
AI research scientist @axon_us. Previously @UW and @Tsinghua_Uni, co-worked with @uwnlp in AI/ML/NLP.
Joined February 2020
- Tweets 26
- Following 263
- Followers 69
- Likes 161
6 Photos and videos
Bowen Zhao retweeted

6 Aug 2025
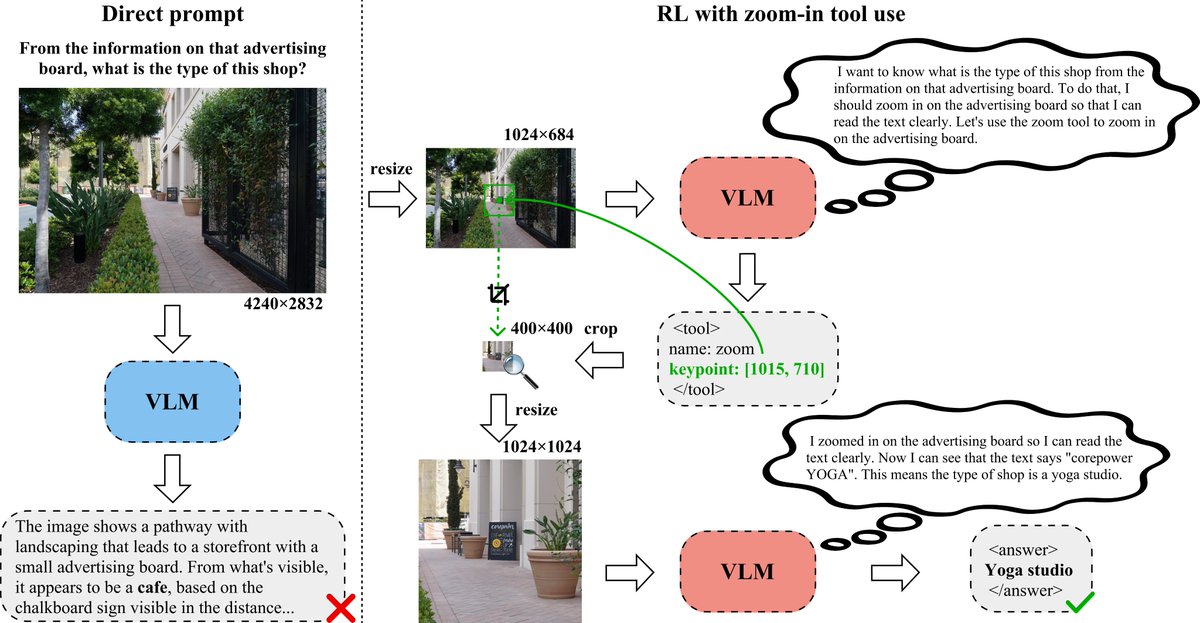
Excited to share some new work: we show how to efficiently train small vision-language models to use a zoom tool with GRPO. We identify key points for doing small-scale RL for tool use in VLMs generally, and share what works (and what doesn’t) under significant resource constraints. arXiv link below ⬇️
16
39
402
31,322
Bowen Zhao retweeted
20 May 2025
We've open-sourced a MCP that allows big models to use huggingface computer vision models as tools.
This allows Claude to act as a "visual agent", using other task specific models to help it solve problems.
Below, is an example of Claude using an open vocab object detector to zoom in on small details to solve a hard problem that it could not solve natively.
Additionally, we've written a blog post discussing why outsourcing vision capabilities from large models is something you should consider.
MCP Repo: github.com/groundlight/mcp-v…
Blog post: groundlight.ai/blog/vision-a…
1
3
33
2,070
Bowen Zhao retweeted
14 Mar 2025
We just released an open-source framework that makes it easy to build visual reasoning agents (with GRPO).
github.com/groundlight/r1_vl…
27
121
965
108,527

12 Mar 2025
It’s my pleasure making some minor contribution to this great project! This attention rollout video is my favorite “visualization of the year” so far. Try out our demo if you are interested and stay tuned for our future research!

We trained a Visual LLM to reason using GRPO, and open sourced the code. Tiny 3B model beats all the big players (GPT, Claude, etc 0-shot) after RL training on this cryptogram task. Live demo and links: groundlight.ai/blog/visual-r…
Vision foundation models have kinda stagnated recently, but now that we have shown how to incorporate reason, I think we'll be able to make progress again.
2
87
Bowen Zhao retweeted

13 Aug 2024
Just dropped ⚡ - our latest youtube tutorial, running Groundlight's computer vision on a Raspberry Pi! Watch it here: youtube.com/watch?v=YpNKHjuZ…
Tim Huff, our Robotics Engineer, walks you step-by-step how to create an application to get notified if someone steals your parking spot.
