
Leading the Cognition, Computation, and Consciousness Lab at Vanderbilt University
Joined November 2021
- Tweets 405
- Following 345
- Followers 1,268
- Likes 414
Photos and videos
End of MaDeLaNe workshop 2026. See you next year, and keep recording those brain networks and neurons!! Thank you to all contributors, especially our special guest BCI pioneer @ScottImbrie for the inspiration to push the frontier of Science!

1
4
270
Getting a chance to meet Scott Imbrie, BCI pioneer, at MaDeLaNe together with colleagues. Amazing moment together exploring how neuroscience can help humanity

1
2
339
Day 1 of our MaDeLaNe workshop at Vanderbilt! We are learning about @KiaBanaie 's new spike sorting technique (KIAsort) and applying it to high density data (amongst other topics). More info here, madelane.bastoslabvu.com


1
9
546

May 30
LOL, I also had this experience today. Felt bad by causing a crazy high token request to just translate a simple script from Matlab to Python

1
199
André M. Bastos retweeted

Introducing the International Brain Lab AI Agent: an experimental tool that helps researchers analyze neural activity across the mouse brain using AI coding agents.
Please try it — we would love your feedback!
github.com/int-brain-lab/ibl…

2
37
119
17,359

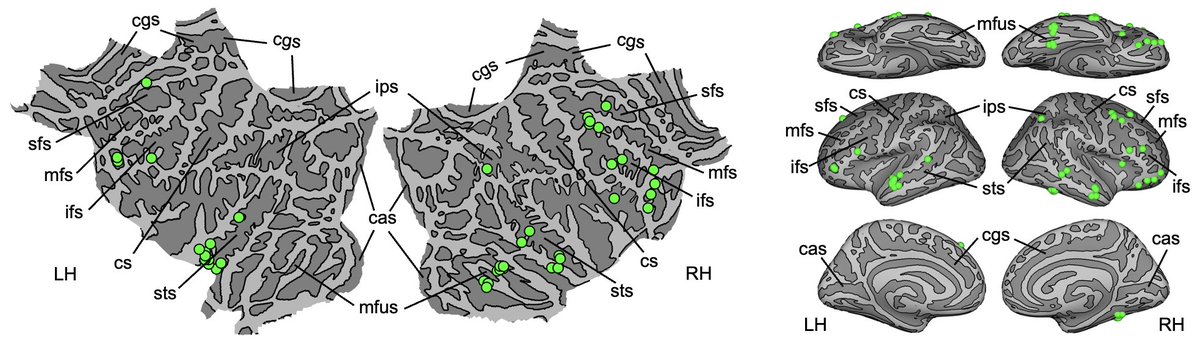
New preprint: "Monosynaptic connections link functionally similar regions in human cortex." We use electrical stimulation fMRI in epilepsy patients to map whole-brain monosynaptic connectivity at 42 cortical sites. doi.org/10.64898/2026.05.19.… 1/n
2
27
80
9,030
André M. Bastos retweeted

May 20
Jensen Huang just told Stanford to their face that their compute problem is their own fault.
And then he explained exactly how to fix it.
This was the complaint: independent researchers, startups, universities across America can't get enough compute. AI is transforming science but the people doing science can't access the tools they need.
Jensen pushed back hard on one part.
It's not that Nvidia isn't delivering. It's that nobody is placing the orders. You can't show up expecting a billion dollars of compute to be sitting on the shelf.
But the deeper problem is structural. Universities stopped building centralized compute decades ago. Every department raises its own grants, controls its own budget and nobody shares.
"Stanford's not alone. You don't have a budget for a billion-dollar compute. It doesn't exist."
His prescription: Stanford has a $40 billion endowment. Cut $1 billion, give it to a cloud provider and give every student and researcher on campus access to AI supercomputers.
The same logic applies everywhere. The institutions that figure out how to pool compute and make it available to their best researchers will produce the next generation of breakthroughs.
The ones that keep running on laptops and individual grants will fall behind.
12
18
112
13,651
André M. Bastos retweeted

