
Intern at @DragonLLM in Paris. (Pre|post)-training LLMs
Joined January 2020
- Tweets 606
- Following 325
- Followers 829
- Likes 54,094
210 Photos and videos








Pinned Tweet

31 Jul 2024
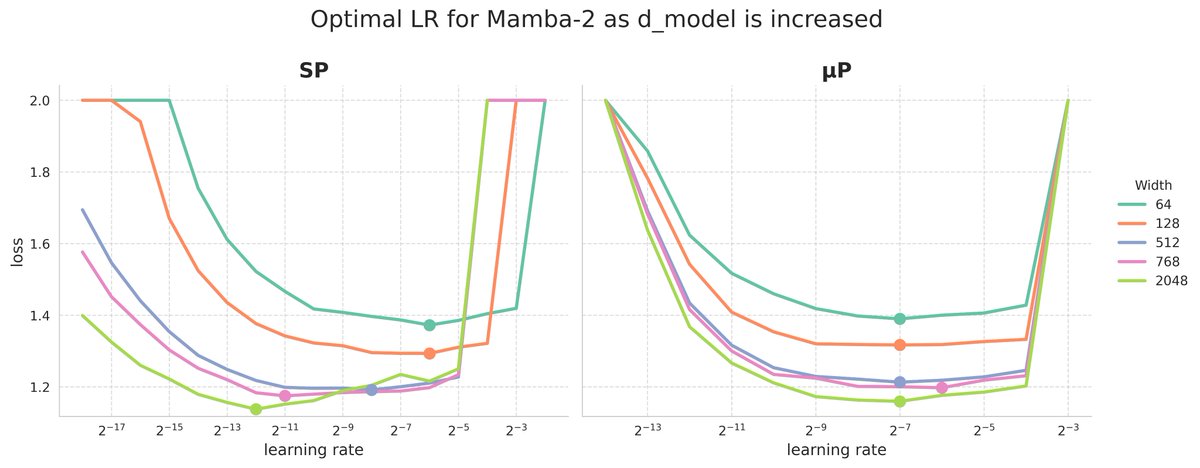
muP works great for Mamba !
Zero-shot transfered the learning rate from a 172k model to a 105 model.
Now part of mamba.py 👇🧵
2
8
72
8,077
Alexandre TL retweeted

We’ve been lucky enough to test Mamba-3 ahead of the curve. 🧪
Here is how it integrates into Hybrid Models (Spoiler: it unlocks Muon for SSMs for the first time). 🧵
Mar 17

The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti @kevinyli_ @_berlinchen @caitWW9, and of course @tri_dao!
1
22
108
15,390
Mar 10
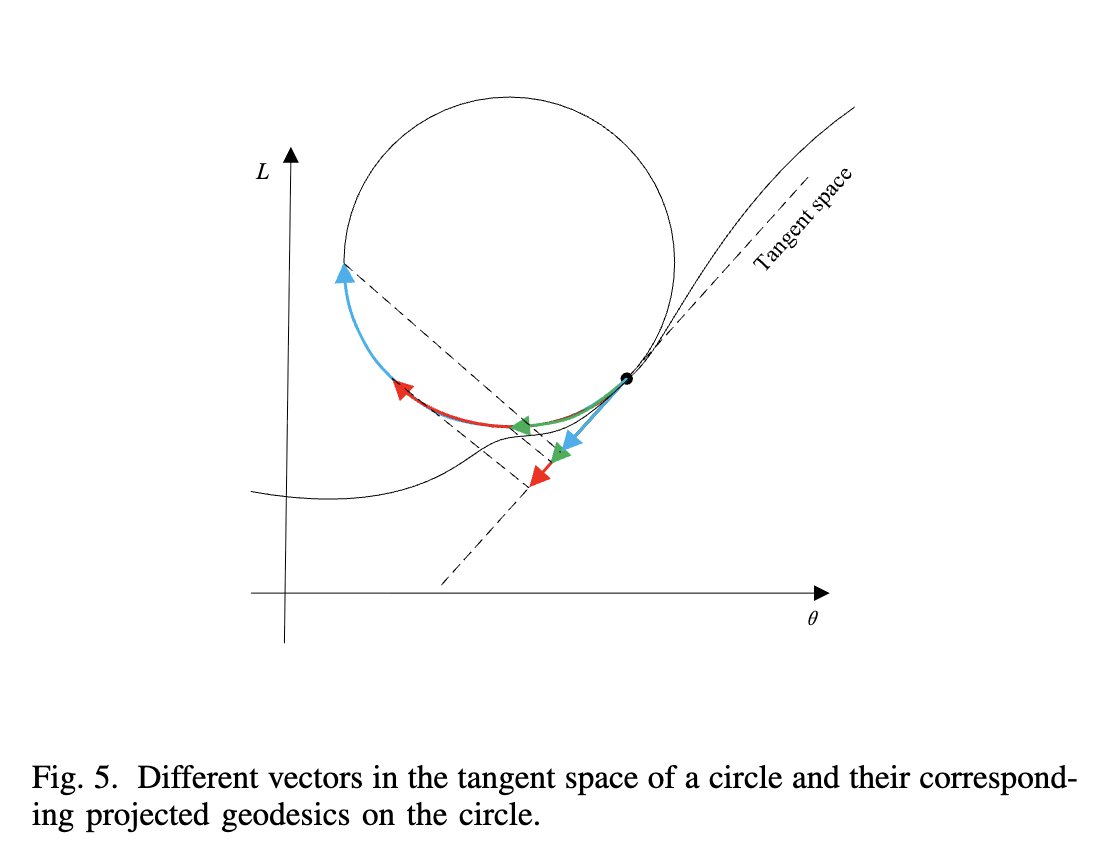
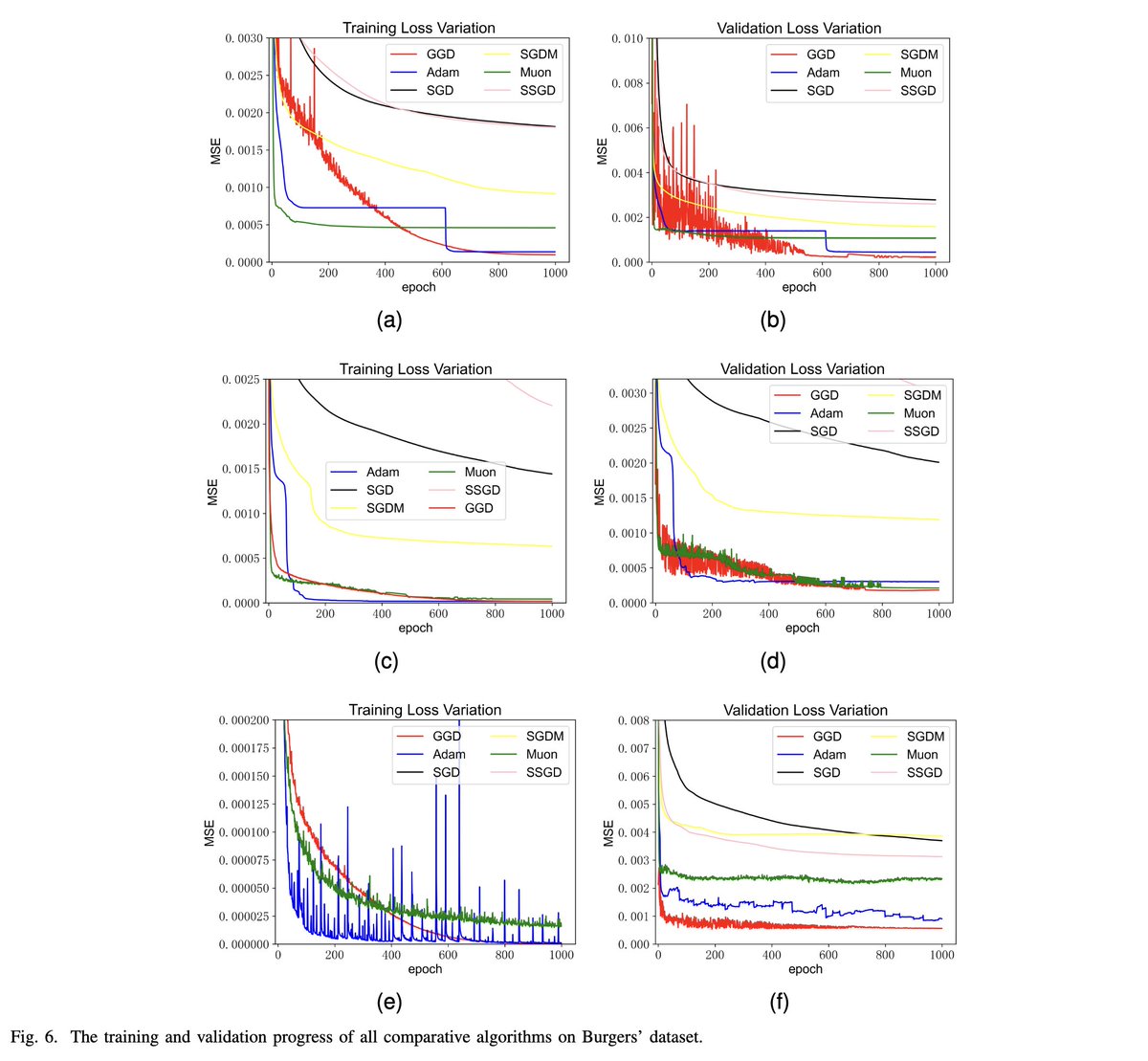
