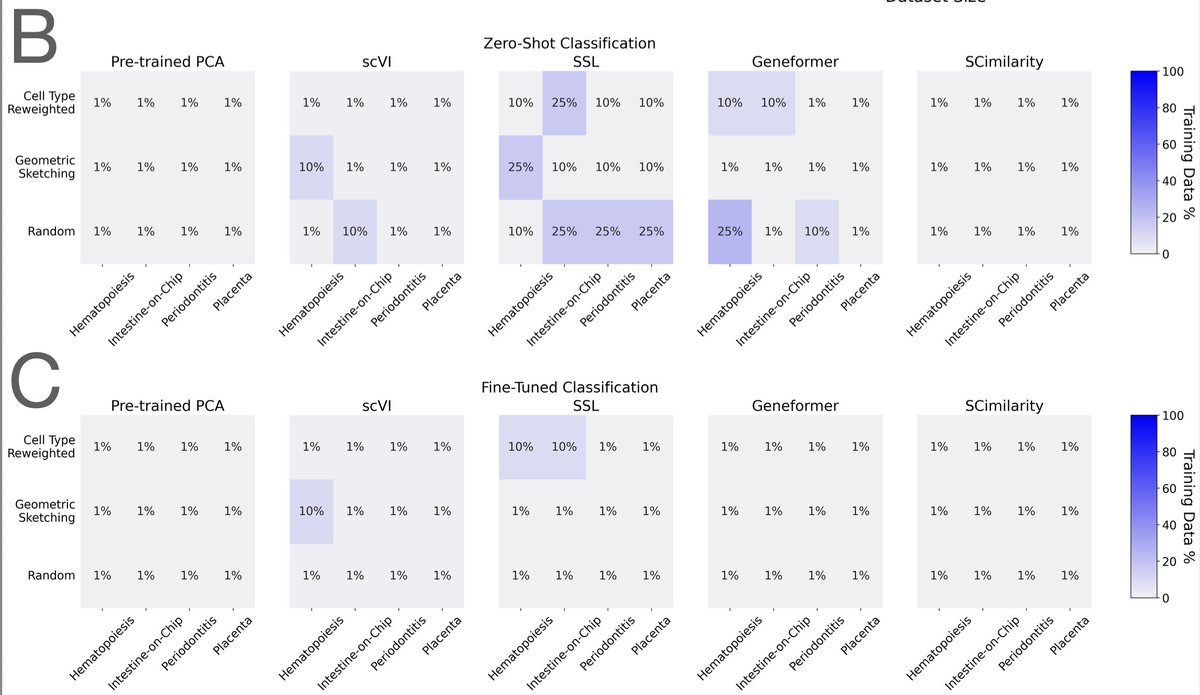
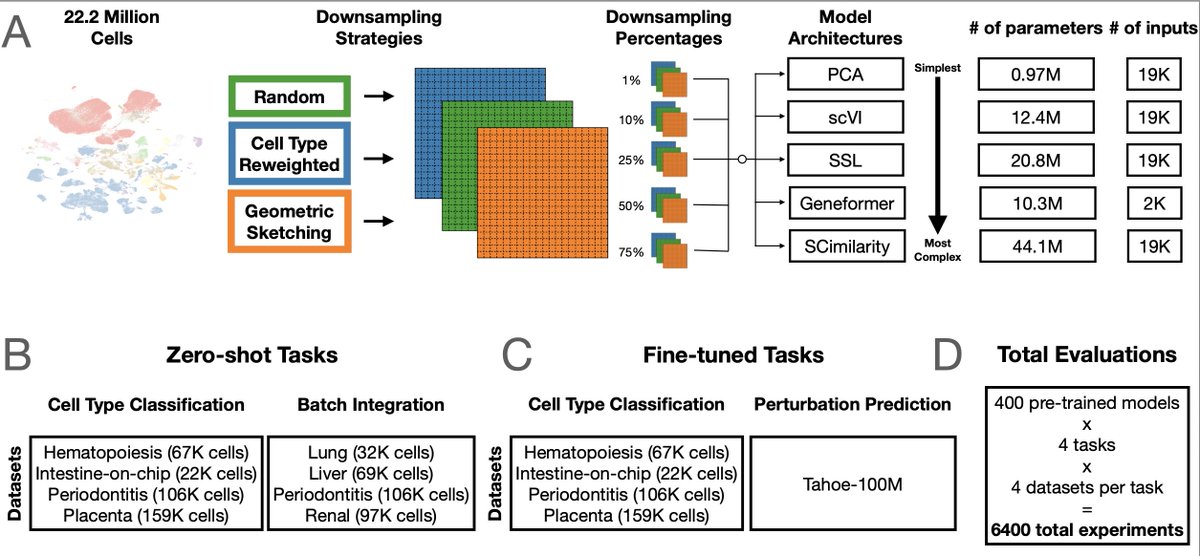
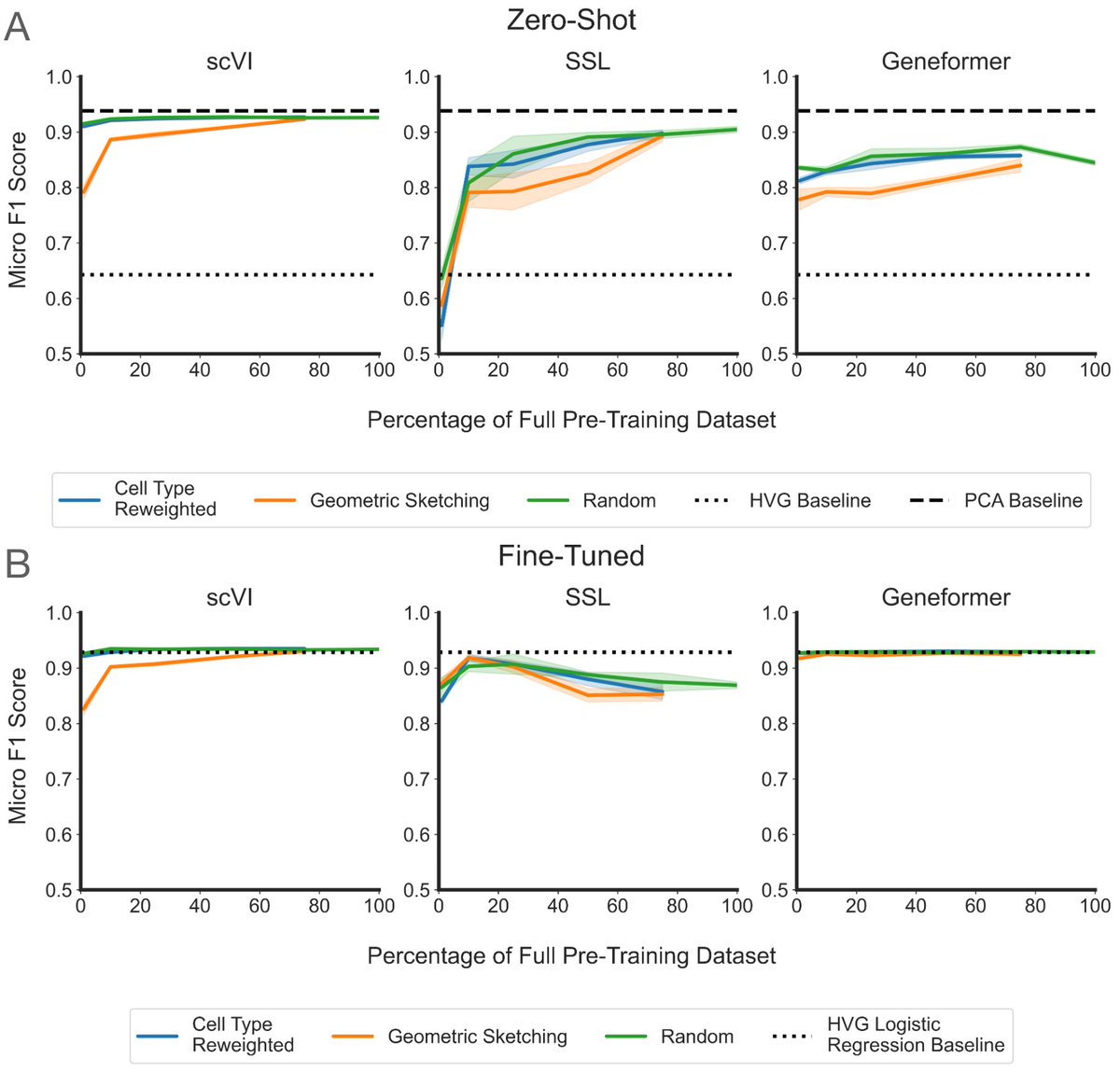
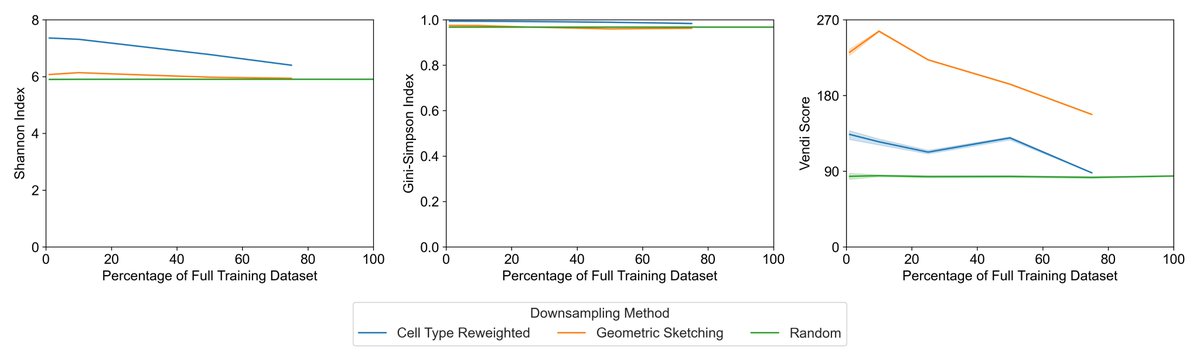
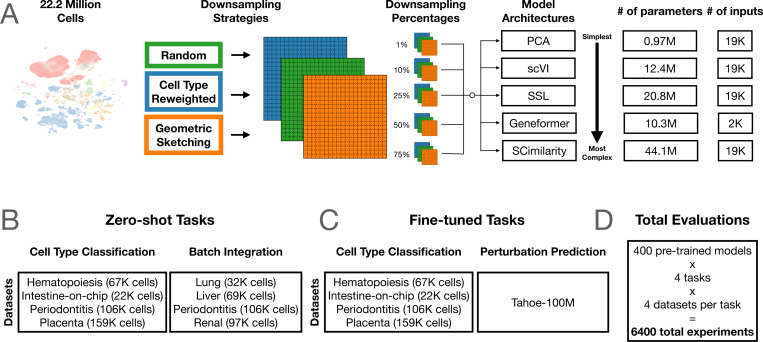
Working from a 22.2-million-cell corpus, they pretrained 400 models across five architectures (from PCA and a variational autoencoder up to the Geneformer transformer) and ran 6,400 evaluation experiments. They