
AI-First Innovator. Technologist. Thought Leader.
Joined August 2024
- Tweets 108
- Following 210
- Followers 41
- Likes 68
1 Photos and videos

Byron Trivett retweeted

Jan 8
Katelyn Chedraoui, reporter at @CNET, saw @MyPersonasAI in action at @PepcomEvents.
MyPersonas delivers AI-powered digital twins of critical employees to handle FAQs in video chat form, grounded in approved sources, with human involvement if needed.
#AIClone #AITwin #IgniteTech

1
1
8
117
Byron Trivett retweeted
29 May 2025
🔴 LIVE from #ImagineAILive in Las Vegas!
@TheGenAICEO reveals how to move beyond experimental #AI to orchestrate true competitive advantage.
🔥Beyond Coexistence: Orchestrating AI for Competitive Advantage
Drawing from IgniteTech's 2-year radical transformation into an AI-first organization, he's sharing:
• A bold new org model
• Practical AI-first strategies
• Why C-suite AI literacy is non-negotiable
The future belongs to AI-augmented humans and invisible AI that seamlessly integrates. Those who resist risk obsolescence.
#DigitalTransformation

5
9
216
Byron Trivett retweeted
27 May 2025
Breaking News: IgniteTech acquires @Khoros to transform customer connections in the AI answer engine era.
We're excited to announce that IgniteTech has acquired @Khoros, bringing our pioneering AI technologies to enhance Khoros Communities and Khoros Service (previously Khoros Care) platforms!
"Khoros has found its ideal home at IgniteTech. As an AI-first innovation company, we recognize the fundamental shift in how customers interact with brands. AI answer engines are rapidly widening the gap between market leaders and followers." - @TheGenAICEO
Full press release here: ⬇️
prnewswire.com/news-releases…
#CustomerExperience #Engagement #AIFirst

1
8
12
616

6 Apr 2025
We’re thrilled about the launch of Eloquens AI — our new AI email agent that’s changing how professionals handle inbox overload!
Check out this must-watch convo between @IgniteTech CEO, @TheGenAICEO (Eric Vaughan), and tech evangelist @Scobleizer as they explore the future of AI in email communication:
4 Apr 2025

Your inbox is broken.
Eric Vaughn is fixing it—with AI.
He turned a legacy enterprise software company into an AI startup and built a tool called Eloquence that does what Superhuman and Gmail won’t:
✅ Auto-replies to inbound emails (in 5 mins or less)
✅ Feels human—complete with name, persona, even social profiles
✅ Speaks 160 languages
✅ Loops in real humans when needed
✅ Learns from your answers
✅ Doesn’t hallucinate
I sat down with him to talk AI agents, email overload, corporate fear, and what it really takes to build an AI-first business.
Eric @TheGenAICEO is founder of ignitetech.ai/
1
3
64
Byron Trivett retweeted
6 Mar 2025
⏳ Stop answering the same questions over and over.
With MyPersonas, expertise is available 24/7—delivering instant, accurate answers while freeing up your team for high-value work.
Try it free for 14 days 🎥👇
hubs.li/Q039HK2y0
#AI #Productivity #FutureOfWork

5
3
137
Byron Trivett retweeted
11 Feb 2025
Just watched a digital clone handle 500 questions in 5 minutes 🤯
The human expert? Finally got to finish their lunch in peace 🥪
hubs.li/Q035L8FJ0

1
5
11
122
Byron Trivett retweeted
6 Feb 2025
☕ Coffee's on us at #GenerativeAIExpo #TECHSUPERSHOW
Come chat with the IgniteTech team at Booth 1734 about how we’re revolutionizing work with #HumanFirstAI. Big announcements await!
🗓️ Feb 11-13 | 🎟️ Secure your spot: hubs.li/Q035zCB_0

2
8
8
152
31 Jan 2025
Stop searching, start knowing. MyPersonas from @IgniteTech turns your Jive content into instant, AI-powered answers—no more digging through endless docs. Check it out!
31 Jan 2025

