
27 Photos and videos











Ameya P. retweeted

Jun 13
Dario (48 hours ago): “US gov should be able to block model deployment”
USG: *export controls models*
Dario: “not like that”

Jun 13

The Trump administration has placed Anthropic's Mythos 5 and Fable 5 under export controls. Commerce Secretary Howard Lutnick sent a letter to Dario Amodei tonight stating that foreign governments, companies, and individuals will no longer have access to either model.
114
542
6,172
701,570
Ameya P. retweeted

Jun 11
New #1 on PostTrainBench: Opus 4.8 (max reasoning) hits 37.23% - a big jump from Opus 4.7's 28.56%.
This is the largest single model improvement we've seen.
We are currently running Claude Fable 5, however Fable's safety classifiers are refusing tasks, which is a new dynamic we haven't seen before. Stay tuned!
posttrainbench.com

2
2
47
6,375
Ameya P. retweeted

Jun 10
🚨 Claude Fable 5 on FutureSim 🚨
While Anthropic folks have been using it internally for predicting evals, we actually put it to test on FutureSim.
We found it has very strong priors but fails to update predictions over time and ends up no better than GPT-5.5!
We report our results on Feb-March subset to minimize contamination with Fable's knowledge cutoff of Jan.

we don’t even run evals anymore we just ask Claude what the score will be
4
5
64
13,405
Ameya P. retweeted

Excited to share KletterMix 🇩🇪🚀
A ~725B-token German pretraining annealing corpus.
Proud to have co-led this with @HarleRuben, Sebastian Sztwiertnia, Abbas Goher Khan, Mehdi Ali, @effi288, and @kerstingAIML.
Paper: huggingface.co/papers/2606.0…
2
6
19
1,021
Ameya P. retweeted

Great to see that MiniMax M3 used PostTrainBench in its announcement!
1
1
33
2,640
Ameya P. retweeted
💥Today we release InferenceBench, our next benchmark after PostTrainBench that measures progress on AI R&D automation.
AI R&D automation will very likely unfold gradually, starting from “boring” tasks like inference speed optimization that are very easily verifiable (accuracy inference time). We show a rather negative result for current frontier agents. They are not good at system-level engineering and managing complex dependencies. They do show non-trivial performance, but they fail compared to a simple baseline: hyperparameter tuning of vLLM/SGLang hyperparameters.
Importantly, InferenceBench tests *open-ended* inference optimization capabilities. This is different from more narrow benchmarks like KernelBench that only let agents optimize kernels (which is a very valuable task, too!). The benchmark is intentionally open-ended, so the poor performance of the agents is not an underelicitation issue. The agents have everything needed to succeed, but they still fail because they are not yet reliable enough for this task.
Our results suggest an inverse scaling phenomenon: Claude Sonnet 4.6 and GLM-5 rank highly because they more often preserve simple, valid, high-performing final servers, while several larger models show stronger peak runs but lose utility through brittle final-state choices. This contrasts with benchmarks where rankings track raw capability (e.g., SWE-Bench, Terminal-Bench, PostTrainBench, FrontierSWE).
One of the primary bottlenecks we have clearly observed is the lack of diversity of strategies: nearly all agents just use vLLM, without exploring alternatives. Overall, proper exploration is lacking: the current agents are not ready to tackle broad enough goals and get stuck after the first found solution (such as vLLM). I’m sure future agents will do much better, but here is where we are now.
This benchmark is our 2nd one in a suite of benchmarks that will track the progress on AI R&D automation. We will develop many more benchmarks that will cover different aspects of AI R&D automation, culminating in recursive self-improvement. Stay tuned!


