
Undergrad and PhD student @PKU1898, LLM Agent | AI4Science | Generative Models | Continual Learning .
Joined May 2023
- Tweets 80
- Following 137
- Followers 257
- Likes 67
30 Photos and videos








Pinned Tweet

Apr 29
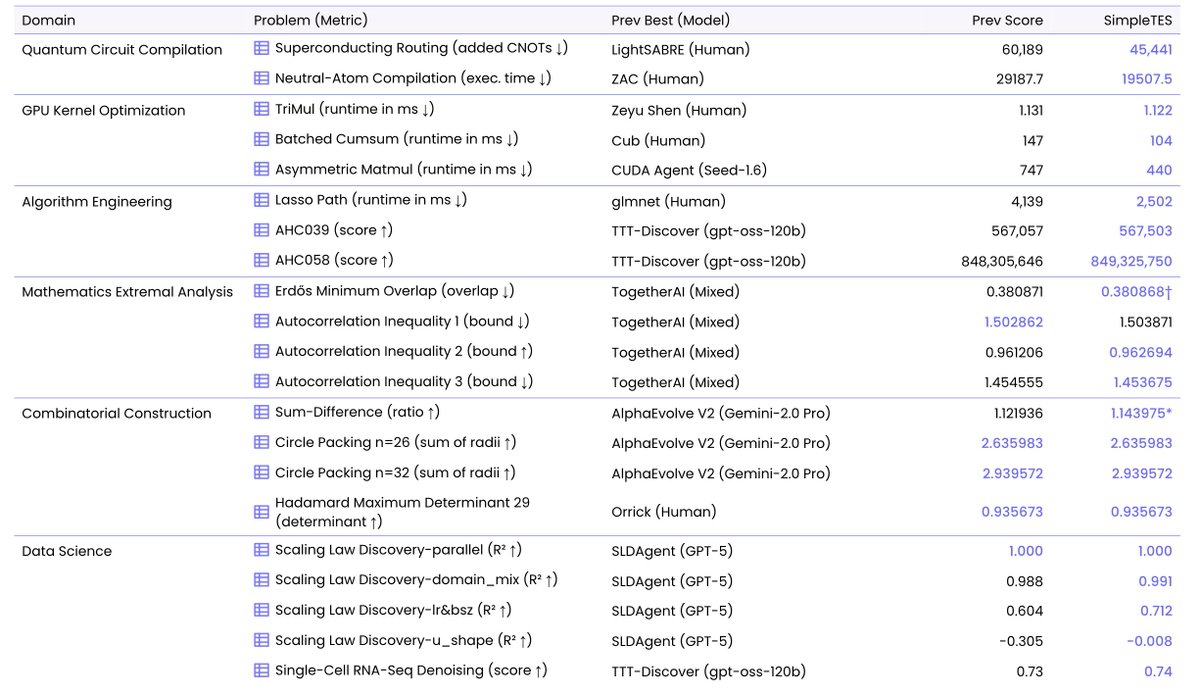
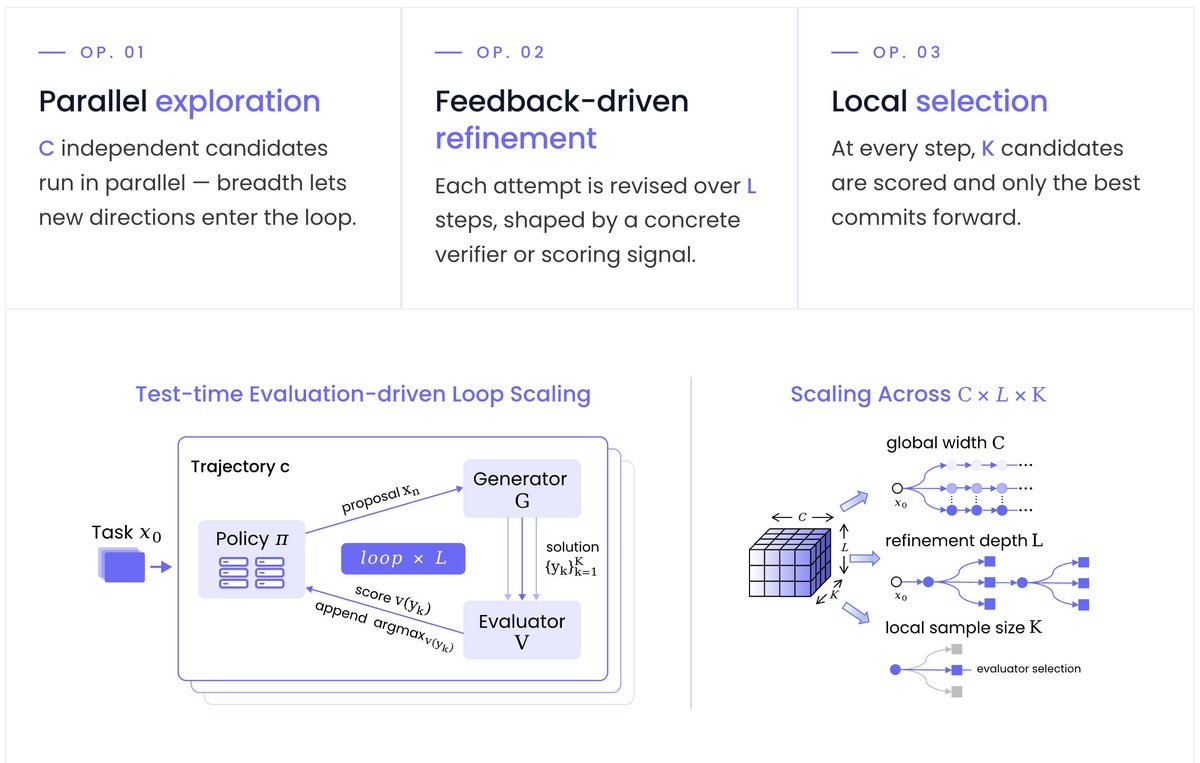
Excited to release SimpleTES: a better open-sourced AlphaEvolve!
With gpt-oss, SimpleTES discovers SOTA solutions across 21 tasks: quantum compilation, LASSO speedup, scaling law discovery, kenel optimization...
Project: wizardquant.com/will/simplet…
Code: github.com/wq-will/SimpleTES