Unlike traditional computer vision:
☑ No need for a dataset
☑ Works on day one
☑ Adapts to your real environment

1
2
6
444
22 Jul 2024
@awk_ai @HannaHajishirzi
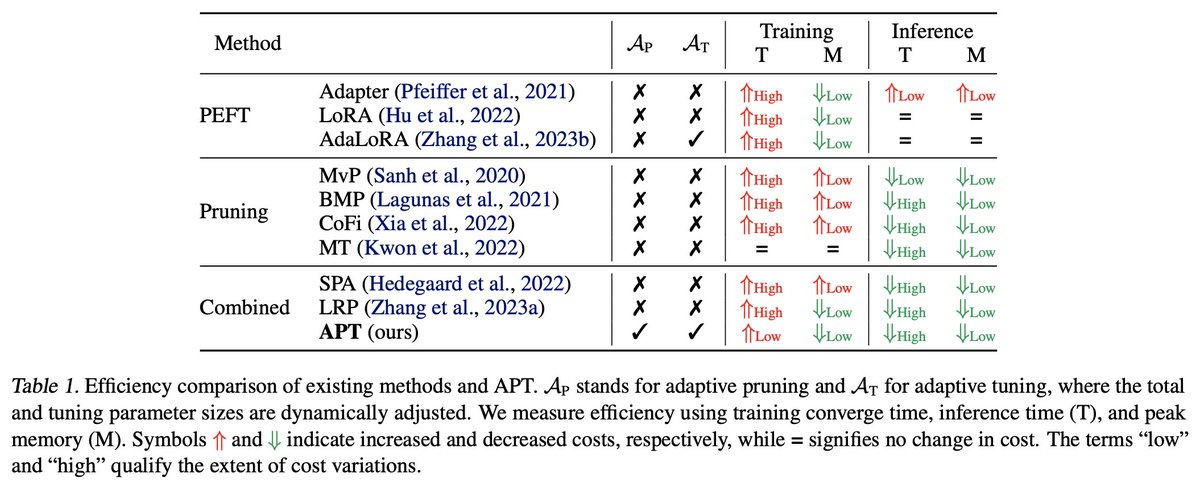
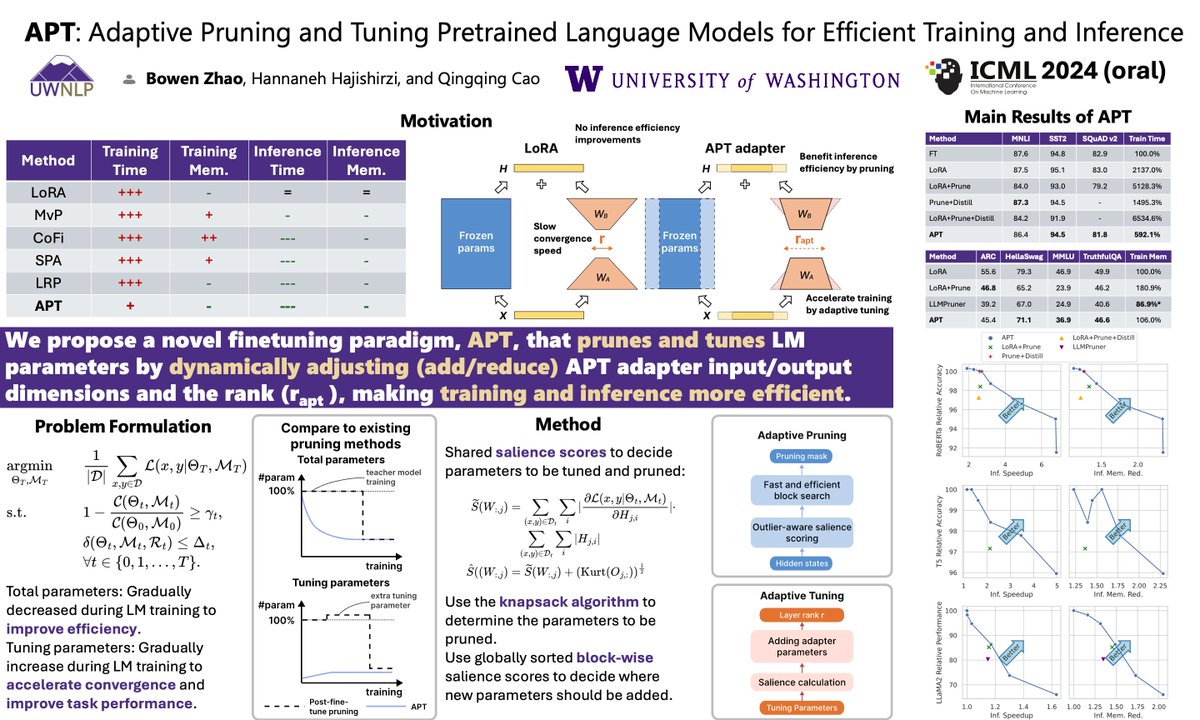
Can’t run billion-level LLMs efficiently? Take a look at our work: APT.
