
Professor, UC berkeley | Founder @bespokelabsai |
Joined April 2009
- Tweets 4,577
- Following 2,627
- Followers 23,540
- Likes 30,424
253 Photos and videos














Jun 4
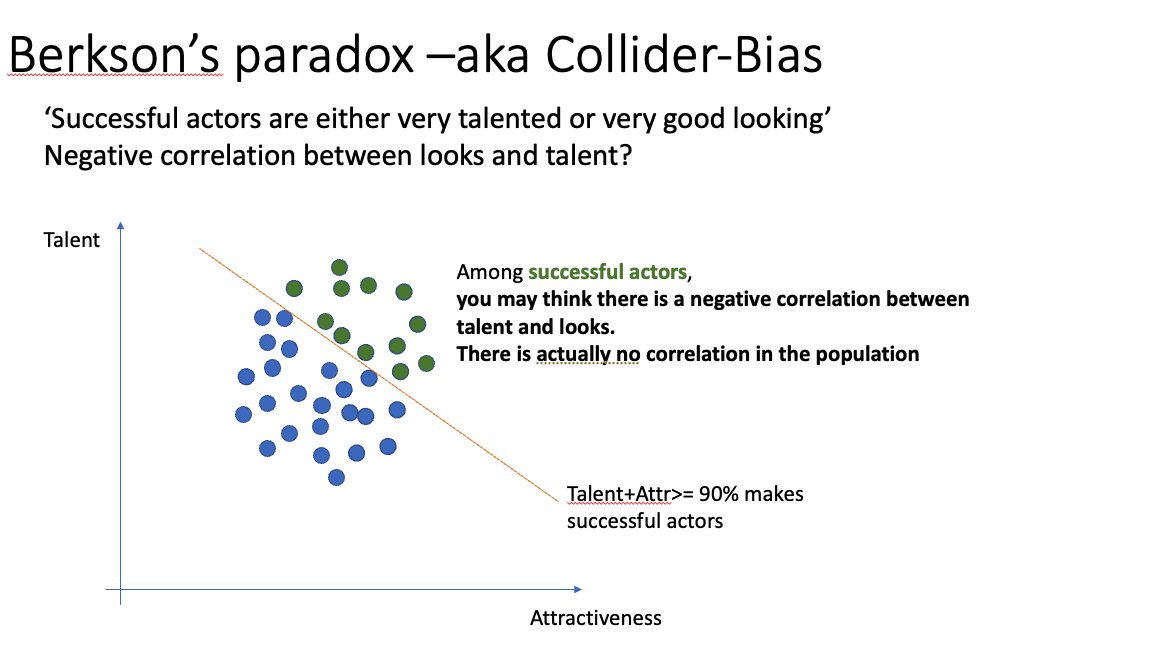
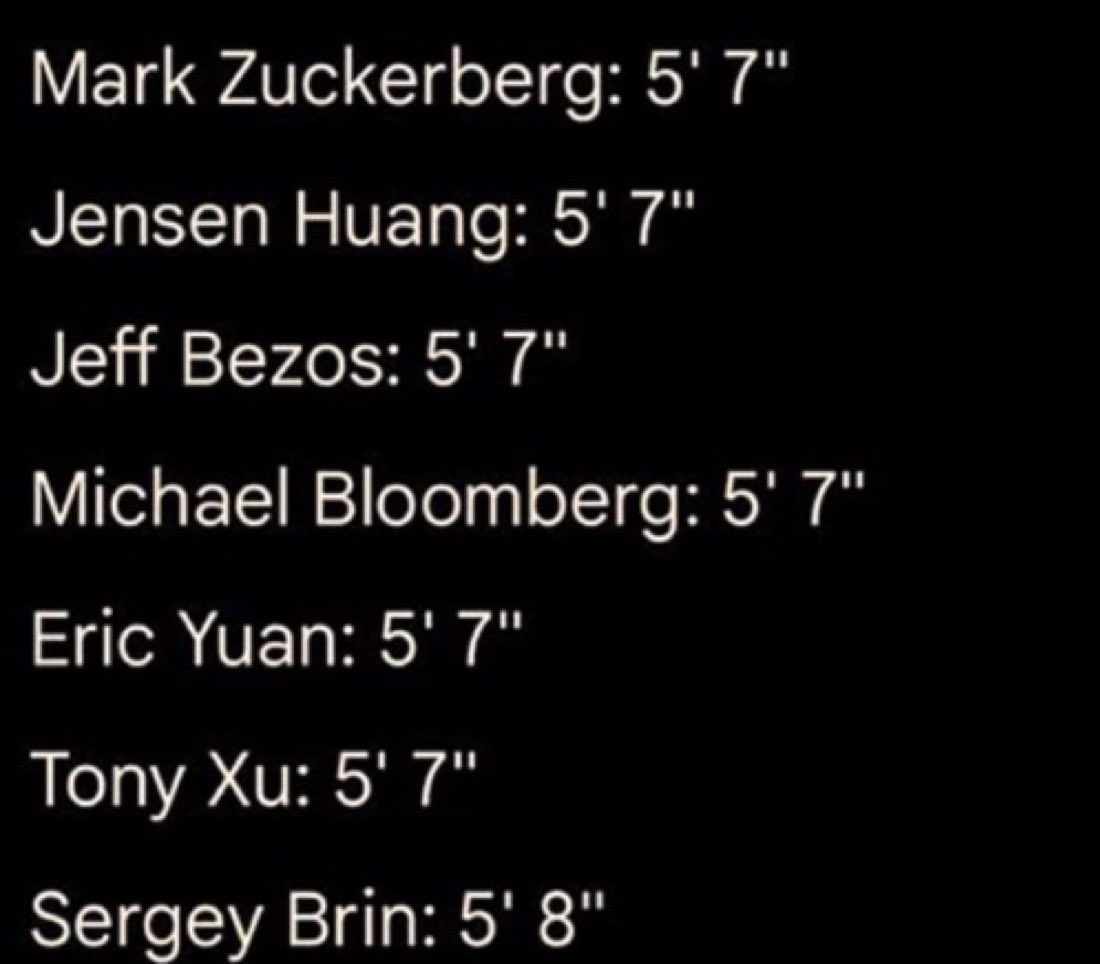
Best predictor of startup success ever. (Jus’saying)

