
Biotechnologist & Biostatistician. I try to convert coffee into code and ideas for uncovering biological mysteries. PhD student @FraticelliLab @IRBBarcelona
Joined May 2017
- Tweets 2,890
- Following 3,070
- Followers 744
- Likes 12,669
82 Photos and videos












Peter retweeted

May 5
The day a blind man sees. The first thing he throws away is the stick that has helped him all his life
655
4,353
60,032
2,587,701
Peter retweeted

Apr 30
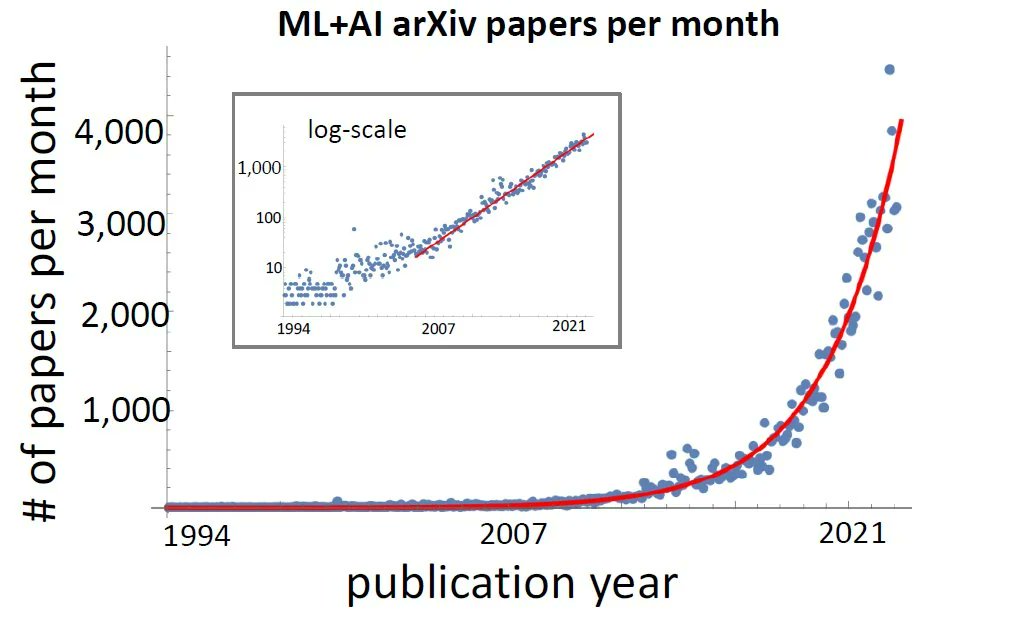
2/ Millions of papers a year, growing faster every year. Most aren't reproducible. Peer review is buckling. And every paper is a lossy compression of the work behind it — months of dead ends, judgment calls, and configuration tricks flattened into a clean story. The format was designed for a world where every reader was human. That world is ending.
1
12
99
8,523
Peter retweeted

