
@prometheusinc, x-Staff at @nvidia, x-prof at @Purdue #MachineLearning, #ArtificialIntelligence #NeuralOperators #AI #Science
Joined June 2014
- Tweets 1,107
- Following 1,342
- Followers 3,498
- Likes 6,119
76 Photos and videos






Pinned Tweet

16 Sep 2024
ICML2024 Tutorial on
"Neural Operators
& Machine Learning on Function Spaces"
is now out. #NeuralOperators #AInScience @nvidia @NVIDIAAI
youtube.com/watch?v=_j7bceE9…
Looking forward to building the future of this field with the bigger community, all together.

9
83
499
46,415
Kamyar Azizzadenesheli retweeted

5 Dec 2025
Today at NeurIPS (4:30-7:30pm), I will present our work on adaptive sampling for bridging the gap between physics informed models and numerical methods. It exploits many interesting links from orthogonal polynomials, quadrature rules and parametrization with neural networks.
1
1
1
498
4 Aug 2025
#NeuralOperators learn physics through data.
We study long term prediction capability of #NeuralOperator on a hard task of ocean emulation with variable forcing, making me think very seriously about coupled weather ocean model, #THEModel
4 Aug 2025

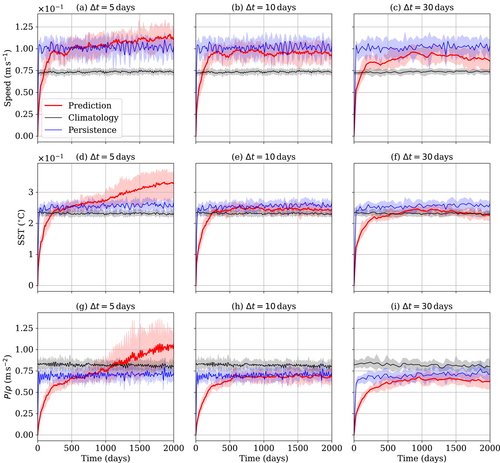
Excited to share our recently published paper in @WileyGlobal on "Ocean Emulation With Fourier Neural Operators: Double Gyre" agupubs.onlinelibrary.wiley.…
We used Fourier Neural Operators to build the first high-resolution weather model, FourCastNet. Since it works so well for atmospheric emulation a natural progression is to extend them to emulate ocean simulations.
We propose learning the dynamics of a simplified ocean simulation using Fourier neural operators. Fourier neural operators.
We are able to generate long forecasts using trained Fourier neural operators, and find that they are more accurate than using climatology or persistence on short-term forecasts and approach the accuracy of the physics-based model.
On long-term forecasts, the neural operators can still predict future scenarios with realistic physics like propagating waves and meandering currents. This is impressive because no physics is explicitly programmed into the neural operators. Physics is learned from data. @Azizzadenesheli
3
8
3,366
Kamyar Azizzadenesheli retweeted

4 Aug 2025
My @MLSysConf keynote is now online. mlsys.org/virtual/2025/invit…
The scaling of large language models has led to impressive gains in language understanding, but at a cost of insatiable memory and bandwidth requirements.
I advocated a principled approach of designing optimization and quantization algorithms that can reduce memory requirements without sacrificing accuracy.
This includes our research into gradient compression methods (GaLore, SignSGD) and logarithmic number system for representation.
We also design fine-grained memory reduction schemes such as KV cache compression, chunking and offloading to overcome memory bottlenecks in language models, especially in the reasoning mode where current memory requirements are massive.
Such principles are broadly applicable and especially relevant to physical AI where the memory and bandwidth requirements are even greater than frontier LLMs.
4
23
100
11,150
31 Jul 2025
FALCON: built on centuries of knowledge from fluid dynamics, turbulent flows, control, RL, and ML, to deliver foundational approach for aviation, tested and trained on real world wing, validated on the real world.
This is very exciting, thanks @BBCBreaking for featuring our work.
30 Jul 2025
Thank you @BBCNews for featuring our work using AI to overcome turbulence bbc.com/news/articles/ckgy7j…
1
1
12
3,277
23 Jul 2025
AI Science book is now up,
After years of work, our book on
Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems
is available at Foundations and Trends® in Machine Learning.
We cover the history of works in the intersection of AI and Science, to novel breakthroughs and advance in foundation of AI.
From neural networks to neural operators,
From PINNs to PINO and so on,
From computer vision to quantum, graph data, grid data, point cloud data, and GenAI in sciences,
From classical reduced order methods to learned ones.
Etc.
With an extraordinary list of co-authors
Xuan Zhang, Limei Wang, Jacob Helwig, Youzhi Luo, Cong Fu, Yaochen Xie, Meng Liu, Yuchao Lin, Zhao Xu, Keqiang Yan, Keir Adams, Maurice Weiler, Xiner Li, Tianfan Fu, Yucheng Wang, Alex Strasser, Haiyang Yu, YuQing Xie, Xiang Fu, Shenglong Xu, Yi Liu, Yuanqi Du, Alexandra Saxton, Hongyi Ling, Hannah Lawrence, Hannes Stärk, Shurui Gui, Carl Edwards, Nicholas Gao, Adriana Ladera, Tailin Wu, Elyssa F. Hofgard, Aria Mansouri Tehrani, Rui Wang, Ameya Daigavane, Montgomery Bohde, Jerry Kurtin, Qian Huang, Tuong Phung, @MinkaiX , Chaitanya K. Joshi, Simon V. Mathis, Kamyar Azizzadenesheli, Ada Fang, Alán Aspuru-Guzik, Erik Bekkers, Michael Bronstein, Marinka Zitnik, @AnimaAnandkumar , @StefanoErmon , Pietro Liò, @yuqirose , Stephan Günnemann, @jure, Heng Ji, Jimeng Sun, Regina Barzilay, Tommi Jaakkola, Connor W. Coley, Xiaoning Qian, Xiaofeng Qian, Tess Smidt, @ShuiwangJi
23 Jul 2025