12
48
348
41,974
Ameya P. retweeted
May 19
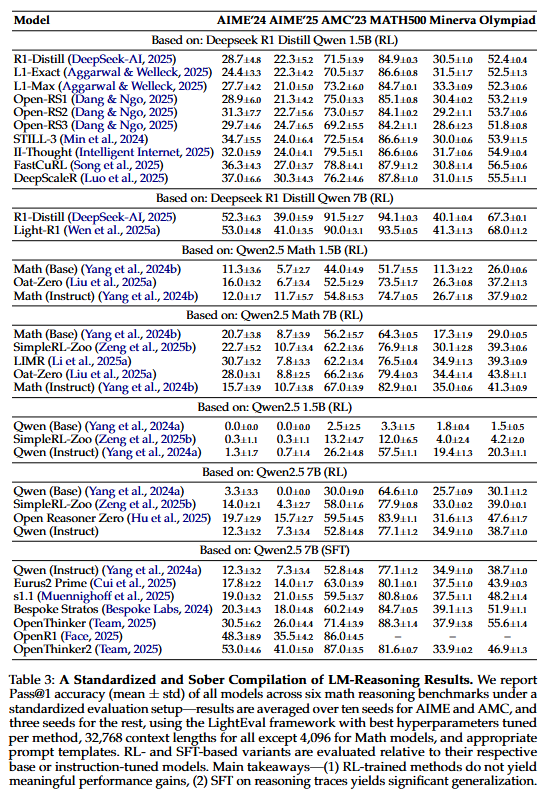
🚨 FutureSim Update 🚨
We evaluated Opus 4.7 at max reasoning in Claude Code.
Despite potential test-set contamination with knowledge cutoff of Jan '26, it scored just 21%, barely edging past Opus 4.6 and still behind GPT 5.5!
Will Mythos be a step-change on FutureSim as it is for coding benchmarks?
May 16

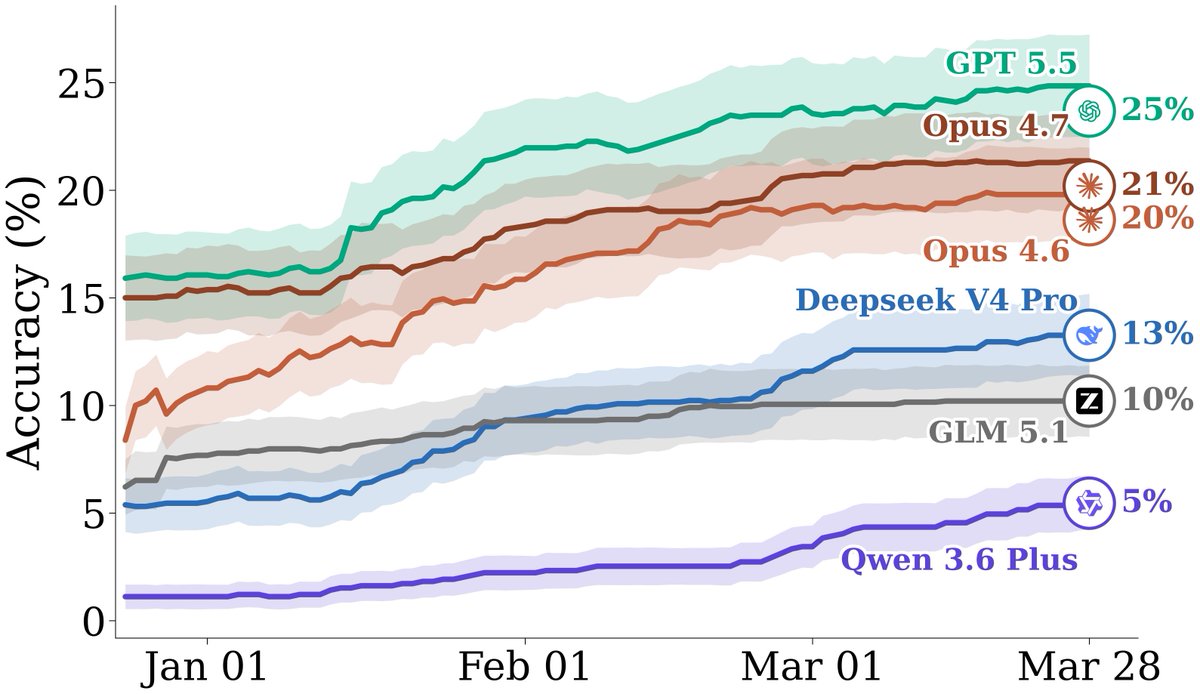
new forecasting benchmark: FutureSim
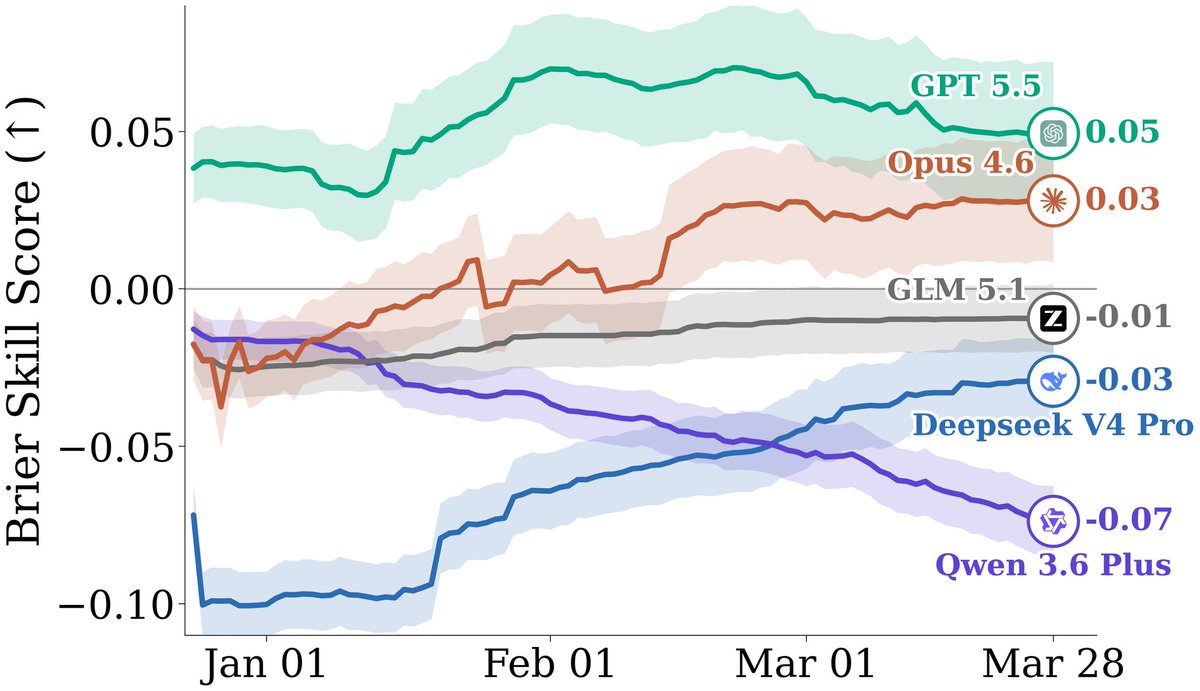
GPT-5.5 performs the best at 25%, but Mythos, Gemini 3.1 Pro and Opus 4.7 are not included. Based on their Brier Skill Score the models don't seem to be much better than just assigning equal probabilities to all outcomes
1
2
24
5,620
Ameya P. retweeted

