
Exploring how Machines Learn.
Joined October 2021
- Tweets 374
- Following 2,138
- Followers 194
- Likes 514
94 Photos and videos










Pinned Tweet

23 Apr 2022
Machine Learning :
Divide & Rule works well in ML too.
All Classification Algorithms doesn't easily classify MultiClass Classification problems naturally like binary. Knn like algos work well in both the cases.
Continue ...
#MachineLearning #Python #AirdropCrypto #javascript
1
11
7
Discover K-Means Clustering & its variants (K-Means , K-Medoids, PAM) in action! See how Amazon, Netflix, Walmart & banks use clustering to find patterns, optimize recommendations & segment customers.
Full guide: substack.com/@chandraprakash…
#LLMs #DeepLearning #Agents #Final #AI
1
2
123
8 Nov 2025
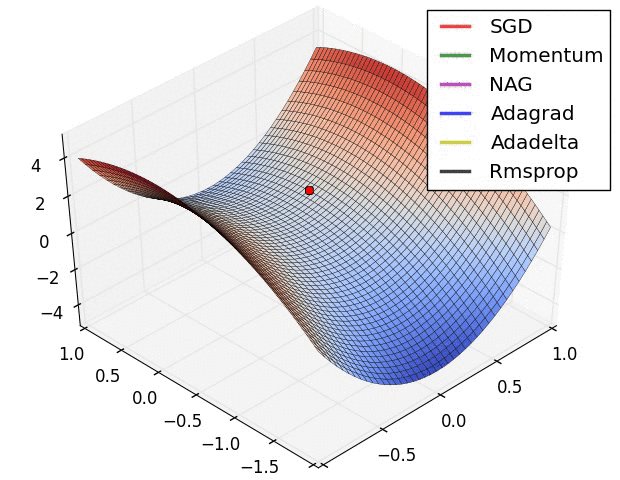
🚀 Deep Learning Part — 9: Optimizers Are What You Need!
Optimizers are the unsung heroes of neural networks —
they decide how weights learn, how fast we converge, and how smooth training feels.
From Gradient Descent → Adam, here’s what’s inside 👇
🔹 GD : the classic mountain climber
🔹 SGD : the quick, noisy learner
🔹 SGD Momentum : smoother, faster convergence
🔹 NAG : looks ahead before stepping
🔹 AdaGrad / RMSProp / Adam : adaptive masters of learning rates
We also explore saddle points, momentum, and how adaptive optimizers help models escape traps and reach global minima.
🧠 Dive into the full article on Medium:
🔗medium.com/towards-artificia…
#DeepLearning #MachineLearning #AI #Optimization #NeuralNetworks #Research #Education #Adam #SGD #Momentum #LearningRate #MLCommunity @GoogleDeepMind @OpenAI @deepseek_ai @LinkedIn @DeepLearningAI @X @grok
1
2
219
7 Nov 2025
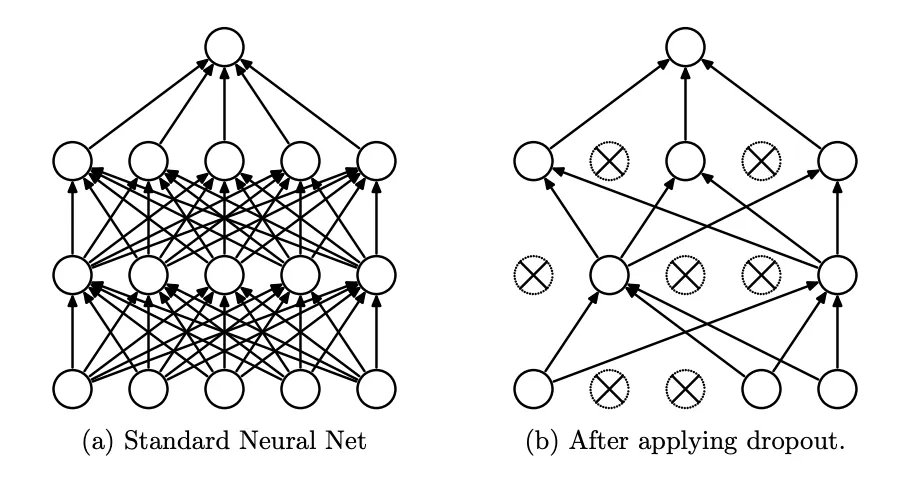
🚀 Deep Learning — 7: Optimize your Neural Networks through Dropouts & Regularization
Deeper networks are powerful, but they can easily overfit.