varied not just dataset size (1% to 75%) but also diversity, using cell-type re-weighting and geometric sketching to deliberately enrich rare cell types and transcriptional states.
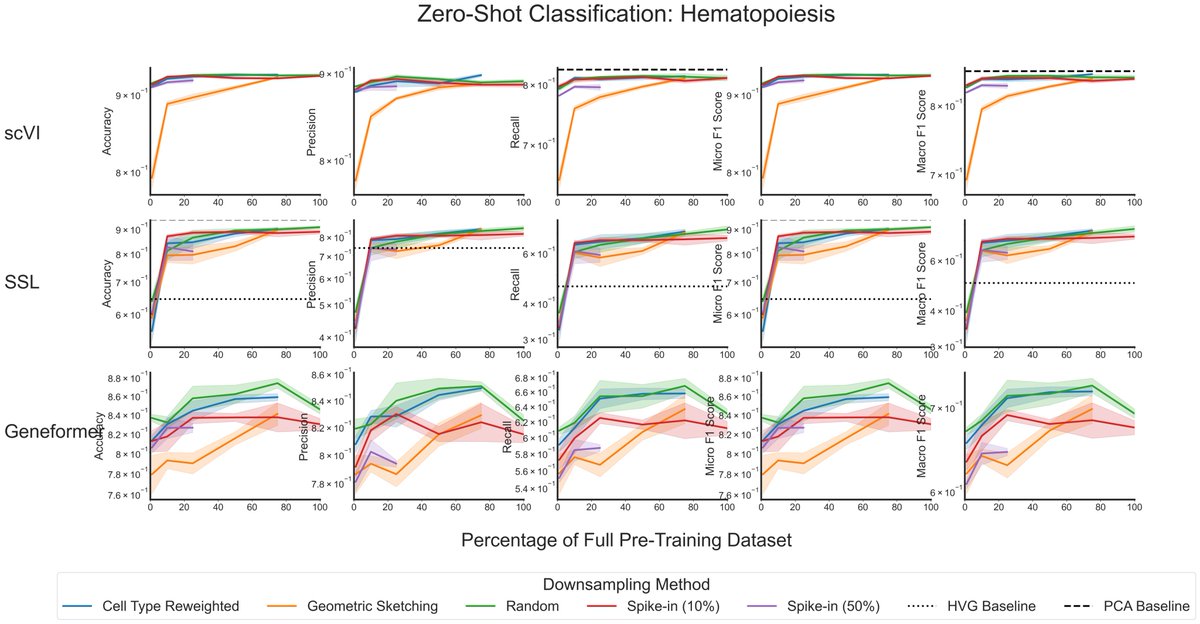
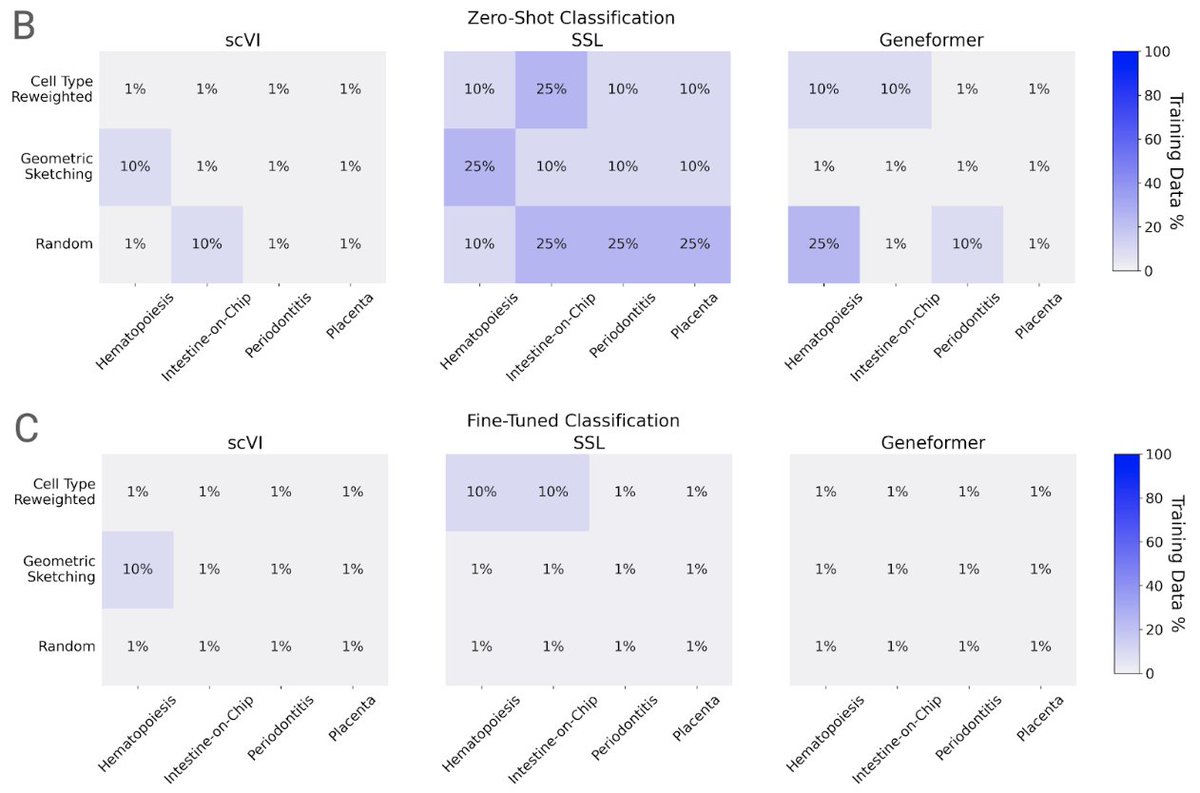
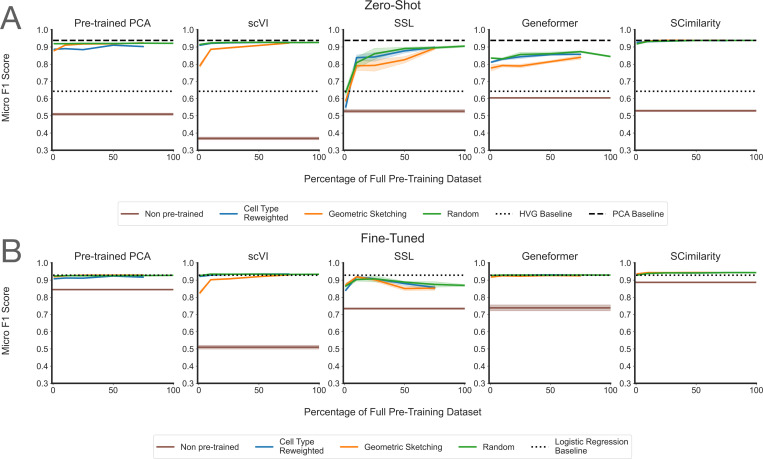
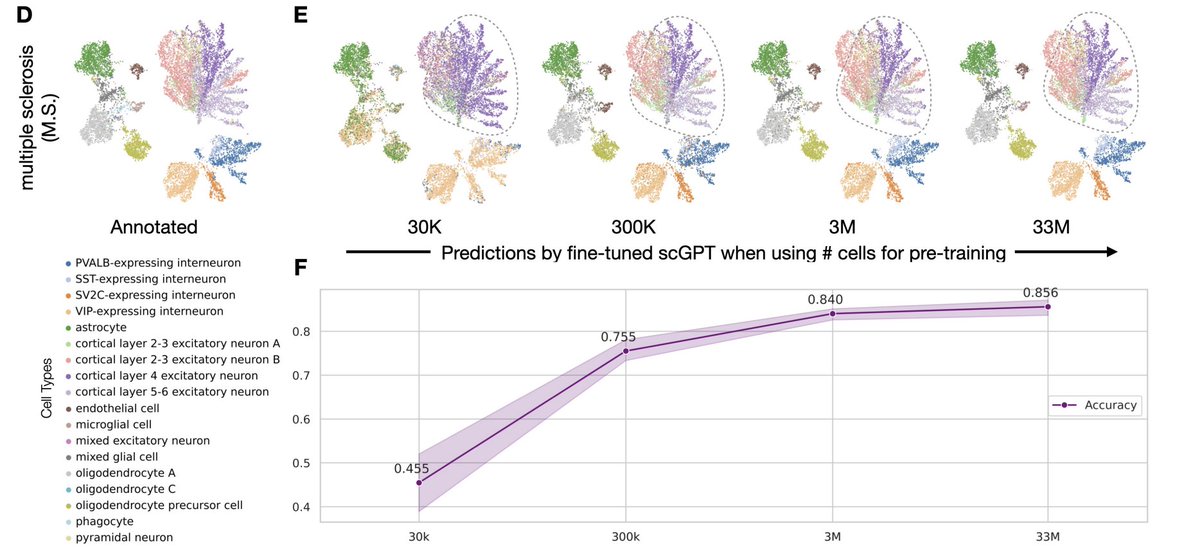
The finding: performance saturates almost immediately. On cell-type classification, batch integration, and perturbation prediction, most models hit their ceiling at roughly 1% of the corpus, about 200,000 cells. Beyond that, adding millions more cells changed essentially nothing. More diversity didn't help. Even spiking in genome-scale Perturb-seq data, to give the models perturbed phenotypes rather than just healthy ones, failed to move the needle. Larger models did score better overall, but they too plateaued early on data.
Two points stood out. Simple baselines (PCA, logistic regression) often matched or beat the transformers. And the strongest model, SCimilarity, won not because of size but because its contrastive training objective is aligned with the downstream task. For single-cell data, what you train on and how you frame the objective matters far more than how much you collect.
This reframes a quiet but expensive habit. In drug discovery, biotech, and any pipeline leaning on cell atlases, the instinct to keep scaling pretraining corpora may be burning compute for no return. The real leverage sits elsewhere: curating high-quality, task-relevant data and matching the training objective to the actual question you're trying to answer.
Paper: DenAdel et al., journal license | doi.org/10.1038/s41592-026-0…