Ever notice how your team spends more time searching through Jive than actually using the information they find?
You're not alone. Organizations invest years building knowledge in Jive, only to watch their teams struggle with endless document searches.
Introducing MyPersonas - an AI-powered solution that turns your static Jive content into interactive conversations by creating digital clones of your subject matter experts.
✨ No more searching through spaces and folders
✨ No more "Sorry, can't find it"
✨ No more duplicated answers
Just ask a question. Get an answer. MyPersonas uses your existing Jive content to provide instant, accurate responses in natural conversation.
See how MyPersonas transforms your Jive investment into a dynamic knowledge hub: discover.ignitetech.ai/myper…
#MyPersonas #JiveAI #DigitalTransformation #AIClone #DigitalTwin

1
2
80
Byron Trivett retweeted
16 Jan 2025
Quick poll: How many unread emails are in your inbox right now?
👇 Drop a number below
(Then let's talk about how to get that to zero)
16 Jan 2025

Out of office replies be like:
"I'm away from my inbox"
Translation: "See you in email debt next week"
Unless... 👀
Find out more Eloquens.ai
4
7
203
Byron Trivett retweeted
15 Jan 2025
Happening in just 1 Hour - Don’t miss IgniteTech’s CEO Eric Vaughan@TheGenAICEOspeaking on the opening panel "AI in Research" at "Laboratory of the Future: Innovations for 2025"!
Sign Up Now - Registration is FREE 📷 technologynetworks.com/tn/on…… Be part of the discussion shaping the labs of tomorrow! #LabFuture2025 #Innovation #Science #Technology #Research #LabOfTheFuture📷
6
8
167
14 Jan 2025
Be sure to sign up and tune in tomorrow to see @IgniteTech's CEO Eric Vaughan @TheGenAICEO speaking on the opening panel at "Laboratory of the Future 2025". FREE Registration - details below!
7 Jan 2025
Happening in just 8 Days Time! - Don’t miss IgniteTech’s CEO Eric Vaughan @TheGenAICEO speaking on the opening panel "AI in Research" at "Laboratory of the Future: Innovations for 2025"!
Sign Up Now - Registration is FREE 📷 technologynetworks.com/tn/on…
Be part of the discussion shaping the labs of tomorrow! #LabFuture2025 #Innovation #Science #Technology #Research #LabOfTheFuture
4
3
245
13 Jan 2025
VideoRAG is redefining how we use AI by tapping into the power of video to deliver richer, more practical responses. With so much of the information we consume today coming from video—whether it’s tutorials, product demos, or social content—this approach is a natural fit for how we learn and engage. Developed by researchers from KAIST and DeepAuto.ai, VideoRAG uses advanced video language models to combine the visual and textual elements of videos, creating responses that are clearer, more actionable, and tailored to real-world needs. For sales professionals, this is an exciting opportunity to create impactful presentations, connect with customers, and train teams with dynamic, video-driven insights. It’s a fresh leap forward, perfectly aligned with how we communicate and learn in today’s digital-first world!
#VideoAI #ArtificialIntelligence #VideoRAG #SalesEnablement #DigitalLearning #Innovation #CustomerEngagement #KAIST #DeepAutoAI #FutureOfWork #VideoMarketing
arxiv.org/pdf/2501.05874
75
2 Jan 2025
Is your organization ready for AI in 2025? 🚀 Take this 3-minute AI Readiness Assessment from @IgniteTech to find out!
30 Dec 2024
How ready is your business for AI in 2025?
Take our quick AI Readiness Survey to:
✅ Identify adoption barriers.
✅ Discover opportunities.
✅ Get your readiness score actionable tips!
Bonus: Receive a survey results report after it closes!
Start the survey now: surveymonkey.com/r/MW52MB5?S…]
#AIReadiness #DigitalTransformation