Here’s how dropout, L₁/L₂ regularization, and architecture design can make your models more robust & generalizable.
Medium Blog: medium.com/towards-artificia…
#medium @Medium @Linkedin @DeepLearningAI @OpenAI @X @grok @GoogleDeepMind @Google #NeuralNetworks #Python #JavaScript #Regularization #BatchNormalization #Dropouts #YannLeCunn #Hinton
1
2
122
5 Nov 2025
🚀 Just deployed my Enhanced MNIST Digit Recognizer: trained with PyTorch & deployed on Hugging Face Spaces!
✅ 5-Fold CV with OneCycleLR AMP
✅ >99.4% accuracy
✅ Draw or upload digits live 🖊️
Try it here 👇
🔗 huggingface.co/spaces/chandu…
#DeepLearning #PyTorch #AI #HuggingFace #Gradio #MLOps @OpenAI @GoogleDeepMind @Google @netflix #MNIST
1
2
73
4 Nov 2025
⚡ Deep Learning — Part 6: Activation Functions in Neural Networks
From Sigmoid → tanh → ReLU → Leaky ReLU → GeLU,
activation functions have powered how networks learn & converge.
🧠 Learn how:
• Sigmoid / tanh caused vanishing gradients
• ReLU sparked the deep learning era
• Leaky ReLU fixed dead neurons
📖 Read here →
medium.com/towards-artificia…
#DeepLearning #AI #MachineLearning #NeuralNetworks #ActivationFunctions #ReLU #GeLU #Backpropagation #MLCommunity @OpenAI @GoogleDeepMind @deepseek_ai @DeepLearningAI
1
2
64
4 Nov 2025
🧠 Deep Learning — Part 5: How to Train Your Neural Networks
Training a neural net = math structure intuition.
From the Perceptron to deep multi-layer models — this post breaks down:
🔹 Forward & Backward Propagation
🔹 Chain Rule Memoization (Backprop essence)
🔹 Mini-Batch SGD for faster, efficient learning
At its core,
Backprop = Chain Rule Memoization
📖 Read here → medium.com/towards-artificia…
#machinelearningprojects #DeepLearning #NeuralNetworks #GenerativeAI #LLMs #MLOps #artificial_intelligence #AGI #Grok #OpenAI @GoogleDeepMind
1
2
66
20 Oct 2025
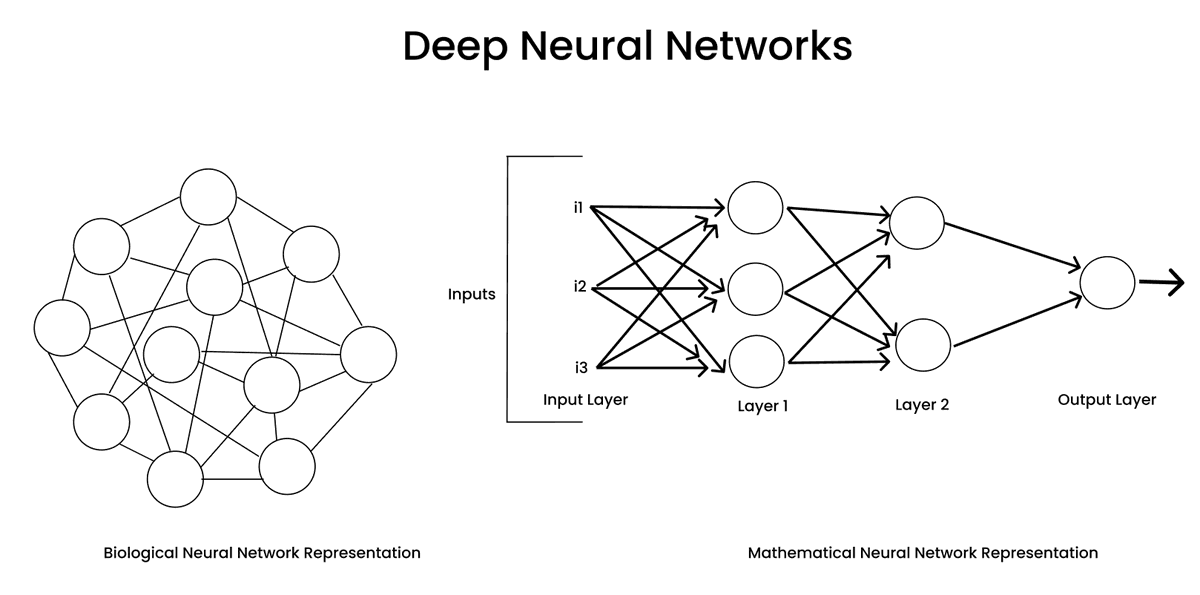
🚀 Deep Learning: Multi-Layered Perceptron (MLP)
🧠 Stacking neurons — the foundation of Deep Learning.