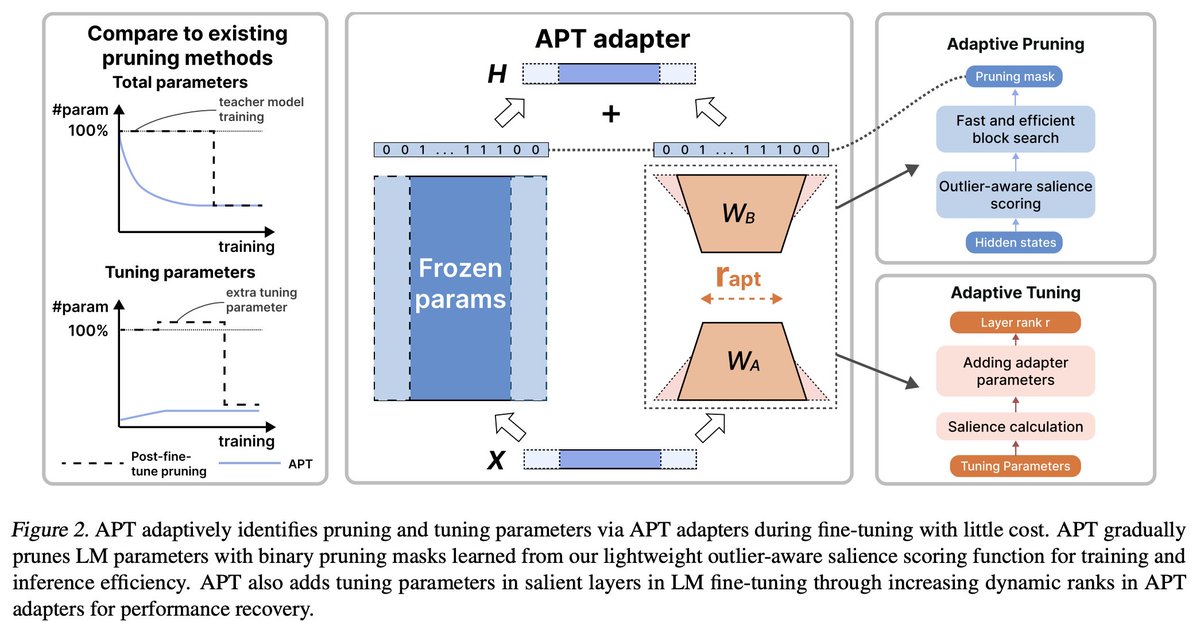
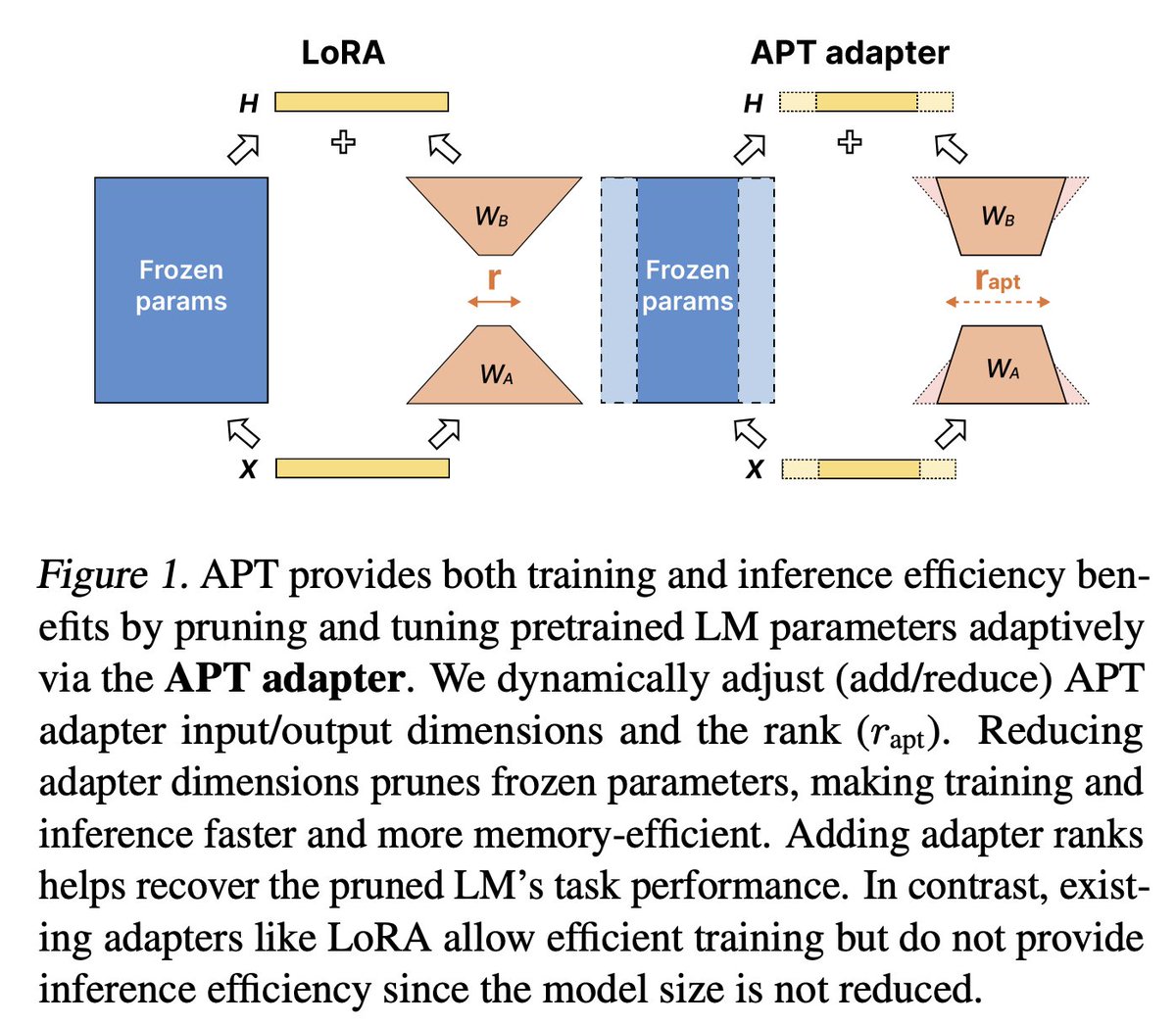
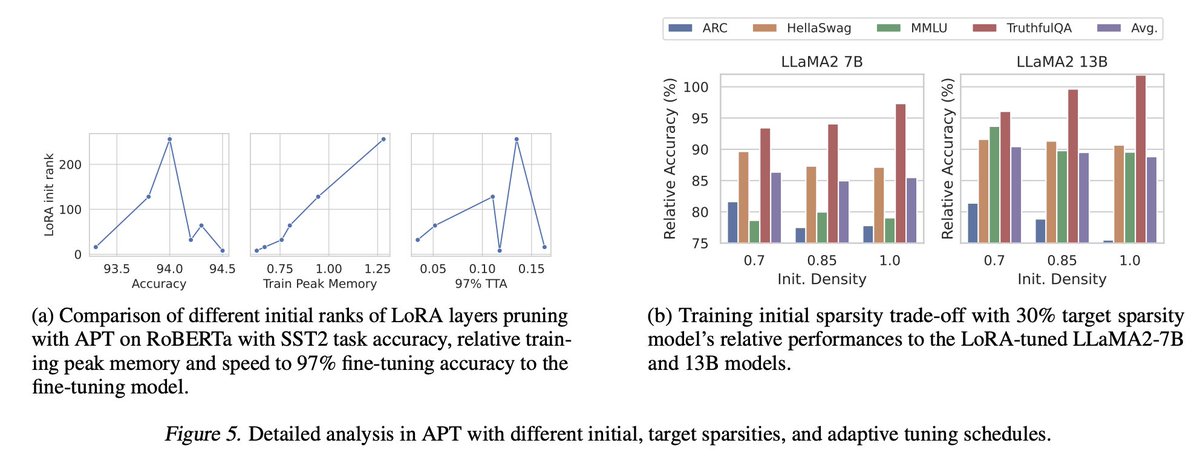
We are excited to share our #ICML2024 oral paper, “APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference”.
Paper: shorturl.at/xabJl
1
4
10
1,194
