
Father of 5️⃣ | Urologist @laheyuro | Associate Prof | MIS robotic onc | 🎸| Personal finance rants | Workplace efficiency enthusiast | Founder @wellprept 👈
Joined October 2012
- Tweets 17,412
- Following 5,833
- Followers 22,032
- Likes 37,210
1,494 Photos and videos













Pinned Tweet

Jan 27
Drowning in bureaucracy & EHR hell?
Step into the OR.
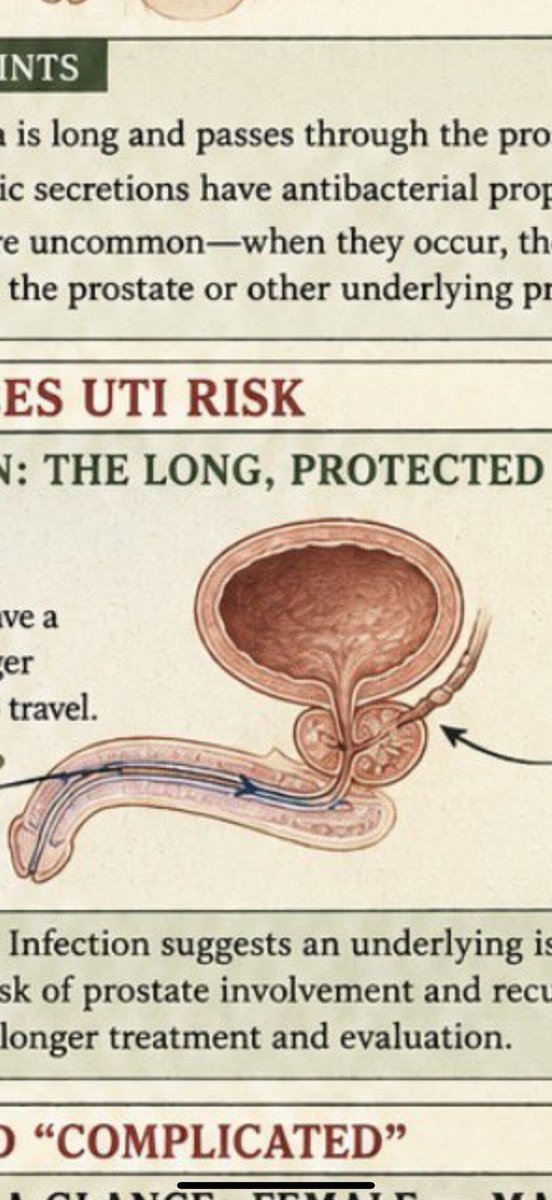
Subtle and still surprising varations in renal hilar anatomy. The ureter peristalsing like clockwork. The course of the obturator nerve...
Unchanged since the dawn of surgery.
Untouched by spreadsheets. Untouched by admin.
It's breathtaking.
Lucky us.
9
12
133
24,998
𝙳𝚊𝚟𝚒𝚍 𝙲𝚊𝚗𝚎𝚜 retweeted
Agree with @Cacciamani_MD a tweetorial probably wasn't the smoothest option for a reply.
Contamination is a strong argument (that the frontier models might have already "known" the questions from their training set). But the authors already conceded this.
The RCQ not being public is a legitimate knock. You can't audit queries you can't see.
The "RCQ was only added after peer review" line is framed as a scandal, but I read it the other way. Reviewers said the contaminated benchmarks weren't enough, the authors built a clean blinded one in response. That's peer review working the way it was inteded to work.
The conflict-of-interest accusation is interesting, and if documented it's serious. But it's coming from OE, the party that "lost" in this paper so it sounds like sour grapes... who knows...
The most uncomfortable result is that free Google AI Overview scored as well as or better than OpenEvidence on real physician queries judged by blinded clinicians. They don't seem to have an answer to that.
2
6
708
𝙳𝚊𝚟𝚒𝚍 𝙲𝚊𝚗𝚎𝚜 retweeted

A twittorial? Ironically, you at @EvidenceOpen do not seem very “open” to “evidence” after all.
Why not submit a letter to the editor addressing these concerns directly? Present the methodological issues, challenge the study’s conclusions, and support your arguments with rigorous, reproducible evidence
That is how science advances: through open debate and critical appraisal!
1
12
1,308
OpenEvidence responds….
🍿