A single neuron (Perceptron) learns simple patterns.
Stack millions and suddenly you have the power to learn speech, vision, and language.
Here’s why 👇
1️⃣ MLPs connect multiple perceptrons → forming a Neural Network.
2️⃣ Each neuron learns a part of the pattern; together, they approximate any complex function.
3️⃣ Activation functions (ReLU, Sigmoid, Tanh) make them non-linear — the secret sauce of deep learning.
4️⃣ Think of it like LEGO bricks 🧩 each layer adds shape & depth to what the model can learn.
From Linear Regression → Function Composition → Neural Intelligence.
No magic only math, pattern learning, and function optimization.
This is where Deep Learning truly begins 🔥
📖 Read full breakdown on my blog:
medium.com/towards-artificia…
#DeepLearning #MLP #NeuralNetworks #AI #MachineLearning #Research #MLPs #DeepNeuralNetworks #BackPropagation #ReLU #ActivationFunctions #Medium @towards_AI
1
2
179
18 Oct 2025
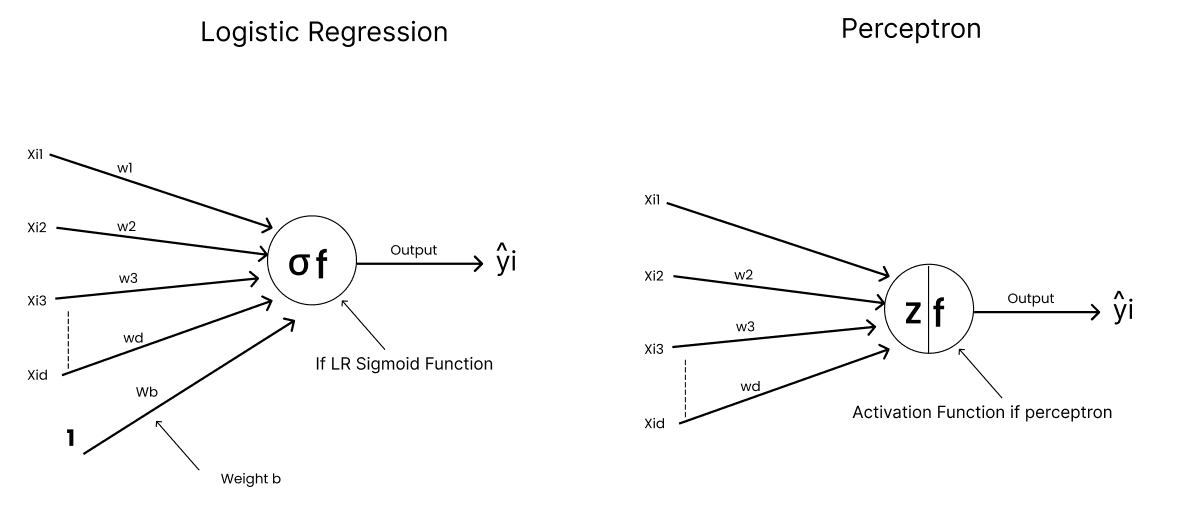
🤯 Perceptron vs Logistic Regression, the OG connection that started Deep Learning!
