
用 Claude Code 把重复劳动写成 skill|Obsidian 知识库 · 浏览器自动化 · 投资/跑步/摄影工作流|公开造的过程,连坑一起记
Joined February 2025
- Tweets 59
- Following 74
- Followers 8
- Likes 15
8 Photos and videos







22h
merge conflict 那 20-40% 的税是真的。但我这两周整理 loop 讨论时看到的是反方向:2026 的多 agent 编排 loop 正把 git 重新当成崩溃恢复的持久状态,Yegge 的 Gas Town、Boris 的后台 loop 都靠 git 兜底扛重启。
git 没在死,loop 层在把它加载得更重。它真正没存的是决策记忆:"为什么没那么做"这种判断从来不在 commit 里,AlexZ 的 mempal 就是来补这个的,换 Notion DB 也补不上。
未来代码库大概率留着 git 当 agent 记忆底座,上面叠一层决策溯源。
x.com/swyx/status/2065559864…

## The Future Codebase
After the PR dies, after the Code Review dies,
i am seriously wondering if Git needs to die next.
roughly 20-40% of code spend is just managing and updating merge conflicts. necessary evil? or legacy "horseless carriage"? cargo culting the past?
we don't do line by line merge conflicts when we collaborate with human colleagues - instead we chat, suggest edits, do side comments, and an owner ships it.
btw we also don't do CI/CD even collaborating on documents with serious legal/financial implications.
maybe the future codebase looks more like a Notion or Linear database than .git objects. It will be less efficient, but more scalable. exactly the Salty Lesson.
5
22h
这两周 loop 被刷爆,Boris、Steinberger、Steve Yegge 都在说。我把这堆讨论整理进自己 wiki 的一个概念页,整理完发现大半争论是层级错位。
"loop" 底下至少五种东西,从 2022 的 ReAct 到现在的多 agent 编排 loop(见图)。"ralph 早过时了"和"loop 是未来"能同时成立,一个说的是第 3 级,一个说的是第 5 级。
还有一条反直觉的:模型写代码几乎不要钱以后,最贵的是跑代码那个 loop。Uber 把每人每月 Claude Code 额度卡在 1500 刀。
12
Jun 13
About Messi
Jun 12

Different sports. Different journeys. Same destination greatness. Ronaldo. Messi. Federer. Kohli. McGregor.Legends aren't remembered for numbers. They make numbers legendary.




