
Digital transformer
Joined March 2009
- Tweets 51,088
- Following 550
- Followers 731
- Likes 1,361
530 Photos and videos

Pinned Tweet

26 Dec 2025
Beyond De-Skilling: Intelligence Explosion and the End of Skill as a Stable Category
4m4.it/posts/beyond-de-skill…
1
1
3
432
Antonio Montano ☼ retweeted

Brandt, S. (2026). Theory of mind and language development. Cambridge University Press. doi.org/10.1017/978100949629…
5
13
752
Antonio Montano ☼ retweeted

Can a vision model learn to see with no augmentations, no masking, no cropping, no reconstruction?
🎬 It can! Introducing Temporal Difference in Vision (TDV), a new visual representation learning paradigm built on a single assumption: the past causes the future.
TL;DR :
- We introduce TDV, the first approach to learn useful representations without any augmentations, masking, cropping or pixel based reconstruction.
- TDV matches SOTA recipes like DINO and iBOT on dense spatial tasks
- We also show that as data scales up, weaker assumptions work better.
🧵Thread:

5
31
196
8,621

[LG] How Post-Training Shapes Biological Reasoning Models
L Fesser, H Zhang, M M. Li, E Wang… [Harvard University] (2026)
arxiv.org/abs/2606.16517




1
2
262
Antonio Montano ☼ retweeted

Neural Variability Enhances Artificial Network Robustness
Robin Preble, Praveen Venkatesh, Stefan Mihalas, Kameron Decker Harris
arxiv.org/abs/2606.13801 [𝚌𝚜.𝙻𝙶 𝚚-𝚋𝚒𝚘.𝙽𝙲]
1
2
145
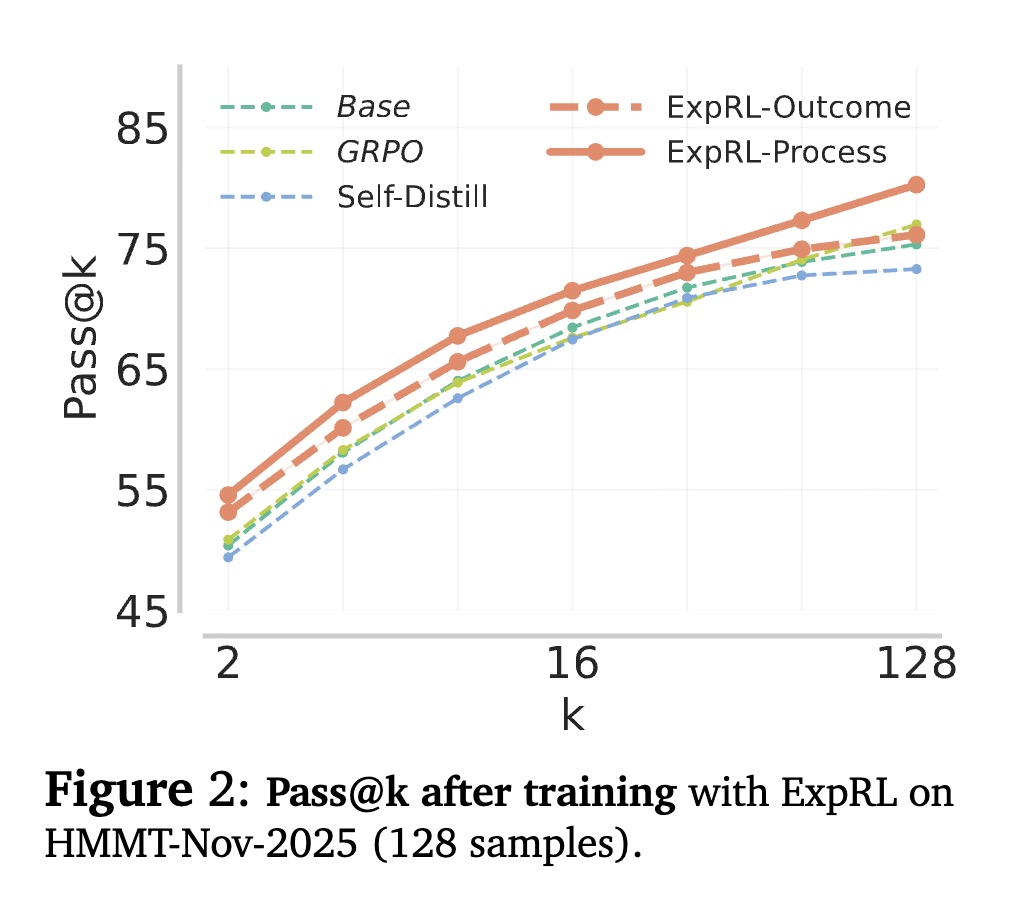
[LG] ExpRL: Exploratory RL for LLM Mid-Training
V Xiang, A Setlur, C Blagden, N Haber, A Kumar [Stanford University & CMU & OpenAI] (2026)
arxiv.org/abs/2606.17024



1
6
602
Antonio Montano ☼ retweeted
Gefen: Optimized Stochastic Optimizer
Nadav Benedek, Tomer Koren, Ohad Fried
arxiv.org/abs/2606.13894 [𝚌𝚜.𝙻𝙶 𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙲𝙻 𝚌𝚜.𝙲𝚅]
1
91
Antonio Montano ☼ retweeted