4
20
7,931
Alex Dimakis retweeted

I'm excited to share that I'll be @bespokelabsai this Summer building out some exciting RL environments! Huge thanks to @madiator and @AlexGDimakis for the opportunity. Excited to work with you all! :)
3
3
33
4,855
Alex Dimakis retweeted

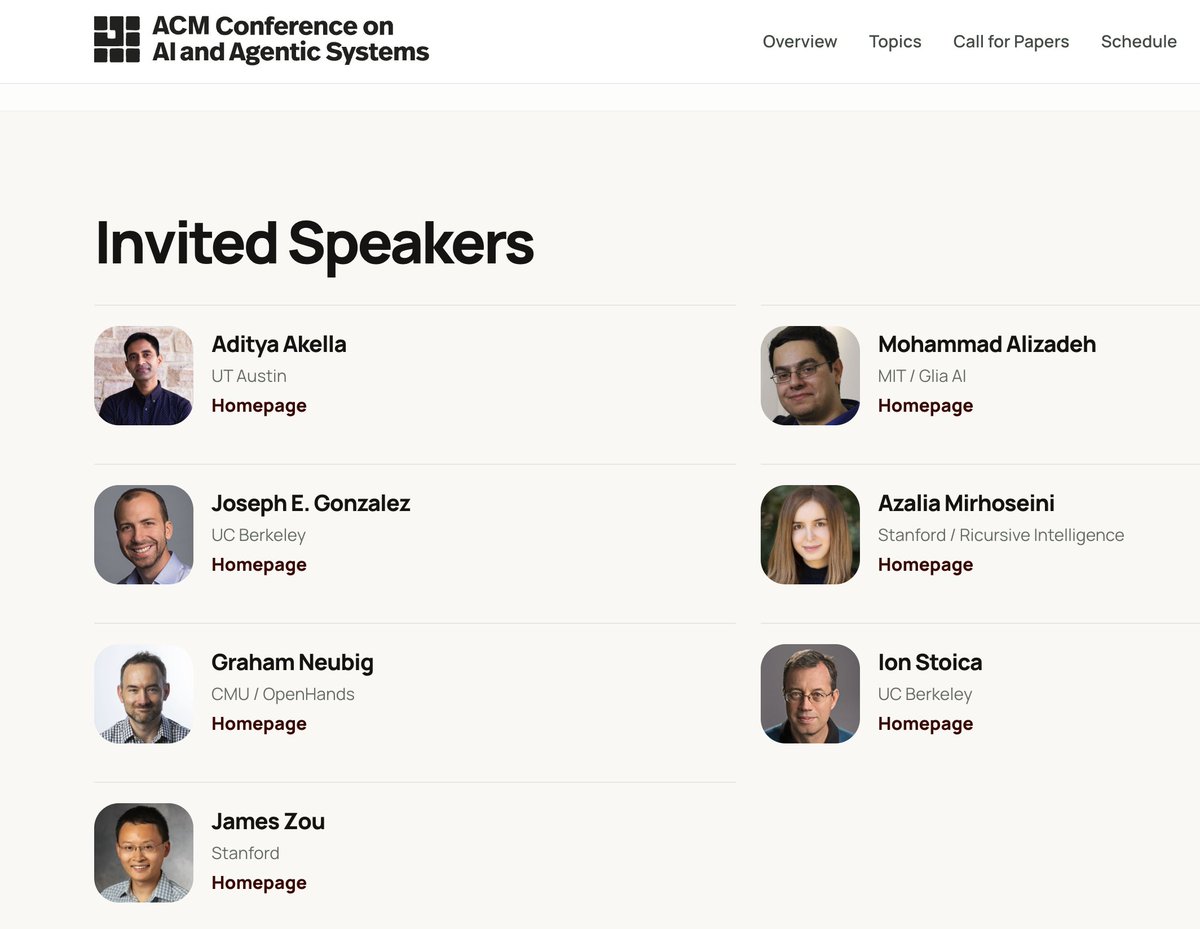
Workshop on Responsibly Enabling Data for Foundation Models at #COLM2026 October 9 in SF
"Unlocking sensitive data sources responsibly for the next generation of AI"
- Amazing invited speakers 😍
- Submission deadline: June 23 🗓️
- Do *you* want to be a PC member? 🫵
@COLM_conf

2
7
32
5,891
Alex Dimakis retweeted

May 27
Had a great time at CAIS '26 discussing "AI Agents for Discovery in the Wild" alongside Mohammad Alizadeh and @AlexGDimakis, with fantastic moderation by @mertcemri.
We dug into the reality of deploying agents today and where the field is heading. A few of my core takeaways from the conversation:
- Harnesses and Scaffolding are here to stay: While frontier models will naturally absorb a lot of the common-sense integrity checks (hallucinations, tool call errors, math mistakes), scaffolds will remain critical for encoding the specific, proprietary policies and specs of the complex systems enterprises are trying to build.
- Harness engineering is not the answer: Today, engineers spend a lot of time tweaking harnesses. But if we have learned one thing from the Bitter Lesson, it is that we should let AI decide most of the "how." In the future, harnesses should be learned, not hand-coded. (P.S. Alex’s Siri actually jumped in and said “That’s my line” right as this point was made, so it must certainly be true.)
- The researcher’s role is moving upstream: The "how" of research is commoditizing with AI. The distinct value of human researchers will be concentrated in defining exactly what problems are worth solving.
- Verification is (and has been) the true bottleneck: AI agents have the capacity to generate novel outcomes, but those breakthroughs might be one in many millions. Nobody will pay attention unless they can be surfaced through rigorous verification.
- Evaluation economics are shifting: Agentic evaluation is reaching cost and quality parity with human evaluation in many domains. As token costs drop, we’ll unlock massive exploration potential.
If you’re excited about pushing these boundaries, especially as we tackle these challenges, please do reach out!
May 27

