
Computer Vision • Multimodal AI • @huggingface Fellow ML🤗 • Computational Intelligence • Diffusion-Driven Adapters • hf.co/prithivMLmods
Joined October 2022
- Tweets 7,565
- Following 778
- Followers 570
- Likes 13,514
277 Photos and videos
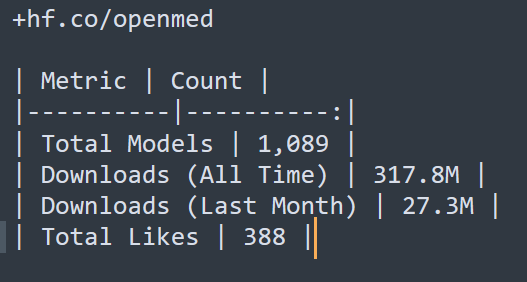



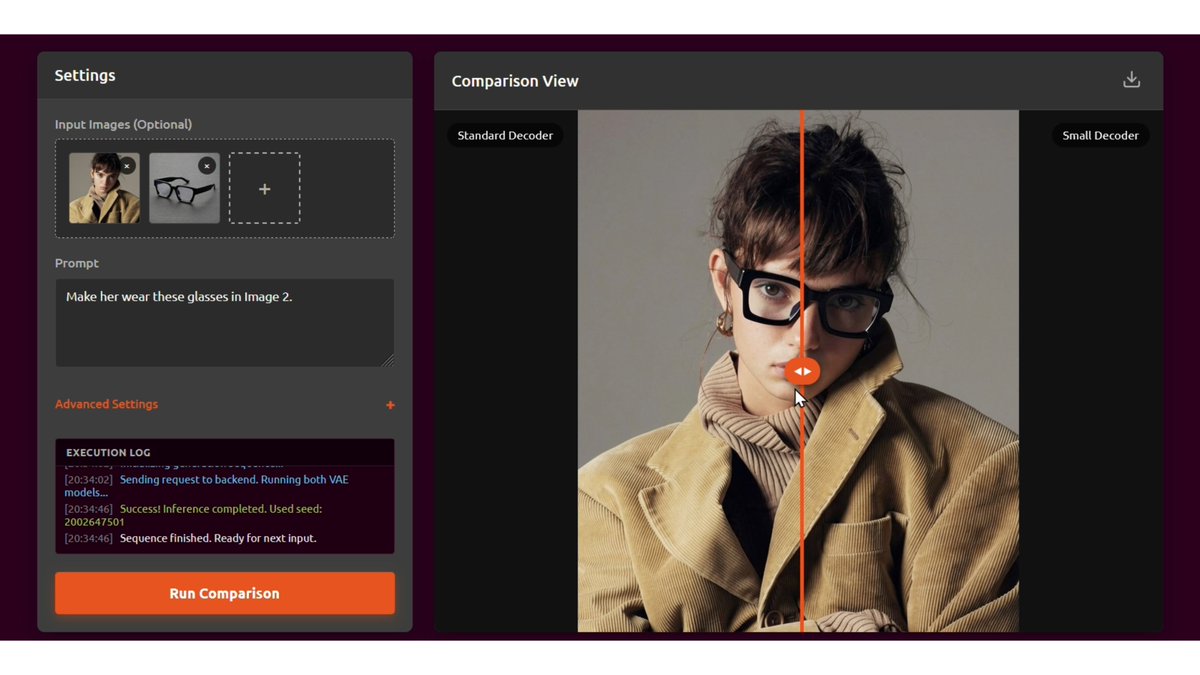




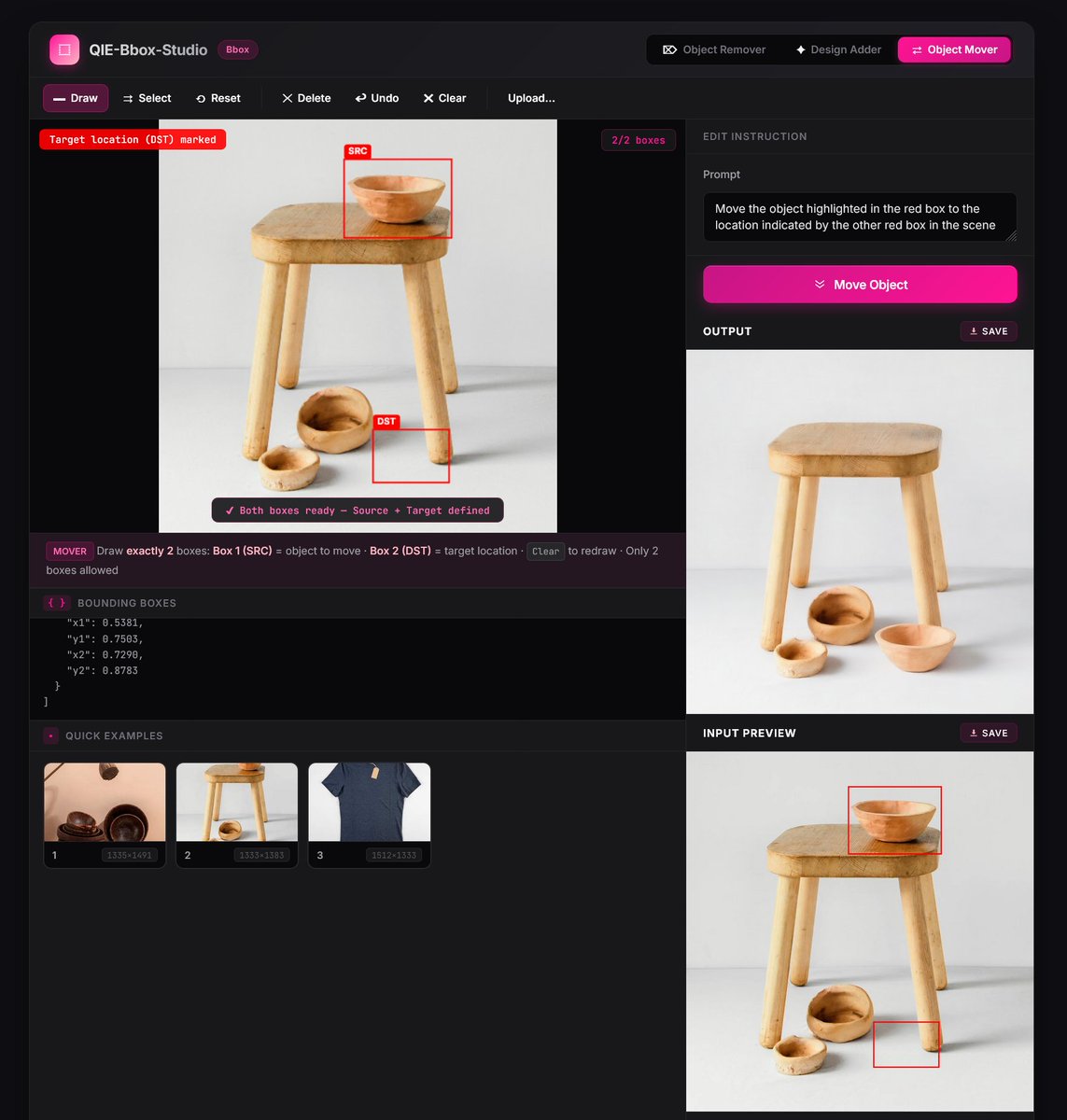


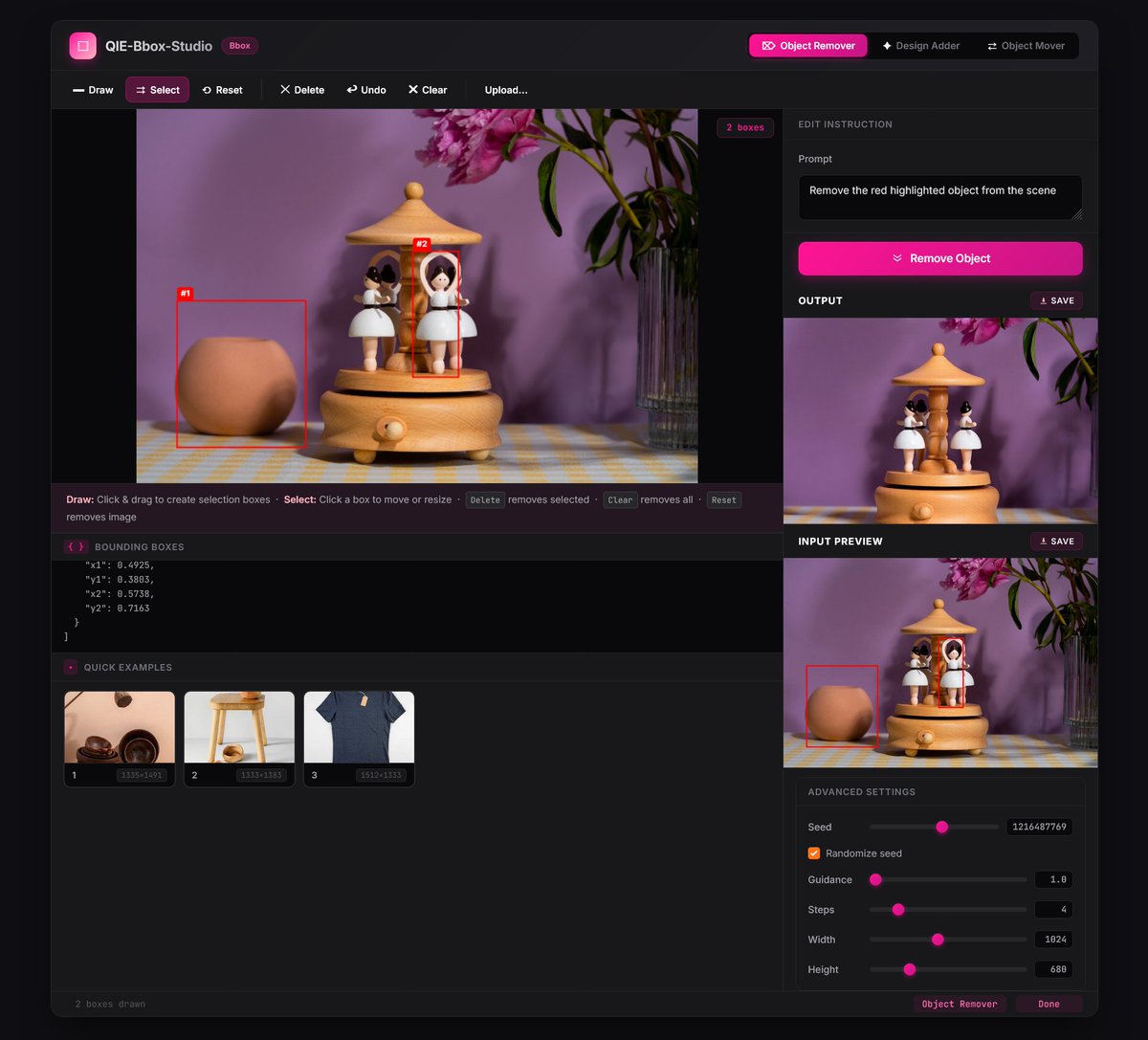


Pinned Tweet