May 17
I hope more people read Section 5 of our paper.
It's easy to generate a ranking among models with a benchmark.
We do that properly (sec 4), but really the main point is all the research (sec 5) that can be done on top of this very new (temporal open-ended) way to do evals

actually lots of interesting empirical results here, that go beyond "forecasting the future eval". Models differ a lot in how they respond to starting from the worst agent's outputs! V4 is generally bad here but recovers the most. Is it just an issue of in- vs out- distribution?

3
3
35
4,272
Ameya P. retweeted
May 15
Introducing FutureSim, the first interactive environment testing agents on predicting world events.
We build a simulation where agents face forecasting questions over the course of 3 months. News articles come in each day and agents continuously revise their prediction in light of new information as we show below for GPT-5.5. (1/5)
4
7
77
13,518
Ameya P. retweeted

May 15
What else have we been up to? As models get better and work over longer and longer time horizons, how do we even evaluate how well they can act and adapt?
One domain we really like there is forecasting, as a hard task that test reasoning under uncertainty.
We've made a benmchmark out of this, where we simulate a whole 3 month period of news, and sanboxed let models continuously read news from those days, plan, and update their forecasts. (see the animation below, just don't be fooled by its speed, this is a slice of the larger 12m token trajectory)
Many more details linked below:
May 15