22 Jul 2024
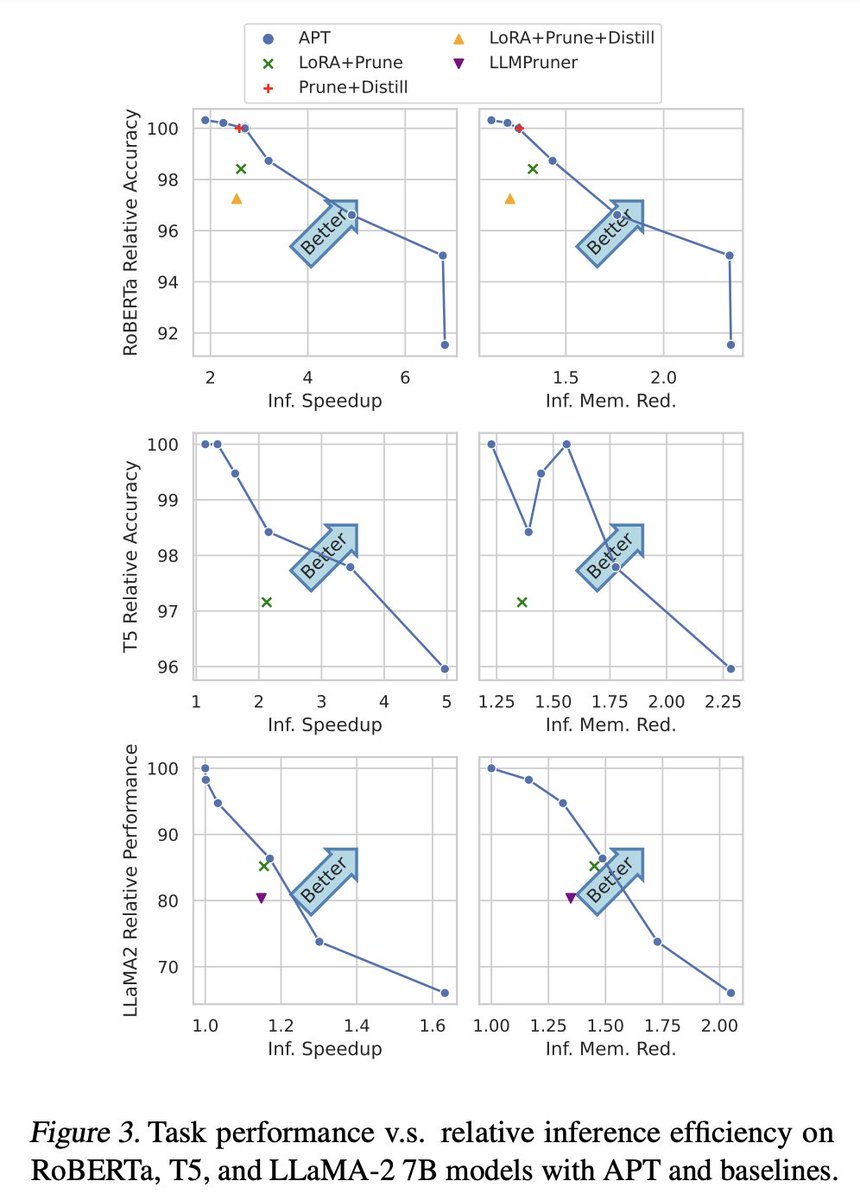
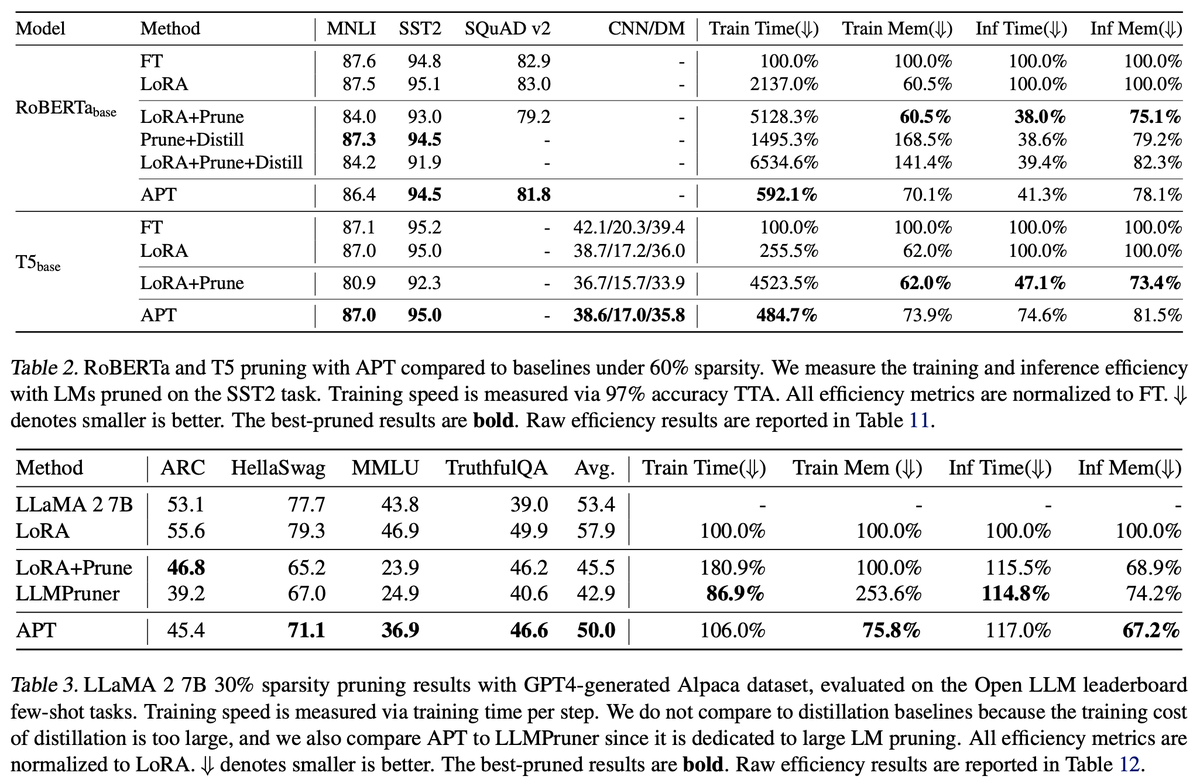
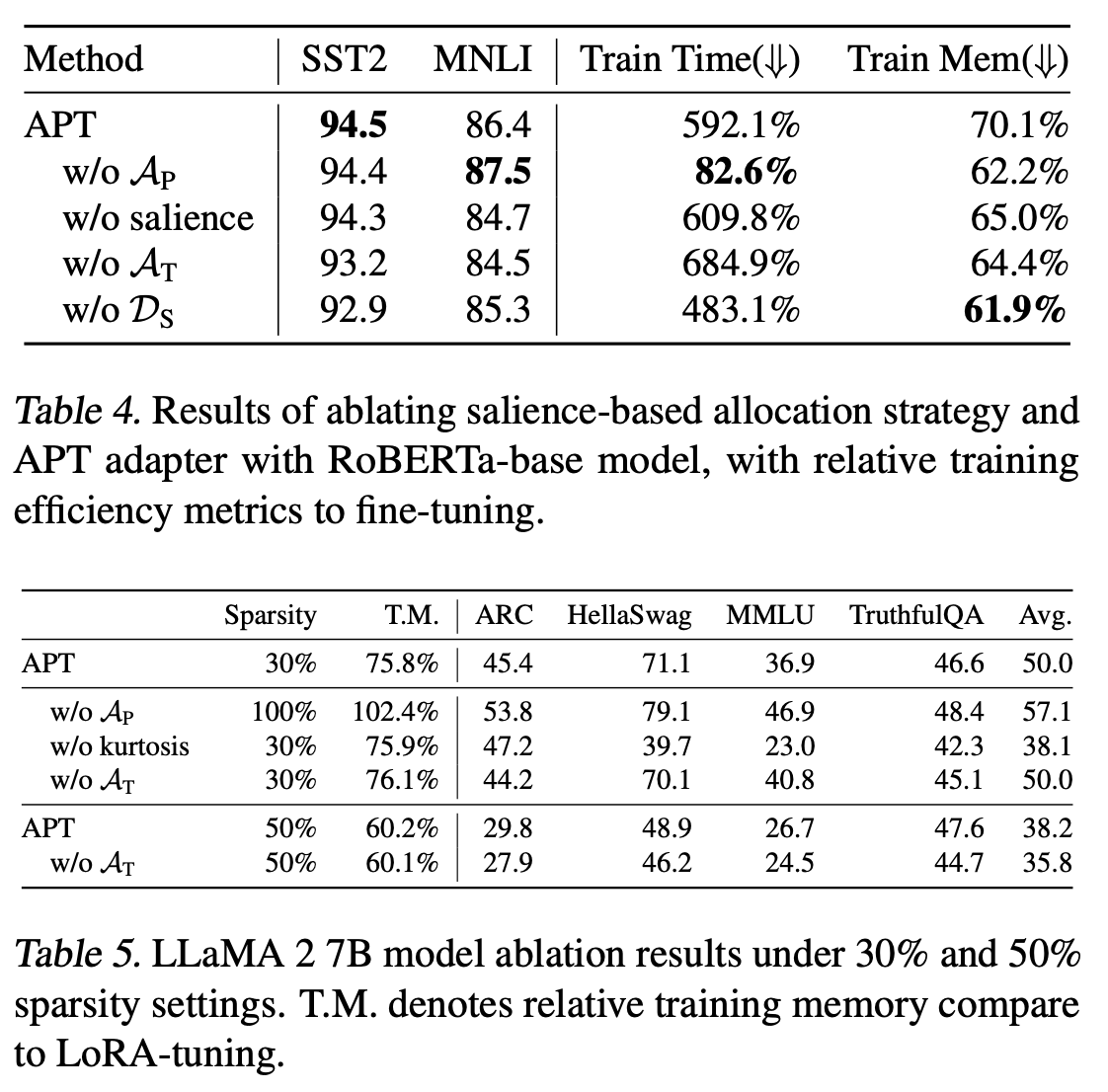
Experiments show that APT maintains 98% task performance when pruning 60% of the parameters in small models, and it preserves 86.4% of LLaMA's performance with 70% density. Furthermore, APT speeds up LMs’ finetuning by up to 8x and reduces LLMs’ training memory cost by up to 70%.
1
79
Bowen Zhao retweeted
20 Jun 2024
#CVPR2024 down the street gets our science team out of the office!
10,000 computer vision researchers in Seattle figuring out what's next in the field from multimodal foundation models to the most creative applications.

3
4
954
Bowen Zhao retweeted
18 Jun 2024
🚀 Exciting News from Groundlight AI! 🚀 Introducing, the Groundlight Hub, your easy access to computer vision.
