
Research Scientist @apple AIML, Previously Postdoc @uwnlp & PhD @sbucompsc. Efficient #NLProc, on-device AI, mobile computing.
Joined July 2014
- Tweets 148
- Following 609
- Followers 583
- Likes 457
14 Photos and videos






Qingqing Cao retweeted

17 Jul 2025
In this report we describe the 2025 Apple Foundation Models ("AFM"). We also introduce the new Foundation Models framework, which gives app developers direct access to the on-device AFM model.
machinelearning.apple.com/re…
499
92
464
70,129

18 Oct 2024
Please email us at mind-research-internship@group.apple.com including your CV and highlighting your most relevant skills and experience, and then apply at jobs.apple.com/en-us/details….
1
1
1
404
18 Oct 2024
The position is full-time for a minimum of 12 weeks, with up to a year possible depending on the start date. Internships can begin before summer, but the sooner the better.
1
306
Qingqing Cao retweeted

16 Oct 2024
1/ KV Prediction for Improved Time to First Token
Tired of waiting forever for your on-device LLM to begin outputting tokens? I know I am.
In our latest preprint, we investigate a method for improving time to first token (TTFT) for on-device models by predicting a model’s KV cache using a small Auxiliary model. We demonstrate improvements in TTFT of up to 2x at a fixed accuracy. Full details: arxiv.org/pdf/2410.08391 . Code at github.com/apple/corenet/tre… .
Work done with @awk_ai , Chenfan Sun, Yanzi Jin, @sacmehtauw @morastegari Moin Nabi.
#LLM #Apple #Research #TTFT #Ondevice #OpenELM #Corenet #KVPrediction

1
1
6
1,347
Qingqing Cao retweeted

22 Jul 2024
@awk_ai @HannaHajishirzi
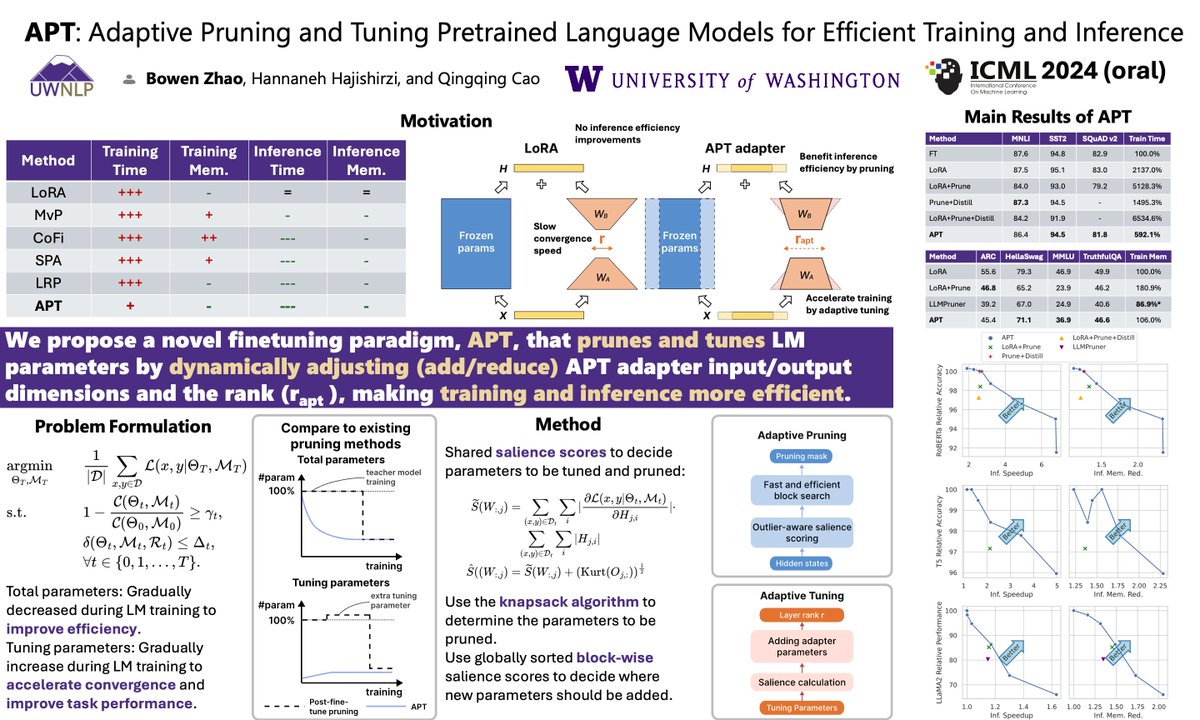
Can’t run billion-level LLMs efficiently? Take a look at our work: APT.
We are excited to share our #ICML2024 oral paper, “APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference”.
Paper: shorturl.at/xabJl
1
4
10
1,194
5 May 2024
Thank you Akari for the help!
5 May 2024