1
5
22
784
Haowei Lin retweeted

May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵

16
111
496
905,557
May 5
Excited to see real-world CL is more and more popular and feasible!
May 4

Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10 frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)

3
108
Apr 28
Apr 28

New paper: Spend Less, Fit Better
Fitting scaling laws for LLMs can cost millions💰-but what if you can get the same insights with just ~10% of the budget?
We frame scaling-law fitting as budget-aware experimental design and propose a method to pick the most valuable runs.#LLM
2
213
Jan 29
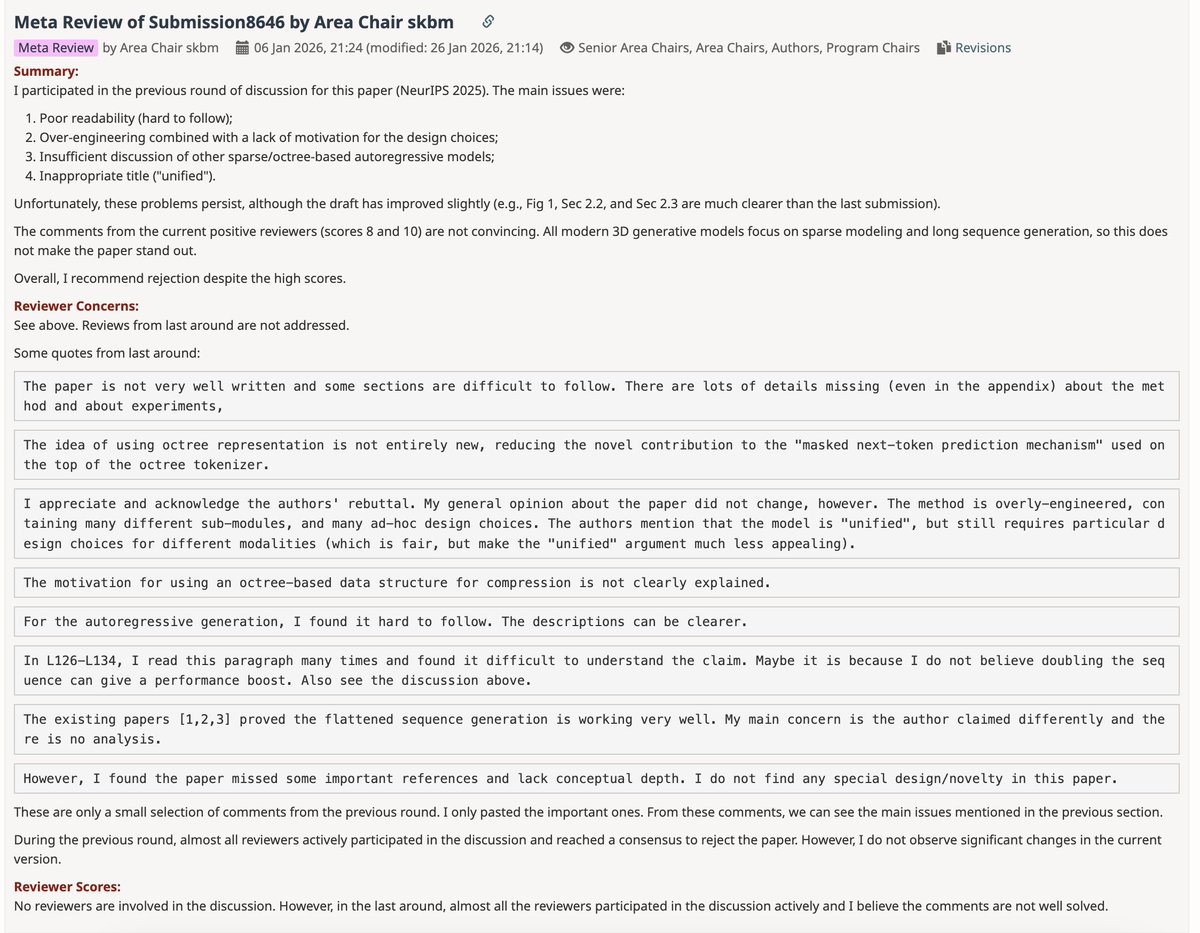
Winning the award for Highest Scored Rejected Paper at @iclr_conf . The AC is a harsh reviewer from NeurIPS and overrides all positive reviews and ignores every improvement made since NeurIPS.
Devastated because this is genuinely my best work yet.
openreview.net/forum?id=mnI8…

11
8
302
38,901
Jan 29
PS. The only negative scored review is the only "Fully AI Generated" review flagged by Pangram (iclr.pangram.com/reviews?sub…) . Other positive reviews are "Fully Human written". What an amazing rejection.
1
1
44
7,169
Jan 28
Excited to share that SLD has been accepted to ICLR 2026! 🎉
Also: SLDBench is now integrated into Harbor (github.com/laude-institute/h…), so you can quickly run any agents × LLMs with minimal setup. It’s much lighter-weight than SWE-Bench / PaperBench. Give it a try!
Jan 23