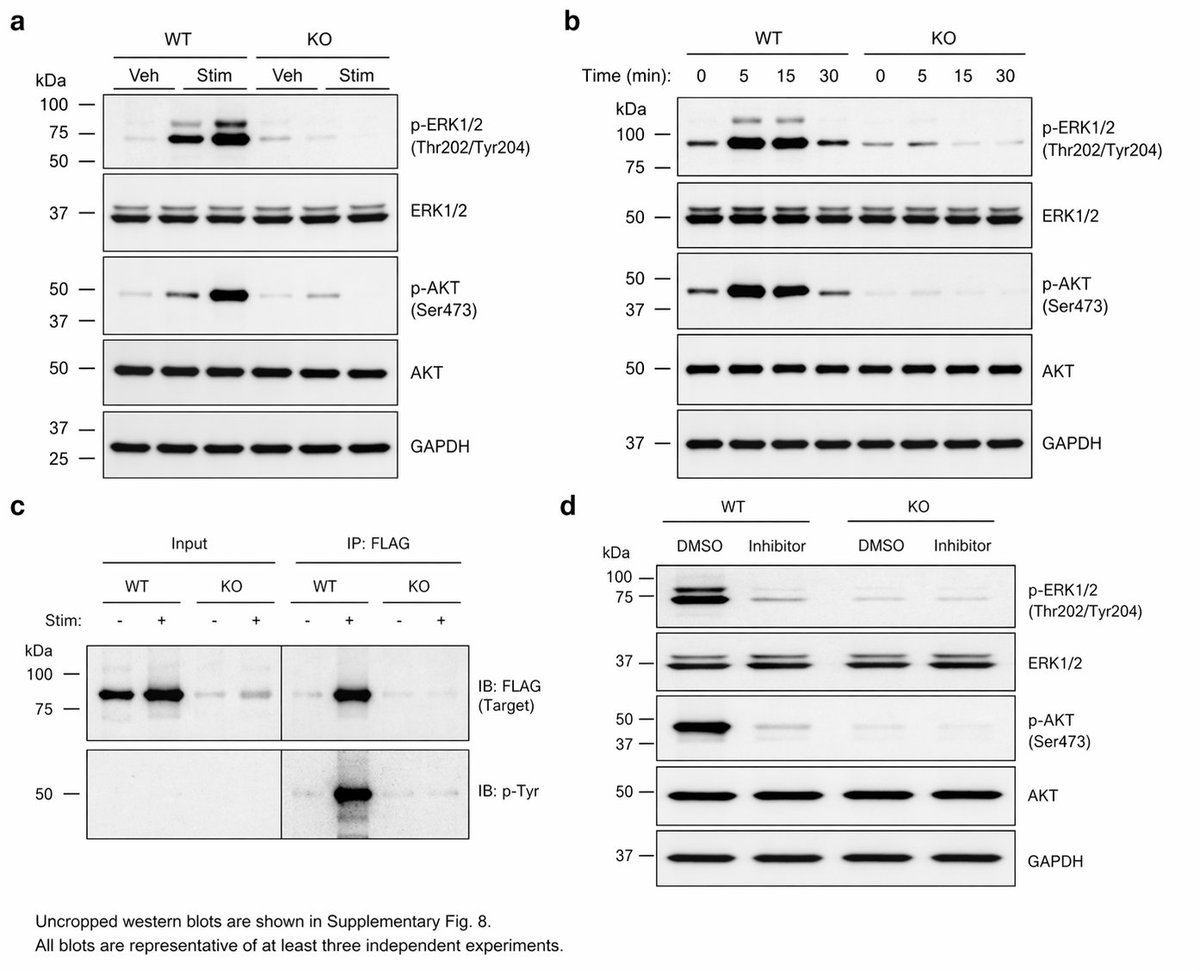
I knew this was coming. We are so f*cked - fake and real now look the same.
We desperately need tools to show journals and researchers that data is real, not AI-generated.
Apr 23

⚠️All of the below images were FABRICATED by ChatGPT Images 2.0, each with a single prompt❗️ ⚠️
65
246
1,008
126,415
Peter retweeted

Apr 17
I’m looking for an automated way to read others’s scientific data without giving credit or acknowledgement, and also claim full credit for insights from it. And I want it to have a fitting name
OAI: say no more

Introducing GPT-Rosalind, our frontier reasoning model built to support research across biology, drug discovery, and translational medicine.
10
63
518
47,008
Peter retweeted

Apr 17
Yes we're all too busy publishing our own papers & hyping our own science but it really is our responsibility to also be part of the push and pull that is necessary to have a robust self correcting enterprise. 3/3
1
32
3,526
Peter retweeted
Apr 15
I'm actually not sure whether (1) EVO2 is the problem (2) training on ClinVAR is the problem (3) the predictor threshold is very poorly calibrated (this is one of the hardest things). Or all three.
1
5
22
2,472
Peter retweeted

Apr 14
Not cool at all. My colleagues and I checked several well-known pathogenic variants, and they were predicted as VUS. Certain variants are simply missing (e.g, there is no information for rs879254374).
I like the idea, I don’t see any reason to use Evo2. Garbage in, garbage out.
Apr 14