This is basically Hyperball GeoNorm

Interesting optimizer that projects the gradient onto a tangent n-dimensional ball on the loss landscape. Unfortunately, the experiments are fairly basic, but i quite like the idea.
🔗arxiv.org/pdf/2603.06651
2
9
62
5,444
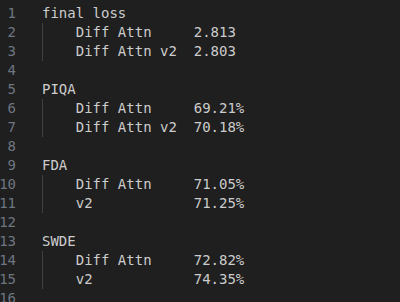
Jan 21
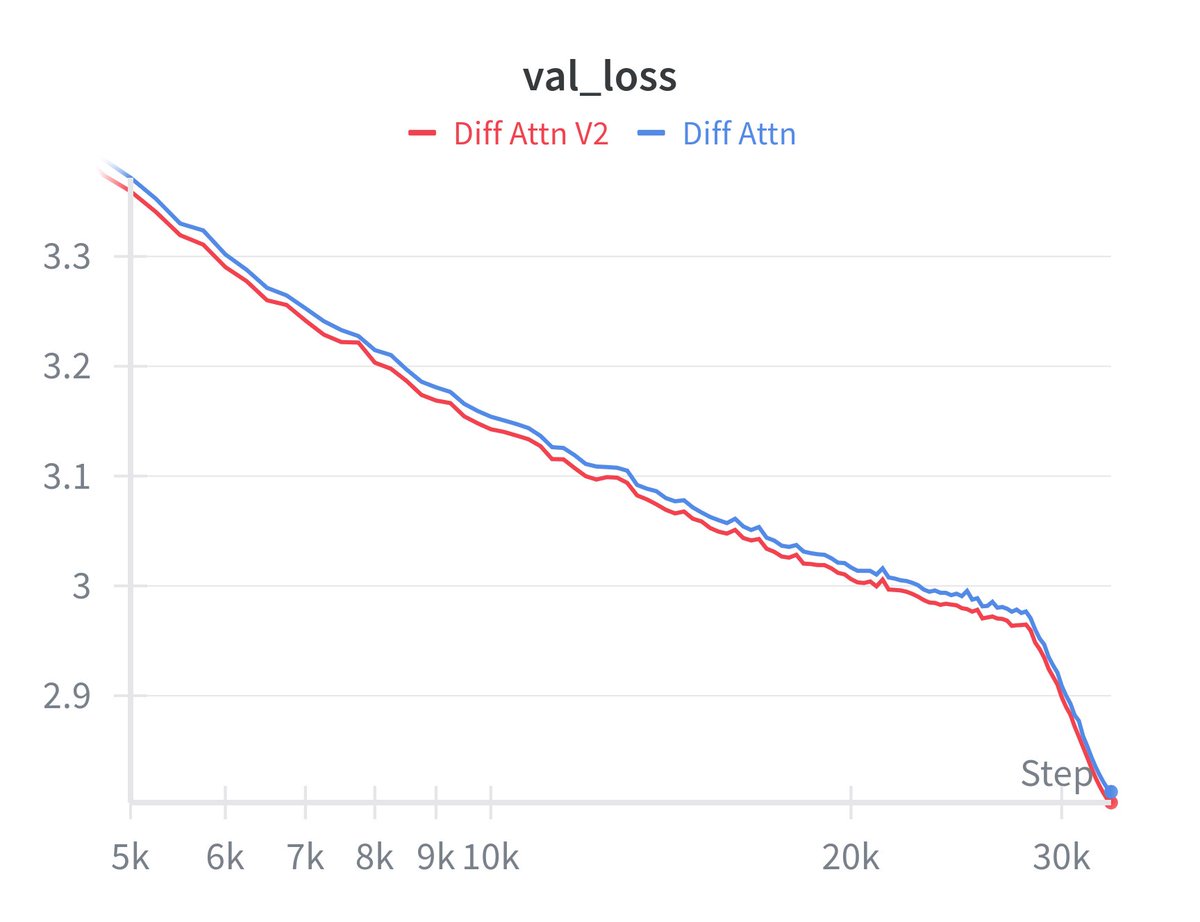
Well, works really great compared to Diff Attn v1! 0.01 loss gap with a faster model
Jan 20

Introduce Differential Transformer V2 (DIFF V2), an improved version of Differential Transformer. This revision focuses on inference efficiency, training stability, and architectural elegance. We verify the design on production-scale LLMs.

2
6
44
10,038
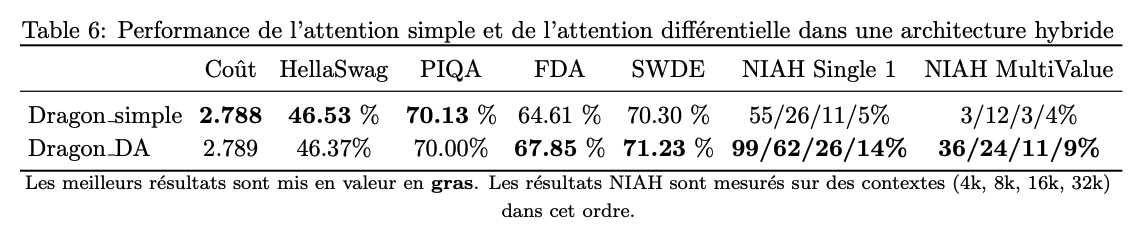
Jan 21
