
Joined October 2021
- Tweets 346
- Following 239
- Followers 277
- Likes 778
71 Photos and videos







Pinned Tweet

May 28
New blog post on @huggingface!
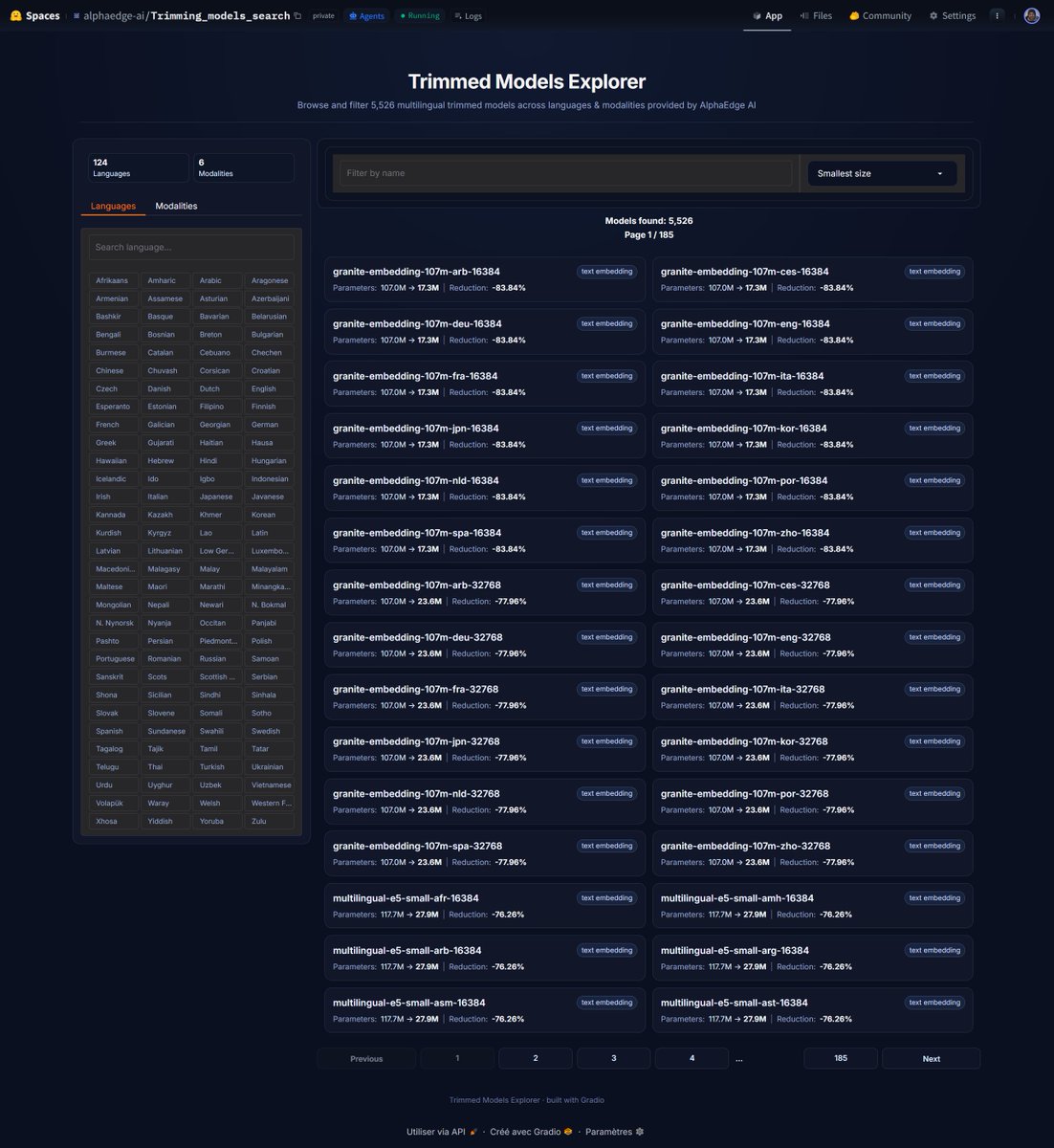
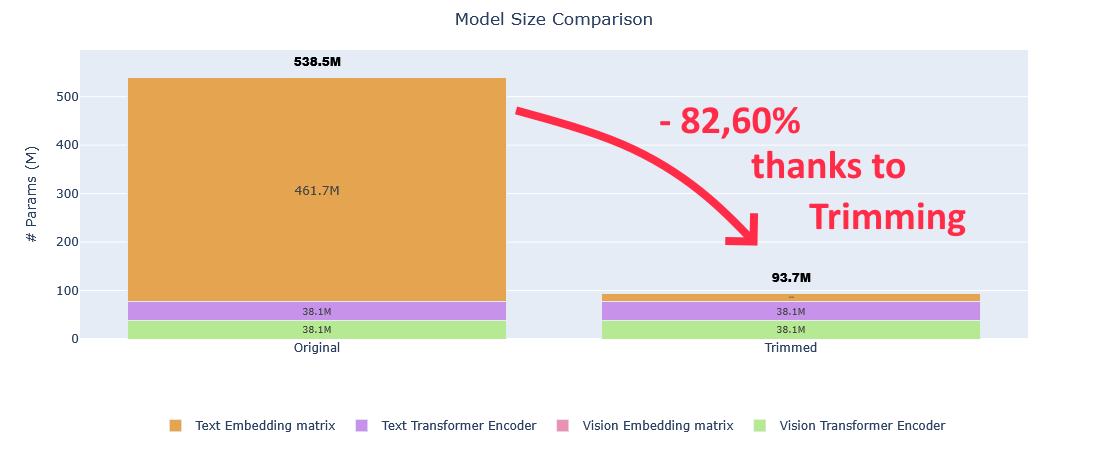
An introdution to Trimming ✂️ a little-known but highly effective model reduction method. We achieved up to 87.24% size reduction while preserving performance 🧵
1
3
9
360
May 28
New blog post on @huggingface!
An introdution to Trimming ✂️ a little-known but highly effective model reduction method. We achieved up to 87.24% size reduction while preserving performance 🧵