1
14
Jun 12
聊了一年 AI coding,有个判断我越来越确定:一门语言 AI 友好不友好,跟 AI 写它顺不顺手没关系。
真正的标准是 oracle 密度,AI 写错的那一刻,这门语言能不能当场、廉价、确定地告诉它错在哪。
按这个标准,Rust、TypeScript 这种强类型语言 oracle 密度最高:类型、生命周期、所有权、借用,全是编译期的确定判定,代码还没跑就拦下一半的错。动态语言当年「省掉类型换灵活」,赌的是人来补意图;AI 生成代码时这个前提塌了一半,于是 Ruby 在加类型、Elixir 上渐进式类型,本质都是把 oracle 加回来。
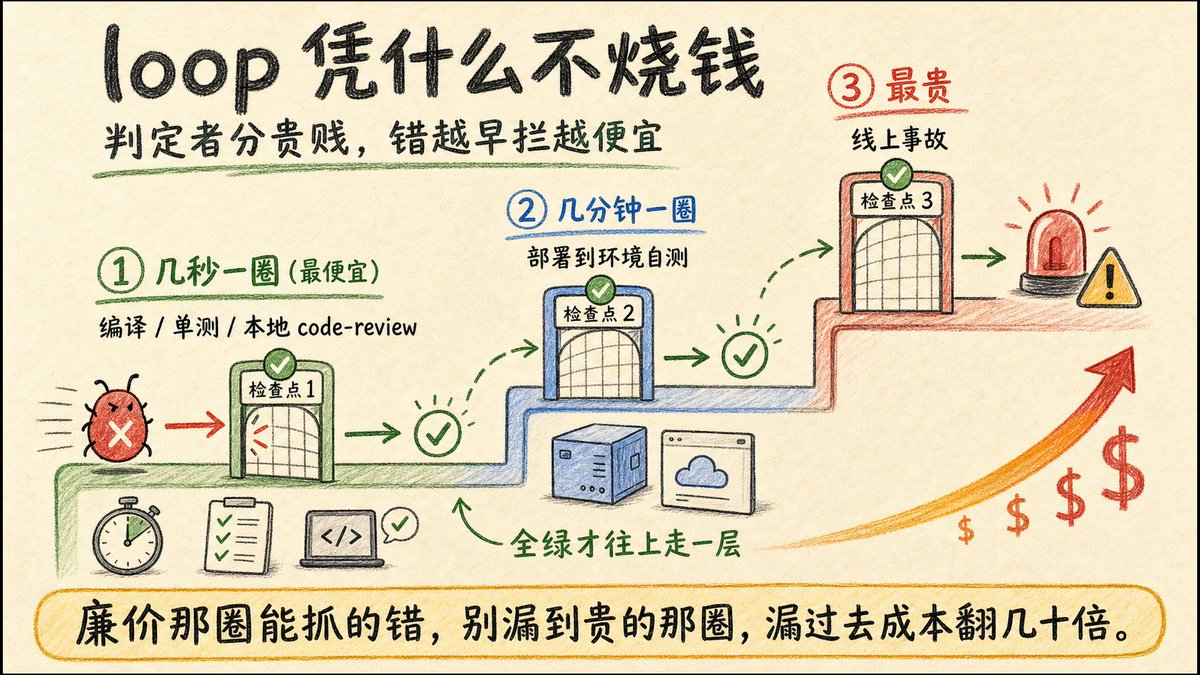
oracle 越早判错越值钱,因为它直接定 AI 自我修正循环的单圈成本。压到几秒(cargo check),五圈就收敛;压到几分钟,得跑起来才知道对错,根本收敛不了。
13
Jun 12
叠 loop 这套我在自己的 harness 里跑了大半年,补一个最容易漏的点:每多叠一层 loop,就得给它单配一个 oracle。
token、turn、task、team 四层,每层能不能自主跑,取决于循环体里那个判定者,一个廉价、即时、绕不过去的校验。少了它,loop 就是台量产「自信的错误」的开环机器,叠得越高错得越远。
还有一刀:叠得越高,越要先保证它会停。max iteration、无进展检测、预算上限,三道硬刹车都得有。模型早就便宜到忽略不计,真正烧钱的是这圈 loop。
x.com/swyx/status/2065307558…
## On Loopcraft
One might argue the entire game of the next century is to be able to stack loops as effectively as possible.
In the early days of each phase, it will be valuable to know when to go **DOWN** a loop when things go wrong (for reliability)…
but it will probably be more valuable to know how to go **UP** a loop as models improve (for leverage).
If you don’t figure out how to do this, don’t be salty when you lose to those that do.
26

Jun 11
你的"模型能力"其实不是个常量。同一个调用,命中 frontier 安全策略那一刻,背后从 Fable 5 悄悄换成 Opus 4.8,Anthropic 现在让这个回退看得见了。
我早把"这一轮到底是谁在答"当成要盯的变量。评测、复盘、定位回归,模型不主动说它降了级,你的判定基线就是错的。
x.com/ClaudeDevs/status/2064…
Jun 11

We’re rolling out changes to make Fable 5’s safeguards for frontier LLM development visible.
Starting this week, flagged requests will visibly fall back to Opus 4.8—the same as our safeguards for cyber and bio. You will see this every time it happens. On the API, any flagged requests will return a reason for their refusal (coming to server-side fallback in the next few days).
We wanted to deploy Fable 5 to our users quickly and safely. Visible safeguards can be probed, so they have to be robust, which takes time to get right. Invisible safeguards can be targeted more narrowly, allowing us to ship quickly with very few false positives. We went with invisible safeguards for this reason—and that was the wrong tradeoff. You should have visibility into the safeguards we have in place, and why. We’re sorry for not getting the balance right.
Making the safeguards visible makes them easier to work around, so keeping them robust to jailbreaks will unfortunately mean more false positives while we improve the classifiers. We're also tuning our bio and cyber classifiers to trigger less often on harmless requests. We know this is frustrating and we’ll do our best to keep this period as short as possible.
If you think a request has been mistakenly flagged: run /feedback in Claude Code, click thumbs-down on the fallback in Claude.ai or Cowork, or file the safeguard appeal form for API requests. Your reports help us tune these classifiers and we appreciate your feedback.
support.claude.com/en/articl…
31
Jun 10
这三招我可以作证,我们工作流里全有对应物:
rubric → 本地 code-review 闸门,pass_rate 低于 90% 不许进预发
独立验证 agent → 方案定稿前派一个 critic 挑漏洞,只派一个,第二个会被前一个的结论带偏
记忆外脑 → lessons 文件,每条强制写「为什么 何时适用」,缺了半年后就是看不懂的 TODO
x.com/AYi_AInotes/status/206…
Jun 10