Continual learning is bottlenecked by realistic evaluations
Introducing FutureSim, which replays real-world events in the temporal order they occurred
We benchmark frontier agents at updating predictions about how our world evolves, in native harnesses like Codex, Claude Code
9
37
4,565
Ameya P. retweeted
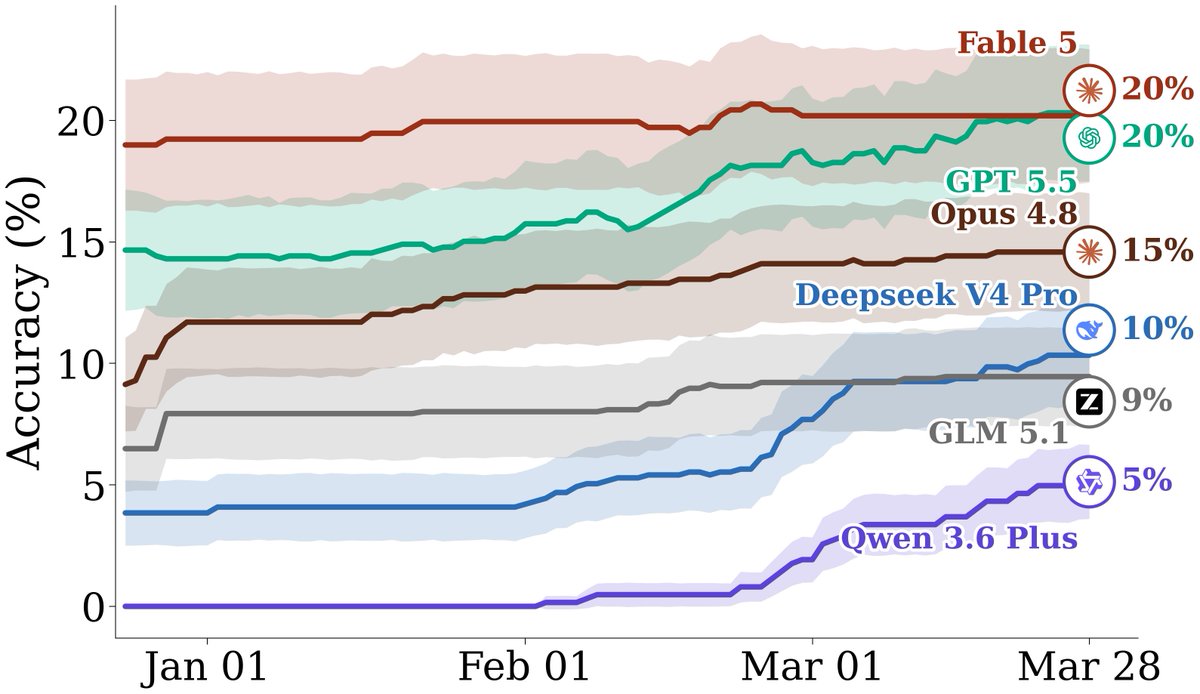
💥 Check out our new paper: FutureSim: Replaying World Events to Evaluate Adaptive Agents.
We create a *reproducible* long-horizon environment where agents have to make forecasts during a 3-month period.
The best performing agent, GPT 5.5 in Codex, consumes 3700 turns and 12.4M tokens spanning many sequential context window compactions in a single run.
(Led by @ShashwatGoel7, @nikhilchandak29, @arvindh__a!)
May 15
Continual learning is bottlenecked by realistic evaluations
Introducing FutureSim, which replays real-world events in the temporal order they occurred
We benchmark frontier agents at updating predictions about how our world evolves, in native harnesses like Codex, Claude Code
1
8
40
3,907

Can agents continually adapt their predictions given new information from real-world events across several months?
A very long horizon benchmark:
alphaxiv.org/abs/2605.15188
Details👇
May 15