1
3
9
360
May 28
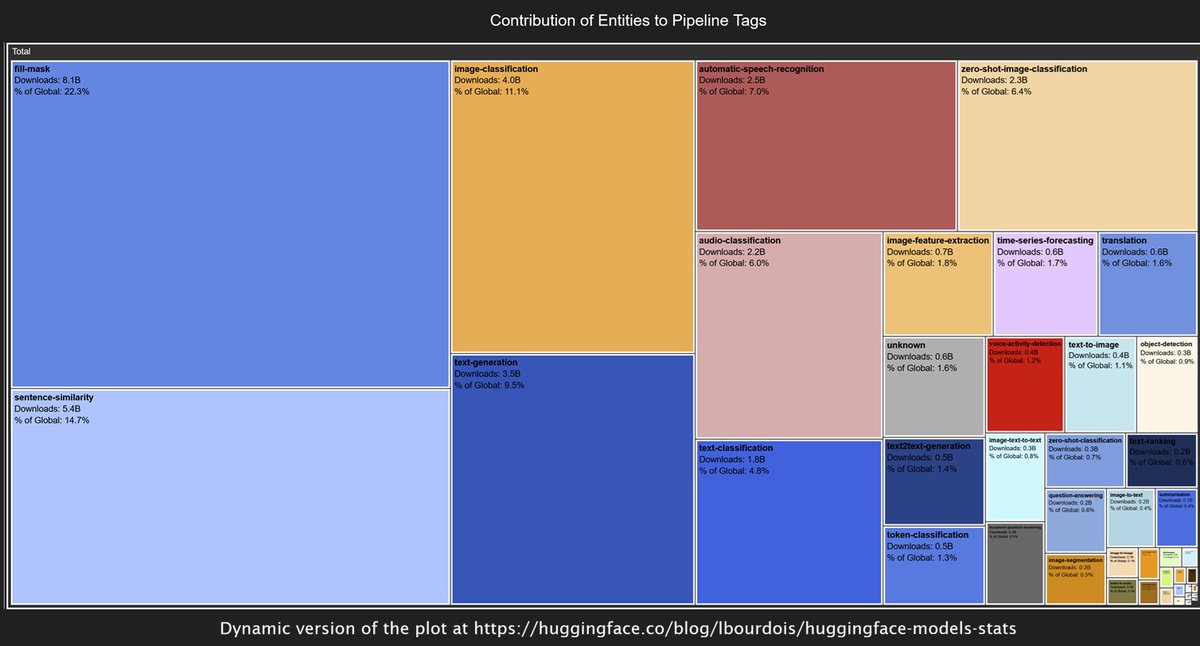
From these 16 families, we generated more than 5,500 monolingual models in 124 different languages.
1
2
81
May 28
Big thanks to my HF Fellows bros for multilingual evaluation @tomaarsen, Bram Vanroy, @christopher, @w00jun_ @mrm8488, @prithivMLmods and to @AI_AlphaEdge for the time dedicated to this project 🙏
Links 👇
Blogpost: huggingface.co/blog/lbourdoi…
Models: huggingface.co/spaces/alphae…
2
4
365
Loïck BOURDOIS retweeted