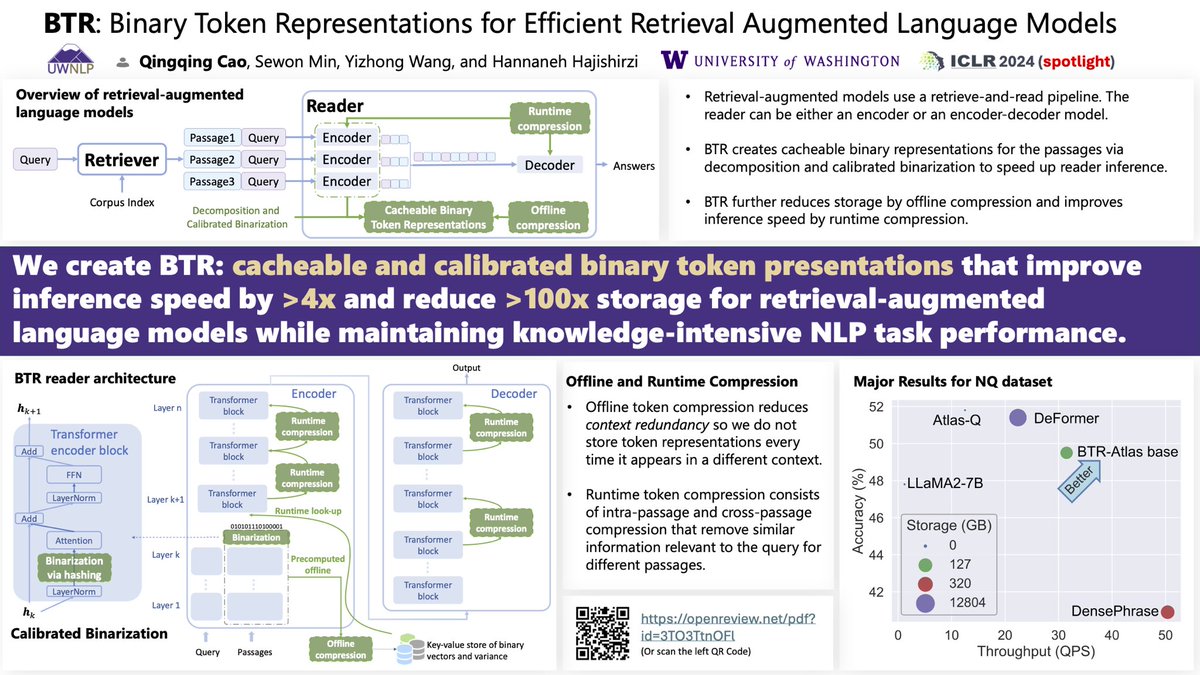
BTR by @sysnlp @sewon__min @yizhongwyz @HannaHajishirzi
None of the authors can travel to ICLR this time 🥲 I’ll do my best presenting this really cool work! You should also check out the video available on the website by @sysnlp!

