
Stuck on a vuln? Get elite second eyes. Private collab rooms, exploit chaining, real impact. Built for serious bug bounty hunters. Finish the bug.
Joined November 2018
- Tweets 131
- Following 3,843
- Followers 909
- Likes 3,025
15 Photos and videos




Pinned Tweet

Mar 28
AI made baseline recon faster.
It also made it more uniform.
Most people are still running variations of:
Subfinder, Amass, assetfinder, crt.sh, gau, waybackurls, httpx, nuclei, dnsx, naabu....
We’re building BugUnstuck Finder to go above that layer.
New angles.
Merged uncommon sources.
Frontier-focused discovery.
On a recent run, BugUnstuck pulled 1,962 unique hosts that every other tool in the comparison missed.
If you want to see the delta on a real target, send a private message to @BugUnstuck and we’ll send you a personalized result list.
2
183
BugUnstuck retweeted

May 11
KithDB Phase 0.13 produced 308 active QC-confirmed candidate protein families from a 1.1M-protein corpus, including a 392-member hardened-novelty pool where 82.9% lack Pfam annotation at the gathering threshold. A UniRef50 cross-check shows the main signal is not “proteins absent from UniProt,” but a Pfam/family-annotation gap in known sequence space.

2
4
49
BugUnstuck retweeted
May 9
Kith Atlas update.
In ~48h, KithDB mapped 1.1M orphan proteins and confirmed 97 hidden protein families / 1,582 proteins.
The important part: 248 confirmed proteins have no Pfam annotation.
Top novelty signals so far:
• 3.40.190 histidine kinase-like candidates
• 2.40.160 esterase-like candidates
• 3.10.450 small cross-kingdom fold family
KithDB is becoming a searchable atlas of protein dark matter.
#ProteinDiscovery #Bioinformatics #ProteinDarkMatter

2
3
72
BugUnstuck retweeted
May 8
In ~24h, Kith mapped 1.1M orphan / no-Pfam proteins into ranked, testable hypotheses inside KithDB.
Then we validated the map and confirmed 21 hidden protein families and 400 proteins across enzymes and structural scaffolds.
Protein dark matter is becoming searchable.
Kith by manifoldmemory.ai
@GoogleDeepMind | @demishassabis | @uniprot @InterProDB | @emblebi

2
3
72
BugUnstuck retweeted
May 6
Kith, a new product from ManifoldMemory, turns unknown protein sequences into testable structural and functional hypotheses.
Instead of leaving “uncharacterized” proteins in the dark, Kith helps map protein dark matter into ranked, investigable candidates.
A step toward faster protein discovery. 🧬
#AI #Biotech #ProteinDiscovery #Bioinformatics #MachineLearningTrivia
@IsomorphicLabs, @GoogleDeepMind, @demishassabis

2
4
67
BugUnstuck retweeted
May 5
AlphaFold showed that the right learned approximation can make biological structure-space searchable.
I wonder if ManifoldMemory can help one layer earlier:
a proprietary latent memory that retrieves structural prototypes, remote fold neighbors, templates, and priors before an AlphaFold-like predictor runs.
Not “ManifoldMemory folds proteins.”
More like:
AlphaFold (@IsomorphicLabs) predicts structure. ManifoldMemory remembers fold-space.