Our 500 page AI4Science paper is finally published:
Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems. Foundations and Trends® in Machine Learning, Vol. 18, No. 4, 385–912, 2025
nowpublishers.com/article/De…

4
3
41
5,899
15 Jul 2025
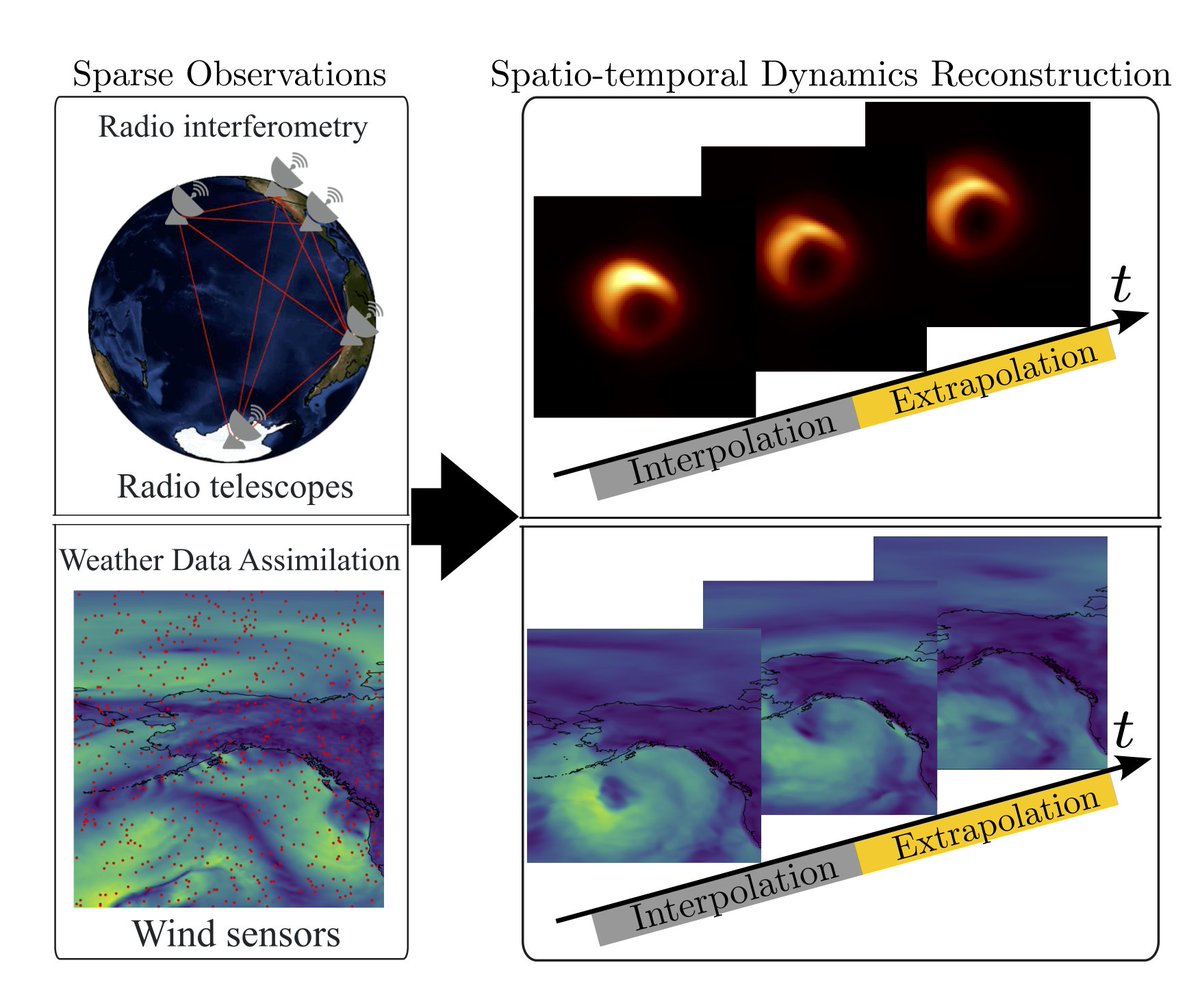
"NeuralDMD"—a fully interpretable neural framework that fuses neural implicit fields with Dynamic Mode Decomposition to recover spatio-temporal dynamics from very sparse and noisy data.
From black-hole imaging to weather nowcasting
Jw. Ali SaraerToosi, @tu_renbo, and Aviad Levis @UofT @nvidia
Paper: lnkd.in/gtGA7Ywu
Website: lnkd.in/gTa5HVTr
Code: lnkd.in/gu8FDKuT
3
28
1,409
11 Jul 2025
Translating the successful techniques, tricks, and developments in neural networks to neural operators to learn on any resolution.
We carefully planned out a practical and easy way to translate what we know works in neural networks and bring them all to neural operators, even go beyond and invent more.
Paper: arxiv.org/pdf/2506.10973
A joint work with @julberner @mliuschi @JeanKossaifi
Valentin Duruisseaux, Boris Bonev, and
@AnimaAnandkumar
The neural operator library to read through:
github.com/neuraloperator
11 Jul 2025