Rigorous evaluation of medical AI is good for everyone, and we welcome it. Counter to a half-dozen independent studies from institutions such as the Mayo Clinic that were highly positive on OpenEvidence—a lone paper now purports to show that generalized AI beats specialized clinical AI (@UpToDate, @EvidenceOpen). The paper has a massive undisclosed conflict of interest and irredeemable methodological flaws.
Behind the scenes: The study authors run a competing in-house medical AI at their hospital, and asked OpenEvidence for an API to power it — including rights to build a "competing product" with OpenEvidence's own API. OpenEvidence declined. Then, this paper coincidentally appeared.
Point-by-point, looking closely at the datasets used in the study, the disingenuous and fatal flaws become immediately apparent 🧵.

2
1
11
3,102
𝙳𝚊𝚟𝚒𝚍 𝙲𝚊𝚗𝚎𝚜 retweeted

25 Jul 2025
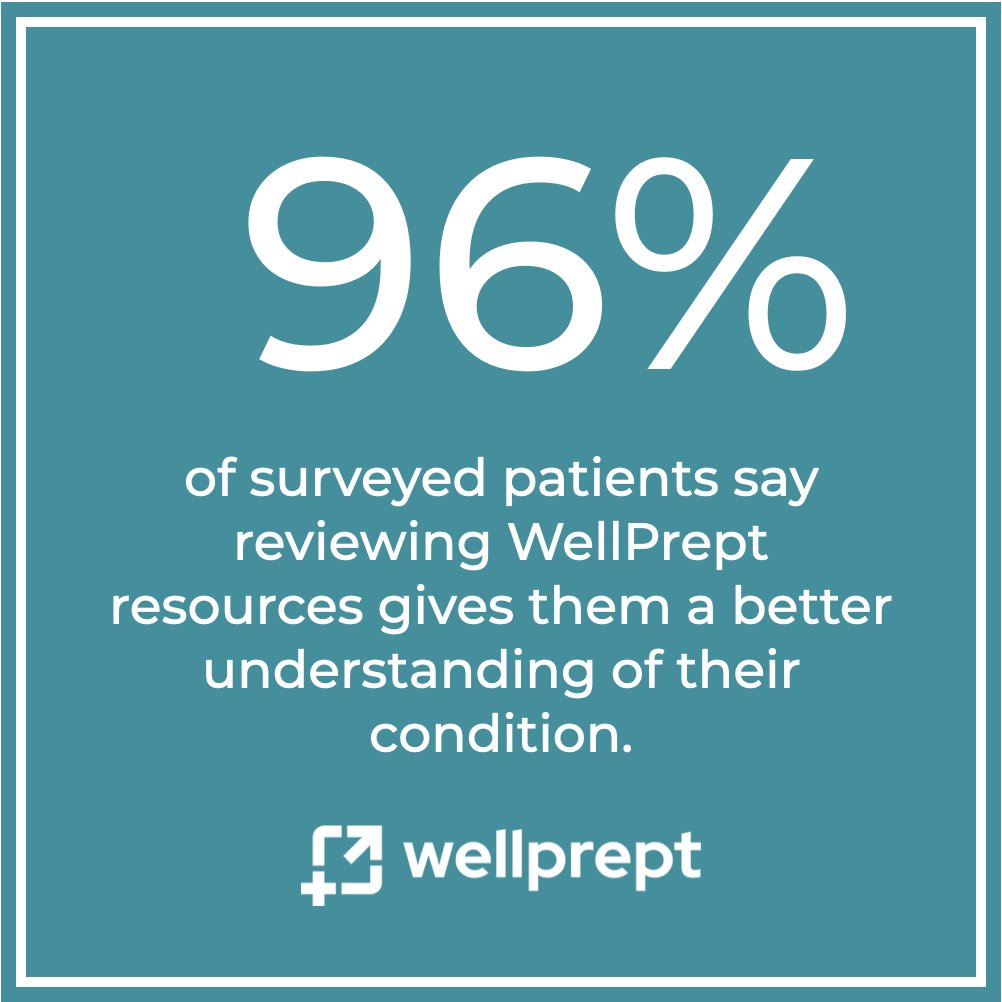
What happens when patients better understand their conditions?
The relationship with the care team becomes a partnership. Outcomes improve.
Fixing patient experience fixes everything.
2
4
1,600
Jun 13
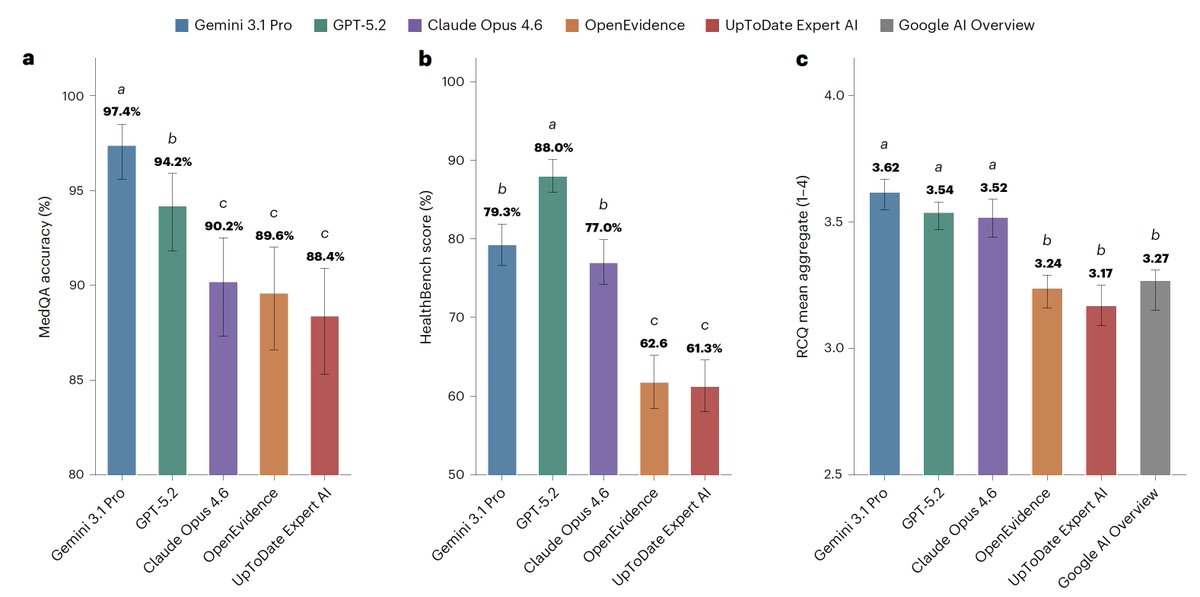
This is one of the more important AI-in-medicine papers I've read in a while (and I read the whole paper), and the result is uncomfortable for anyone betting on specialized clinical tools. NYU Langone group put OpenEvidence and UpToDate Expert AI head to head against GPT-5.2, Gemini 3.1, and Claude Opus 4.6. The frontier general-purpose models won. Every benchmark, every dimension.
(Disclosure: I wrote this post, then used AI to clean it up and make it read better. The ideas are mine)
The part that should get your attention: they included free Google AI Overview as a control, and it scored as well as or better than both clinical tools on real physician queries. The specialized answer engine performed about the same as the summary that pops up when you Google a question.