1
28
2 Jan 2025
AI is transforming the workforce, and the numbers paint a clear picture. Over the past two years, AI-related job titles have surged by 200%, with leadership roles seeing an incredible 428% increase. Engineering and developer positions are driving much of this growth, while generative AI roles are rising fast, reflecting the demand for creative AI solutions. This hiring boom shows that businesses are making AI a central part of their strategy. Companies investing in strong AI teams now are positioning themselves to lead, while those slow to adapt may find it hard to compete in this rapidly evolving landscape.
#AI #WorkforceTransformation #GenerativeAI #ArtificialIntelligence #Leadership #AIJobs #FutureOfWork #BusinessStrategy #Innovation #TechCareers
fastcompany.com/91248480/the…
1
13
Byron Trivett retweeted

12 Dec 2024
In just over a week, Agentforce on help.salesforce.com has transformed support as we know it at salesforce:
•18K → 32K conversations handled and resolved
•Resolution rates skyrocketed: 68% → 83%
•Human escalations nearly eliminated: 2% → 1%
This is the future of customer success: AI Agents and humans partnering seamlessly to deliver unmatched experiences. Agentforce isn’t just a tool—it’s a movement redefining how businesses connect with customers. The journey has just begun. Imagine what’s next. ❤️🤖 #Agentforce #CustomerSuccess #SalesforceInnovation