Before Transformers and GPUs, Deep Learning began with one neuroscience-inspired question:
“Can we mimic human behavior in machines?” 🧠
From that spark came the Perceptron, a single “neuron” model.
And around the same time Logistic Regression emerged from statistics.
Different fields => Same math =>Same intuition.
💡Both compute 👇
z=wTx b
But here’s the difference that changed everything:
🧩 Perceptron: Step Function → 0 or 1 → acts like a switch 🕹️
🎚️ Logistic Regression: Sigmoid → values between 0 and 1 → acts like a dimmer 💡
That one small change (Step → Sigmoid) turned rigid decisions into probabilistic reasoning and gave rise to Neural Networks 🔥
So next time you run a deep model, remember:
It all started from a simple neuron trying to fire correctly ⚡
📖 Read the full story →
medium.com/towards-artificia…
#DeepLearning #AI #MachineLearning #Perceptron #LogisticRegression #NeuralNetworks #MLP #ArtificialIntelligence @towards_AI @OpenAI #JavaScript #LLMs #RAGs
1
2
84
17 Oct 2025
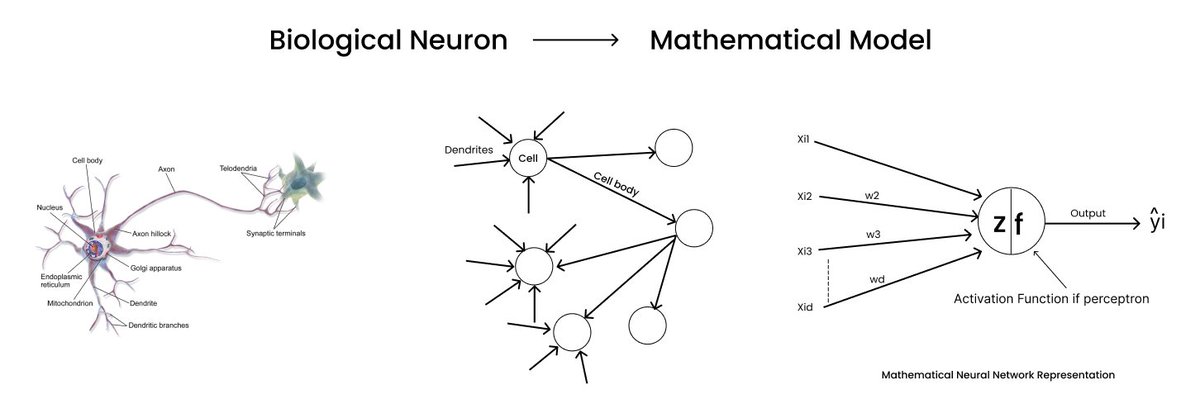
🧠➡️🤖 Ever wondered how the human brain inspired #DeepLearning?
In my latest blog, I explore how a single biological neuron became the blueprint for artificial neural networks from dendrites to the Perceptron!
Read here 👉
medium.com/towards-artificia…
@towards_AI @OpenAI @DeepLearningAI #NeuralNetworks #Neuron #ActivationFunctions #Agents #AgenticAI #LLMs #Grok
2
1
2
90
16 Oct 2025
Exploring the Origins of Deep Learning: From a Single Neuron to Modern AI
Did you know that deep learning began with a single neuron in 1957? 🧠
In my latest blog, I delve into the fascinating evolution of deep learning, tracing its roots from Frank Rosenblatt's Perceptron to the sophisticated neural networks driving today's AI advancements.
🔍 Key Highlights:
1957: Introduction of the Perceptron, the first neural network model capable of learning.
1970s-80s: Challenges and breakthroughs leading to the development of multi-layer networks.
2012: The resurgence of deep learning with the success of AlexNet in image recognition.
This journey not only showcases technological progress but also underscores the transformative impact of deep learning on industries and society.