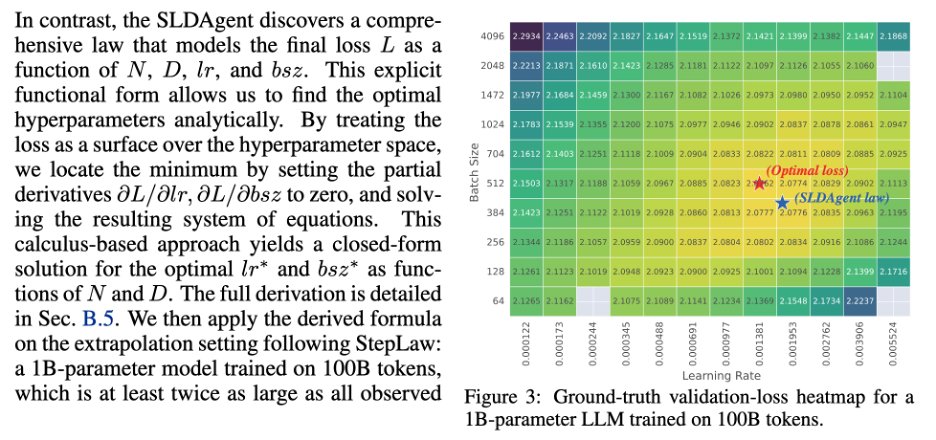
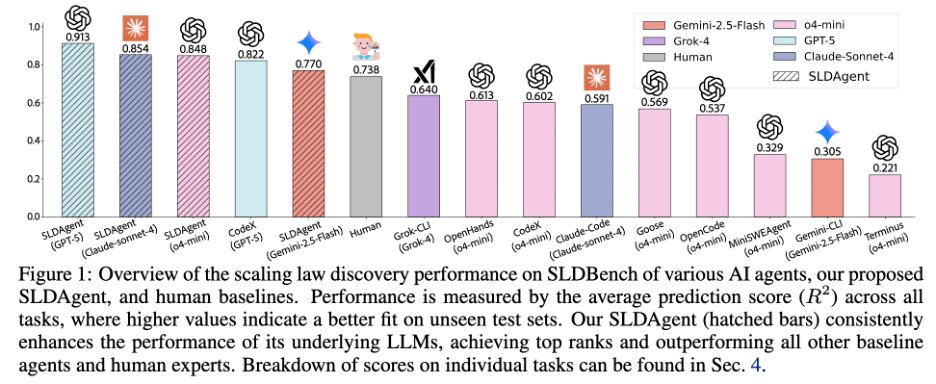
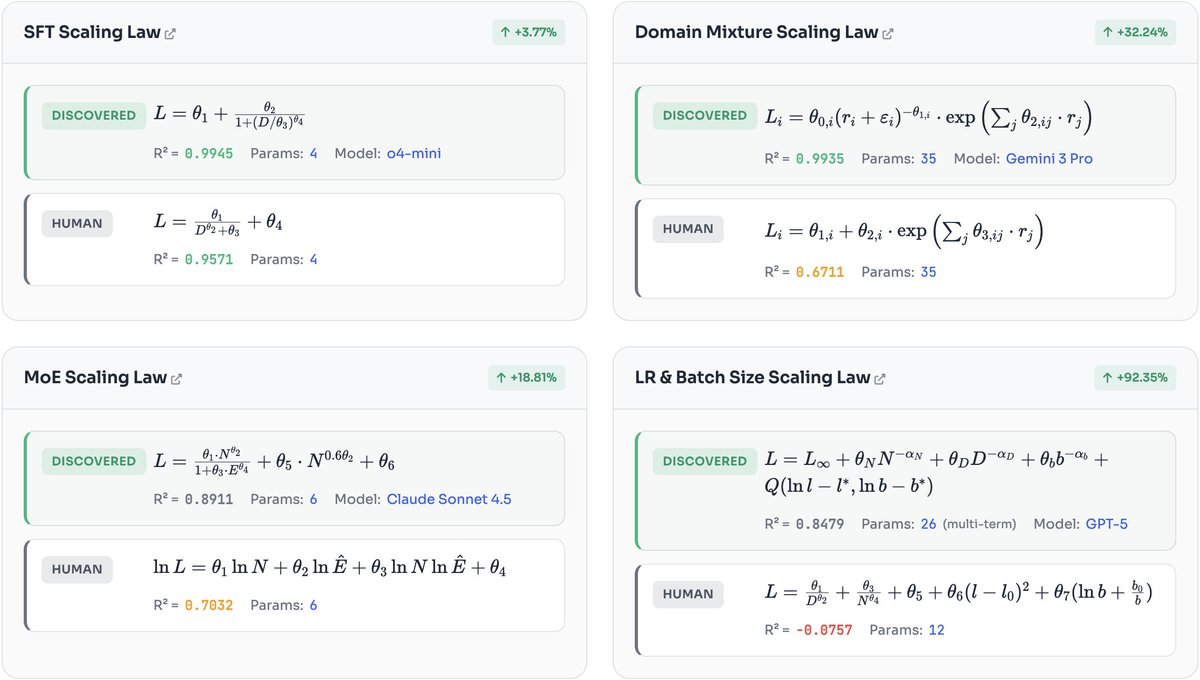
Sharing our interesting study on AI discovering its own physics! 🧪 Can AI scientists automatically discover scaling laws better than human experts?
We found that AI-discovered laws are not just more accurate: they are surprisingly interpretable and reveal patterns humans missed. 🤯
Check our blog for details: shorturl.at/zw1Ne