Agent trajectories as programs: fingerprinting and programming coding-agent behavior
Hamidah Oderinwale
arxiv.org/abs/2606.16988 [𝚌𝚜.𝚂𝙴 𝚌𝚜.𝙻𝙶]
1
5
120
Antonio Montano ☼ retweeted
Specifications for Humans, Agents, and Tooling
Mark Marron
arxiv.org/abs/2606.15084 [𝚌𝚜.𝚂𝙴]
1
1
6
136
Antonio Montano ☼ retweeted
Natively Unlearnable Large Language Models
Gaurav R. Ghosal, Pratyush Maini, Aditi Raghunathan
arxiv.org/abs/2606.13873 [𝚌𝚜.𝙻𝙶 𝚌𝚜.𝙲𝙻]
1
3
208
Antonio Montano ☼ retweeted

Next-token prediction is myopic. What if transformers learn to predict their own next latent state?
🌠 We present 𝗡𝗲𝘅𝘁-𝗟𝗮𝘁𝗲𝗻𝘁 𝗣𝗿𝗲𝗱𝗶𝗰𝘁𝗶𝗼𝗻 (𝗡𝗲𝘅𝘁𝗟𝗮𝘁): a self-supervised learning method that teaches transformers to form compact world models for reasoning and planning. It also unlocks up to 3.3x faster inference via self-speculative decoding! 🚀

ALT illustration of next-latent prediction vs. other predictive mechanisms
24
156
995
67,438
Antonio Montano ☼ retweeted

🚨 New Preprint!
🧠 We gave an AI model one simple rule: rearrange your neurons so that nearby ones respond alike. We never told it what a face, a voice, or a sentence was.
It grew brain-like maps for all three anyway. 🧵👇
🌐 Website: topo-omni.epfl.ch

4
30
97
7,081
The New Cognitive Infrastructure of Science – Random Bits of Knowledge 4m4.it/posts/new-cognitive-i…
1
Antonio Montano ☼ retweeted

Jun 16
Modern text-to-image models are increasingly powered by large pretrained LLMs.
But there is a curious mismatch: the LLM typically encodes the prompt only once, while the evolving noisy latent states are handled entirely by a newly trained generative backbone.
Can pretrained multimodal prior participate in the denoising process?
Introducing RepFusion. (1/12)
📄 arxiv.org/abs/2606.14700
🌐 xichenpan.com/repfusion/

2
29
93
15,748
Antonio Montano ☼ retweeted

"Learning the Geometry of Data: A Mathematical Review of Shape Space Analysis" (by Gary P. T. Choi, Khanh Dao Duc, Shira Faigenbaum-Golovin, Karen Habermann, Emmanuel Hartman, Christoph von Tycowicz, Chi Zhang, Wenjun Zhao, Felix Zhou): arxiv.org/abs/2606.17022
1
15
83
4,479
Antonio Montano ☼ retweeted

Jun 15
VLMs Systematically Fake Visual Understanding
Even when VLMs appear to be good at visual understanding, most of their answers are not actually grounded in the image (hallucinated!).
We identify two types of hallucinations that appear in up to 98% of answers that seem to demonstrate visual understanding.
First, textual biases. The model answers using language patterns, information in the question, and knowledge learned during training, without engaging its visual representations.
Second, spurious images. The model constructs false visual content inside its internal representation and then answers as if this imagined content were grounded in the real image.
In both cases, the answers may still be correct, but they are not grounded in the visual input at all!!

3
6
31
5,475
Antonio Montano ☼ retweeted

Cédric Villani le mois dernier : les LLM ne sont pas intelligents et ne comprennent rien à ce qu'ils racontent, ce ne sont que des machines statistiques réductibles à des fonctions ; la preuve de leur inintelligence, ces modèles se trompent sur l'exemple de la voiture à laver...
7 Dec 2025

En 6 ans Villani n'a rien changé à son discours. Sa conférence de 2024 en est une belle illustration. Fil avec extraits 🧵
Pour lui les IA ne sont "que des fonctions f(x)=y" et donc "pas plus intelligentes que la formule qui calcule vos impôts". C'est comme ça 🤷♂️
79
48
557
396,855
Antonio Montano ☼ retweeted

Jun 15
1/ Standard transformers have a fundamental topological flaw: they cannot track dynamic states over time without running out of layers.
Once a state representation reaches the top layer of the feedforward stack, the model's ability to update its belief collapses. 🧵

11
93
645
119,561
Antonio Montano ☼ retweeted

The alpha version of my new book "Optimal Transport
for Machine Learners" is out, with in particular an online version with interactive figures
gpeyre.com/ot4ml/

9
94
407
27,898
When a Nobel Laureate Uses an LLM to Prove a Theorem: A Turning Point for Mathematical Discovery – Random Bits of Knowledge 4m4.it/posts/when-a-nobel-la…
4
Antonio Montano ☼ retweeted

🚨🌍World models are surprisingly fragile!
We introduce BadWorld, an adversarial attack for visual world models.
A tiny perturbation to the starting image 🖼️ can break down the whole world.
Code:github.com/LinghuiiShen/BadW…
Paper:huggingface.co/papers/2606.1…
Arxiv:arxiv.org/abs/2606.16519
5
26
136
24,883