Feb 27
Qwen3-VL-Video-Grounding Demo. Perform point tracking, text-guided detection, and video question answering, all powered by the Qwen3-VL-4B vision-language model with real-time bounding box detection and cross-frame object matching. 🤗 @huggingface Demo in 🧵
4
66
475
50,279
Prithiv Sakthi retweeted

Jun 14
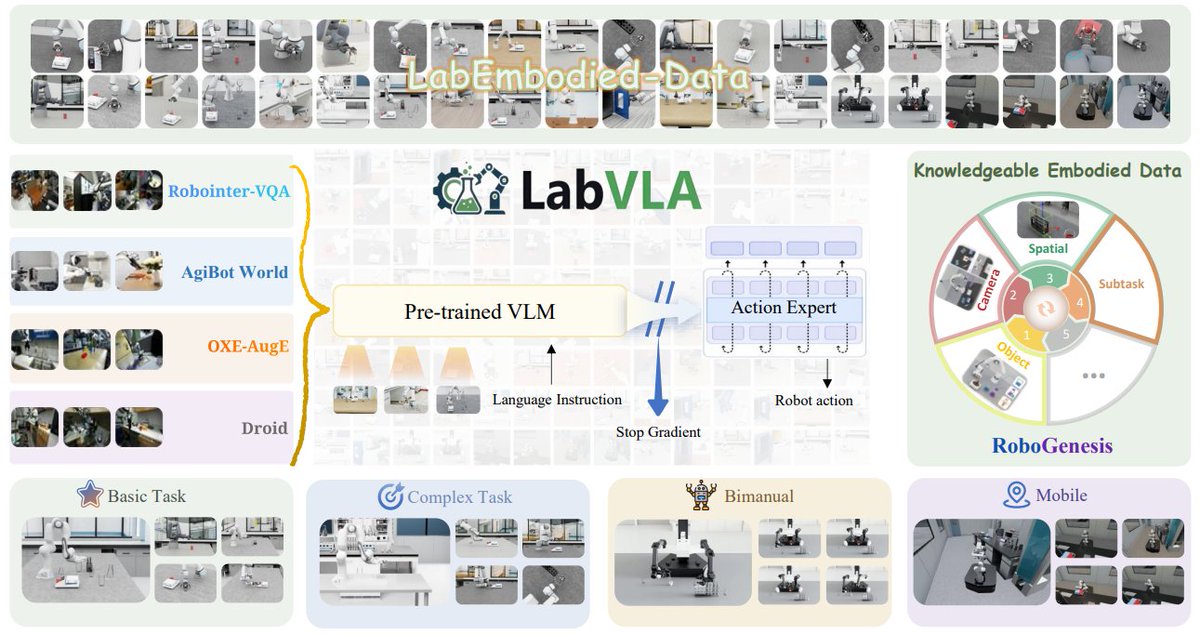
LabVLA: Grounding VLA models in scientific laboratories
RoboGenesis builds 10K lab scenes across 16 robot types. LabVLA pairs a Qwen3-VL backbone with a DiT flow-matching expert, reaching 71.1% success on LabUtopia and transferring to real Franka robots.
1
17
84
3,779
Prithiv Sakthi retweeted
Jun 14
SpatialWorld
A new benchmark pushing multimodal agents to navigate, manipulate, and reason in physical 3D spaces.
760 tasks across 8 simulators reveal even GPT-5 only succeeds 17% of the time.