5
18
5,900
Haowei Lin retweeted

Jan 24
Brilliant paper from Stanford Tsinghua Peking University Wizard Quant
Shows an evolution style LLM agent can discover scaling laws that predict performance better than humans.
The big deal is that it turns scaling law writing from slow expert guesswork into an automated search that can guide expensive training and fine tuning decisions.
Scaling laws are simple formulas that guess how an LLM will do as it gets bigger, but experts still craft them by hand and they can fail in new settings.
The authors build SLDBench from 5,000 or more past training runs, and each task asks for 1 formula that predicts well on larger, unseen runs.
They propose SLDAgent, which keeps rewriting both the formula code and the parameter fitting code, testing each new version and keeping the best like an evolution loop.
This helps because the formula and the fitting method depend on each other, so improving only 1 often gives shaky predictions.
Across 8 tasks it beats human formulas on extrapolation, meaning prediction beyond the seen scale, and with GPT-5 its average R2 rises from 0.517 to 0.748.
The payoff is practical because it helps pick learning rate (step size) and batch size (examples per update) with fewer sweeps, and it helps choose which pretrained model to fine tune from small trial runs.

12
53
256
33,382
Jan 23
We created a new AI4Science task: AI as the science. It’s interesting to observe AI scientist explore its own mechanisms in the future.
Jan 23

AI discovers its own scaling laws!📈
SLDAgent uses symbolic reasoning evolution to find new laws that are more predictive/intuitive than widely-used expert-fit formulas. And they improve pretraining and fine-tuning!
Great work led by @AndyLin2001 @haotian_yeee!
1
1
499
Haowei Lin retweeted

Jan 22
The Terminal-Bench paper is here! Read it to learn where frontier models still fail and the secrets of how we sourced hundreds of high quality environments from our open source community. 🧵