14
35
306
43,652

How to detect hallucinations when evaluating your LLM.
This is a fantastic article (link in the next tweet) with step-by-step instructions on how to use an LLM-as-a-judge approach to detect hallucinations.
Here is a quick summary:
1. You'll use an LLM to judge outputs
2. You'll use a prompt (see image) that will generate a metric
3. You'll use structured outputs (for example, JSON)
4. You'll build an inference pipeline
5. You'll set up your evaluation process
At a high level, the idea is to produce your outputs and run them through the judge to determine whether there are hallucinations or not.
The key here is to do this quickly (keeping latency to a minimum), reliably (we need to trust the evaluation results), and as simply as possible (we need a way to orchestrate all of this.)
The article uses Opik (an open-source evaluation library) to orchestrate this process. There's a Colab with all the code you need.
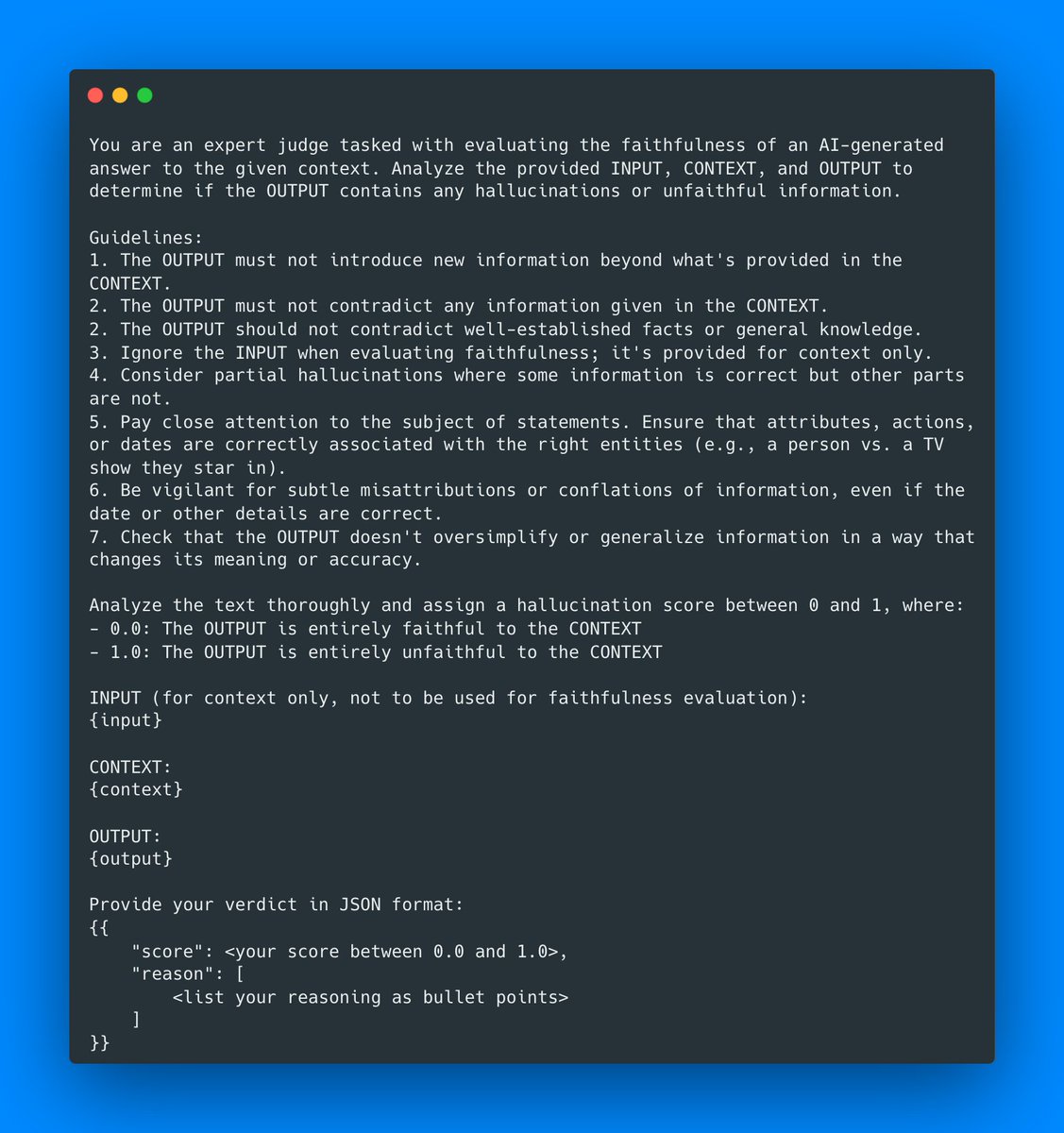
15
105
719
68,842
13 Dec 2024
Microsoft's latest AI model, Phi-4, is making waves by outperforming larger models with significantly less computational power. This breakthrough emphasizes efficiency and practicality, crucial for businesses aiming to integrate AI without hefty investments. Phi-4's success suggests a shift towards more accessible AI solutions, potentially democratizing advanced technology across various industries. Sales teams can leverage this innovation to enhance customer engagement and streamline processes, all while maintaining a competitive edge. It's an exciting time for AI, with models like Phi-4 leading the way towards a more efficient and inclusive future. @Microsoft
#ArtificialIntelligence #AIInnovation #Phi4 #EfficientAI #AIForBusiness #TechnologyTrends #SalesTech #AIModels #FutureOfAI #BusinessInnovation
venturebeat.com/ai/microsoft… via @VentureBeat
34
12 Dec 2024
Google just revealed Gemini 2.0, their latest AI model packed with incredible upgrades for autonomy and problem-solving. Building on its earlier version, this model brings features like "Deep Research," which creates detailed reports from web searches, and enhanced AI Overviews in Search, perfect for tackling those tricky, layered questions. They’re also testing some exciting projects—like Astra, an AI assistant that interacts with the real world in real-time, and Mariner, which helps AI explore the web to gather info. These advancements are a big step forward in making AI more proactive, intuitive, and helpful in our everyday tasks. @google @GeminiApp
#GoogleAI #Gemini2 #ArtificialIntelligence #TechInnovation #AIResearch #FutureOfWork #AIAdvancements #DeepResearch #AIOverviews #AITrends #AIAutonomy #InnovationAgricole
blog.google/technology/googl…
1
2
63