
Crafting AI Models for Finance
Joined April 2013
- Tweets 261
- Following 431
- Followers 280
- Likes 502
39 Photos and videos












Pinned Tweet

15 Oct 2025
It’s a new name! We are Dragon LLM and we craft models. linkedin.com/posts/dragonllm…
7
1
13
1,565
We wanted to share this important news ! linkedin.com/posts/dragonllm…
2
109
If you are in Paris, don't miss these talks!
📅 our wonderful team will be participating at 2 unmissable events tomorrow on Feb 3, go meet them.
@JG_Barthelemy and @AlexandreTL2 are presenting at the @datacraft "Mamba and AI Factories" event from 16:30 , 55 Rue La Boëtie, 75008.
👉 luma.com/u66szusv
Gaëtan Caillaud will be joining an AI-in-Finance round table organised by @LouisBachelier in collaboration with @Genci_fr and AI Factory France at Palais Brongniart from 16:30.
👉 lnkd.in/eeB_m4Be
Sign up for these events, see you there!
1
4
239
Dragon LLM (ex Lingua Custodia) retweeted

Jan 21
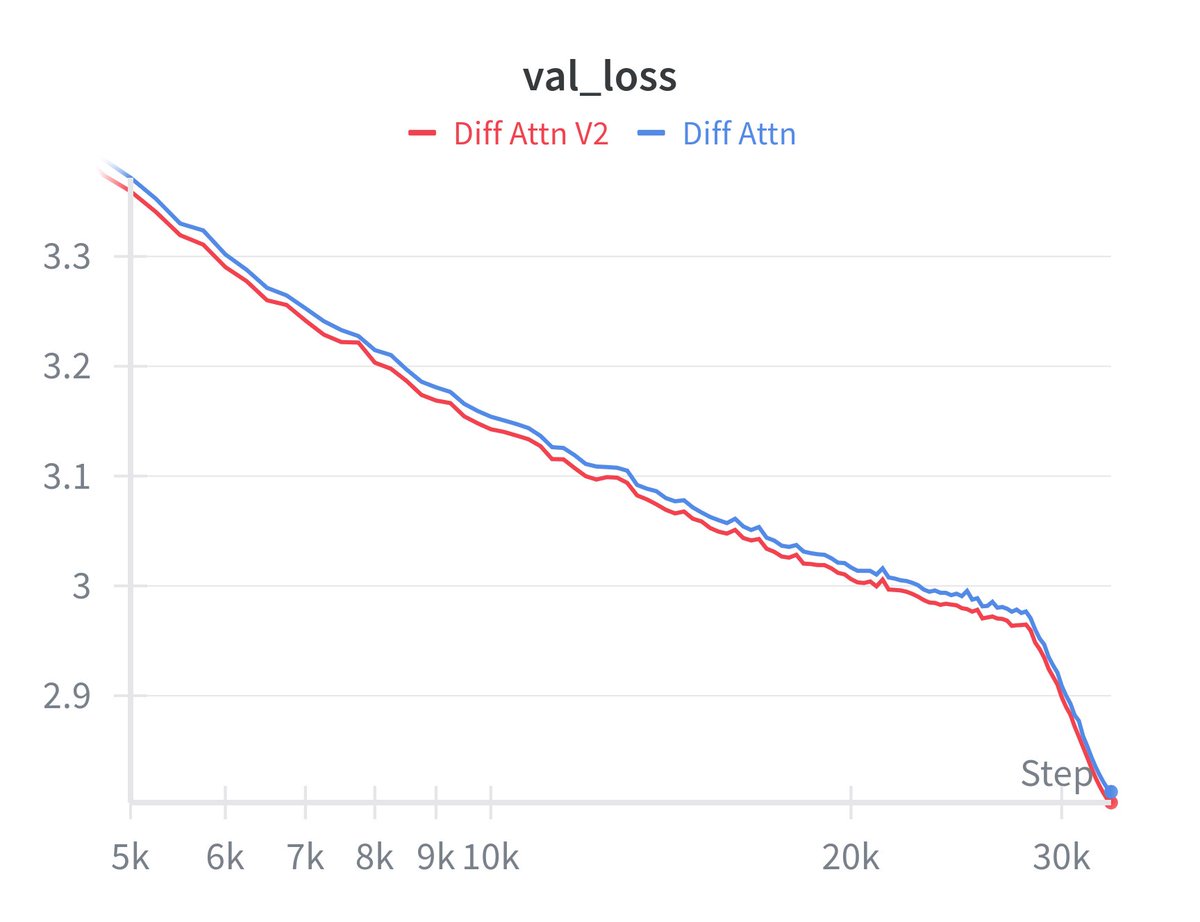
Well, works really great compared to Diff Attn v1! 0.01 loss gap with a faster model
Jan 20

Introduce Differential Transformer V2 (DIFF V2), an improved version of Differential Transformer. This revision focuses on inference efficiency, training stability, and architectural elegance. We verify the design on production-scale LLMs.