Now, credit where due. Building a HIPAA-compliant evaluation off 100 real clinical queries with 12 blinded physician raters is a serious undertaking, and they were honest about their own limits, which I appreciate. They flag that HealthBench is an OpenAI benchmark that GPT then won while also sitting on the grading panel, so they tell you to discount it and treat it as supplementary. That's the right call.
But here's where I'd put the asterisk. The frontier models were queried through APIs (computer to computer interfaces). The clinical tools were queried manually through the browser interfaces (like you use it), with all the hidden prompts and formatting that comes with that. OpenEvidence's weakest score was clarity, not correctness. So is the underlying model actually worse, or is the wrapper just presenting answers in a way clinicians liked less? The study can't separate those, and that distinction matters a lot for what we conclude.
One thing worth noting: OpenEvidence isn't something clinicians pay for. It's free for verified docs, same as Doximity's tools, though some health systems pay for BAAs. So this isn't really a "you're wasting subscription dollars" story. It's a "the specialized layer doesn't appear to add accuracy over a frontier model" story, which is the more interesting claim anyway.
What I'm comfortable saying: the specialized clinical wrapper doesn't appear to produce better answers than a frontier model, and might cost you on clarity. What I'm not ready to say: that domain-specific tuning is inferior as an approach. The authors don't claim that either.
This is a snapshot of a field that's moving fast, and the frontier models have already been updated since the study was done. But if you're a health system making decisions here, it's worth a close read.
Jun 12