benchmarks looks great also
(this is an hybrid model with 4 DA layers and 20 GDN layers)
1
7
529
11 Dec 2025
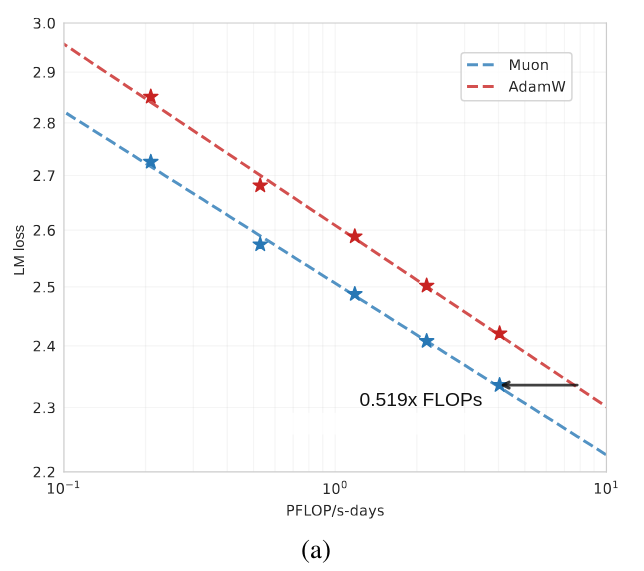
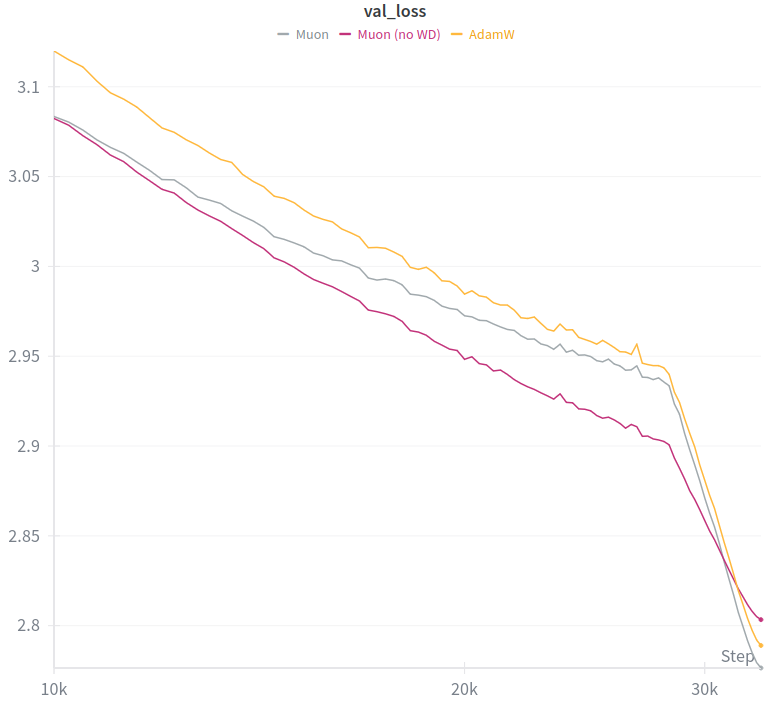
This is the best I got for Muon on a hybrid architecture compared to AdamW. Anyone knows what could be happening here ?
4
1
3
616
11 Dec 2025
if WD, its value is 1e-4, LR 0.6 (it's using muP with indep WD hence the small WD and large LR.
"translated" to SP, that would be LR=5e-4 and WD=6e-3
1
1
263
11 Dec 2025
also, quite important, batch size is 64 * 4736 = 300k tokens
1
226
11 Dec 2025
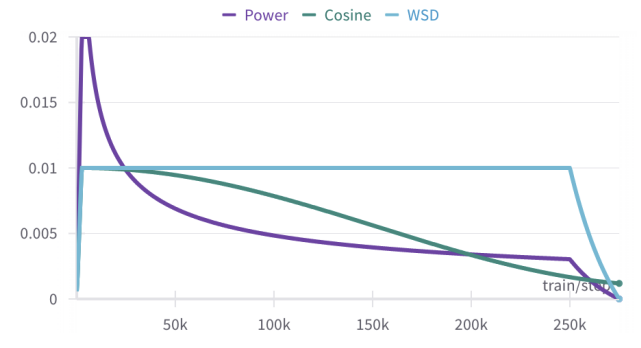
on my todo lists to try are:
-different WD values
-bigger warmdown duration
1
156
1 Nov 2025
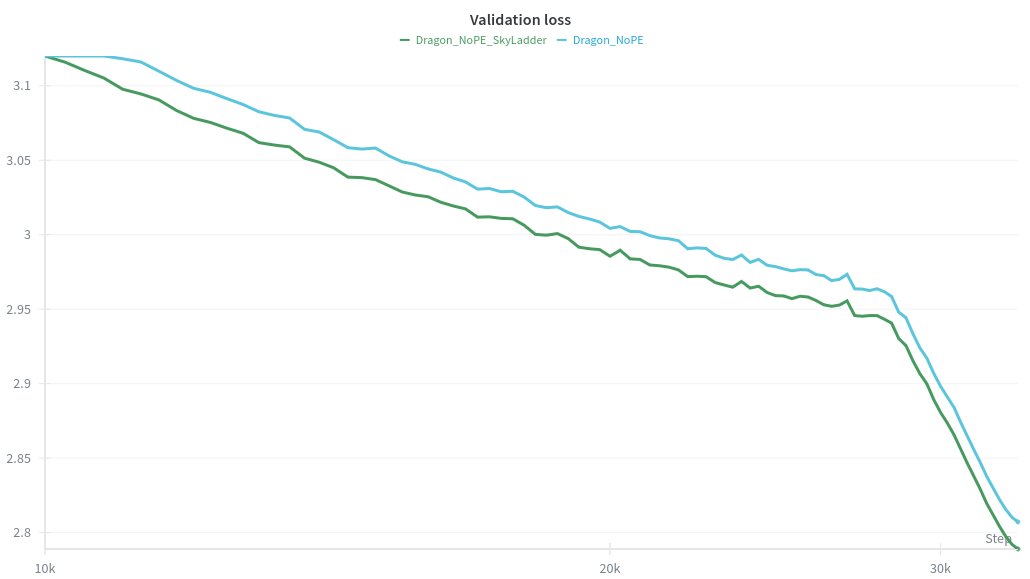