1
2
15
1,863
Alan DenAdel retweeted

Jun 10
The success of transformer-based models on natural language and images has motivated their use in single-cell transcriptomics.
The results in this article show that current methods tend to plateau in performance with pretraining datasets that are only a fraction of the size of current training corpora.
Single-cell models show no clear data scaling laws, indicating that developers should focus on balancing model capacity, dataset size and computational resources rather than indiscriminately increasing all three.
nature.com/articles/s41592-0…
2
8
755
Alan DenAdel retweeted
Jun 10
I never expect counting RNAs in ever more single cells to scale model performance very far.
Now, the evidence is in.
This large new study finds that performance gains from single-cell transcriptomic models plateau well before the largest training set sizes.
The evidence suggests that scaling RNA counts alone is insufficient.
Scientific progress depends not only on measuring more samples, but also on measuring the variables that regulate biological systems.

3
19
97
8,529
Alan DenAdel retweeted

Jun 10
Can’t believe I missed this when it was a pre-print. My favorite type of finding to point at when I’m arguing for a smaller replicate-rich dataset specific to the task the team actually cares about (vs trying to build out full virtual cells for every task)
Jun 9
No scaling laws for single-cell foundation models: when bigger atlases stop teaching the model anything
In language and vision, the recipe has been simple: more data, bigger models, better performance. Single-cell biology borrowed that playbook. Foundation models for transcriptomics jumped from 1 million cells to atlases of over 100 million, on the assumption that scale would unlock the same gains. Alan DenAdel and coauthors put that assumption to the test, and the result is sobering.
Working from a 22.2-million-cell corpus, they pretrained 400 models across five architectures (from PCA and a variational autoencoder up to the Geneformer transformer) and ran 6,400 evaluation experiments. They varied not just dataset size (1% to 75%) but also diversity, using cell-type re-weighting and geometric sketching to deliberately enrich rare cell types and transcriptional states.
The finding: performance saturates almost immediately. On cell-type classification, batch integration, and perturbation prediction, most models hit their ceiling at roughly 1% of the corpus, about 200,000 cells. Beyond that, adding millions more cells changed essentially nothing. More diversity didn't help. Even spiking in genome-scale Perturb-seq data, to give the models perturbed phenotypes rather than just healthy ones, failed to move the needle. Larger models did score better overall, but they too plateaued early on data.
Two points stood out. Simple baselines (PCA, logistic regression) often matched or beat the transformers. And the strongest model, SCimilarity, won not because of size but because its contrastive training objective is aligned with the downstream task. For single-cell data, what you train on and how you frame the objective matters far more than how much you collect.
This reframes a quiet but expensive habit. In drug discovery, biotech, and any pipeline leaning on cell atlases, the instinct to keep scaling pretraining corpora may be burning compute for no return. The real leverage sits elsewhere: curating high-quality, task-relevant data and matching the training objective to the actual question you're trying to answer.
Paper: DenAdel et al., journal license | doi.org/10.1038/s41592-026-0…
1
15
2,928
Alan DenAdel retweeted

Jun 9
🧬🔬

Jun 9

Today in @naturemethods, we shared research on how AI can help us better understand cell behavior, offering new insights into why cancer medicines do not work the same for everyone.
By learning more about cell state — how individual cancer cells respond to their surroundings — we have the potential to match therapies more precisely to each patient and improve outcomes. news.microsoft.com/signal/ar…
1
9
58
11,602
Alan DenAdel retweeted

Jun 9
Unfortunately, most patients don't get lasting benefit from treating cancer by mutations alone. A signal we were missing is visible in cell state, and doing something about it quickly turns into a high-dimensional control problem. We've spent years building a unified model that can reason about cell state (among other things). Project Ex-Vivo is the first time we have seen it at work.
Jun 9
Today in @naturemethods, we shared research on how AI can help us better understand cell behavior, offering new insights into why cancer medicines do not work the same for everyone.
By learning more about cell state — how individual cancer cells respond to their surroundings — we have the potential to match therapies more precisely to each patient and improve outcomes. news.microsoft.com/signal/ar…
1
2
37
9,247
Alan DenAdel retweeted

Jun 9
Today in @naturemethods, we shared research on how AI can help us better understand cell behavior, offering new insights into why cancer medicines do not work the same for everyone.
By learning more about cell state — how individual cancer cells respond to their surroundings — we have the potential to match therapies more precisely to each patient and improve outcomes. news.microsoft.com/signal/ar…
90
131
576
193,188
Alan DenAdel retweeted

Excited to share our latest work out today in @naturemethods where we systematically evaluate how increasing pre-training dataset size influences single-cell foundation models and their downstream tasks.
nature.com/articles/s41592-0…
2
23
89
7,198
Alan DenAdel retweeted