For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
10
8
37
6,419
Jun 12
😂🤣
Jun 12

I cancelled my $10/mo Calendly subscription and vibe coded my own with Fable for $12,000
1,624
Jun 12
Please repost for visibility.
Jun 11

@AnthemBCBS My staff is trying to get a single case agreement for a patient.
Have collectively spent >4 hours trying to get someone on the phone, still have yet to speak to a live agent.
The only humans who answer say "that's not my department," transfer to dead end numbers.
A patient is at stake. Please help.
3
6
2,783
Jun 11
Command-shift-G on a mac
Paste the file or folder path
🎉brings you right to it
5
1,094
Jun 11
Has anyone else had similar problems dealing with @AnthemBCBS ?
Jun 11
@AnthemBCBS My staff is trying to get a single case agreement for a patient.
Have collectively spent >4 hours trying to get someone on the phone, still have yet to speak to a live agent.
The only humans who answer say "that's not my department," transfer to dead end numbers.
A patient is at stake. Please help.
2
2
2,713
Jun 6
Mark Cuban for president
Jun 6

All doctors are underpaid.
4
3
68
12,031
Jun 4
Most second opinions end the same way: I almost always recommend less than the patient was told elsewhere.
Other than removing cancer or clearing a blockage, doing less tends to serve patients better.
Took me years to trust that.
4
1
29
5,161
May 31
Thoughtful review of the PROTEUS trial by @DrSpratticus
First, real credit to the investigators. Pulling off a phase 3 perioperative RCT in localized prostate cancer is a massive undertaking, and easy to forget when you're critiquing from the armchair (mea culpa, I don't run trials like this).
That said, Daniel is essentially pointing out (I think 🤪) that PSMA-PET catches BCR so early that "metastasis-free survival" is really just biochemical recurrence in disguise, and EFS is a lousy surrogate for OS (see his tweetorial for the reasons).
The part that confuses me most: this isn't compared to standard of care. We don't give ADT with prostatectomy. So what are we supposed to do with this information?
nejm.org/doi/full/10.1056/NE…
@DrSpratticus @adamkibel_uro @uretericbud @daviesbj
May 31

#ASCO26
The PROTEUS trial results are now online...buckle up as we wait to see the full presentation. This is going to be a trial that is likely highly controversial until the full results are published.
Some may call this a homerun, others may call this the largest negative trial @ASCO 2026. Up to you to interpret!
@urotoday @EricTopol @DrChoueiri @neerajaiims @ASCO @US_FDA @NCCN @myESMO @ASTRO_org @PCF_Science @declangmurphy @mcuban
4
8
40
10,182
May 29
I propose annual mandatory ECG recertification for physicians.
And I immediately veto my own proposal.
May 29
We have to get BLS certifications, laser certifications, fluoro certifications.
And recertify... and recertify...
And yet my inbasket fills up with preop ECG reports, which I am now wholly unqualified to interpret at this point.
6
3,222
May 29
We have to get BLS certifications, laser certifications, fluoro certifications.
And recertify... and recertify...
And yet my inbasket fills up with preop ECG reports, which I am now wholly unqualified to interpret at this point.
4
2
25
7,648
May 29
I just learned something new today.
Either I'm late to the game (likely), or perhaps other Urologists also don't know this.
Angiotensin II receptor blockers (ARBs) as a class, modestly suppress PSA levels.
Worth knowing.
(thought to downregulate androgen receptor protein expression)
8
9
62
10,460
May 28
Show up to a robot console to start my day to find the velco straps on the masters secured in tight loops.
My immediate thought. I wonder who used this yesterday...
3
696
May 23
Best basic description of how AI works

1
18
6,996
May 21
This is kind of a big deal
May 20
Until now, physicians using AI in clinic had to assemble the patient’s context themselves. Allergies, comorbidities, medications, prior procedures, copy-pasted in from the chart.
Today we’re announcing a partnership with @CedarsSinai. OpenEvidence now works directly inside Epic, drawing on the patient’s full record and interpreting the medical literature through the lens of that specific patient.
Cedars-Sinai is the first academic health system to deploy patient-aware clinical intelligence at enterprise scale. The clinician asks a complex question in natural language. The answer reflects both the best available evidence and the patient in front of them.
Patient data is never stored after the clinical session or used for any other purpose.

16
46
597
255,637