1
503
Qingqing Cao retweeted

25 Apr 2024
Like OpenELM, CatLIP is also "Open"
github.com/apple/corenet

Apple presents CatLIP
CLIP-level Visual Recognition Accuracy with 2.7x Faster Pre-training on Web-scale Image-Text Data
Contrastive learning has emerged as a transformative method for learning effective visual representations through the alignment of image and text
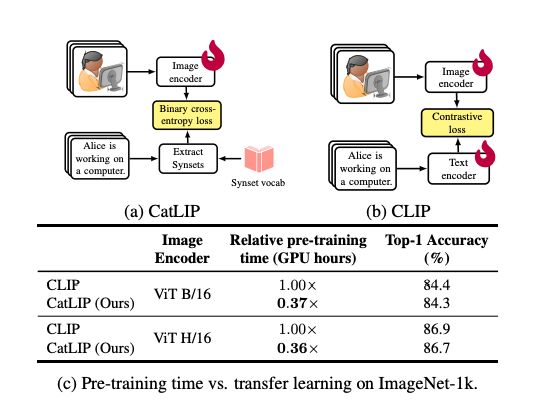
6
15
2,602

Apple presents OpenELM
An Efficient Language Model Family with Open-source Training and Inference Framework
The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and

6
97
556
173,899
12 Jul 2023
LLMs are becoming more powerful and multimodal, wonder how we can run them faster?
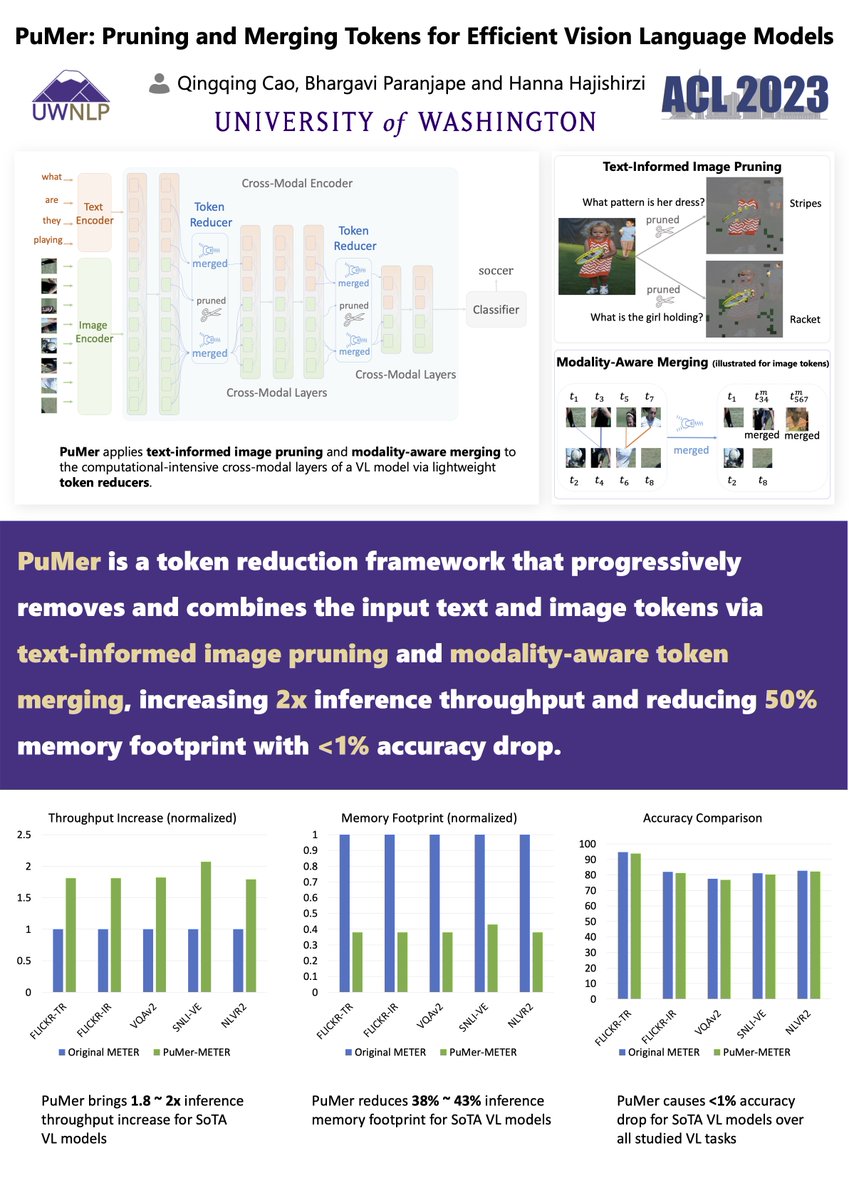
I'm happy to present the paper "PuMer: Pruning and Merging Tokens for Efficient Vision Language Models" at the #ACL2023NLP @aclmeeting, joint work w/ @bvp22294 @HannaHajishirzi
1
1
18
2,177
12 Jul 2023
Come and join our poster session tomorrow (July 12) at 11:00-12:30 (EDT, America/Toronto). Unfortunately, I cannot present the work in person due to visa and family reasons. But feel free to check it out at virtual2023.aclweb.org/paper…, video at underline.io/events/395/post….
1
1
2
375
Qingqing Cao retweeted