May 18
Introducing a revival of PapersWithCode!
As @ilyasut said, we're back to the "age of research".
Hence, it's important to share research and build on each other's work.
> find SOTA per domain, not just LLMs
> leaderboards
> methods
> all parsed at scale using AI agents.
34
91
610
78,923
Loïck BOURDOIS retweeted

Apr 9
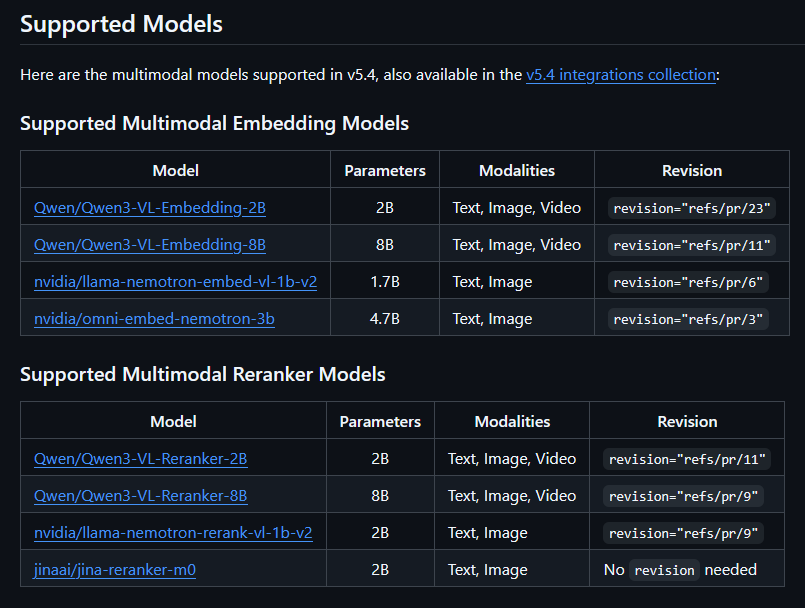
🌐 I've just released Sentence Transformers v5.4: we're going fully multimodal for embeddings & reranking!
Also featuring a modular CrossEncoder, and automatic Flash Attention 2 input flattening.
Highlights in 🧵
19
31
174
29,003
Loïck BOURDOIS retweeted

Apr 3
著者です!
Attentionの「相対比較しかできない」という制約を外した、新しい機構を提案しました
①まずわかりやすい利点
✅学習時より圧倒的に長い文でも性能維持&正確な情報取得
✅収束が非常に高速(LR=1でも学習可能)
✅モデルサイズ4割削減
✅推論速度3倍超
(続く)
arxiv.org/abs/2604.01178