It was so much fun moderating the afternoon panel today with a great set of distinguished researchers today, thanks for the engaging and enjoyable discussion @AlexGDimakis @abeirami and Mohammad Alizadeh!


3
3
32
6,796
Alex Dimakis retweeted

May 27
And the AI Agents for Discovery in the Wild workshop ends with the happy hour sponsored by @bespokelabsai , thanks for all of your participation!

May 26
Check out our workshop on AI Agents for Discovery in the Wild tomorrow in San Jose!
We will also have a happy hour at a nearby location after the workshop, register at luma.com/x4rzt92b !
2
5
14
2,743
May 26
I am making the slides for OpenThoughts-Agent, the next project we are working on, after OpenThoughts.
Its a data curation investigation for agents, so the data are environments. We still find that the multiple-answers mystery remains: You're often better off getting 10 rollouts from the same task compared to 10x more rollouts.
7 Dec 2025

The multiple answers mystery is the most surprising thing we stumbled on from OpenThoughts:
Sampling multiple answers for the same question is better than having more questions, each answered once.
To explain: Say you are creating a dataset of questions and answers to SFT a reasoning llm.
You can take 1000 questions (eg from stackexchange) and answer them with deepseekR1.
Or you can take 500 questions (from the same distribution) and answer each question *twice* independently with deepseekR1.
Which one is a better dataset? Surprisingly, if you re-answer the same questions , it’s a better dataset for distillation (at the same size) and this was a robust finding from OpenThoughts across models and data sources.
We have no theoretical understanding why, and no way to predict how many times to repeat. Clearly it must stop at some point (take one question and answer it 1000 times won’t be a good SFT dataset) but we don’t know how to predict this, beyond empirically trying.
3
4
53
7,342
May 21
A breakthrough by OpenAI in a very famous Combinatorics problem, the Planar Unit Distance problem by Erdos 1946.
The problem is amazing because it can be described to a first-grader: Find a way to place n points on the plane to maximize the number of pairs that have distance exactly 1.
For example, if you have n=4 points on a square (of side-length 1) you have 4 pairs of distance 1. The diagonals have length sqrt(2) so don't count.
But you can squeeze one diagonal and create a point-set with n=4 points and 5 pairs of distance 1. And you can't get more than 5 pairs from n=4 points, so we are done with n=4 points.
Now, if you place n points on a line, you have n-1 pairs of distance 1. In general, all known constructions of n points had a number of pairs scaling essentially linearly: n^{1 something vanishing}
It seems that the model found a way to
place n points on the plane so that their unit distances scale super-linearly: like n^{1 delta} for some *constant* delta. Delta was not explicitly specified apparently, but a forthcoming refinement by Will Sawin shows delta=0.014 works, according to the announcement.
This is incredible progress for mathematics, since this is (unlike previous Erdos problems solved by AI) a major breakthrough, in one of the most studied problems in combinatorial geometry. If you're in mathematics research now, you feel the AGI.
Lijie Chen said it honestly in the video:
"It's very hard to sleep, man"
16
36
236
117,541
May 21
Very cool work. Asking agents to build big coding projects from scratch is a great way to create long-horizon tasks.
May 5