2
6
44
10,038
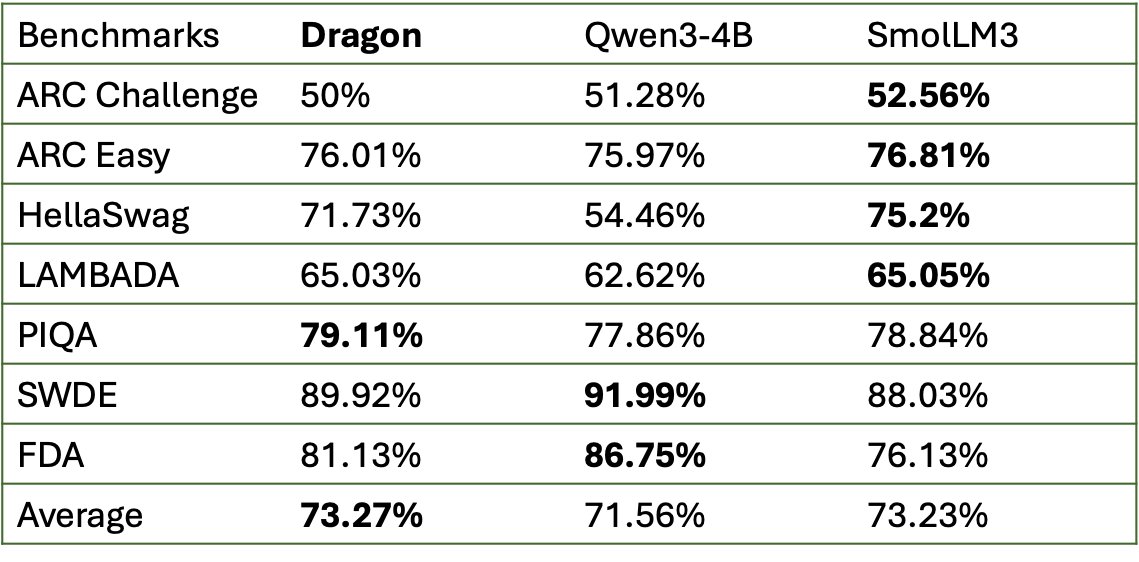
The chosen model is a fine tuned Qwen3 Reasoning 8B, we can evaluate its ability to call tools and produce structured outputs. Our Open Finance models are all there :
huggingface.co/collections/D…
1
1
95
Dragon LLM (ex Lingua Custodia) retweeted
11 Dec 2025
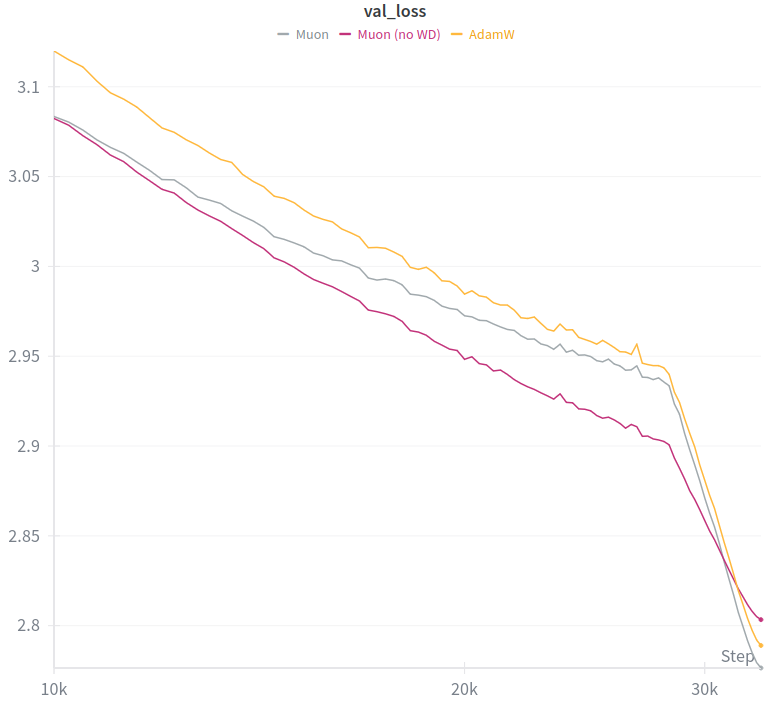
This is the best I got for Muon on a hybrid architecture compared to AdamW. Anyone knows what could be happening here ?
4
1
3
616
27 Nov 2025
We can only agree with @Lagarde latest speech on EU risk of lagging on #AI.
As @AndreeaNiculcea puts it (c) ,
"We become users of someone else’s models, someone else’s compute, someone else’s innovation — with our margins squeezed and our clients drifting to whoever offers real intelligence, not generic chatbots."
#Hint 👉 Dragon LLM is not generic.
The full transcript is worth reading :
ecb.europa.eu/press/key/date…
2
72
13 Nov 2025
🥳 #Adopt_AI - Grand Palais is rapidly approaching!
Iconic event at an iconic venue! 😍
We'll be at booth F6—we'd love to see you there! 🤗
📅 25-26 November
🗺️ The Grand Palais, Paris 🥖
👉 adoptai.artefact.com/partner…
2
3
179
4 Nov 2025
Introducing LLM Pro Finance models with @AgefiFrance today.
‣ Gemma Pro Finance 12B
‣ Qwen Pro Finance 32B
‣ Llama Pro Finance 70B
They are fine tuned for FR/EN finance and show significantly better performance vs base models. Find them here 👇
1
3
96
4 Nov 2025
One more 🍪: try or train the two Open Finance models:
‣ Llama Open Finance 8B
‣ Qwen Open Finance R 8B
huggingface.co/collections/D…
1
70
4 Nov 2025
If you would enjoy some ready made cookbooks or recipes to use them with @langchain @LLamaIndex @Pydantic_ai or @Mastra, just ❤️ this post.
58
4 Nov 2025
Today is the day. Parlez-vous finance en français dans le texte?
@DragonLLM releases its fine tuned models for french finance. Stay tuned.
29 Oct 2025