15
133
804
87,631
Mar 2
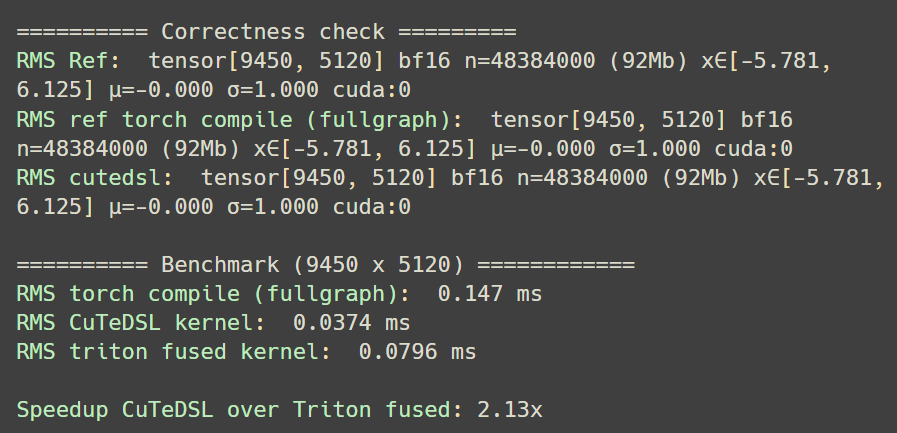
CuTeDSL is really nice
For those wishing to get into writing kernels in this language, github.com/b-albar/machete can be useful
Boris ALBAR reimplemented Flash Attention, RoPE, RMSnorm, etc.
Everything compatible with HF Transformers (tests on llama3, GLM4.7, Qwen3), TRL, PEFT/LoRA
Mar 1

CuTeDSL is my new favourite thing: I wrote a kernel for RMS norm after learning about layouts, tiling, copying tensors, reductions and so on, especially for inference and it is about 2.13x faster than a triton fused kernel for the given shape.
1
167
Loïck BOURDOIS retweeted

Feb 4
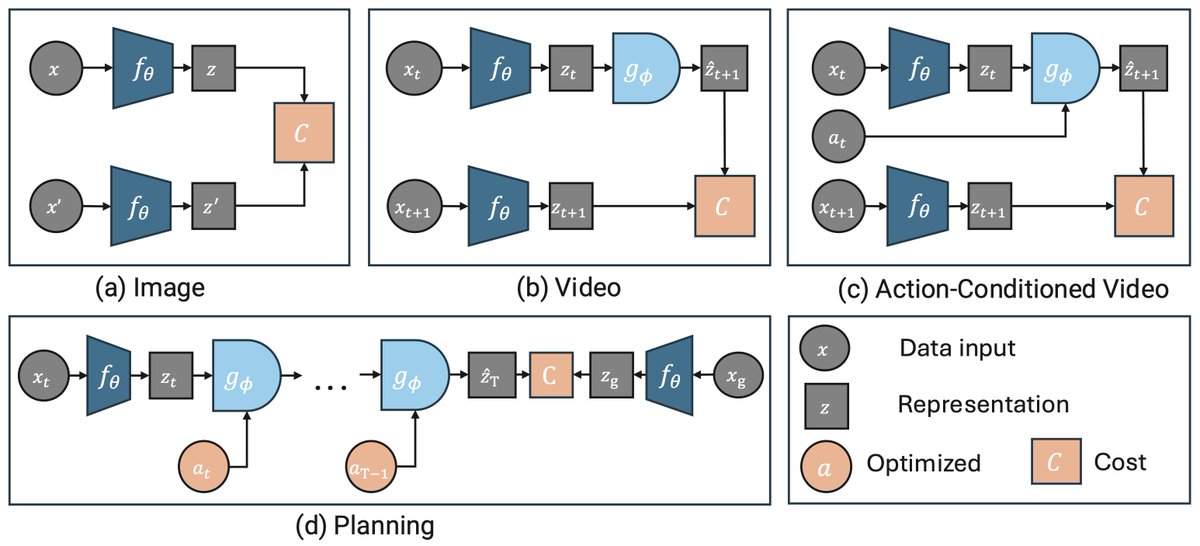
𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗘𝗕-𝗝𝗘𝗣𝗔 ⚡
An open-source library making JEPAs accessible, trainable on a single GPU in hours! 🚀
🔗 Paper: arxiv.org/abs/2602.03604
💻 Code: github.com/facebookresearch/…
13
96
657
92,184
Loïck BOURDOIS retweeted