How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
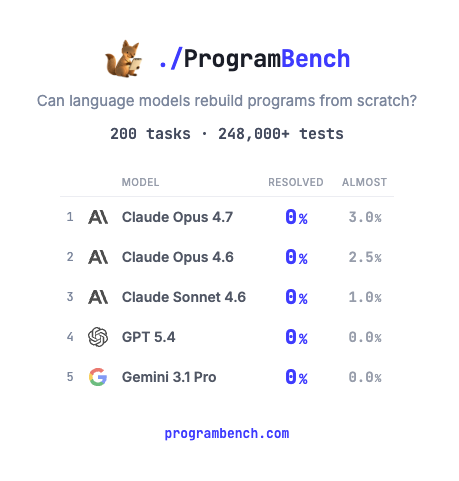
6
3
33
5,653
May 21
Terminal-Bench Science is a direct way to contribute to AI for Science. It's programming agents by task specification. Ask a precise scientific question and watch how AI agents will learn to solve it:
Step 1. Package a scientific task or workflow, something that takes a working scientist a week or month to do into an RL environment.
Step 2. Write tests that verify if the task has been done correctly (can be done easily if you have already solved the task manually).
Step 3. Sit back and let AI agent progress solve it in 6 months.
May 20

📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵

9
6
42
5,478
May 19
Learning in Prompts: Fast learning, Learning in weights: Slow learning. How to combine them iteratively!

Learning from rich textual feedback (errors, traces, partial reasoning) beats scalar reward alone for LLM optimization. GEPA demonstrated this for context-space optimization (prompts and agent harnesses), delivering frontier results at a fraction of the cost of RL.
But context-only optimization is bounded by the base model's capability ceiling; weight updates can reach further.
Very excited about this new line of work on Fast-Slow Training (FST), which interleaves context and model weight optimization!
The idea is a clean division of labor between two interleaved loops:
🔹 Fast loop (context): GEPA reads rich rollout feedback updating the context layer. The context becomes a fast-updating scratchpad of what the model needs to know about this task, right now.
🔹 Slow loop (model parameters): RL updates the model's parameters conditioned on the evolving context. Because the prompt already carries task-specific nuances, the model parameters are freed from absorbing them and focus on what actually generalizes across tasks and pushes the frontier.
⦁ 3× more sample-efficient than RL on math, code, and physics reasoning
⦁ ~70% lower KL divergence from base at matched accuracy
⦁ Plasticity preserved: FST checkpoints respond better to additional RL on new tasks than RL-only ones
⦁ Continual learning across changing tasks (HoVer → CodeIO → Physics) where RL stalls the moment the task switches
FST is a direction towards:
⦁ Addressing RL's pain points: entropy collapse, sparse rewards, long-horizon exploration
⦁ Providing a clean channel for rich feedback into weight updates
⦁ Demonstrating model-harness co-evolution
⦁ Discovery: Using fast context updates for broad exploration, while leveraging a continually improving model.
Check out the full thread below:
6
3
35
5,692
May 18
Improve your agents with one weird trick: ECHO says, when you SFT an agent, do not train it to predict only the agent replies, but also the terminal responses.
When you GRPO, you use the same rollout to predict the terminal responses with cross entropy loss. Its basically free and gets extra supervision from the CLI.
This apparently helps the model develop a 'world model' of the terminal, and improves performance, which was very surprising to me.

3
7
49
7,136
May 16
There is a very interesting idea in this paper: how to judge if an optimization problem created by an LLM is ‘interesting’ or ‘valuable’ ? The proposed measure is called *idea divergence* : asks llms to solve the task multiple times and measures how many different strategies are used and perform well. We could not measure such solution diversity objectively before LLMs, but now we can easily get it with prompting.
May 15