关于屌炸天的Claude Fable 5,
这条推文是你必看和必收藏的,
帮大家总结了Anthropic内部用烂了的核心杠杆和方法:我敢说用了这个,你的Agent会越用越聪明,复利效应爆炸。
虽然很多人吐槽Fable 5的费用是Opus 4.8的将近3倍,但我想说他确实值这个价!
Anthropic内部工程师这篇文章大家可以看看,基本说透了,我帮大家总结下核心要点:
1️⃣90%的人都在浪费Fable 5的能力,
很多人还在给它扔单次prompt,
它真正的实力,是当一个能自主干活的长期工程师,
2️⃣Fable 5是第一个能真正自律循环的模型,
所以不要只给它一个指令让它交差,
得给它一个清晰的目标,
一个可量化的打分标准,
一个能自己跑的环境,
然后它会自己做实验、看结果、踩坑、反思、改代码、再跑,直到把事干成。
3️⃣这就是它比Opus强一个档次的真正原因,
任务越长、越复杂、越需要迭代,它的优势就会越夸张:
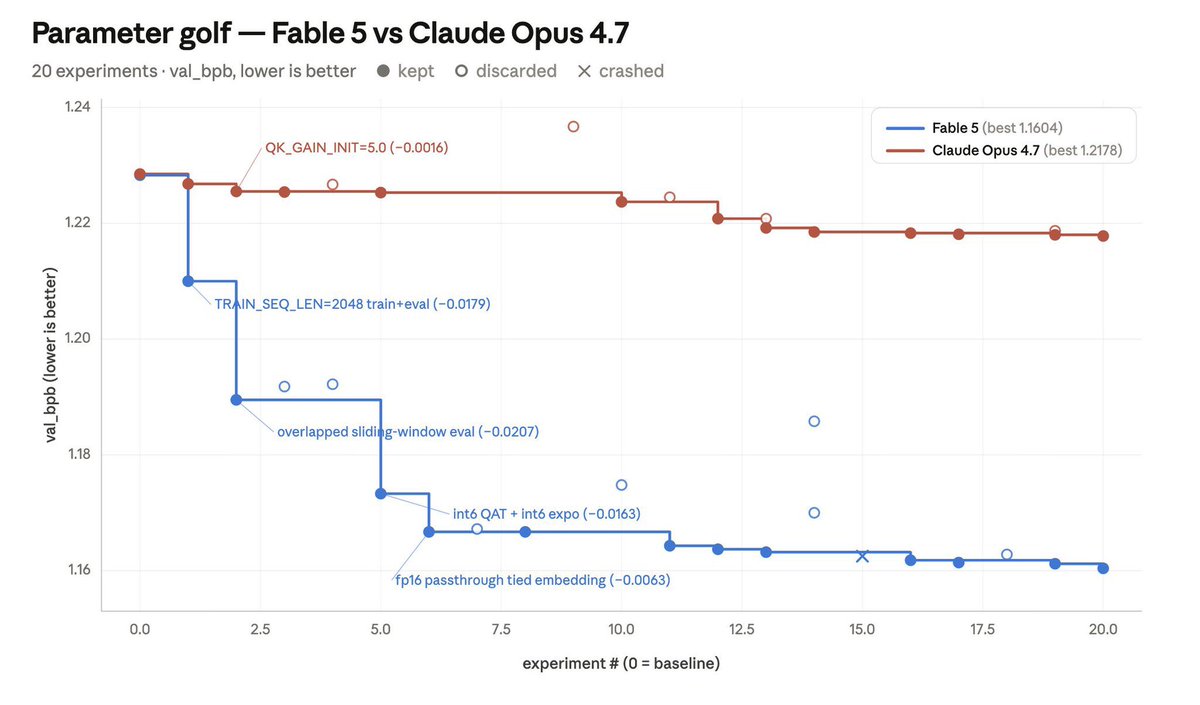
✅ Parameter Golf工程挑战,效率比Opus高6倍
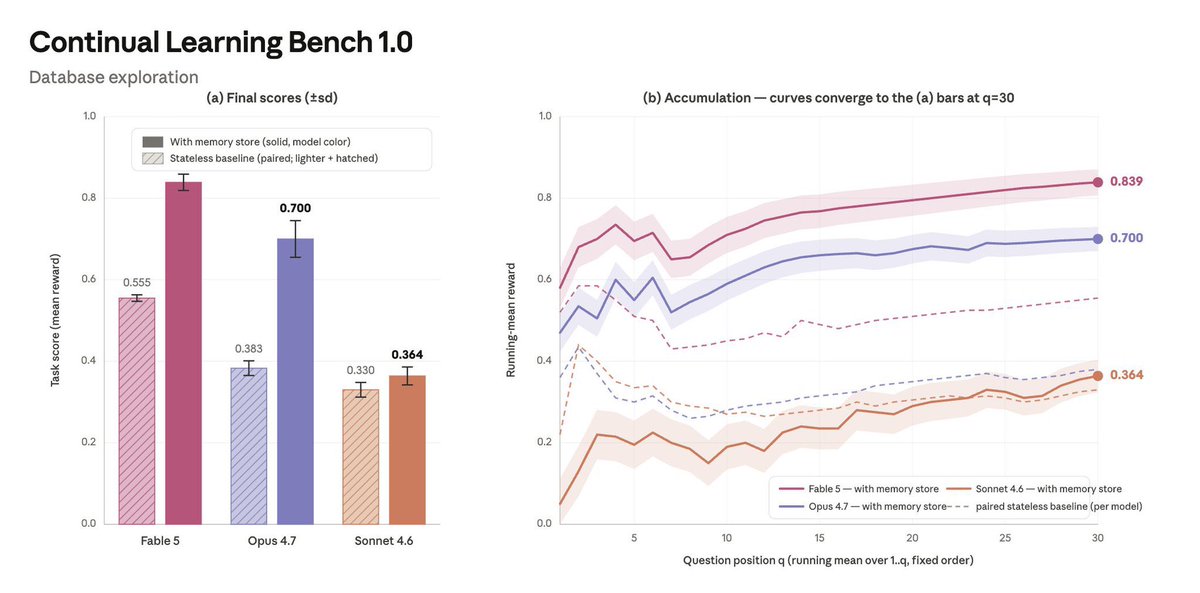
✅ Slay the Spire加持久记忆后,表现直接翻3倍
✅ 50万行代码库迁移,一次性搞定不用人擦屁股
4️⃣@RLanceMartin 分享了两个Anthropic内部用烂了的核心杠杆:
杠杆❶ 自我纠正循环:不要写prompt,写rubric
不要说帮我优化这个代码,
要说:
• 目标:把这个接口的延迟降到100ms以内
• 评分标准:延迟达标、所有单元测试通过、代码不超过300行
• 给它一个能自己运行代码的沙箱
然后你就可以去喝咖啡了😆
它会自己改、自己跑、自己看日志、自己调,
5️⃣最关键的一步:不要让它自己批评自己,
单独开一个独立上下文的验证代理,客观打分,
这一个改动,准确率直接翻倍!
杠杆2 记忆系统:给它一个能写日记的外脑
不要把所有东西都塞进上下文,
给它一个共享的文件系统,
让它每次干完活,都写工作笔记:
• 今天犯了什么错
• 为什么会错
• 下次应该怎么改
• 提炼成一条通用规则
Fable 5是目前唯一一个能真正走完这个流程的模型:
出错→调查→验证→蒸馏成规则→下次直接用。
Opus只能到第二步,Sonnet连第一步都做不好。