Introducing FutureSim: where we replay a temporal slice of the web and let agents forecast real-world events over time 🔮🌎
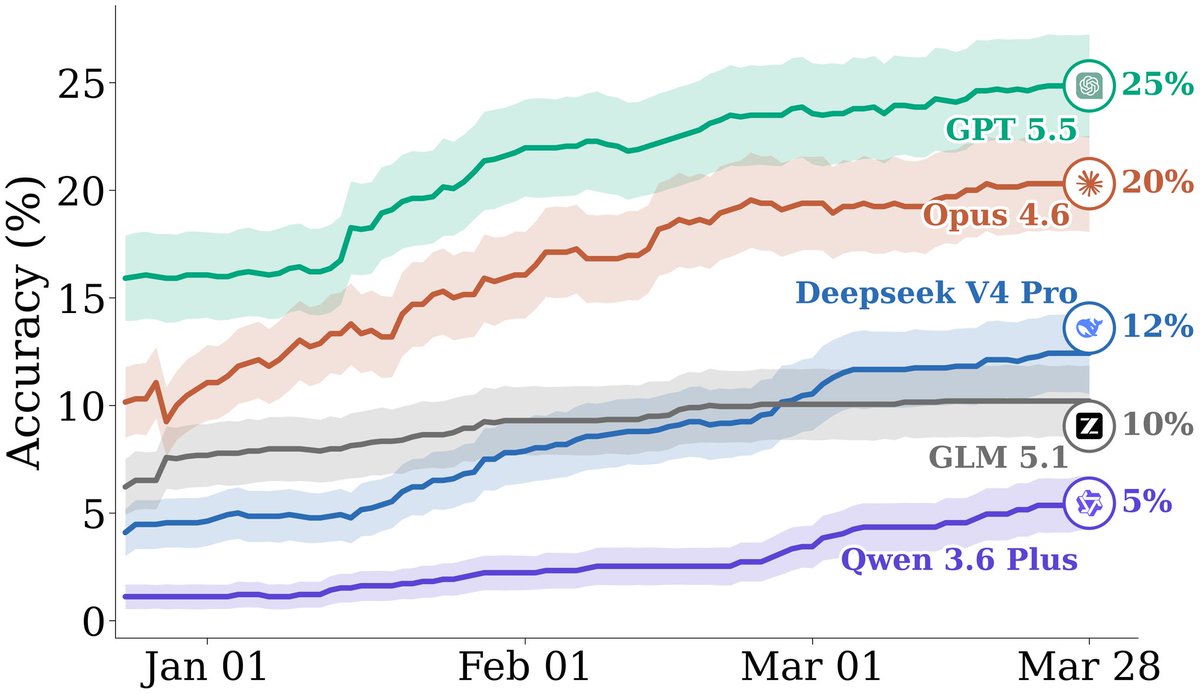
FutureSim replays the web day by day. Agents start on Jan 1, 2026 (past their knowledge cutoffs) with date-gated access to real news articles and forecast on real-world events resolving over the next 90 days. Around 244K new articles stream in during the simulation. Agents decide which questions to answer, what to search for, and when to advance to the next day 🤔
We evaluate frontier models in their native harness. GPT 5.5 (Codex) leads at 25% acc, followed by Opus 4.6 (Claude Code) at 20% 📈 Open weight frontier models have a significant gap to catch up, with DeepSeek V4 pro at 13%, GLM 5.1 at 10%, and Qwen3.6 Plus at 5%
On some questions that have a parallel @Polymarket market, we find that GPT 5.5 in our simulation sometimes beats the crowd aggregate, like in the Super Bowl LX ($704M traded) market 💰💸
FutureSim serves as a test bed for evaluating a lot of important agentic capabilities
> Adaptation: how agents adapt beliefs over time, and handle new incoming information and environment feedback
> Memory: how agents make the best use of external memory to store persistent insights and handle context limitations over a thousand tool calls
> Search: how agents find relevant information over thousands of articles streaming in
> Inference scaling: how agents benefit from scaling inference compute
More cool insights and deep dives in our paper 👇
1
6
282
Can agents continually adapt their beliefs with new information from real-world events?
We provide a testbed for LLM agents to learn to accumulate useful signals across time.
Exciting new directions👇:
• Memory
• Search
• Multi-agent self-play
• Inference Scaling
May 15
Continual learning is bottlenecked by realistic evaluations
Introducing FutureSim, which replays real-world events in the temporal order they occurred
We benchmark frontier agents at updating predictions about how our world evolves, in native harnesses like Codex, Claude Code
4
12
752
Ameya P. retweeted
May 13
We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn.
This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information.
In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can …
🔵Be created by instruction-tuning for the stream format
🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in)
🔵Multi-Stream LLMs are fast, they can predict read tokens in all streams in parallel in each forward pass, improving latency
🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security
🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized.
Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.
42
168
1,367
156,854
Ameya P. retweeted

Apr 29
the tabooification of research ideas in ai safety in this manner is silly. if it helps performance just assume a frontier lab is already doing it, and if a frontier lab is already doing it then it’s good to write papers on it so we can get more eyes on it to fix problems.
Apr 29

I think this is bad because it makes it much harder to track misalignment, especially deceptive alignment.
8
10
127
10,765
Ameya P. retweeted