Open-ended coding training data may no longer be the bottleneck: AI can scale open-ended tasks—and even outperform human-expert curation.
FrontierCS team is releasing FrontierSmith: a system for synthesizing open-ended coding problems at scale. Starting from closed-ended coding tasks, FrontierSmith mutates, filters, and builds runnable optimization environments for long-horizon coding agents. In our experiments, FrontierSmith data trains stronger models than human-curated open-ended data on FrontierCS and ALE-bench.
Blog: frontier-cs.org/blog/frontie…
Paper: arxiv.org/abs/2605.14445
Code: github.com/FrontierCS/Fronti…
Model: huggingface.co/runyuanhe/qwe…
7
16
135
23,430
Alex Dimakis retweeted

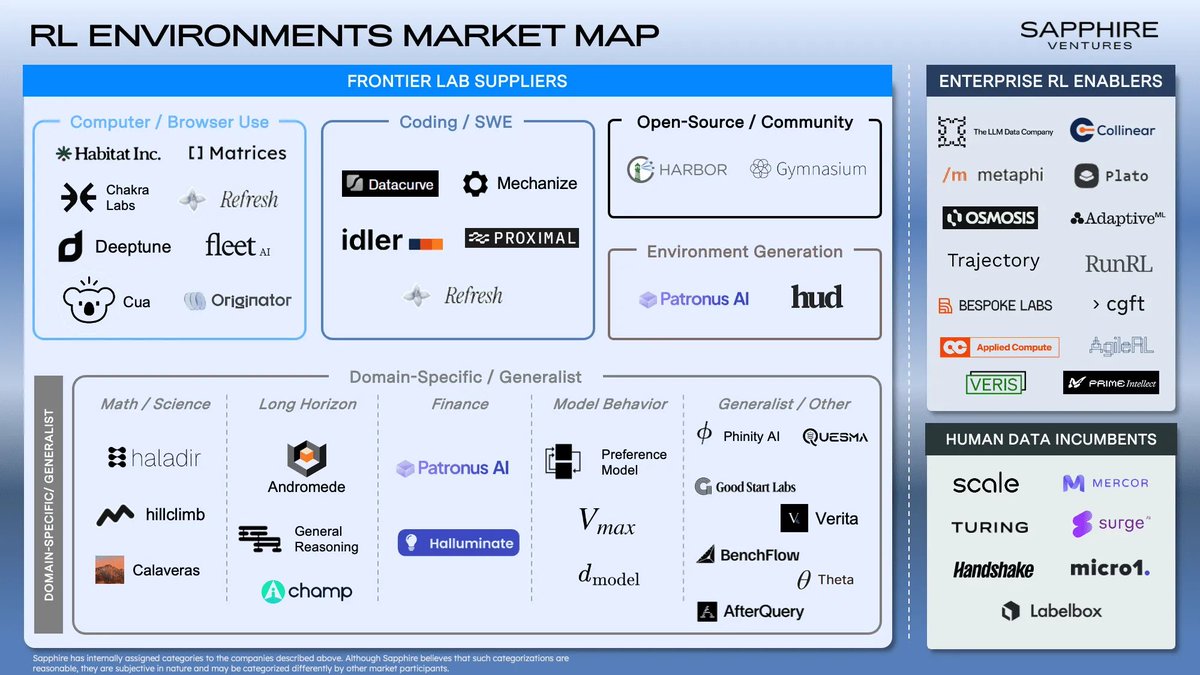
May 8
Happy to be featured in this Market map of RL Environment companies. We work closely with both Frontier labs and Enterprises.
1
2
30
4,235
May 12
Open-Ended optimization is a great way to challenge agents and create long horizon tasks.
May 12
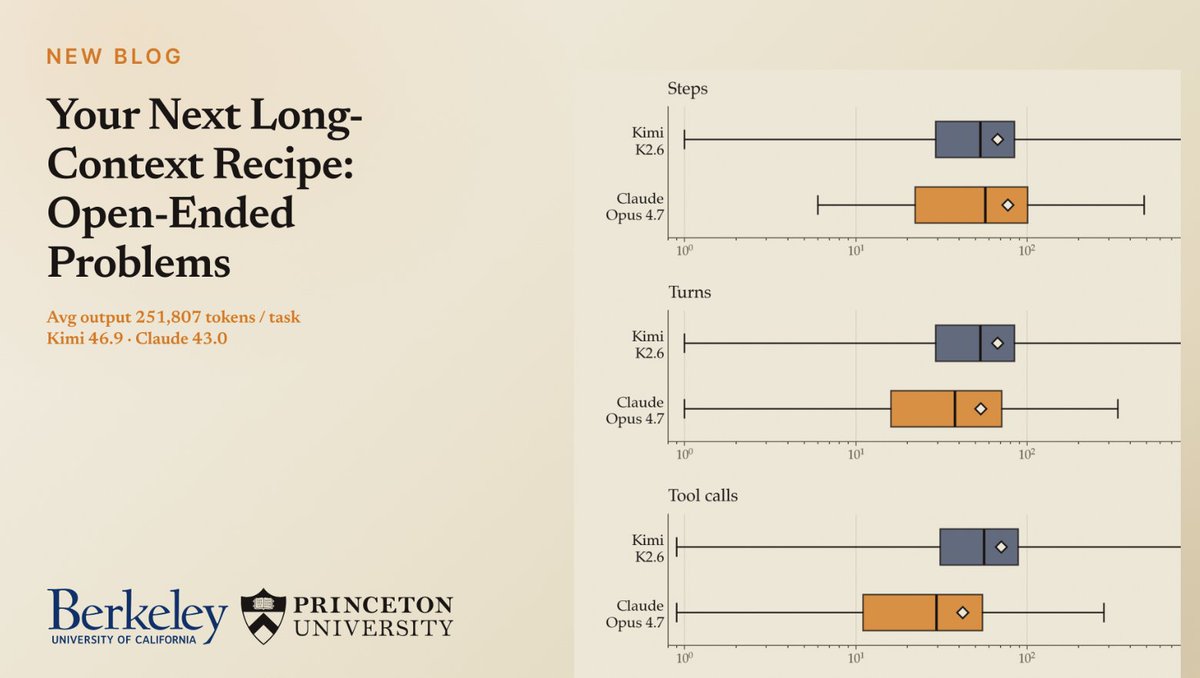
We integrated FrontierCS into Harbor and are releasing a preview long-horizon agent leaderboard (up to 835 turns, ~200K output tokens) with Kimi K2.6 @Kimi_Moonshot (score 46.9) and Claude Code Opus 4.7 @claudeai (43.0) 🚢. The goal: evaluate frontier coding agents in a setting where they iteratively write code, run experiments, read feedback, and improve in an extremely long loop.
FrontierCS tasks are open-ended optimization problems. Each task has a continuous score. There is no single accepted output. Agents need to search for better solutions under a step/time/token budget. This makes FrontierCS a natural fit for agentic evaluation. Just plan, code, test, revise, fail, recover, and keep optimizing.
Check out our blog: frontier-cs.org/blog/harbor
FrontierCS GitHub: github.com/FrontierCS/Fronti…
3
2
19
2,697
May 9
In case you want to know who invented looped transformers. Congratulations Angkeliki.
The co-inventor of Looped Transformers defended her PhD thesis yesterday and is heading to an incredible new role soon :) congratulations @AngelikiGiannou 🥳 🎉🎈