9 Jul 2023
I'll be moderating an Efficiency in #NLProc Panel at the #SustaiNLP 🌿 workshop at #ACL2023 this Thursday. We have top leaders from Academia and Industry: @DrorRotem, @myleott, @sysnlp, @sarahookr
Any questions you would like to ask? Post here or join the panel!
1
7
25
5,408
Qingqing Cao retweeted

7 Jul 2023
Don't miss our #ACL2023 tutorial on Retrieval-based LMs and Applications this Sunday!
acl2023-retrieval-lm.github.…
with @sewon__min, @ZexuanZhong, @danqi_chen
We'll cover everything from architecture design and training to exploring applications and tackling open challenges! [1/2]

ALT Tutorial on Retrieval-based LMs and Applications at ACL 2023. - Instructors: Akari Asai (University of Washington), Sewon Min (University of Washington), Zexuan Zhong (Princeton), Danqi Chen (Princeton) - Time & location: Sunday, July 9 14:00 - 17:30 (EDT) @ Metropolitan West - website https://acl2023-retrieval-lm.github.io/
6
103
487
91,239
Qingqing Cao retweeted

12 Jun 2023
Introducing💃AdANNS: A Framework for Adaptive Semantic Search🕺
TL;DR: Up to 90× faster nearest neighbor retrieval and 2× lower memory cost for web-scale search.
Applies to vector search at scale & improves all "retrieval" augmented models!
arxiv.org/abs/2305.19435
[1/8]
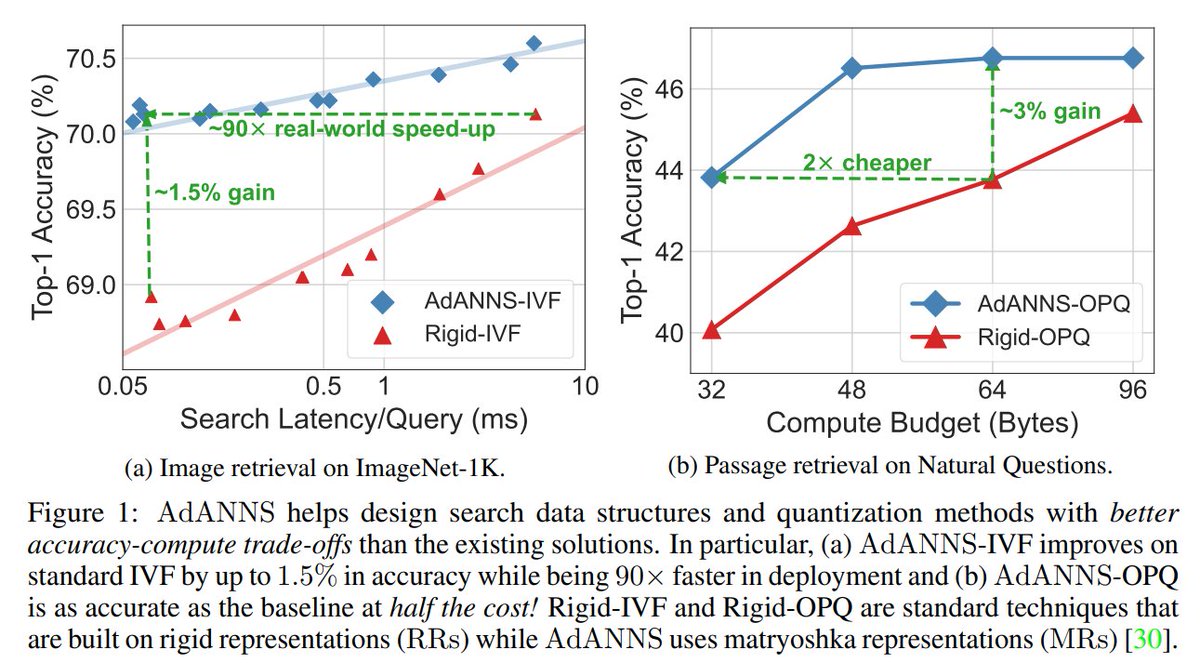
5
88
470
91,083
Qingqing Cao retweeted

24 May 2023
4-bit QLoRA is here to equalize the playing field for LLM exploration. You can now fine-tune a state-of-the-art 65B chatbot on one GPU in 24h.
Paper: arxiv.org/abs/2305.14314
Code and Demo: github.com/artidoro/qlora
24 May 2023

QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:
Paper: arxiv.org/abs/2305.14314
Code Demo: github.com/artidoro/qlora