👉 Read the full article here: pub.towardsai.net/deep-learn…
1
1
2
85
14 Oct 2025
🔥 Built an AI app that predicts customer subscriptions with a Decision Tree! 🚀
💡 Trained a model on banking data, balanced with SMOTE, and hit 89% accuracy & 0.87 F1-score. 📊
Visualized the tree feature importance with Plotly. 🌐
Wrapped it in a sleek Flask app with TailwindCSS UI for real-time predictions.
Why it’s cool:
✅ Users input data, get instant subscription likelihood confidence.
✅ Actionable insights for businesses.
✅ Full-stack ML in one project!
Feel Free to Connect..!
#MachineLearning #AI #DataScience #Python #Flask #DecisionTree

1
2
86
8 Oct 2025
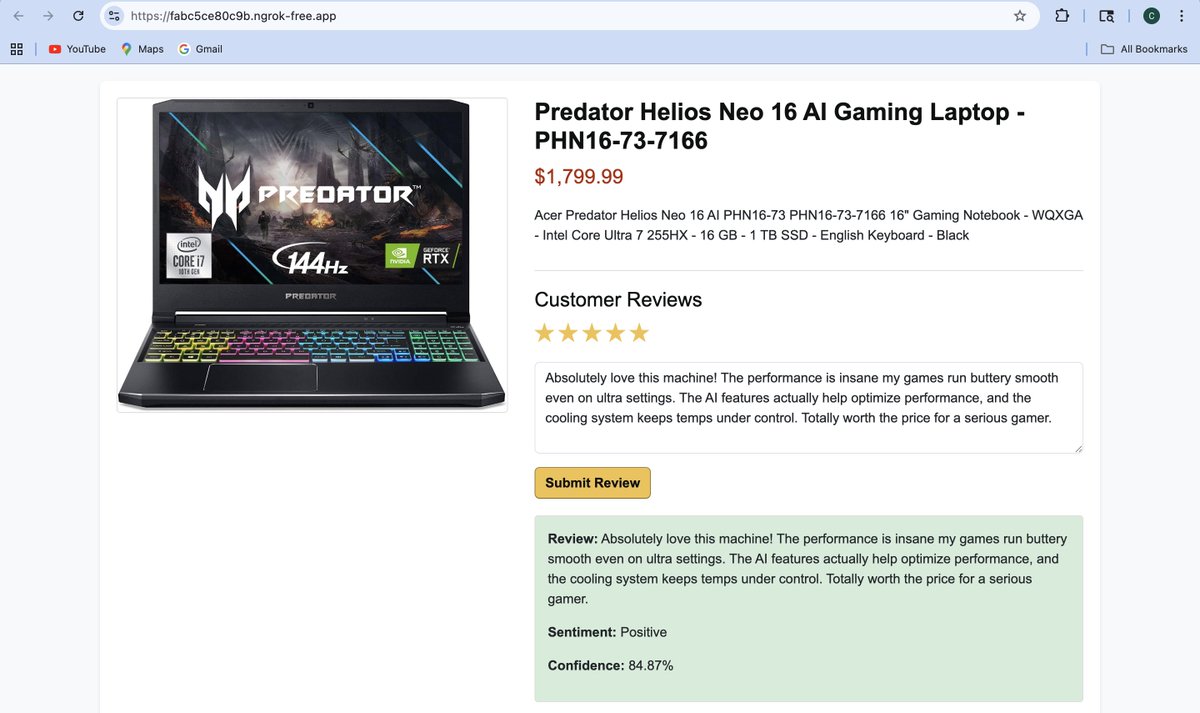
🚀 #SVM in Action: Sentiment Analysis meets Amazon-style UI! 🛒💬
Just built & deployed a full Amazon Review Sentiment System powered by Linear SVM, with an interactive web UI, all live from #GoogleColab via Flask ngrok.
🔍 Pipeline:
Data cleaned & prepped
TF-IDF features (unigrams bigrams)
LinearSVM (C=10) classifies with sharp boundaries
Metrics: Accuracy, Precision, Recall, F1
Real-time Amazon-like review interface
Public deployment (mobile-friendly!)
⚡️ Results:
~92–94% accuracy on balanced data
Sentiment confidence scores, just like Amazon
Old-school #SVM, new-school #NLP. Still the best at drawing razor-sharp boundaries between opinions.
1 notebook, 1 model, 1 click → live!