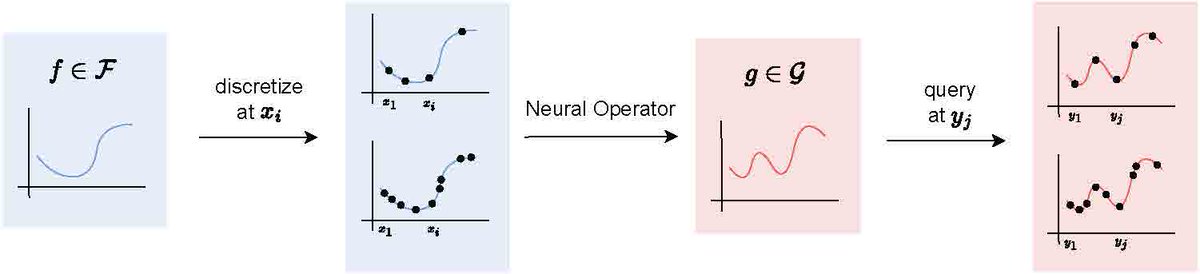
Neural Operators – Deep learning at any resolution
Extending neural networks to function spaces: While many phenomena are inherently described by functions, neural networks define vector-to-vector mappings that rely on fixed discretization of the input and output.
Neural Operators instead define learnable function-to-function mappings that guarantee consistent predictions across different discretization of the input and output functions. By respecting the functional nature of the data, neural operators can achieve improved performance and generalization.
Translating the success of deep learning to operator learning: Careful engineering of neural architectures has been a key factor in deep learning’s success. Translating these architectures to neural operators is crucial for operator learning to enjoy the same empirical optimizations.
Key principles for constructing Neural Operators:
*Recipes for converting popular architectures (CNNs, GNNs, transformers, etc.) into Neural Operators
*Guidance for practitioners
arxiv.org/abs/2506.10973
github.com/neuraloperator
@julberner @mliuschi @JeanKossaifi Valentin Duruisseaux Boris Bonev @Azizzadenesheli @caltech