2
4
68
10,728
May 8
Enjoyed a great event at Berkeley with Daytona AI researchers. RL Environments and Sandboxes clearly getting in the center of attention.
May 8

Last night we hosted our @daytonaio AI Researchers Meetup at @UCBerkeley, and the talks were outstanding. Here are the key takeaways:
🎤 @AlexGDimakis (UC Berkeley & @bespokelabsai) — environments are the new data. We're moving from 'What does AI know' to 'What can AI do'.
🎤 @charlie_ruan (UC Berkeley, @BerkeleySky) — SkyRL: a modular RL library pushing infrastructure below the algorithm layer.
🎤 @sijun_tan (UC Berkeley, @BerkeleySky) — Hive: multi-agent collaborative evolution. 45% → 77% on Tau2-Bench 🤯
🎤 @lihanc02 (UC Berkeley, @BerkeleySky) — FrontierCS: 244 open-ended CS problems frontier models still can't crack.
🎤 @muhashmii (@daytonaio) — the RL 'episode' abstraction is broken for long-horizon agents. New primitives needed.
See you at the next one!




2
14
1,902
May 7
This is an amazingly high quality dataset:
1250 Questions on scientific figures annotated by original paper authors. And they're pretty hard to answer!
May 7

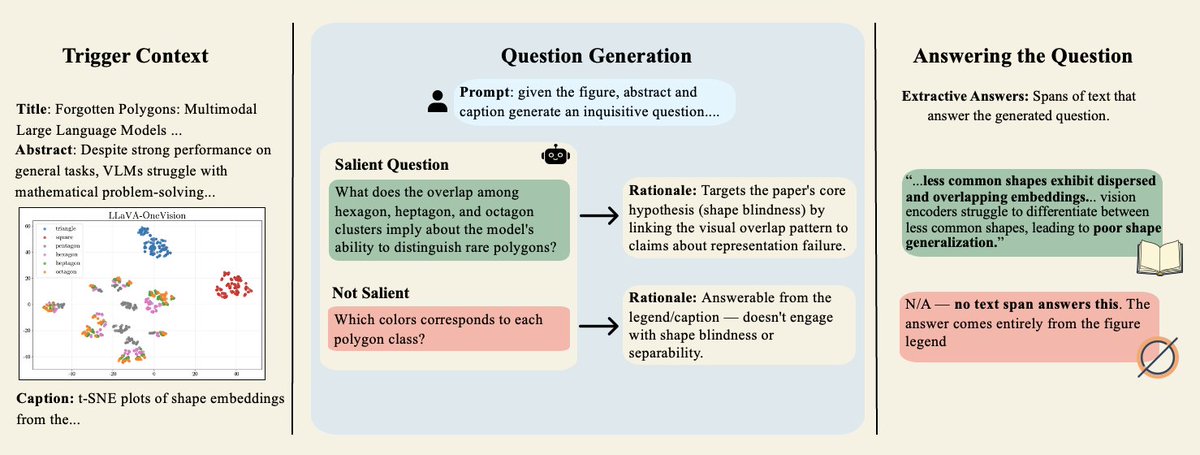
What does a scientific figure make you wonder? 📊
When we read papers, figures often raise questions that the surrounding text helps answer.
But most VLM benchmarks focus on questions answerable from the figure alone.
We introduce MQUD: 1,250 inquisitive questions over 245 figures from 56 papers, annotated by original paper authors.
MQUD extends Questions Under Discussion (QUD) from text to multimodal scientific discourse.
Instead of asking only what is visible, MQUD asks what implicit scientific question a figure raises in context.
1
3
12
2,732
May 7
Want Questions on Figures? This is a dataset of 1,250 high-quality questions grounded on scientific 245 figures from 56 papers, annotated by original paper authors. Probably the highest quality dataset for questions on figures you can find. Its called MQUD: Multimodal Questions Under Discussion (QUD).
May 7
What does a scientific figure make you wonder? 📊
When we read papers, figures often raise questions that the surrounding text helps answer.
But most VLM benchmarks focus on questions answerable from the figure alone.
We introduce MQUD: 1,250 inquisitive questions over 245 figures from 56 papers, annotated by original paper authors.
MQUD extends Questions Under Discussion (QUD) from text to multimodal scientific discourse.
Instead of asking only what is visible, MQUD asks what implicit scientific question a figure raises in context.
1
1
6
1,974