21
102
459
103,757
Haowei Lin retweeted

6 Dec 2025
🤔Want a principled way to RL your diffusion model?
Check Data-regularized Reinforcement Learning (DDRL)! Post-train @nvidia #Cosmos World Foundation models with a million GPU hours! 🤯
Novel formulation ➡️ Theoretically integrates SFT into RL ➡️ Robust to Reward Hacking 🛑
Details: research.nvidia.com/labs/dir…
#DDRL #Diffusion #RL #NVIDIA #Cosmos
4
75
270
77,521
4 Dec 2025
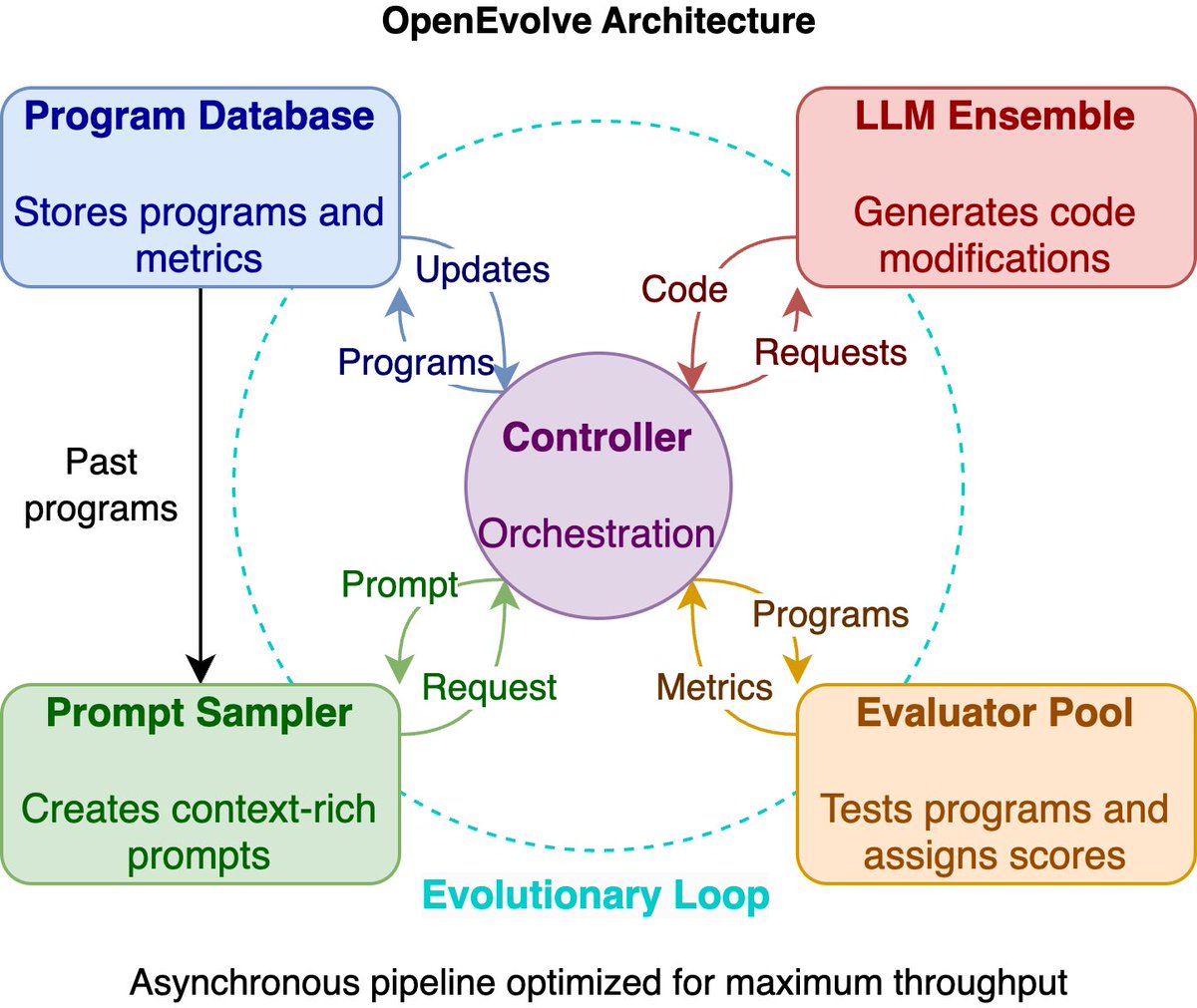
Check our new blog post in collaboration with Algorithmic SuperIntelligence Labs about using OpenEvolve to discover scaling laws: algorithmicsuperintelligence…
3
2
1,042
28 Nov 2025
Spent countless hours carefully reviewing for ICLR (even stepping in as an emergency reviewer), giving both positive and negative scores. To then be hit with this kind of unreasonable criticism is infuriating and deeply disappointing. Judge my reviews for yourself. @iclr_conf
4
15
6,583
28 Nov 2025
Very dramatically, in a paper with ID > 10000, I was surprised to see that I was the only reviewer who gave a positive overall recommendation (8442) for this paper. Sadly, this is not captured by OpenReviewers lol
3