Jun 9
No scaling laws for single-cell foundation models: when bigger atlases stop teaching the model anything
In language and vision, the recipe has been simple: more data, bigger models, better performance. Single-cell biology borrowed that playbook. Foundation models for transcriptomics jumped from 1 million cells to atlases of over 100 million, on the assumption that scale would unlock the same gains. Alan DenAdel and coauthors put that assumption to the test, and the result is sobering.
Working from a 22.2-million-cell corpus, they pretrained 400 models across five architectures (from PCA and a variational autoencoder up to the Geneformer transformer) and ran 6,400 evaluation experiments. They varied not just dataset size (1% to 75%) but also diversity, using cell-type re-weighting and geometric sketching to deliberately enrich rare cell types and transcriptional states.
The finding: performance saturates almost immediately. On cell-type classification, batch integration, and perturbation prediction, most models hit their ceiling at roughly 1% of the corpus, about 200,000 cells. Beyond that, adding millions more cells changed essentially nothing. More diversity didn't help. Even spiking in genome-scale Perturb-seq data, to give the models perturbed phenotypes rather than just healthy ones, failed to move the needle. Larger models did score better overall, but they too plateaued early on data.
Two points stood out. Simple baselines (PCA, logistic regression) often matched or beat the transformers. And the strongest model, SCimilarity, won not because of size but because its contrastive training objective is aligned with the downstream task. For single-cell data, what you train on and how you frame the objective matters far more than how much you collect.
This reframes a quiet but expensive habit. In drug discovery, biotech, and any pipeline leaning on cell atlases, the instinct to keep scaling pretraining corpora may be burning compute for no return. The real leverage sits elsewhere: curating high-quality, task-relevant data and matching the training objective to the actual question you're trying to answer.
Paper: DenAdel et al., journal license | doi.org/10.1038/s41592-026-0…
15
93
384
96,264

Jun 9
I'm exited to share that our paper investigating how increased pre-training dataset size influences single-cell foundation model performance impacts performance on downstream tasks has been published at Nature Methods!
nature.com/articles/s41592-0…
2
1
5
750
Jun 9
A special thanks to my PhD advisor @lorin_crawford and to @avapamini, @peterswinter, and Srivatsan Raghavan, for the mentorship and collaboration during my PhD work. Their lab, Ex Vivo, was also featured by Microsoft today
news.microsoft.com/signal/ar…
1
1
95
Jun 9
Here is my previous thread walking through the work.
x.com/AlanDenadel/status/198…
7 Nov 2025

We have recently uploaded our revised manuscript “Evaluating the role of pre-training dataset size and diversity on single-cell foundation model performance”.
TL;DR: More models, more tasks => same results.
1
60
Alan DenAdel retweeted

Brain disease is tragic, but it doesn’t have to be. It’s time for a new approach to #brainhealth research.
That’s why we and our partners are launching the Brain Health accelerator.
1
5
24
5,641
Alan DenAdel retweeted

Jun 2
Today I am proud to announce the launch of the Brain Health Accelerator, a global initiative to transform our understanding of brain disease and accelerate the development of new treatments.
For more than 20 years, the @AllenInstitute has built foundational data, tools, technologies, and knowledge that have helped reshape neuroscience. Today, we are taking the next step: bringing together scientists, clinicians, technologists, AI experts, patient advocates, philanthropists, and industry partners around a shared mission to tackle some of the world’s most devastating brain diseases.
#BrainHealth will initially focus on Alzheimer’s disease, Parkinson’s disease, Huntington’s disease, ALS, and Lewy body disease, while building a radically open and collaborative framework designed to accelerate progress across many neurological disorders.
This effort launches with a total commitment of more than $400 million, including $200 million from the Allen Institute (supported by the Fund for Science and Technology), $100 million from the Bezos family, and an additional $100 million from @awscloud, @NIH-supported programs, and @Everything_ALS.
We believe the future of brain health will be built through unprecedented collaboration, cutting-edge biology, advanced AI, and open science.
Science unites us. Together, we can go farther and create a healthier world.
#BrainHealth #Neuroscience #OpenScience #AI #BrainInitiative #NIH #Neurodegeneration #Alzheimers #LewyBodyDisease #Parkinsons #ALS #HuntingtonsDisease

5
26
134
12,857