May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
136
973
7,418
575,197
André M. Bastos retweeted

May 11
Drawing on a large-scale dataset of more than 12 million scientists, a new #SciencePolicyArticle reports that early-career scientists may be more inclined toward transformative breakthroughs, whereas seasoned researchers excel at synthesizing and extending existing knowledge. scim.ag/4wi7emp
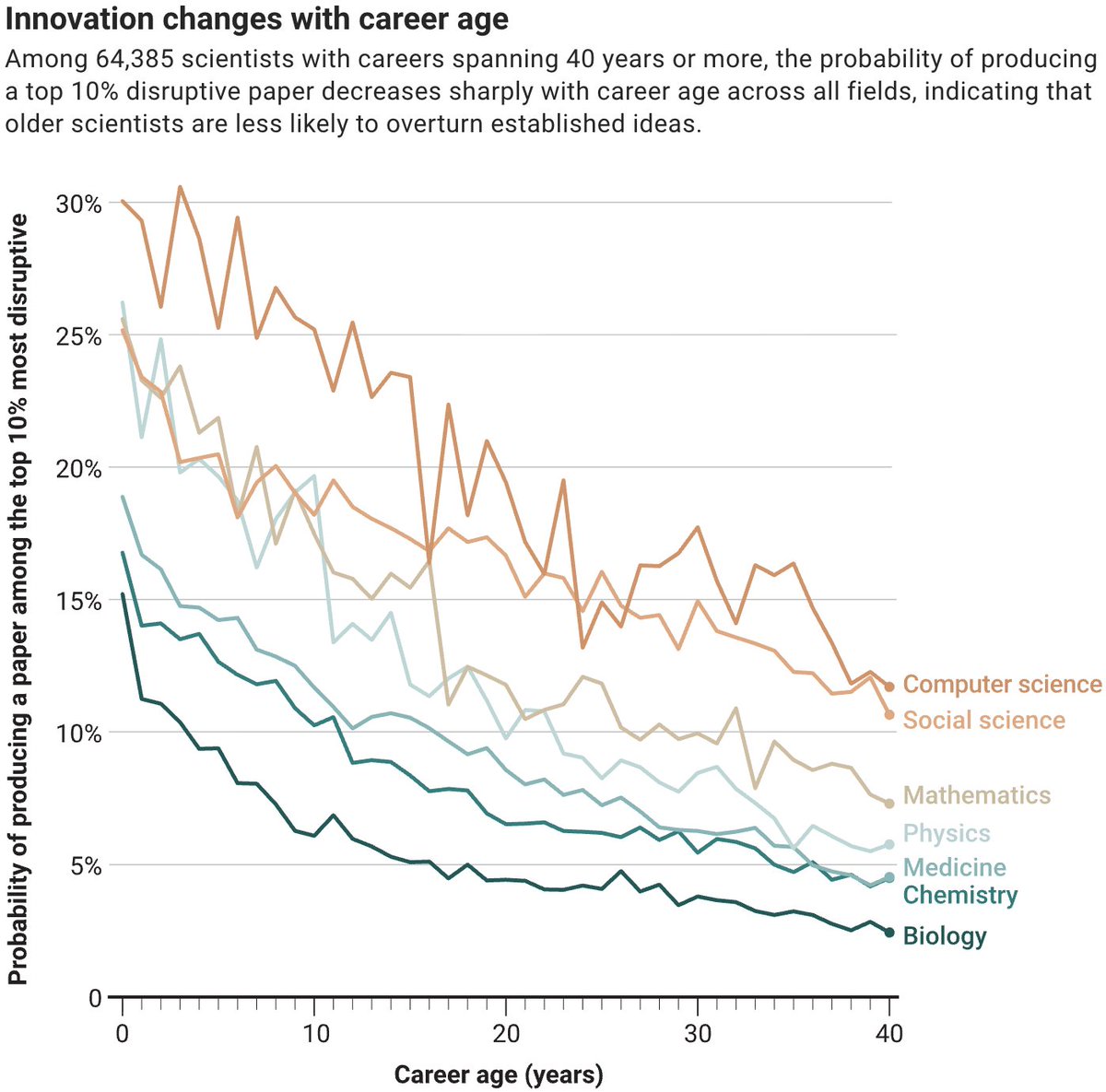
ALT Innovation changes with career age Among 64,385 scientists with careers spanning 40 years or more, the probability of producing a top 10% disruptive paper decreases sharply with career age across all fields, indicating that older scientists are less likely to overturn established ideas.
5
22
70
15,342
André M. Bastos retweeted