5
25
3,709
Kamyar Azizzadenesheli retweeted
14 Jun 2025
The best undergraduate and graduate research awards at @Caltech commencement this year were presented to research on Neural Operators by my students @ZongyiLiCaltech and Miguel Liu-Schiaffini.
This recognition is a testament to their passion and dedication, and the impact their work has already had: from building a foundation for AI Science through multi-scale learning, creating the first high-resolution AI-based weather model, designing a novel medical catheter that reduces bacterial contamination, to name just a few.
The future of Physical AI will be built on the foundation of Neural Operators since the real world exists in multiple scales and resolutions, while standard deep learning only supports fixed resolution. This is essential for us to unlock the full potential of AI for scientific discovery.
#Caltech2025 #ai #science #NeuralOperators
10
12
130
30,080
11 Jun 2025
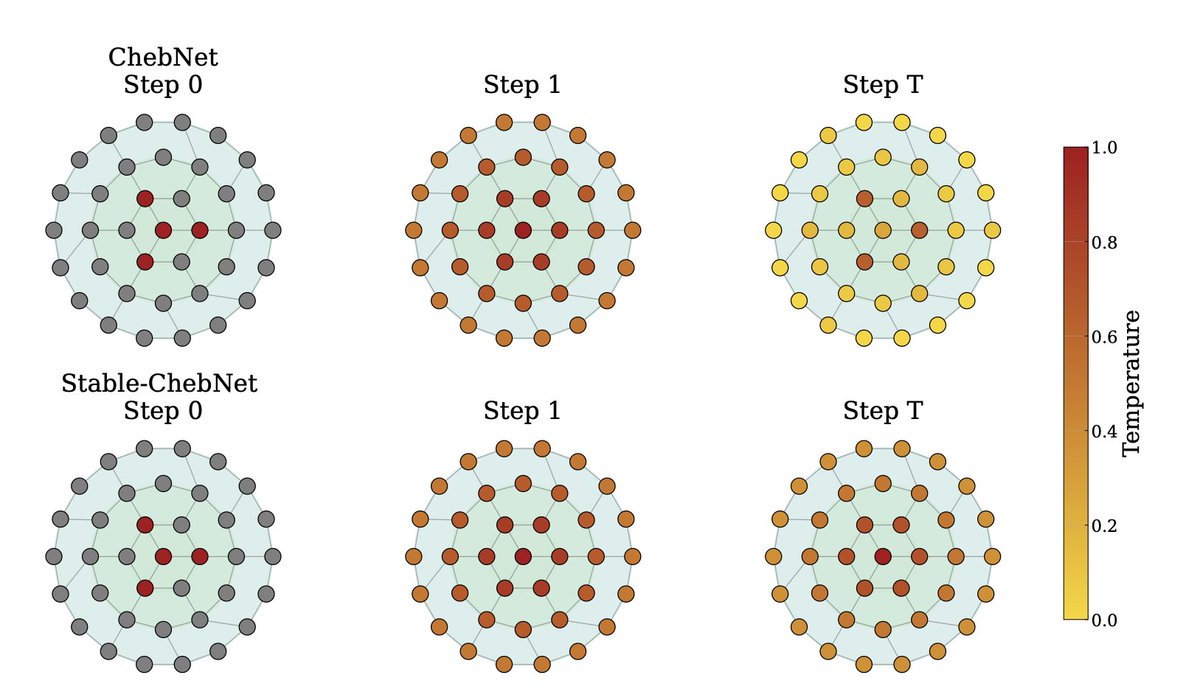
Stable-ChebNet
Stable long range dependency is essential for physics, social network, and science,
Technically, information needs to traverse effectively through out deep learning models without dissipating by due to lack of design.
We propose a fundamentally non-dissipative model with controlled stable information propagation, with strong empirical benefits on all the long range dependency benchmarks.
A great work led by @haririAli95, our rising star in ML and graph learning.
11 Jun 2025

📢ChebNet is back—with long-range abilities on graphs !🎉
We revive ChebNet for long-range tasks, uncover instability in polynomial filters, and propose Stable‑ChebNet—a non-dissipative dynamical system with controlled, stable info propagation 🚀
📄: arxiv.org/abs/2506.07624

1
10
2,964
6 Jun 2025
We developed the foundations of diffusion model and posterior sampling on function spaces.
We carefully extend Tweedie principle to function spaces which sits at the core of our methods.
We provide techniques for functional regressions/reconstruction given partial sample observations.
This way, we establish a few of the initial steps towards functional regression and data assimilation in science and engineering.
4 Jun 2025
Excited to introduce our latest work, Guided Diffusion Sampling on Function Spaces (FunDPS) (arxiv.org/abs/2505.17004) - a discretization-agnostic generative framework for solving PDE-based forward and inverse problems.
Diffusion-based posterior sampling on function spaces: Our model recovers full-field PDE solutions, coefficient functions, and boundary conditions from severely sparse (just 3%) measurements, yielding SotA performance in both speed and accuracy.
Multi-resolution operator learning pipeline: FunDPS leverages Gaussian Random Field priors and neural operator architectures, enabling multi-resolution training and inference, reducing training time by 25% and inference time by 50%.
Infinite-dimensional Tweedie’s Formula: We extend Tweedie’s formula into infinite-dimensional Banach spaces, forming the rigorous theoretical foundation for posterior mean estimation.
Results: Achieved an average 32% accuracy improvement and 4x fewer sampling steps compared to previous SOTA approaches across five challenging PDE tasks. Plus, our multi-resolution inference pipeline accelerates computations by up to 25x!
Paper (arxiv.org/abs/2505.17004). Code (github.com/neuraloperator/Fu…), based on our earlier workshop paper (ml4physicalsciences.github.i…).
@jiacheny7, @AbbasMammadov11, @julberner, @gavinkerrigan, Jong Chul Ye, @Azizzadenesheli
#DiffusionModels #InverseProblems #PDE #MachineLearning #NeuralOperators #AI4Science
1
10
1,411
6 Jun 2025
This work has been keeping me awake for quite sometime,
The secret sauce behind Adam is its Signum. This is just mind consuming, great work @orvieto_antonio and @gowerrobert.
It is also a great news for efficiency and MLSys communities.
29 May 2025