These LLM-Pro-Finance models will be presented at the AGEFI AMTech Event on Nov, 4th. Join us to see live demonstrations and learn how these models can transform financial operations in both English and French-speaking markets.
1
88
Dragon LLM (ex Lingua Custodia) retweeted
1 Nov 2025
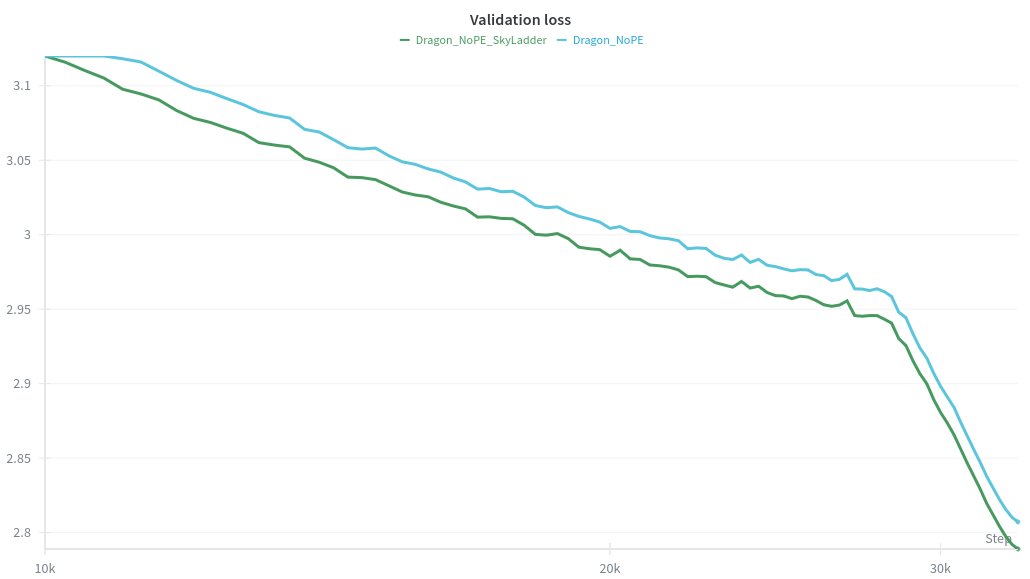
RoPE vs NoPE in hybrid linear attention models like Kimi Linear / Qwen3Next is tricky
for example, when using NoPE, we found that slowly expanding the window size of the attention layers during training (64->4k) greatly helps convergence:
30 Oct 2025

You see:
- a new arch that is better and faster than full attention verified with Kimi-style solidness.
I see:
- Starting with inferior performance even on short contexts. Nothing works and nobody knows why.
- Tweaking every possible hyper-parameter to grasp what is wrong.
- Trying to find the efficient chunkwise parallelizable form to squeeze juice out of the GPU
- RoPE or NoPE, a question haunting for nights.
- Fighting buggy implementation that causes one of the long-context benchmarks drops ~20 pts.
- RL diverging. Aligning training-inference numerics.
- Dedicated efforts to make sure comparisons are solid and fair.
- Going back-and-forth in a pool of adversarial gate-keeping tests, and finally it survives.
Great teamwork!
3
3
19
2,212
1 Nov 2025
Check 4️⃣
1 Nov 2025

THINGS YOU MISSED ON DIGITAL:
1️⃣ AI Uptake: New EU strategies to accelerate AI in industry & science
2️⃣ Cable security: Securing Europe’s digital backbone
3️⃣ Online Safety: Platforms must protect minors online
4️⃣ Dragon: The LLM powered by @EuroHPC_JU supercomputers




2
68