Samples: colab.research.google.com/dr…
Colab: colab.research.google.com/dr…

6
45
222
81,370
Qingqing Cao retweeted

28 Mar 2023
Looking for valuable insights and carefully curated pointers on efficient NLP research directions? 🔎 Check out our updated survey covering an extensive range of topics in the classic NLP pipeline 🚀:
arxiv.org/abs/2209.00099
Product of an amazing collaborative team effort! 🤝
28 Mar 2023

Efficient NLP methods - an up-to-date survey, to appear in TACL. We cover efficiency wrt:
* Data
* Model design
* Pre-training
* Fine-tuning
* Inference & compression
* Hardware utilization
* Evaluation
* Model selection
This was a blast to co-produce!
arxiv.org/abs/2209.00099
2
4
24
3,900
Qingqing Cao retweeted

2 Sep 2022
How can NLP be more efficient? We can't blindly scale forever. This survey I'm lucky to be part of presents current efficiency research at many stages of the NLP process, and actionable advice to practitioners for making their NLP more efficient.
arxiv.org/abs/2209.00099 #nlproc
8
73
293
10 Jul 2022
I'll be at #NAACL2022 this week, my first ever in-person #nlproc conf since I joined the @uwnlp group at the University of Washington. I'm happy to chat about efficient #nlproc (QA, retrieval, vision-language models, etc.) or postdoc at UW, life in Seattle.
1
2
33
Qingqing Cao retweeted

8 Nov 2021
@lal_yash is presenting this in Bavaro 4 right now! Stop by and have a chat @emnlpmeeting #EMNLP2021
26 Aug 2021

IrEne-viz is a platform showcasing energy consumption of transformer models. Built over IrEne (from #ACL2021), it allows for fine-grained & interpretable analysis of models & their components. Joint work by @yash_lal, Reetu Singh, @harsh3vedi, @sysnlp, @aruna__b, @b_niranjan /n

2
1