Adam is similar to many algorithms, but cannot be effectively replaced by any simpler variant in LMs.
The community is starting to get the recipe right, but what is the secret sauce?
@gowerrobert and I found that it has to do with the beta parameters and variational inference.
arxiv.org/pdf/2505.21829

1
1
17
5,640
28 Apr 2025
Human, mouse, monkey brain imaging,
Ultrasound imaging is about the study of wave functions and their functional inversion, constituting a critical path to brain imaging.
As a problem on function spaces, we introduce a novel #NeuralOperator technology for imaging, that is
1- exceptionally less invasive,
2- data and energy efficient
3- and fast
taking us towards the future of real-time brain imaging.
28 Apr 2025

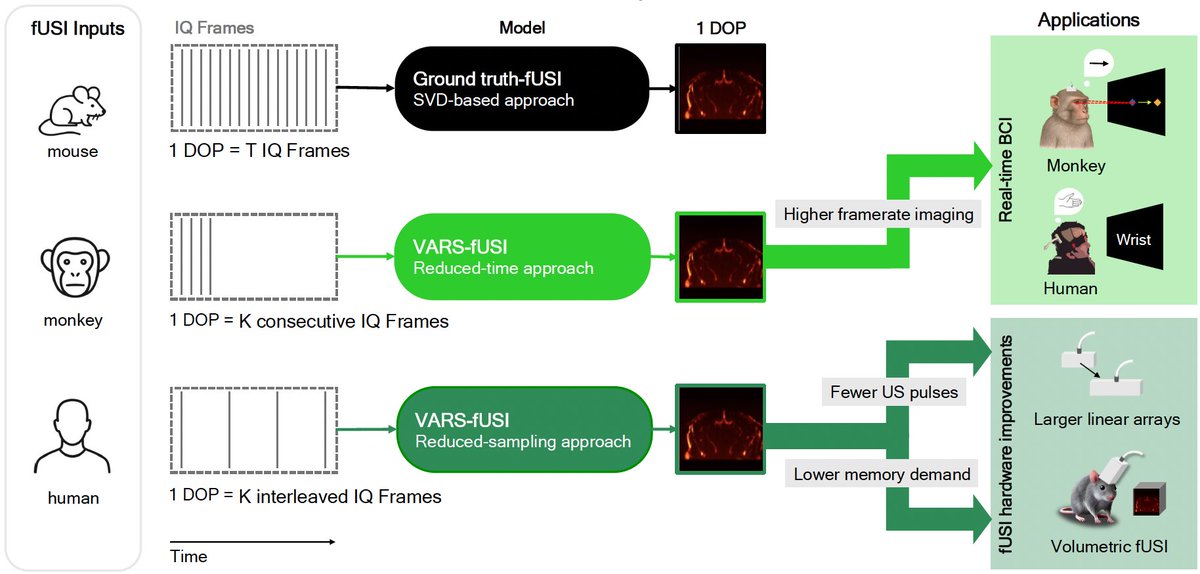
We have released VARS-fUSI: Variable sampling for fast and efficient functional ultrasound imaging (fUSI) using neural operators.
The first deep learning fUSI method to allow for different sampling durations and rates during training and inference. biorxiv.org/content/10.1101/… 1/
3
13
4,110