May 12
I’ve always believed the No.1 application of AI should be to improve human health.
That work started with AlphaFold, and now at @IsomorphicLabs with the mission to reimagine drug discovery and one day solve all disease!
We are turbocharging that goal with $2.1B in new funding.
730
2,643
21,265
3,151,689
André M. Bastos retweeted

How can you live a more meaningful life?
In his Graduates Day address to the Class of 2026, @arthurcbrooks challenged students to consider their quest for happiness. 💛🎓
4
7
33
3,140
André M. Bastos retweeted

💫Very happy to release NeuralBench, to benchmark Neuro AI models and datasets in the open!
🧵Thread, 💻Code, 📝White Paper below:

🧠 Introducing NeuralBench: a unified, open-source framework to benchmark NeuroAI models.
v1.0: 36 EEG tasks, 94 datasets, task-specific foundation models. MEG/fMRI ready.
MIT-licensed, FAIR's Brain & AI @AIatMeta.
Code: github.com/facebookresearch/…
Paper: ai.meta.com/research/publica…
4
23
159
41,889
André M. Bastos retweeted

Does the brain really know what word is coming next?
elifesciences.org/articles/1…
1
17
62
6,850
André M. Bastos retweeted

The deadline for the Neurobiology of Cognition Gordon Conference is coming soon. We have an awesome lineup of speakers. We will begin assigning fellowships in mid May, so don't delay, apply now! Spread the word! 🧪 🧠 #neuroscience #cognition grc.org/neurobiology-of-cogn…

8
47
3,894
André M. Bastos retweeted

Apr 30
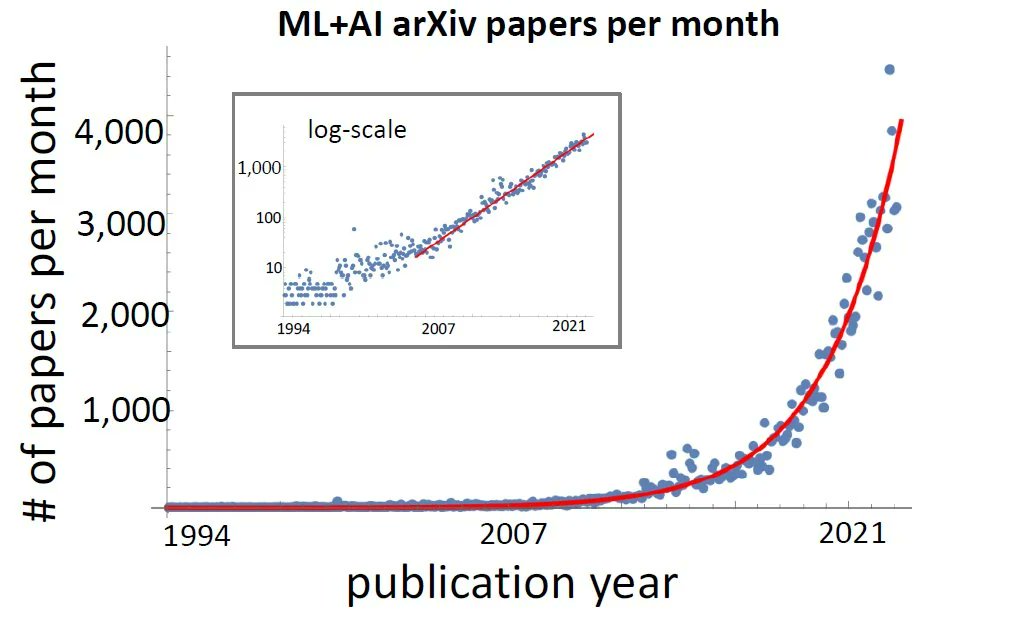
2/ Millions of papers a year, growing faster every year. Most aren't reproducible. Peer review is buckling. And every paper is a lossy compression of the work behind it — months of dead ends, judgment calls, and configuration tricks flattened into a clean story. The format was designed for a world where every reader was human. That world is ending.
1
12
99
8,521
André M. Bastos retweeted