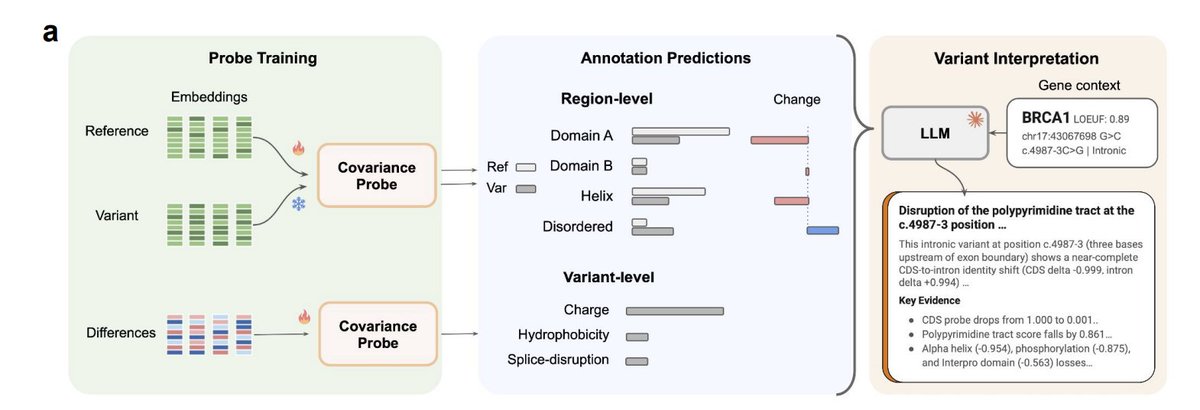
very cool work. more dna language model pilled than i was an hour ago
when i wrote my Evo 2 article a long time ago (owlposting.com/p/a-socratic-…) the question was always 'how do you interpret the outputs of these models if it just spits out log-likelihoods?'
and increasingly the answer is 'use probes to annotate embeddings, and ask the LLMs to interpret those'. in feb 2025, when i wrote my article, i didnt really trust the models to do that well. now i do, and perhaps there is an immense amount of greenspace for really crazy things to be done
but one of the big failure modes of LLM-for-science approaches is that the models try really hard to be consistent with the data instead of reality. theres no experimental validation here, so who knows whether that's happening here
id be extremely curious for someone to cross-reference the annotated VUS's here with, e.g. the UK Biobank 500k~ exomes with linked phenotype data. maybe Claude one-shot human variant function annotation, or maybe the annotations are slop, or maybe its in between
6
16
111
27,086
Peter retweeted

Apr 13
Very excited to announce that the #BayesianWorkflow book by @StatModeling, @avehtari, @rlmcelreath et al publishes in June! routledge.com/9780367490140 #RStats #DataScience #Bayesian @mcmc_stan

7
42
192
18,408
Peter retweeted
Mar 29
AI for bio teams in academia & industry have been playing "offense" pumping out billion parameter models every other week that are worth less than a paper weight. How can anyone claim that the field needs "more offense" & less "rigor", when it requires literally the opposite?!?

This applies to academic labs too — maybe more than anywhere.
Defense in academia looks like rigor: protect your niche, optimize your pipeline, wait for the field to settle. It isn't rigor. It's just slower irrelevance.
The labs that matter in five years aren't asking "how do we use AI to do our old experiments faster." They're asking "what questions are now askable that weren't before?"
That's the offensive posture. And academics have something founders don't — the freedom to chase questions with no obvious payoff. That's an enormous edge, if you use it.
3
16
159
16,363
Peter retweeted

Epigenetics is not a bystander in cancer. It links life’s exposures to disease risk.
It’s time to bring DNA methylation into the clinic for risk prediction.
x.com/Aiims1742/status/20377…
Mar 28

Multiple recent papers (two just this week) highlighting the role of inflammation in sculpting “epigenetic memory” and promoting tumorigenesis across various solid organs.
science.org/doi/10.1126/scie…
nature.com/articles/s41586-0…
science.org/doi/10.1126/scie…
cell.com/developmental-cell/…




1
37
209
43,402
Peter retweeted

I was so pleased to be part of a great team writing a commentary on the draft FDA guidelines on Bayesian clinical trial designs. Should have been done 30 years ago, but better late than never
Mar 23

💬 Perspective: Bayesian methodology supports efficient, flexible clinical trial designs; FDA guidance encourages prespecification and sensitivity analysis of priors.
@f2harrell @d_spiegel
ja.ma/47hHTyb

4
76
292
48,304
Peter retweeted
Mar 21
This argument, that what’s ultimately right and better may not appear to be the best solution now, is the best rebuttal I’ve heard to the current fervor for translational and applied research over basic science
Mar 20

When Copernicus proposed heliocentrism in 1543, it was actually less accurate than Ptolemy's geocentric model - a system refined over 1,400 years with epicycles precisely tuned to match observed planetary positions.
It took another 70 years before Kepler, working from Tycho Brahe's unprecedentedly precise observations, replaced Copernicus’s circles with ellipses - finally making heliocentrism empirically superior.
Terence Tao's point is that science needs a high temperature setting. If we only fund and follow what's most state of the art today, we kill the ideas that might need decades of work to surpass some overall plateau.
12
27
233
25,449
Peter retweeted
Mar 21
Honestly feel kinda sad to see so many young scientists adopting and idolizing ultra hype culture. I think people don't really understand the medium and long term consequences to their own credibility and that of science as a whole.
22
39
551
66,203
Peter retweeted