20 Mar 2025
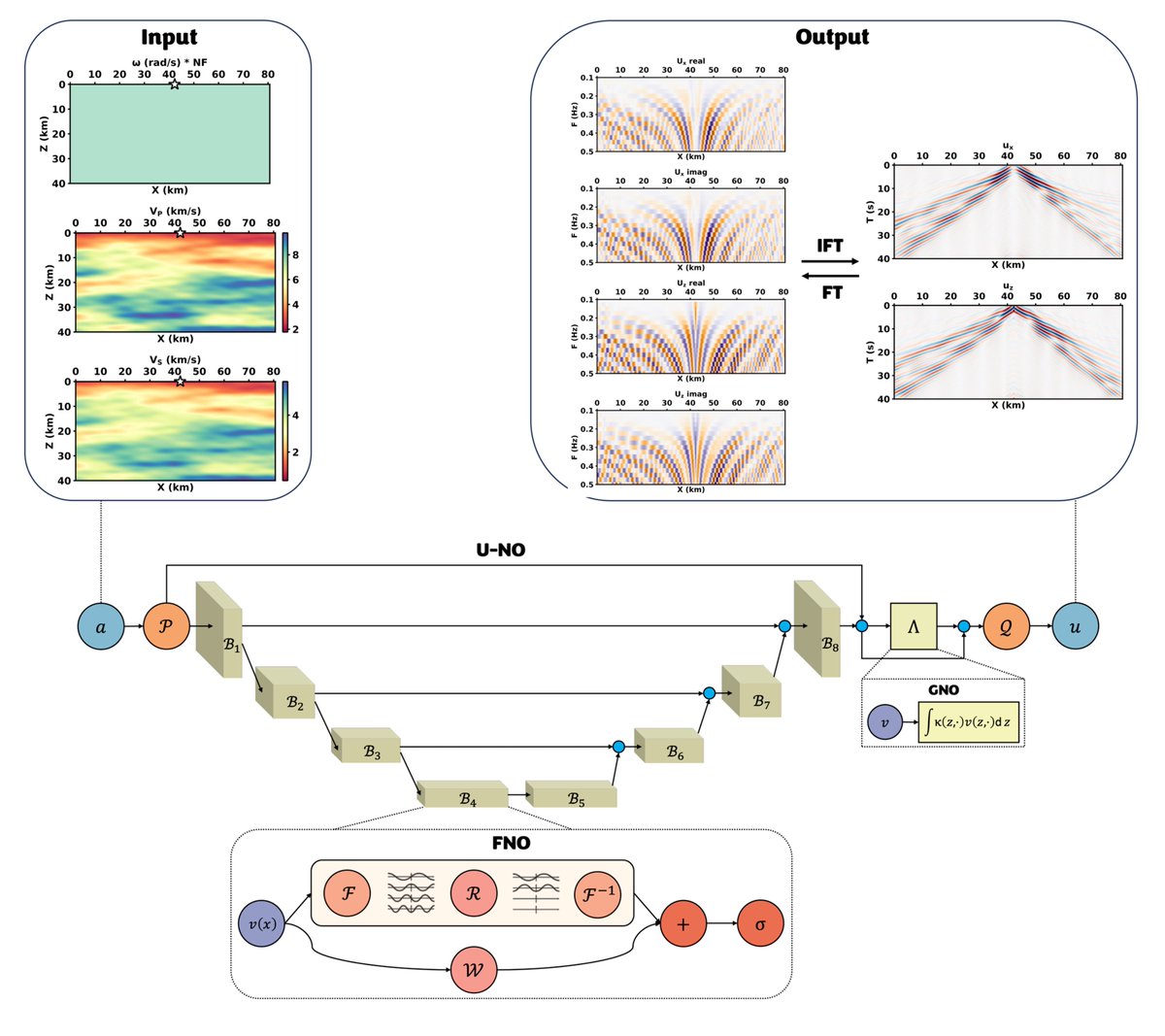
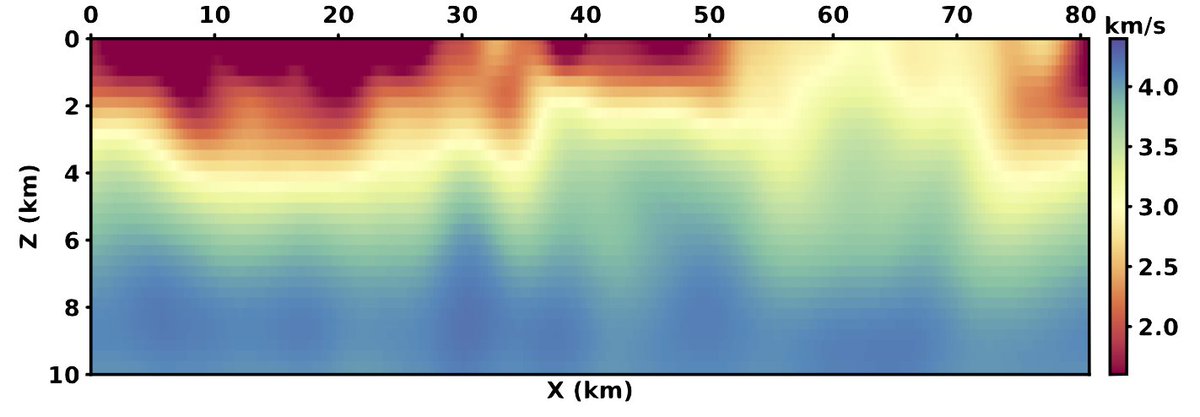
#NeuralOperators for real world seismology
Full waveform inversion on a real seismic sites, San Gabriel, Chino, and San Bernardino basins in the Los Angeles metropolitan area.
Steps:
1- Develop a domain-informed architecture
2- Train on generated function data resemble real phenomena
3- Do inversion on real data
For the first time, we can remove the "linear approximation" limitation of prior art that for decades ignored importnat details in subsurface Earth. Now we understand our Earth with much strong lenses.
For the first time we can run massive models with little memory footprint thanks to our domain specialized HelmholtzNO(HNO) architecture.
Paper: arxiv.org/pdf/2503.15013
#SanGabriel #Chino #SanBernardino
Joint work of #NeuralOperatorLab at @Caltech, University of Utah, and @nvidia @NVIDIAAI
Joint with Caifeng Zou, @zross_, Robert W. Clayton , Fan-Chi Lin
1
5
33
2,901
20 Mar 2025
5
497
Kamyar Azizzadenesheli retweeted
18 Mar 2025
Thank you for the honor!
18 Mar 2025