5 Nov 2025
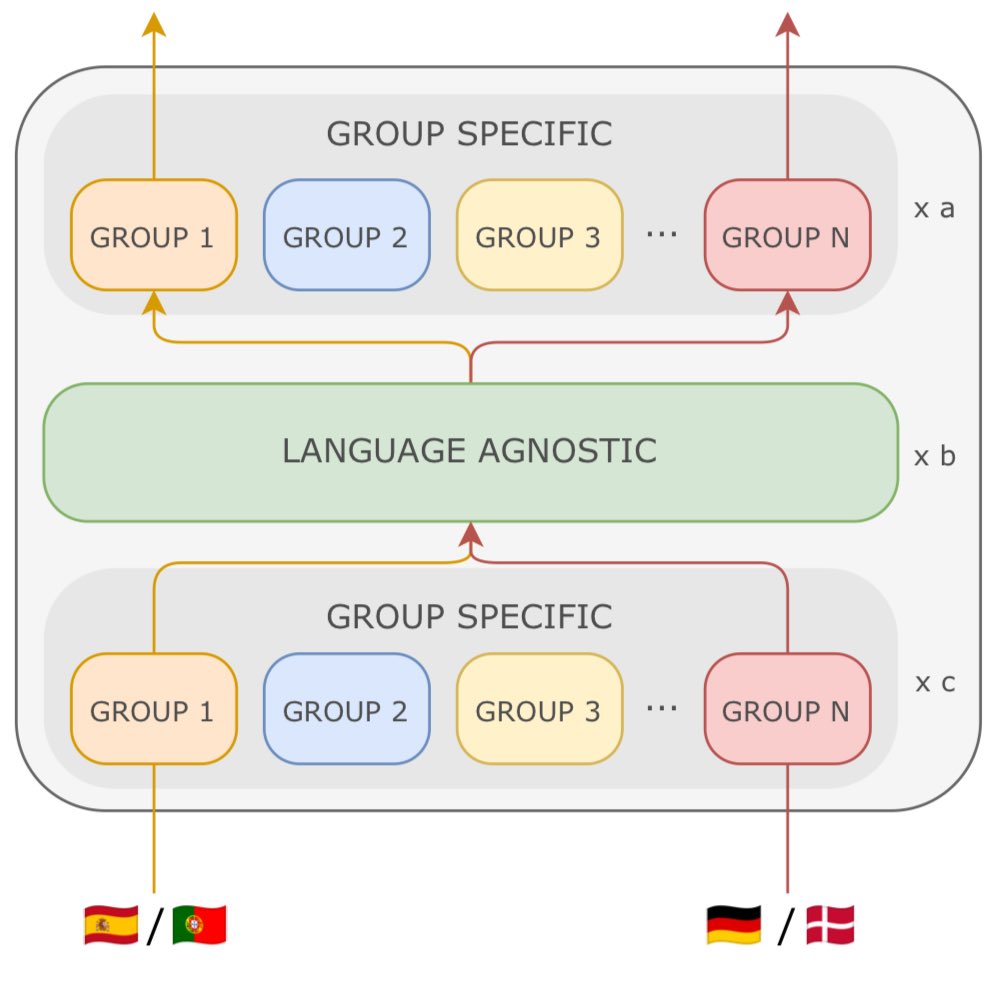
🚨New Paper @AIatMeta 🚨
You want to train a largely multilingual model, but languages keep interfering and you can’t boost performance? Using a dense model is suboptimal when mixing many languages, so what can you do?
You can use our new architecture Mixture of Languages!
🧵1/n
3
11
22
2,009
Loïck BOURDOIS retweeted