3
9
59
3,152
Jun 13
^EVERYDAY
Jun 13

run local models TODAY
1
41
Prithiv Sakthi retweeted

Jun 12
new transformers tutorials just dropped for vision 🔥
🛰️ segmentation on satellite imagery: fine-tune RF-DETR-Seg segment buildings
📱 object detection on mobile UI: fine-tune RF-DETR on screenshots
runs on toaster, converges fast, give to your agent for your use cases🫡
8
34
189
16,686
Prithiv Sakthi retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


618
1,639
13,708
2,100,673
Prithiv Sakthi retweeted

Jun 10
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
169
810
5,025
921,821
Prithiv Sakthi retweeted

Jun 9
🚀 Excited to share Mirage: latent spatial memory for video world models.
No RGB point-cloud render-and-encode loop. No pixel-space detour.
Just store 3D memory directly in latent space.
⚡ Up to 10.57x faster generation and 55x smaller 3D cache. 🧵
🌐 aka.ms/latent-spatial-memory
13
55
510
80,383
Prithiv Sakthi retweeted
Jun 9
SpatialWorld reveals how poorly multimodal agents reason in 3D space
760 human-annotated tasks across 8 simulators, from kitchens to city streets.
Even GPT-5 only solves 17.4% of them.

3
9
39
2,981
Prithiv Sakthi retweeted

Jun 8
llama.cpp just added video input support 👀
You can now enjoy Gemma 4 video understanding capabilities in your chat completions endpoint and via mtmd-cli
github.com/ggml-org/llama.cp…
22
44
399
17,615
Prithiv Sakthi retweeted
Jun 7
Gemma 4 MTP just got officially merged into llama.cpp
This means you can use Gemma 4 QAT MTP for a lightweight super fast setup. Excited to see what the community builds with it
github.com/ggml-org/llama.cp…
57
130
1,229
93,565
RT @harbhajan_singh: Sad no Rajat Patidar in the indian squad. What else he needs to do ? Scored 501 runs strike rate almost 200 . Unfair 💔…
3,972
Prithiv Sakthi retweeted
Jun 5
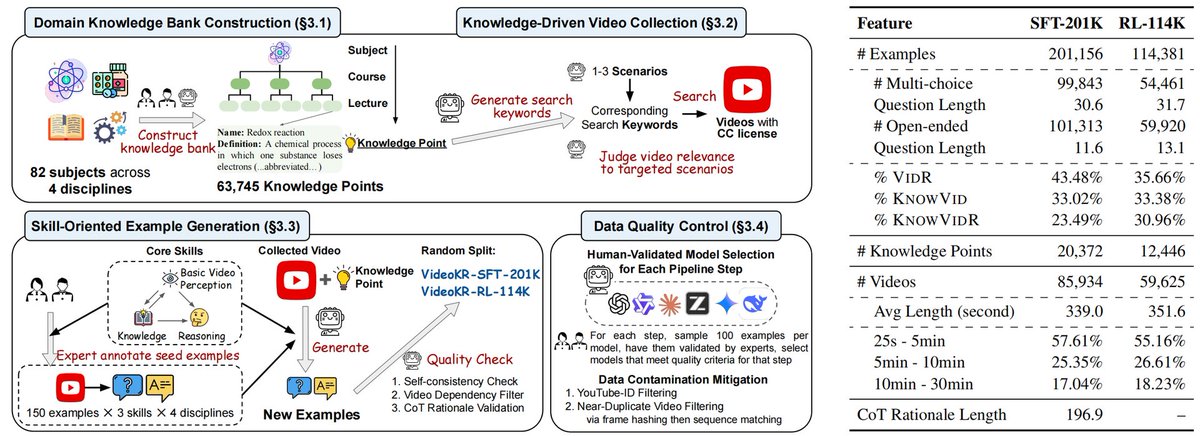
VideoKR: The first dataset for knowledge- and reasoning-intensive video understanding
It curates 315K examples over 145K expert-domain videos with human-in-the-loop generation.
The VideoKR-Eval benchmark forces models to perform genuine visual reasoning rather than relying on textual shortcuts.
1
8
39
2,189