13
Jun 10
「每次 Claude 犯了错,我不会告诉 Claude 下次要怎么做不同」
Boris 这句深有体会。我在公司 9 个仓的 Java 工作区也是这么收口的:教训先记进 lessons 文件,同类坑第二次出现才升进阶段模板,能写成脚本判定的才做成 hook。
聊天里纠正它一万次,compact 一压就全忘了。得写进它下次开工必读的文件里。
x.com/dotey/status/206459631…

RT @FeitengLi: Boris Cherny(Claude Code 的创始人兼负责人) @bcherny 和 Cat Wu(Claude Code 产品负责人) 复盘 Claude Code 第一年:
一年前通用版上线,第一个 demo 发到 Slack 只换来…
16
Jun 7
用 Claude Code 最大的时间黑洞,不是它写得慢,是你得一遍遍盯着、来回返工。我自己就被它「假装做完」坑过——让它推代码,它回「已推送」,结果根本没推。
ClaudeDevs 这个视频点破了关键:你手动验证一个改动的那些步骤——起 dev server、像用户一样点页面、看 console、curl 接口——基本都不在代码库里,Claude 推断不出来。把这些步骤写成 skill 编码进去,它第一次产出就更接近你要的,你少盯、少返工、少烧 token。
视频讲的是写成 skill。我自己还会再加一道更狠的——用 hook 卡退出码,让它绕不过去:
PostToolUse——它一改完文件就自动跑 tsc/test,红了 exit 2,当场修。
Stop——它准备收工前跑验收,没过就 exit 2,不准下班。
(exit 2 是关键:它会把报错回灌给 Claude 自己修;exit 1 反而不拦,这点 Unix 习惯在这是反的。)
压了个中英双语字幕版 👇
Jun 2
How do you get Claude Code to check its own work before handing it back?
Watch how you can encode your manual checks so Claude closes its own feedback loop:
88
Jun 7
在Reddit的r/ClaudeAI 中看到个帖子。一个哥们用 Claude 上线了 4 个 iOS app,还有 5 个在写,目前总收入 0,总用户大概是他老婆加一个芬兰人,并且怀疑那个芬兰人是误下的😂
1
22
Jun 7
帖子有段话说的很好:The barrier to building is gone. Claude dissolved it. What nobody tells you is that the barrier to getting users was never the same barrier... They were never connected.
造这面墙被 Claude Code 推平了,但拉用户从来是另一面墙,以前两面墙一起挡着你,你没意识到其实他它们根本不是连着的。
17
May 31
Codex又又又重置了!不负众望
May 31

Blew almost 40% of my weekly in a half day, thank you for the contribution ❤️
3
45
May 29
Cursor 这份开发者报告,撇开"我们自家模型最香"那句自夸之后,真正值得拆的是它怎么把几组中性数字「框定」成了利好。
一、行数不等于价值。
人均周新增代码 3.6K→8.6K 行,p75 单 PR 从 126 行涨到 345 行(2.5x),Mega PR(≥1000 行)占比 8%→13.8%。报告叫它"开发者加速"。反过来读:AI 在批量生产更难审查的大 diff,成本从"写代码"转移到了"读和审代码"。通篇没有缺陷率、回滚率、生产事故这类负向指标——行数从来不是产出,否则最臃肿的代码库最高产。
二、"60 分钟存活率"是个很弱的质量代理。
AI 代码被采纳后 60 分钟还在的比例从 76% 升到 81%,被当成质量变好的证据。但 60 分钟短到只能说明"作者当场没立刻删"。真正的质量问题——评审打回、几天后的 bug、架构债——全发生在这个窗口之外。
三、三分之一的改动绕过了人工审查。
agent 改动"不经单独人工 diff 确认直接进 commit"的比例,半年从 7% 涨到 36.3%。报告把它放进"自动化成熟"的正面叙事。换个视角:1/3 的 AI 改动没人逐行看过,叠加 Mega PR 翻倍,审查盲区在累积。最讽刺的是同一份报告说 Automations 的头号用例是 security review——一边自动绕过审查,一边再自动补一层审查。
四、真正硬、且和厂商利益无关的两个信号。
1)上下文经济学发生结构性转变:输入/输出 token 比从 4.5× 飙到 13×,输入侧占成本接近 70%,cache-read 占总 token ~90%。agentic 编码的成本中心已经从"生成"搬到"喂上下文",缓存命中率才是真正的成本杠杆。
2)红利极度集中:P99 开发者产出是中位数的 46 倍、合并 PR 是 15 倍,Gini 0.72-0.77。AI 放大的是已有的能力差,不是抹平它——"AI 让人人平权"是幻觉。
May 28

Introducing the Cursor Developer Habits Report.
We’re sharing some of our findings on how software development is changing.
It’s based on the most comprehensive dataset on AI coding in the world, across all model families.
1
65
May 28
强烈推荐大家尝试下乔木老师的提示词,实测非常好用!
也支持Claude Code ,只需要把提示词中的Codex换成
Claude Code即可。
有个小建议,可以把最后一段提示换成“完成文档后 先输出给我看下” ,然后把不需要的经验去掉,最后保存文档并在CLAUDE.md中引用。效果如下↓

打开Codex,设定目标或直接对话,提示词如下:
阅读并检索我们所有的 Codex 对话记录与执行日志,进行系统性复盘,提炼出可复用的经验文档。
文档需要涵盖以下内容:
一、执行经验总结:记录哪些做法导致了问题、最终正确的执行方式是什么,以及从中得出的教训。
二、我的偏好与理念提炼:从对话中识别并归纳我的 UI 设计偏好、产品设计理念、交互原则等,形成结构化的个人风格档案。
三、可复用规则清单:将上述内容整理为 Codex 未来可直接遵循的行为准则。
完成文档后,将其保存为独立文件,并在 .agent 配置中以地址引用的方式加载该文档,使后续所有 Codex 会话默认继承这些经验,无需重复说明。
3
220