30 Oct 2025
We've just published the Smol Training Playbook: a distillation of hard earned knowledge to share exactly what it takes to train SOTA LLMs ⚡️
Featuring our protagonist SmolLM3, we cover:
🧭 Strategy on whether to train your own LLM and burn all your VC money
🪨 Pretraining, aka turning a mountain of text into a fancy auto-completer
🗿How to sculpt base models with post-training alchemy
🛠️ The underlying infra and how to debug your way out of NCCL purgatory
Highlights from the post-training chapter in the thread 👇

22
91
491
142,768
Loïck BOURDOIS retweeted

28 Oct 2025
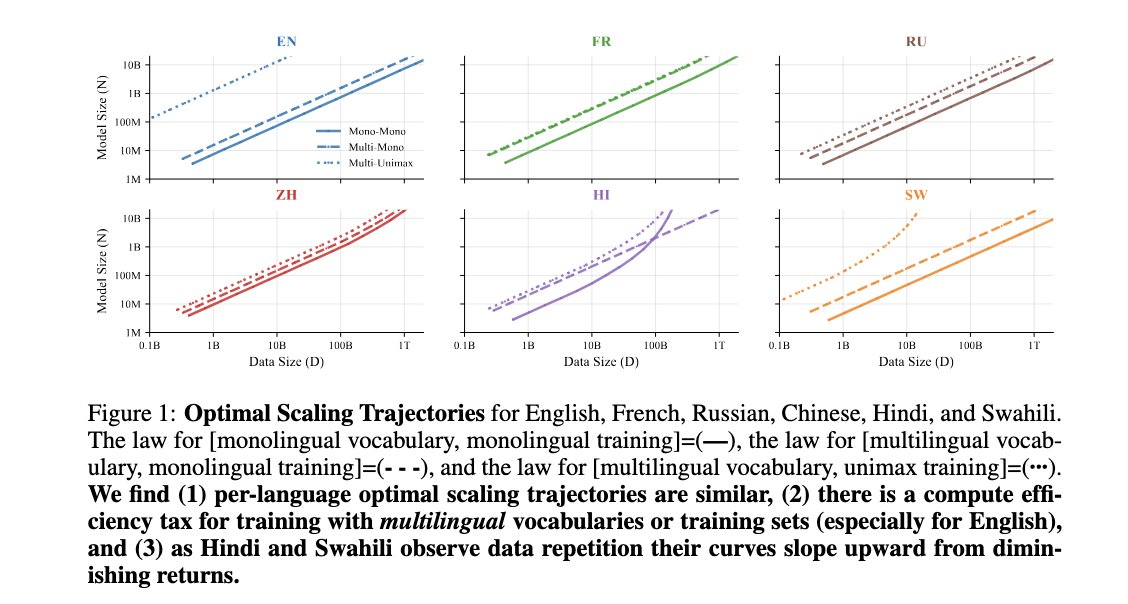
📢Thrilled to introduce ATLAS 🗺️: scaling laws beyond English, for pretraining, finetuning, and the curse of multilinguality.
The largest public, multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400 languages) to answer:
🌍Are scaling laws different by language?
🧙♂️Can we model the curse of multilinguality?
⚖️Pretrain from scratch or finetune from multilingual checkpoint?
🔀Cross-lingual transfer scores for 1444 lang pairs?
1/🧵

7
42
154
24,634
Loïck BOURDOIS retweeted
22 Oct 2025
🤗 Sentence Transformers is joining @huggingface! 🤗
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵

24
46
375
41,519