2
2
29
BugUnstuck retweeted
May 3
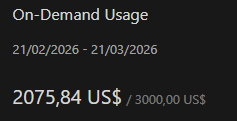
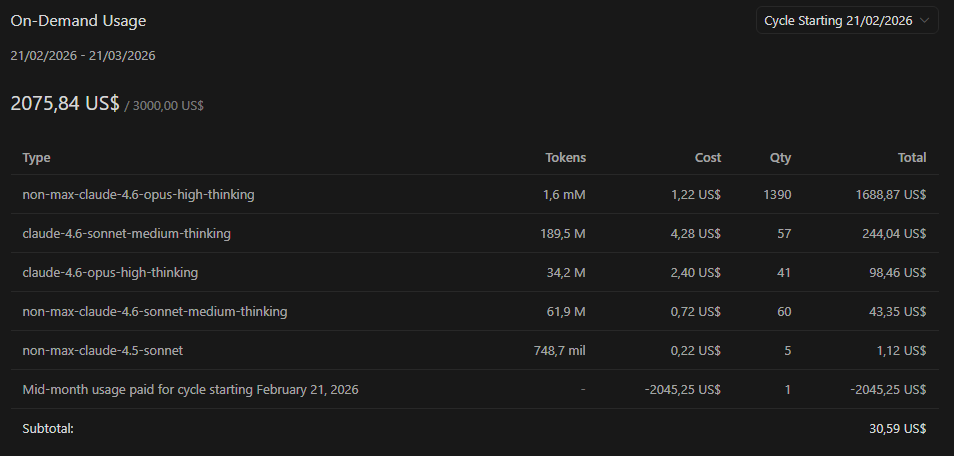
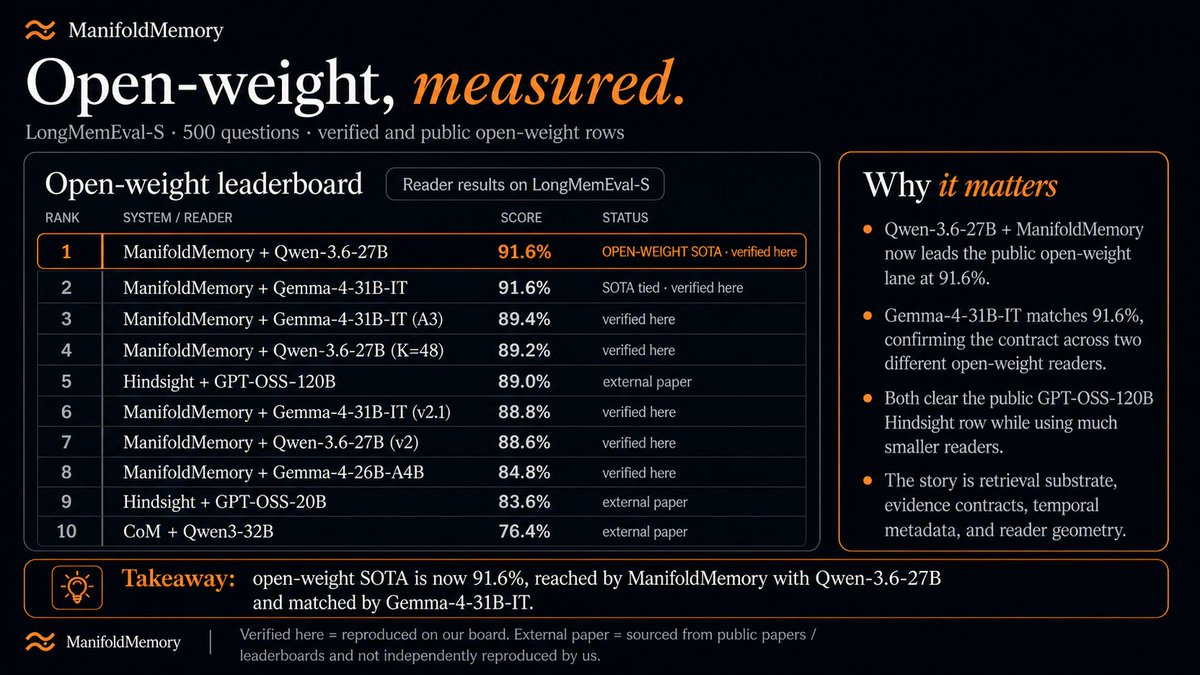
Open-weight SOTA on LongMemEval-S.
ManifoldMemory Qwen-3.6-27B (@Alibaba_Qwen) reached 91.6% on the 500-question split under our strict judge.
And ManifoldMemory Gemma-4-31B-IT (@googlegemma) also reached 91.6%, tying the top open-weight result on our board.
That pushes past the public GPT-OSS-120B open-weight Hindsight row we track, while using much smaller readers.
Current open-weight lane:
ManifoldMemory Qwen-3.6-27B — 91.6%
ManifoldMemory Gemma-4-31B-IT — 91.6%
ManifoldMemory Gemma-4-31B-IT (A3) — 89.4%
ManifoldMemory Qwen-3.6-27B (K=48) — 89.2%
Hindsight GPT-OSS-120B — 89.0%
ManifoldMemory Gemma-4-31B-IT (v2.1) — 88.8%
ManifoldMemory Qwen-3.6-27B (v2) — 88.6%
ManifoldMemory Gemma-4-26B-A4B — 84.8%
Hindsight GPT-OSS-20B — 83.6%
CoM Qwen3-32B — 76.4%
The story is not “just use a bigger model.”
It is retrieval substrate, evidence contracts, temporal metadata, and reader geometry.
A 27B open-weight reader can now lead the public open-weight lane, and a 31B open-weight reader matches it, both clearing the tracked 120B-class public open-weight row when the memory engine around them is strong.
manifoldmemory.ai/leaderboar…
2
5
214