1,317
30 Sep 2025
Can LLMs discover scaling laws?
The answer is YES. And they can do it better than humans.
arxiv.org/pdf/2507.21184v2
#AI #LLM #ScalingLaws #AgenticAI #ML
1
1
9
798
30 Sep 2025
An example of SLDAgent discovered law v.s. human law: conceptually sound and better fitness. This is really a newly discovered knowledge / science.
1
182
30 Sep 2025
SLDAgent is based on a simplified version of OpenEvolve @asankhaya (github.com/codelion/openevol…) with domain specific prompts, evaluator, and initial program. We also think SLDBench will be a good testbed for both evolving-based agents and general coding agents.
3
144
30 Sep 2025
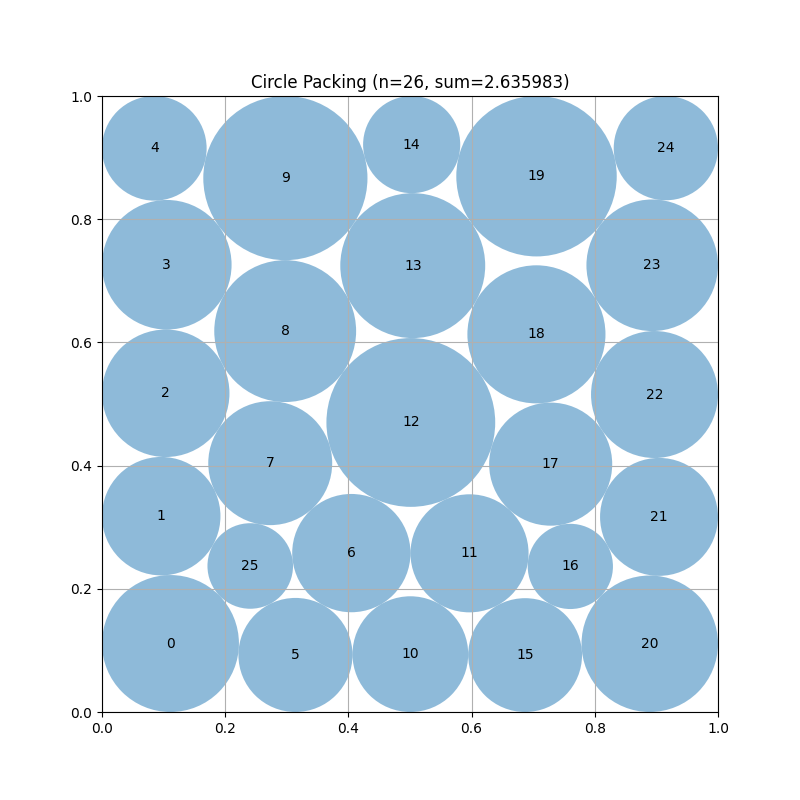
Impressive results from our latest run: OpenEvolve GPT-OSS-120B with single-phase evolution reached a score of 2.6359830849.
This not only tops AlphaEvolve (2.635863) but is within 1e-8 of ShinkaEvolve results—all without adding any new features.
@SakanaAILabs @asankhaya
1
2
2
518
30 Sep 2025
This shows OpenEvolve remains highly competitive, even with an OSS model. Are Shinka's results the current SOTA? I only run the experiments for 6 times and find this impressive one.
1
1
132