youtu.be/u3xPnOnvTcE
1
6
9
725
Bowen Zhao retweeted
29 May 2024
Our Robotics Engineer, Tim Huff, gives a demo of Groundlight AI's Visual Inspections 🔍 and Anomaly Detection solution, compatible with @Universal_Robot 🤖 cobots:
1
3
6
1,123
Bowen Zhao retweeted

6 May 2024
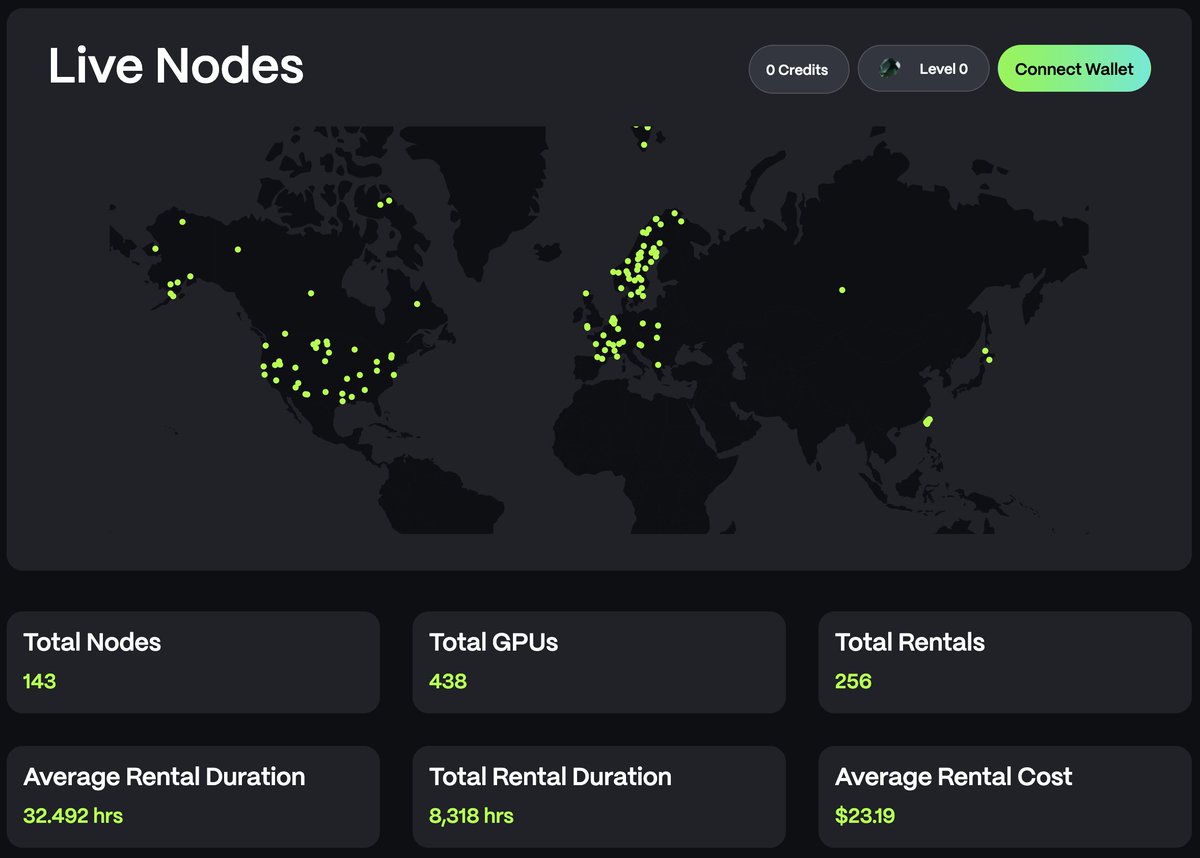
Importance of Demand Generation ✍️
🌟 The number of GPUs we own and the robustness of our L1 integration are crucial, but they're not the sole determinants of our long-term success. It's all about creating demand for our product.
🥅 Our ultimate goal is to stimulate demand for our GPU nodes through diverse integrations and utilities. We're committed to providing solutions that meet the needs of our users and drive adoption.
📈 In just the last 3 days, we've seen a significant uptick, accumulating nearly 400 additional rental hours for our $GPUs. This demonstrates the growing interest and demand for our platform.
🥇 Our primary focus remains clear: to establish #NodeAI as the premier infrastructure provider for high-performance AI.
Demand generation is key, and we're dedicated to making it happen.
#AI #DEPIN #GPU
77
947
1,463
222,689
1 Mar 2024
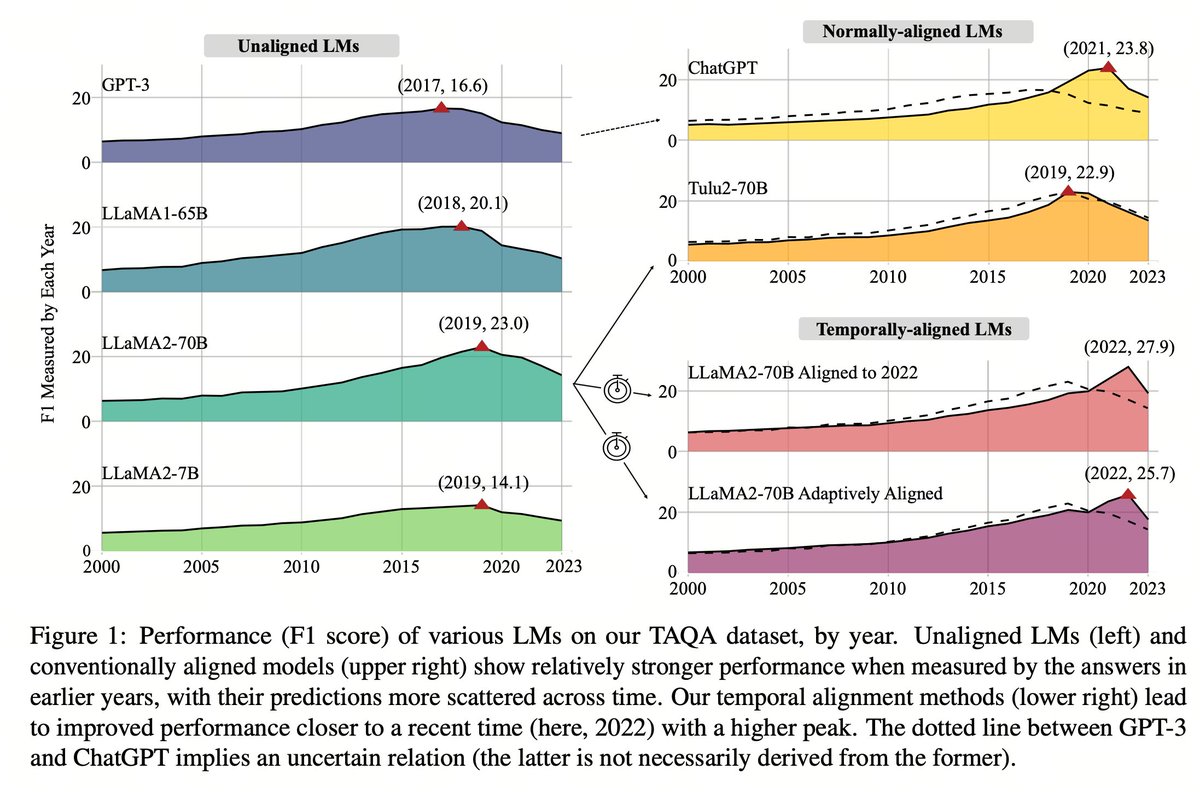
Super excited to share this paper! Temporal chaos in pretraining corpora greatly impacts language model’s capabilities in answering time-sensitive questions. We will publish our codes for dataset generation and temporal alignment later. Stay tuned!