Evet sonunda hackerone triagerlarının bu işi bilmediklerini gösteren bir olay olmuş. Büyük bir çoğunluğu gerçekten çok kötüler. Lovable'ın "all reports" kavramı çok dikkat çekici, yani bu raporlara birden fazla triager bakmış olabilir. Artık bi aksiyon alınır umarım.
6
6
39
8,572
BugUnstuck retweeted

May 2
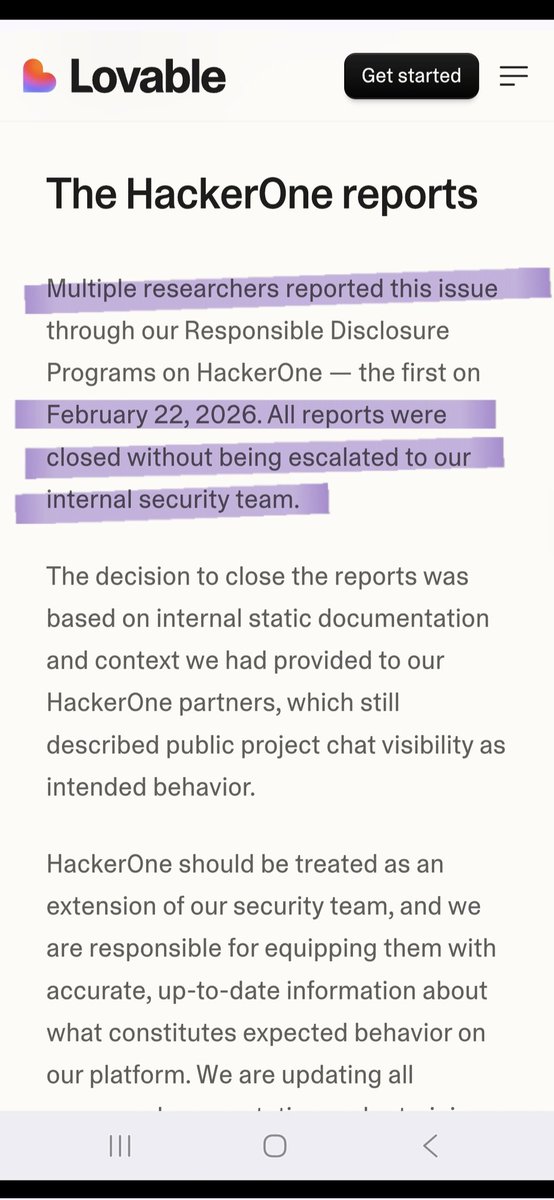
To be secure in 2026 you have to shut down your bug bounty program on HackerOne.
Lovable got hacked because HackerOne's incompetent triage team closed multiple valid vulnerability reports starting February 22, 2026 as "intended behavior."
Poorly trained monkeys. Zero escalation to Lovable's security team. AI bots auto-closing critical findings.
The result? Public project chat history and source code were exposed for MONTHS until a researcher was forced to go public.
Two companies. Same platform. Same failure. Same lies.
ClickUp. Lovable. Both breached because HackerOne buried critical reports while collecting your bounty fees.
HackerOne is NOT a security partner. They are a liability.
They close real vulnerabilities. They protect their own metrics over your data. They let researchers get attacked while they stay silent.
Stop paying HackerOne to get hacked.
lovable.dev/blog/our-respons…