Feb 18
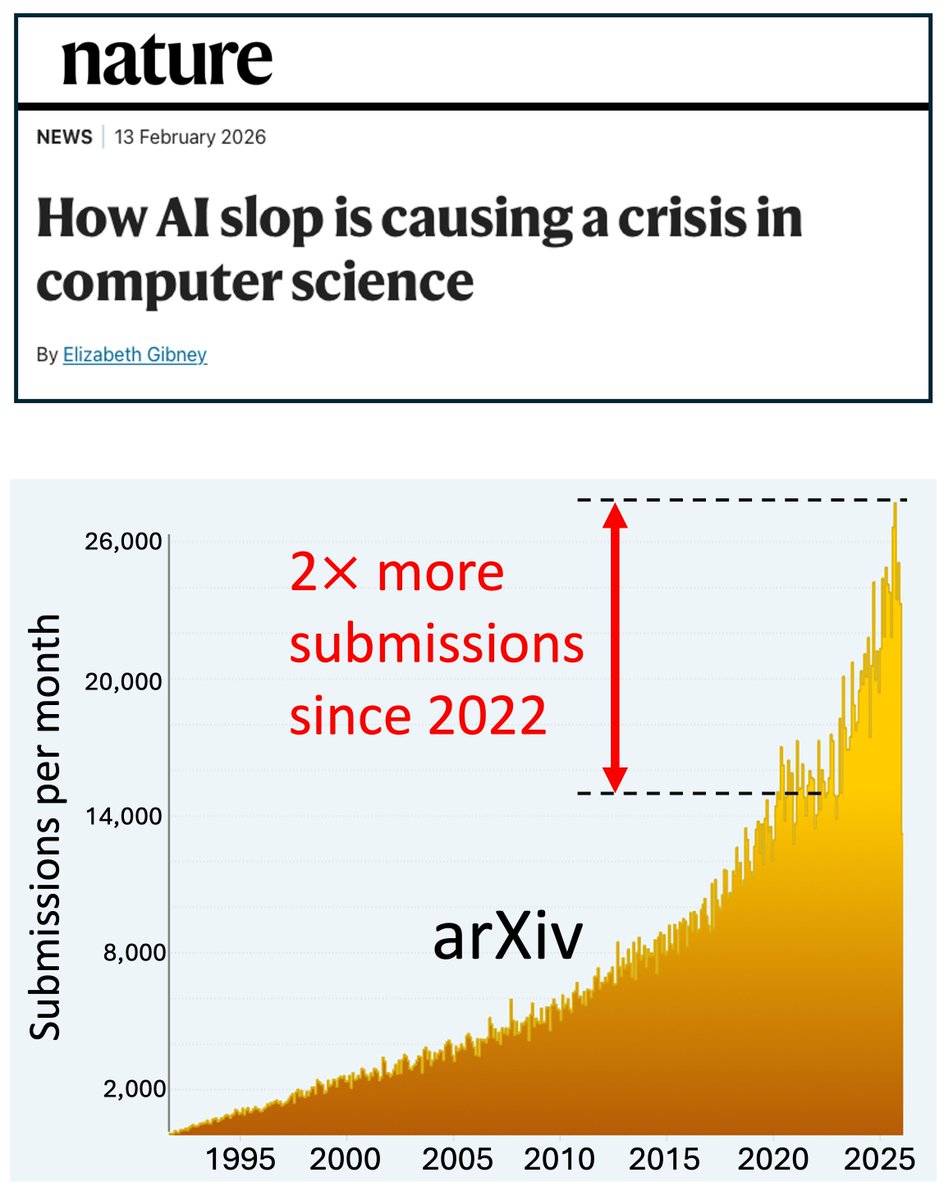
A really dangerous situation. Too many submissions. Too many generated papers. Little responsibility.
1. In 2026, more than 24,000 submissions were made to the International Conference on Machine Learning (ICML). It’s TWO times more than in 2025. To fight it, the organizers now require researchers to pay $100 for every subsequent paper.
2. LLM adoption has increased researcher productivity by 90% (there’s a recent paper in Science).
3. The number of papers is becoming far too high. Submissions to arXiv have risen by 50% since 2022.
4. There are simply not enough reviewers. Plus, many scientists no longer want to invest precious time in it for free.
5. We can’t easily identify AI-made papers from the genuine ones.
__
Important words from Paul Ginsparg, a co-founder of arXiv:
“AI slop frequently can’t be discriminated just by looking at abstract, or even by just skimming full text. This makes it an “existential threat” to the system.”
Basically, we’re getting closer to the tipping point.
📍 Many professors blame the AI.
But the problem is likely elsewhere:
1. Without a sufficient number of papers, many PIs can’t get funded. They have to prove their credibility to reviewers. Their proposals have to rely on prior publications. In many countries, there are some informal (or even formal) expectations for how many papers a group with a certain size has to publish to survive (funding-wise).
2. Our students / postdocs need papers if they want to be hired in faculty roles. Yes, some departments hire people with few publications. But the majority still want to ensure their faculty can get funded. If funding is partly a function of papers, this is used in decision-making.
3. The number of papers is important if you want to get high-level awards. Many of them are not given because you published one paper (even if it’s great). They are given because you made a meaningful CONTRIBUTION to the field. How do you make it? Publish more papers.
4. Tenure promotions in many places take the number of your papers into account (often indirectly). Your tenure may get delayed if you don’t publish enough. Not everywhere, but for many mid- to low-ranked universities this story is more or less the same.
There are many more to mention.
📍My opinion:
Much of this is rooted in how funding is distributed.
There is a strong correlation between the requirements at a university and the funding acquisition criteria.
If funding were based ONLY on the quality of published papers, universities would hire people for the quality of their science. If funding agencies strongly discouraged publishing too many papers, universities wouldn’t expect numbers from faculty during promotions. And some supervisors wouldn’t pressure students and postdocs to publish unfinished studies and low-quality data.
Yes, we need good detectors of fake papers.
But we also need the right policies and better funding allocation criteria.
94
366
1,427
194,271
Peter retweeted