RoPE vs NoPE in hybrid linear attention models like Kimi Linear / Qwen3Next is tricky
for example, when using NoPE, we found that slowly expanding the window size of the attention layers during training (64->4k) greatly helps convergence:
30 Oct 2025

You see:
- a new arch that is better and faster than full attention verified with Kimi-style solidness.
I see:
- Starting with inferior performance even on short contexts. Nothing works and nobody knows why.
- Tweaking every possible hyper-parameter to grasp what is wrong.
- Trying to find the efficient chunkwise parallelizable form to squeeze juice out of the GPU
- RoPE or NoPE, a question haunting for nights.
- Fighting buggy implementation that causes one of the long-context benchmarks drops ~20 pts.
- RL diverging. Aligning training-inference numerics.
- Dedicated efforts to make sure comparisons are solid and fair.
- Going back-and-forth in a pool of adversarial gate-keeping tests, and finally it survives.
Great teamwork!
3
3
19
2,212
1 Nov 2025
It kind of corroborates the results of arxiv.org/abs/2509.24552 which trains using a stochastic context size (instead of a growing one as we do, from 64 to 4k). the intuition is to force the attention layers to use the linear attention memory
2
1
5
353
1 Nov 2025
More info and surprising results of our arch @DragonLLM here : dragonllm.substack.com/p/ins…
1
144
15 Oct 2025
So this is our take on a hybrid GDN Attention architecture !
It was a very fun project : a very little team and a lot of research papers to implement & combine (and a lot of skipped nights)...
15 Oct 2025

Sharing a preview of Dragon, a new hybrid GDN-Transformer that outperforms traditional architectures! We are an EU 🇪🇺🇫🇷 based company developing foundational models.
What's new, what's different? 🧵👇
1
8
467
15 Oct 2025
Still a lot of things to improve this recipe I think, like muP integration, optimizer, as well optimizations to make on the inference side, to really make the small kv cache shine.
Fun bit, a snarky answer I got from Copilot, surely a punishment for being too lazy an intern:
1
1
162
15 Oct 2025
We make everything open-source
Model & architecture : huggingface.co/DragonLLM/Dra…
Detailed blogpost : dragonllm.substack.com/p/ins…
Thanks to @JG_Barthelemy for taking a chance on me and making me part of this still ongoing project!
2
2
178