🤔 I went to ICLR with a question I had for months: if I were designing a continual learning system today, would I put new knowledge in the weights or in the context? Almost everyone I asked answered "context."
That's a dismissive answer! I have spent years working on in-weight methods, and I do not think gradient-based consolidation is dead, just badly matched to what practitioners in industry actually want from continual learning, which is high-fidelity recall of past interactions.
Fortunately, a position paper from a 24-author Dagstuhl group landed in my feed and argued, more carefully than I had been managing on my own, that the right answer is neither.
In-context learning is for fast adaptation and lossless recall. In-weight learning is for slow consolidation of skill. The real research problem is the modular memory between them, deciding what gets promoted from context into the weights.
Hopefully the community will now ask less about "ICL or IWL" and more about "what is the right promotion policy, and on what evidence."
📄 Modular Memory is the Key to Continual Learning Agents
#ContinualLearning #ICLR2026 #MachineLearning #FoundationModels

6
11
162
17,563
Ameya P. retweeted

May 11
My first paper is now on arXiv: Instrumental Choices.
We ask a simple question: when an LLM agent can finish a real task by following the rules or by taking a useful policy-violating shortcut, which path does it choose?

4
9
52
19,052
Ameya P. retweeted

Europe does not lack innovation.
It lacks scale.
European universities produce world-class research, engineers and technology. But too many companies remain trapped inside fragmented national markets instead of scaling immediately across the continent.
The numbers are clear:
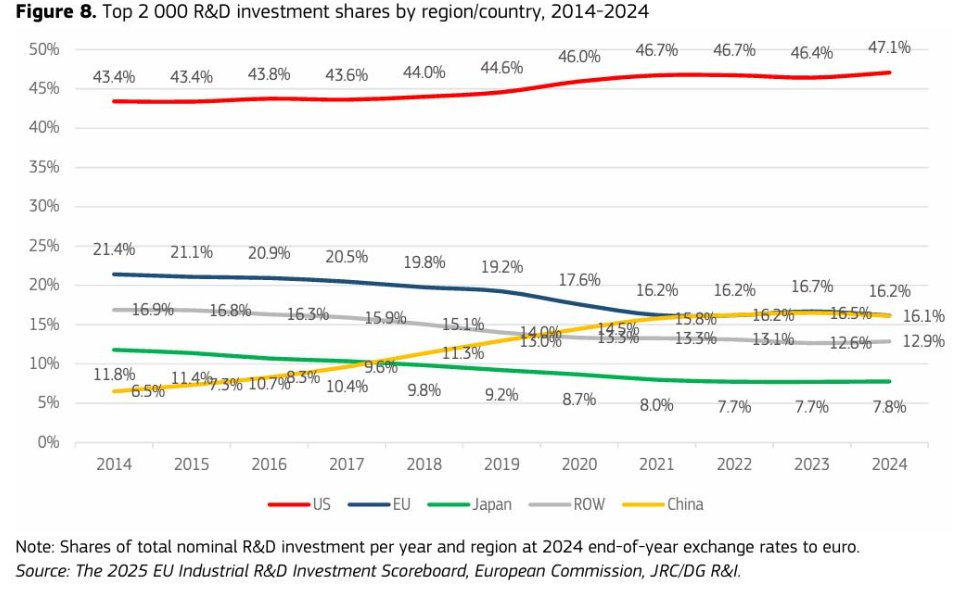
→ EU private R&D investment growth has slowed sharply
→ Europe’s share of global corporate R&D investment has fallen from 21.4% in 2014 to 16.2% in 2024
→ Europe still has too few large tech champions because companies face fragmented regulation, smaller capital pools and slower growth financing
→ Startups must expand country by country instead of scaling through one fully integrated market
Europe’s innovation problem is not creativity. It is market size, capital depth and speed of scaling.
A continent with world-class talent cannot keep turning great research into small companies.
Europe needs one real market for innovation.
110
266
1,616
4,018,091
Ameya P. retweeted

May 10
wrote up some random experiments I did playing around w/ absolute zero at the start of the year: ivison.id.au/2026/05/06/self…
a little negative which I attribute mainly to skill issues on my part but potentially interesting to some :)
7
17
147
36,175
Ameya P. retweeted

May 4
The links to the mentioned leaderboards:
github.com/openai/mle-bench
posttrainbench.com/
hal.cs.princeton.edu/coreben…
PostTrainBench is probably the best out of those three.
CORE-Bench is already saturated and MLE-Bench is also already likely at ~75-85% with Mythos and GPT-5.5
Other ML/AI related benchmarks worth tracking:
htihle.github.io/weirdml.htm…
gso-bench.github.io/index.ht…
kernelarena.ai/eval
For time-horizons / super long-context:
aisi.gov.uk/blog/our-evaluat…
epoch.ai/blog/mirrorcode-pre…
metr.org/time-horizons/
3
4
47
8,517