27 Sep 2025
The point of science is to cover the greatest number of empirical facts at the least model complexity cost.
10
10
195
21,729
Peter retweeted

15 Jun 2025
We are so proud of Marta Lopez ( @mlopezosias ) presenting her PhD work yesterday at @young_eha in Milan!! 🥰 🥳 She nailed it 💥🚀 #EHA2025 @EHA_Hematology

1
6
63
4,649
Peter retweeted
10 Jun 2025
The rate at which you learn is to a great extent a function of your metacognitive sensitivity -- your propensity to introspect and critique your own mental models and learning processes
46
189
1,644
94,775
Peter retweeted

5 Jun 2025
We've been working on this resource for months: A VISUAL GUIDE TO GENOME EDITORS.
Learn how tools like Cas9, Cas13, prime editors, and Bridge editors work - with diagrams!
We hope this becomes a valuable resource for the biology community and students.
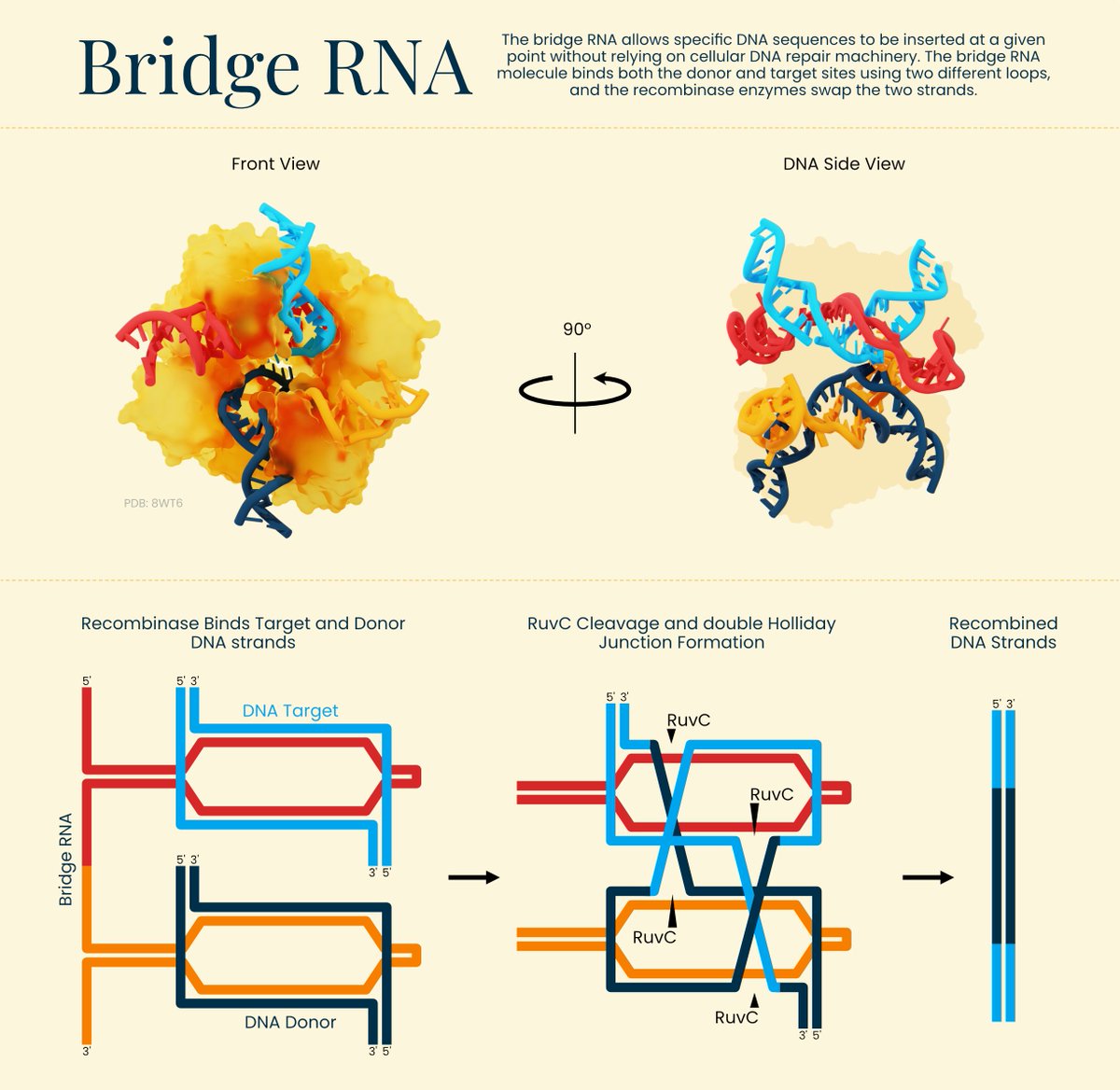
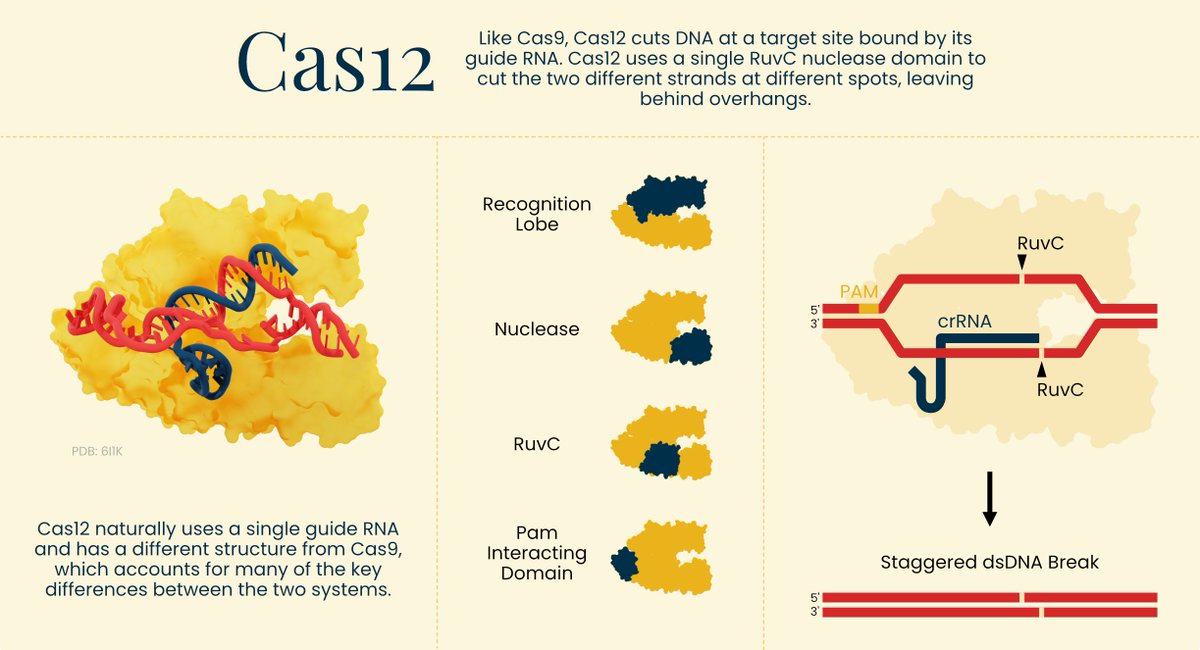
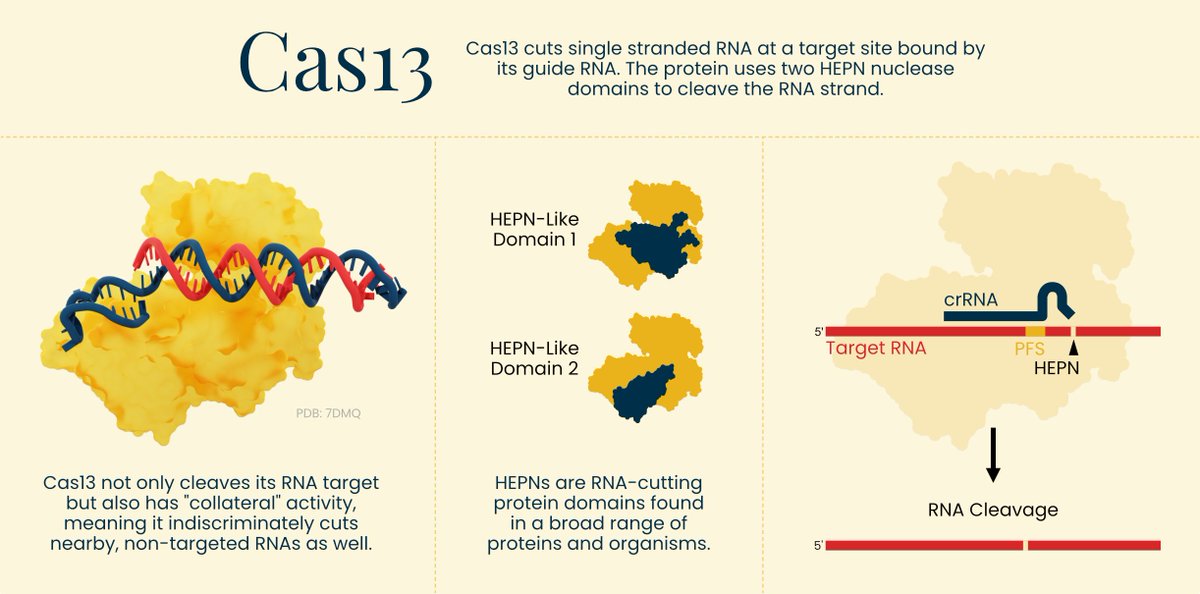