51
94
878
91,028
BugUnstuck retweeted
Apr 25
Same model family. Different benchmark story.
On @AnthropicAI 's public coding benchmark, Opus 4.7 improves over Opus 4.6.
But on ManifoldMemory’s fixed-evidence Reader Leaderboard:
Claude Opus 4.6: 75.6%
Claude Opus 4.7: 72.6%
Same retrieval contract. Same 500 questions. Same judge. Only the reader changes.
That does not mean “4.6 is better than 4.7.”
It means benchmark choice matters.
A model can improve on coding / agentic workflows and still regress on a tightly controlled evidence-reading task.
This is why I’m separating evidence access from evidence reading.
manifoldmemory.ai/leaderboar…

1
3
103
BugUnstuck retweeted
Apr 25
I released v0 of a frozen-retrieval reader benchmark for LongMemEval-S.
The goal is to separate evidence access from evidence reading.
Instead of letting each system bring its own retrieval stack, I freeze the retrieval layer and expose the exact top-10 evidence chunks used by every reader.
Retrieval substrate:
500 questions
top-10 chunks per question
full chunk text
manifest SHA-256
R@5 = 481/500 = 96.2%
Then each reader answers from the same evidence block and is judged with the same GPT-4o 5-seed majority protocol.
Current results:
Gemma-4-26B-A4B Hybrid F3-on-TR: 71.4%
Gemma-4-26B-A4B canonical Hybrid: 70.0%
Qwen3.6-27B Hybrid: 66.2%
Gemma Stack-only: 63.8%
gpt-5-mini same-retrieval reference: 59.0%
Gemma no-retrieval: 53.2%
The interesting thing is not the ranking.
It is the reader gap: even when retrieval places gold evidence in top-5 for 96.2% of questions, readers still differ sharply.
This suggests long-memory evaluation should report evidence access and evidence reading separately.
Leaderboard:
manifoldmemory.ai/leaderboar…
Submission substrate:
manifoldmemory.ai/submit
4
7
80
233
Apr 21
A friend of mine is looking to publish work on arXiv and is currently seeking sponsorship.
He’s been working on a serious project in AI systems / memory-retrieval research, and I genuinely think it deserves a fair look.
If anyone here is in a position to review it and, if appropriate, sponsor the submission, please reach out. Would really appreciate any help or signal boost.
18