Congratulations to @Caltech's @AnimaAnandkumar on her 2025 @IEEEorg Kiyo Tomiyasu Award, sponsored by the late Dr. Kiyo Tomiyasu, @IEEE_GRSS, and @IEEEMTT, for contributions to #AI, including tensor methods and neural operators: bit.ly/IEEEAwards2025TFAs #IEEEAwards2025

16
4
158
8,014
7 Mar 2025
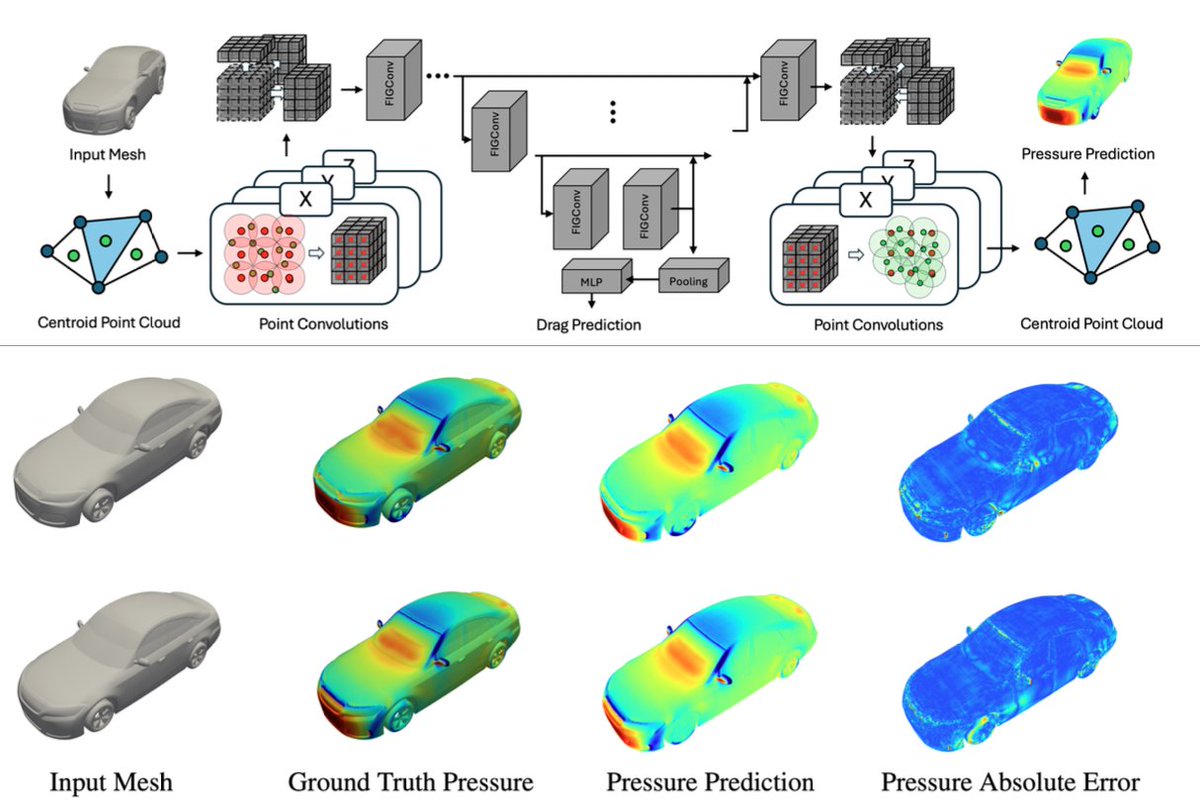
A new #NeuralOperator for #Automotive industry, a leap towards new generation of modern engineering.
10x more accurate than prior art,
140,000x faster that conventional methods
Fully open source!
We present Factorized Implicit Global Convolution (FIGConvUNet) that is
GNO 3D_U-shapeFactorizedConv GNO
Paper:arxiv.org/pdf/2502.04317
Code:github.com/NVIDIA/modulus/tr…
According to experts, the accuracy almost matches the solver accuracy, which is important to conceive.
5
10
83
200,366
7 Mar 2025
Jw: Chris Choy, Alexey Kamenev, @JeanKossaifi , Max Rietmann and @jankautz
The code is fully public in @nvidia Modulus.
Our work is an efficient and cuda optimized deep learning method to solve CFD problems for industry large 3D meshes and arbitrary input and output geometries.
We empirically validate our approach on the industry benchmark Ahmed body and the real-world DrivAerNet dataset based on Volkswagen DrivAer dataset, with geometries composed of 100 thousand and 1 million points, respectively.
1
1
787
7 Mar 2025
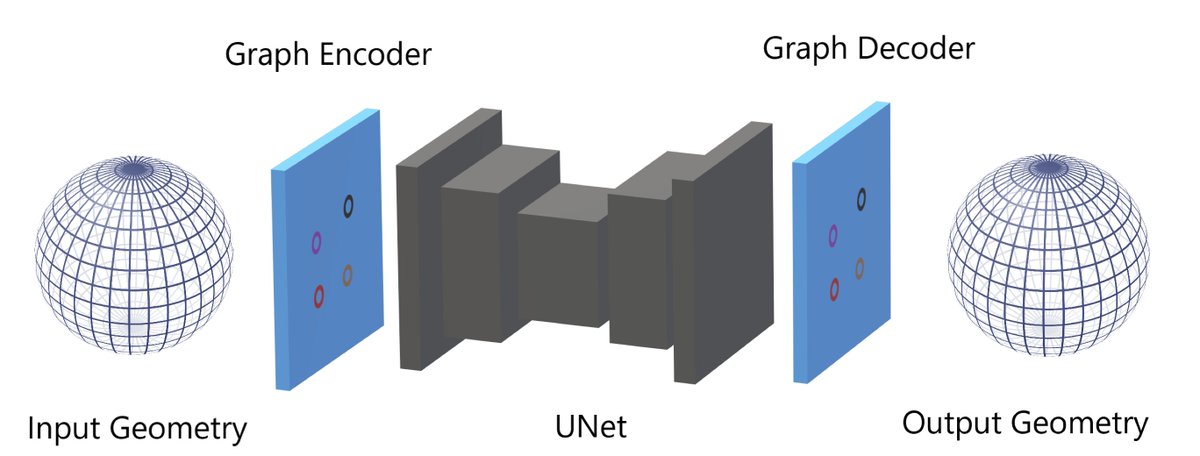
This is the continuation of "Geometry Informed Neural Operator" (GINO) line of developments led by
@ZongyiLiCaltech Nikola Borislavov Kovachki, Chris Choy, Boyi Li, @JeanKossaifi , Shourya Prakash Otta, Mohammad Amin Nabian, Maximilian Stadler, Christian Hundt, and @AnimaAnandkumar . #FNO #GINO #GNO #NeuralOperators