5
151
687
89,128
Peter retweeted

4 Jun 2025
Very cool work - a blood-based epigenetic clock for intrinsic capacity predicts mortality and is associated with clinical, immunological and lifestyle factors | Nature Aging nature.com/articles/s43587-0…
1
2
11
970
Peter retweeted

28 May 2025
Interesting how the nearest neighbors don’t actually look like the nearest neighbors in 2d 🧐
27 May 2025

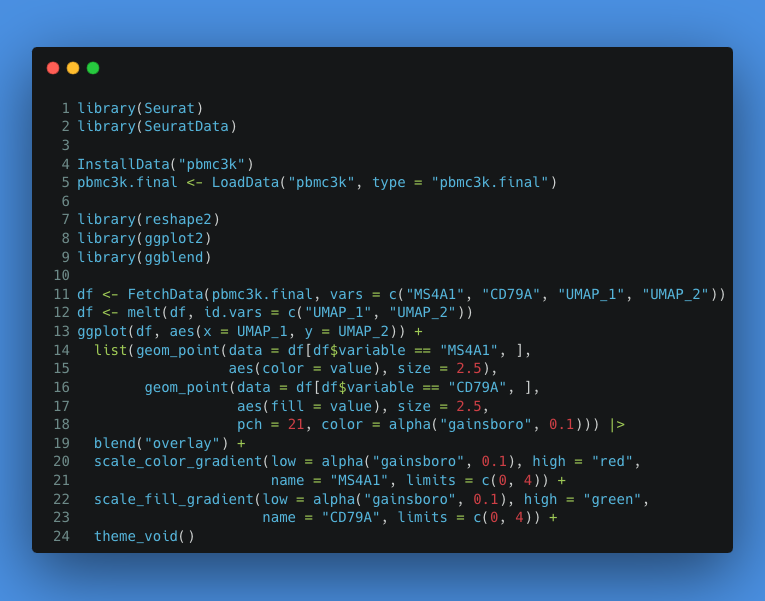
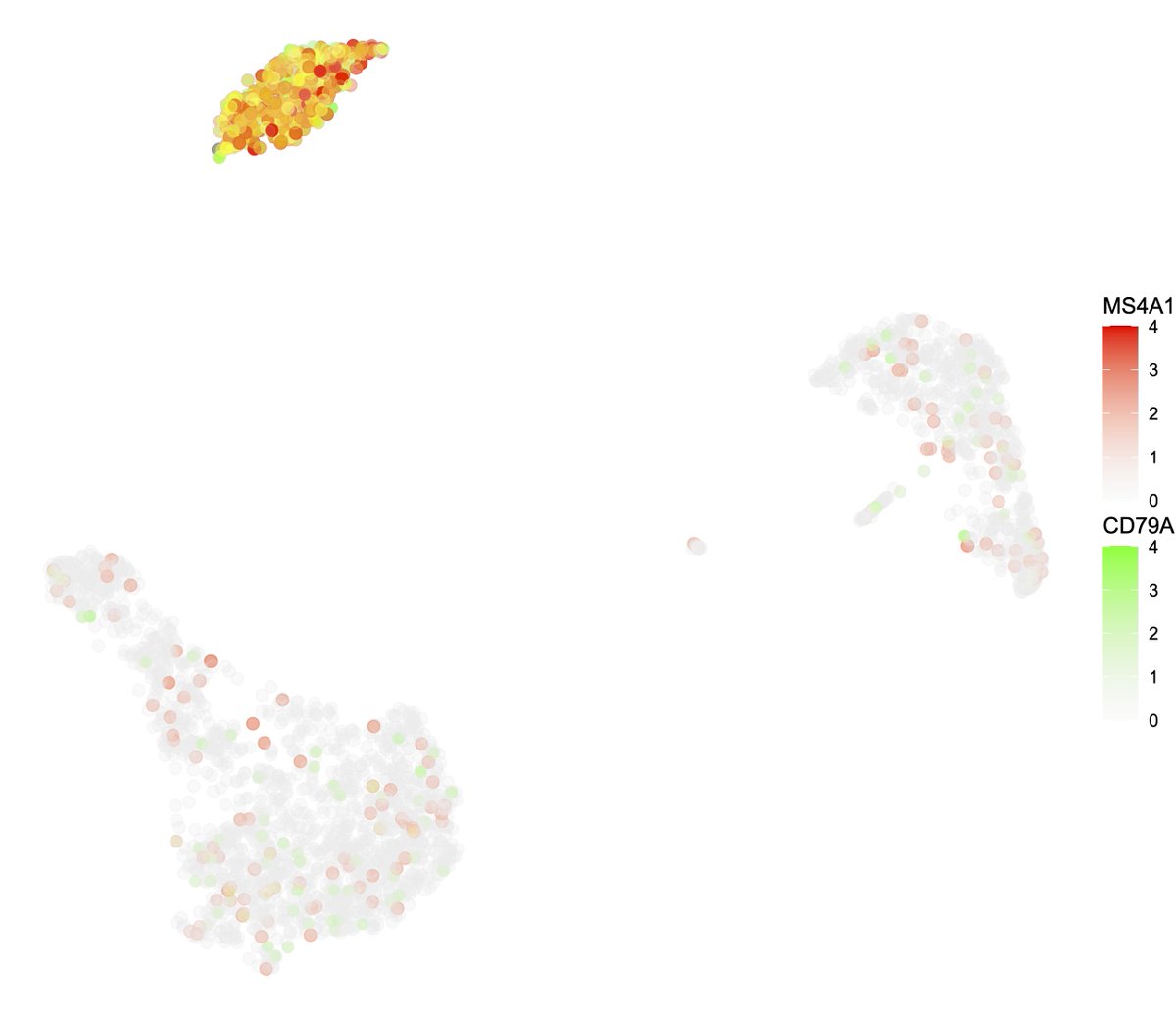
I'm prototyping a little tool for interactively visualizing the near-nearest neighbor network in single-cell RNA-seq. Clicking a cell triggers a wave, revealing its nearest neighbors, then their neighbors, and so forth.
Data: 10k PBMCs from a Healthy Donor (v3), 10x Genomics
1
3
31
2,321