Apr 29
Preprint alert! We've done the first ever wireless brain recordings from the high-level visual & motor regions (IT/PMv/PFC) in monkeys engaged in natural behaviors as well as during controlled screen-based tasks. Read below for a lay summary and the link for details! 1/8

2
22
99
5,733
André M. Bastos retweeted

Apr 16
This paper from Harvard and MIT quietly answers the most important AI question nobody benchmarks properly:
Can LLMs actually discover science, or are they just good at talking about it?
The paper is called “Evaluating Large Language Models in Scientific Discovery”, and instead of asking models trivia questions, it tests something much harder:
Can models form hypotheses, design experiments, interpret results, and update beliefs like real scientists?
Here’s what the authors did differently 👇
• They evaluate LLMs across the full discovery loop hypothesis → experiment → observation → revision
• Tasks span biology, chemistry, and physics, not toy puzzles
• Models must work with incomplete data, noisy results, and false leads
• Success is measured by scientific progress, not fluency or confidence
What they found is sobering.
LLMs are decent at suggesting hypotheses, but brittle at everything that follows.
✓ They overfit to surface patterns
✓ They struggle to abandon bad hypotheses even when evidence contradicts them
✓ They confuse correlation for causation
✓ They hallucinate explanations when experiments fail
✓ They optimize for plausibility, not truth
Most striking result:
`High benchmark scores do not correlate with scientific discovery ability.`
Some top models that dominate standard reasoning tests completely fail when forced to run iterative experiments and update theories.
Why this matters:
Real science is not one-shot reasoning.
It’s feedback, failure, revision, and restraint.
LLMs today:
• Talk like scientists
• Write like scientists
• But don’t think like scientists yet
The paper’s core takeaway:
Scientific intelligence is not language intelligence.
It requires memory, hypothesis tracking, causal reasoning, and the ability to say “I was wrong.”
Until models can reliably do that, claims about “AI scientists” are mostly premature.
This paper doesn’t hype AI. It defines the gap we still need to close.
And that’s exactly why it’s important.

88
216
563
39,750
Apr 17
It's a wonderful project to be a part of and will be transformative for our understanding of predictive coding in the brain. When we put our brains together, amazing new ideas are born. Thank you for your leadership in such an open and inclusive way, @LecoqJerome
Apr 15

Exactly one year later after sharing this gigantic review with the world arxiv.org/abs/2504.09614, we just shared 56TB of data with the world: Entirely new experiments described in the review. And more is coming...
12
1,241
Apr 10
Cool science on how human neurons respond to imagination vs visual perception.
Apr 9

1/8 Our preprint is now a peer-reviewed paper :) Big thanks to our reviewers who pushed us to examine our results more carefully and Olivier Wyart (headquarter.paris/) for the exquisite visual. science.org/doi/10.1126/scie…

1
338
André M. Bastos retweeted

Apr 9
1/8 Our preprint is now a peer-reviewed paper :) Big thanks to our reviewers who pushed us to examine our results more carefully and Olivier Wyart (headquarter.paris/) for the exquisite visual. science.org/doi/10.1126/scie…
3
39
136
49,820