1 Mar 2024

When you use ChatGPT, do you notice that it has a data cutoff date? 🗓️ But as models are pretrained on web text originating from many historical periods, do they have a sense that they should use their latest knowledge to answer questions rather than historical info?
Excited to introduce our new work on *Temporal Alignment*! We show that pretrained LMs encode a chaotic sense of time, but it’s possible to align them to a recent time, or some time in history! 🕐🕟🕘
📜 shorturl.at/cfrR8
3
228
Bowen Zhao retweeted

1 Mar 2024
This is a joint work co-led with my awesome mentees @BowenROIM and @zanbrum. Please reach out to them if you have job or collaboration opportunities for them! Finally, always many thanks to our fantastic advisors @HannaHajishirzi and @nlpnoah ❤️❤️❤️
2
3
5,744
Bowen Zhao retweeted

27 Sep 2023
What if we combine PPO with Monte-Carlo Tree Search – the secret sauce for AlphaGo to reach superhuman performance?
Spoiler: MAGIC!! Our inference-time decoding method, PPO-MCTS, achieves impressive results across many text generation tasks.
📜 arxiv.org/abs/2309.15028
🧵(1/n)
9
97
448
73,987
Bowen Zhao retweeted

21 Jun 2023
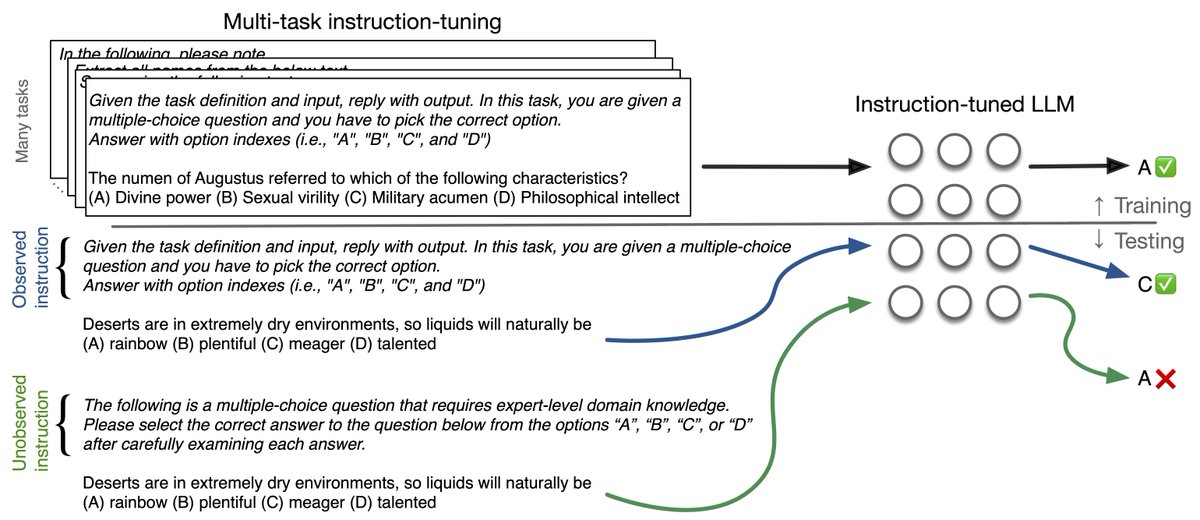
How robust are the instructions in your instruction-tuned model?
In our most recent work (w/ @ChantalShaib and @byron_c_wallace), we show that there is a considerable dip in performance on in-domain tasks when you slightly vary the instruction.
arxiv.org/abs/2306.11270
1
8
43
11,273
Bowen Zhao retweeted

17 Jun 2020
Perisic and Icardi winning league titles and still in the UCL while Conte & Inter........

8
13
52