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
199
461
3,483
1,242,806
Prithiv Sakthi retweeted
Jun 2
Model:
huggingface.co/nvidia/4D-RGP…
Paper page:
huggingface.co/papers/2512.1…
1
2
12
982
Prithiv Sakthi retweeted

Jun 1
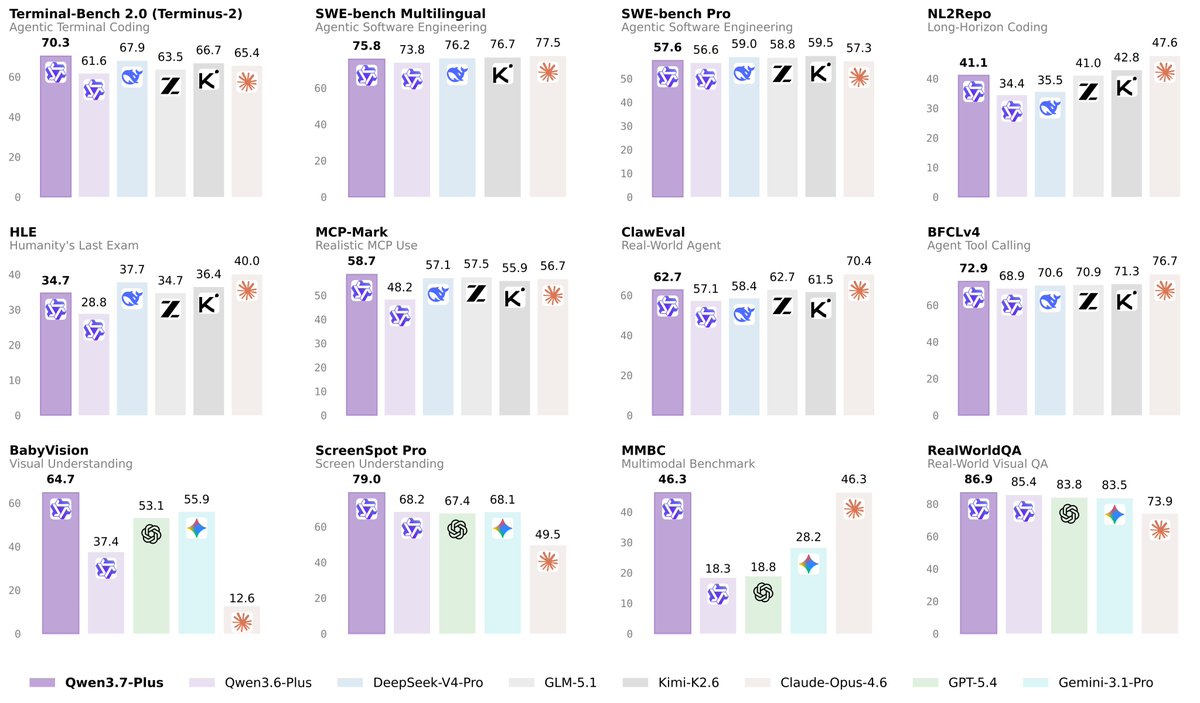
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:qwen.ai/blog?id=qwen3.7-plus
Qwen Studio:chat.qwen.ai/?models=qwen3.7…
API:modelstudio.console.alibabac…
271
457
3,951
489,760
Open Source — Qwhen? 👀
Jun 1

👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:qwen.ai/blog?id=qwen3.7-plus
Qwen Studio:chat.qwen.ai/?models=qwen3.7…
API:modelstudio.console.alibabac…
1
67
Prithiv Sakthi retweeted

Jun 1
We asked ourselves a question last year- can we go back to back?
Here we are again 🏆🏆❤️❤️
@RCBTweets




3,971
29,970
216,732
2,835,678


Prithiv Sakthi retweeted

May 28
Big thanks to my HF Fellows bros for multilingual evaluation @tomaarsen, Bram Vanroy, @christopher, @w00jun_ @mrm8488, @prithivMLmods and to @AI_AlphaEdge for the time dedicated to this project 🙏
Links 👇
Blogpost: huggingface.co/blog/lbourdoi…
Models: huggingface.co/spaces/alphae…
2
4
364