x.com/AnimaAnandkumar/status…
12 Dec 2023
Automotive aerodynamics aims to study the behavior of vehicles under motion, minimizing drag and detecting any undesirable behavior before the vehicle design is approved for production. This is typically done with a combination of simulation and wind tunnel testing, which are time-consuming and expensive.
We develop AI methods based on Geometry Informed Neural Operator (GINO) to dramatically speed up the simulations of industry-grade automotive geometries. An implementation of GINO is available in our open-source neural operator library neuraloperator.github.io/neu…
#Neurips2023 our poster "Geometry-Informed Neural Operator for Large-Scale 3D PDEs" on Tue at 11am, #500.
To benchmark simulation methods for 3D vehicle design, an industry-standard shape, Ahmed Body, shown below, is used. A reference traditional simulation (RANS) is expensive: it requires around 10 million mesh points in space, and each simulation takes a long time: up to 19 hours on GPU-accelerated OpenFOAM.
Our AI model predicts the drag coefficients 26,000 times faster than GPU-accelerated OpenFOAM and achieves good accuracy on the full pressure field. The model is based on the Fourier neural operator in the latent space, augmented by graph-based models at inputs and output layers to incorporate the irregular geometries of automotive surfaces. Our model is capable of zero-shot super-resolution, training with only one-eighth of the original mesh points, and having good accuracy when evaluated on the full mesh not seen during training.
@ZongyiLiCaltech @NKovachki @Azizzadenesheli @JeanKossaifi @caltech

1
3
587