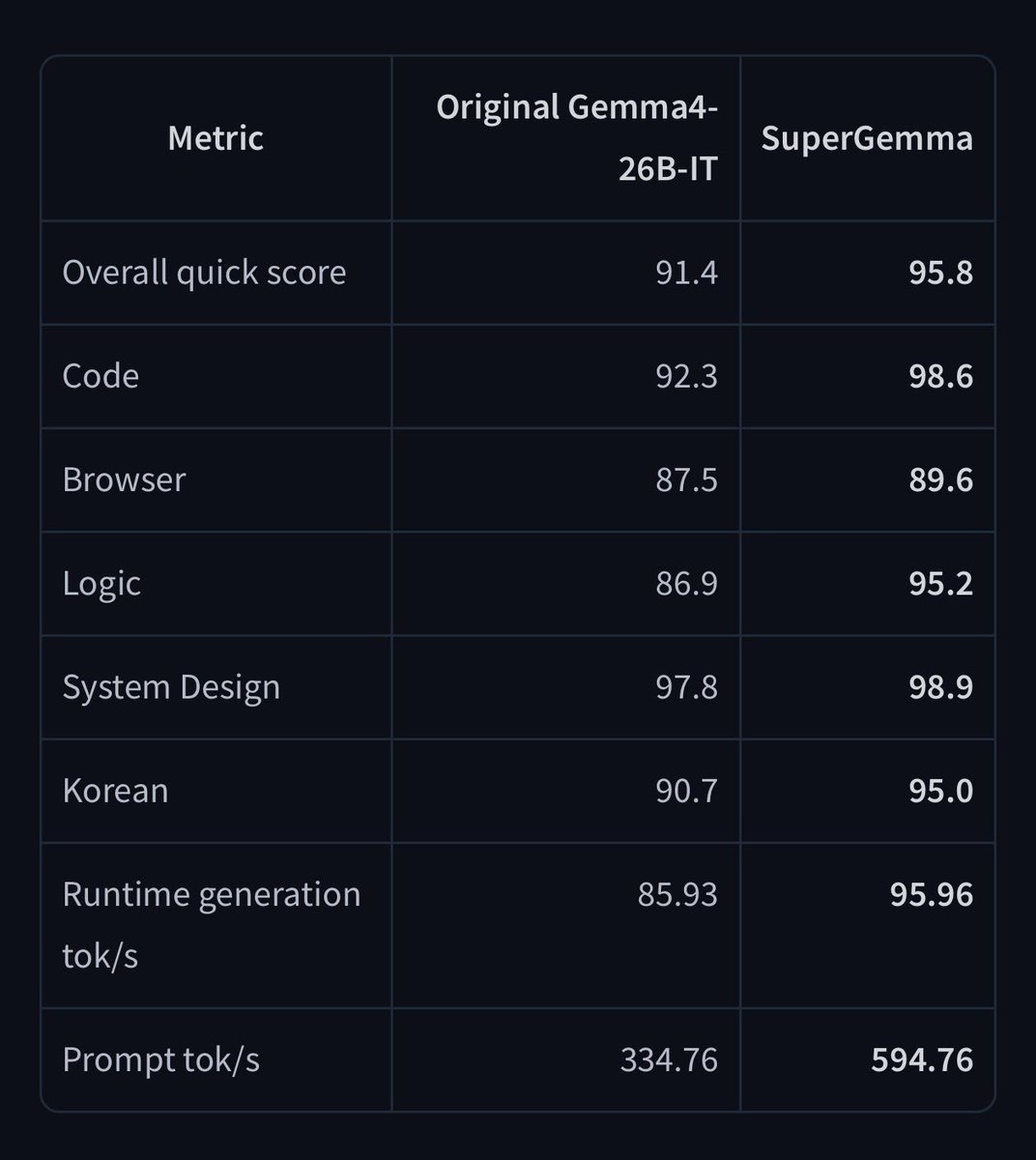
Mar 31
How a dupe still got me invited to multiple private program:
Found a real BOLA in a healthcare target. It got closed as duplicate.
No payout. No public win. Just 4 points.
But the signal was there:
valid bug
real impact
good writeup
serious research
right instinct
People obsess over the final status too much. Triagers see “duplicate”.
Good teams also see who is consistently landing on real attack surface.
Sometimes a dupe is not a loss.
Sometimes it’s proof you’re looking in the right places.
That one ended with private invites.
Not every good find pays immediately. Some of them compound... @yeswehack #BugBounty
1
17
686
BugUnstuck retweeted

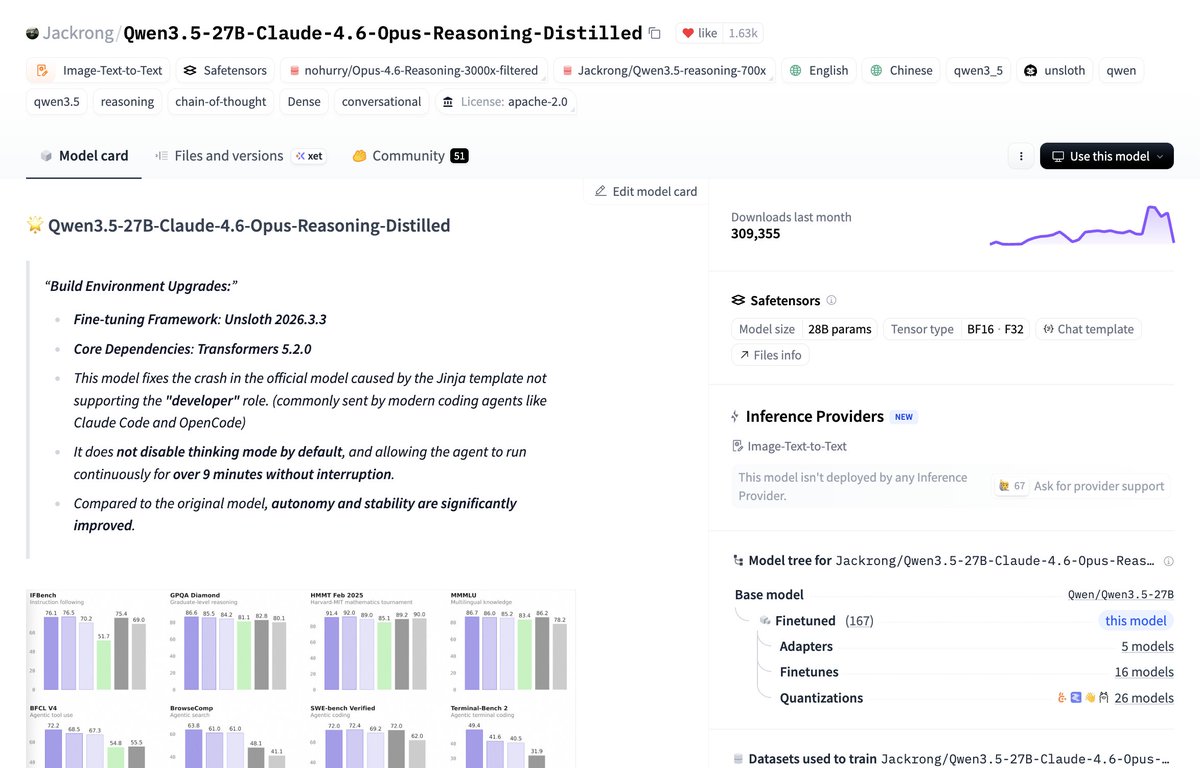
Mar 30
This model has been #1 trending for 3 weeks now.
It's Qwen3.5-27B fine-tuned on distilled data from Claude-4.6-Opus (reasoning). Trained via Unsloth.
Runs locally on 16GB in 4-bit or 32GB in 8-bit.
Model: huggingface.co/Jackrong/Qwen…
88
227
2,741
208,716
BugUnstuck retweeted

Mar 30
Bug bounty
Mar 30

Name a huge scam.
12
12
165
17,290
BugUnstuck retweeted

Mar 28
My dear front-end developers (and anyone who’s interested in the future of interfaces):
I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept):
Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
1,335
8,196
64,988
24,003,982
Mar 29
Send us a target.
We’ll run it through BugUnstuck and give you an attack surface recon result set to compare against your existing tooling.
Same target.
Same objective.
See what coverage delta looks like.
1
42