#MachineLearning #AI #DataScience #Python #Flask #Colab #ngrok @ngrokHQ @amazon @DeepLearningAI @Google #SVM #Kernels #evals #LLMs #DeepLearning #Algorithms
1
1
3
164
4 Oct 2025
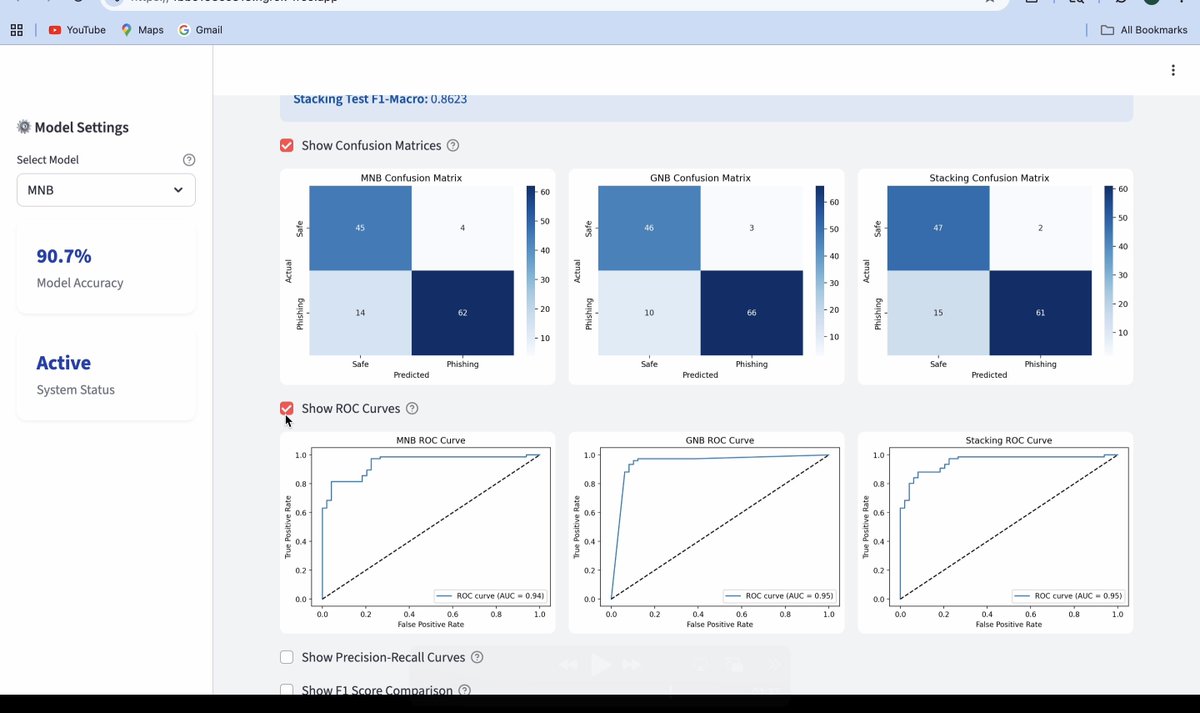
🚨 Phishing Shield AI: Catch phishing emails with Naive Bayes! 🛡️📧
Built a sleek Streamlit app that detects phishing emails using MultinomialNB, GaussianNB, and a Stacking Ensemble model. Lightweight, fast, and powerful! 💪
🔑 Features:
Smart preprocessing: TF-IDF keyword features message length
Handles imbalanced data with ADASYN
Tuned with GridSearchCV StratifiedKFold
Visuals: Confusion matrices, ROC/PR curves, F1-score in UI
Deployed via Streamlit ngrok for quick demos
💡 Why it matters: Naive Bayes proves simple algorithms can tackle real-world threats like phishing with clarity and efficiency.
Check it out for text classification, cybersecurity, or ML deployment inspo! 🚀
@OpenAI @Google #NaiveBayes #Probability #Attention #MachineLearning #DeepLearning #DataScience #JavaScript #100DaysOfCode #CyberSecurity #Python #Matplotlib @streamlit @ngrokHQ #GenerativeAI
1
2
150
3 Oct 2025
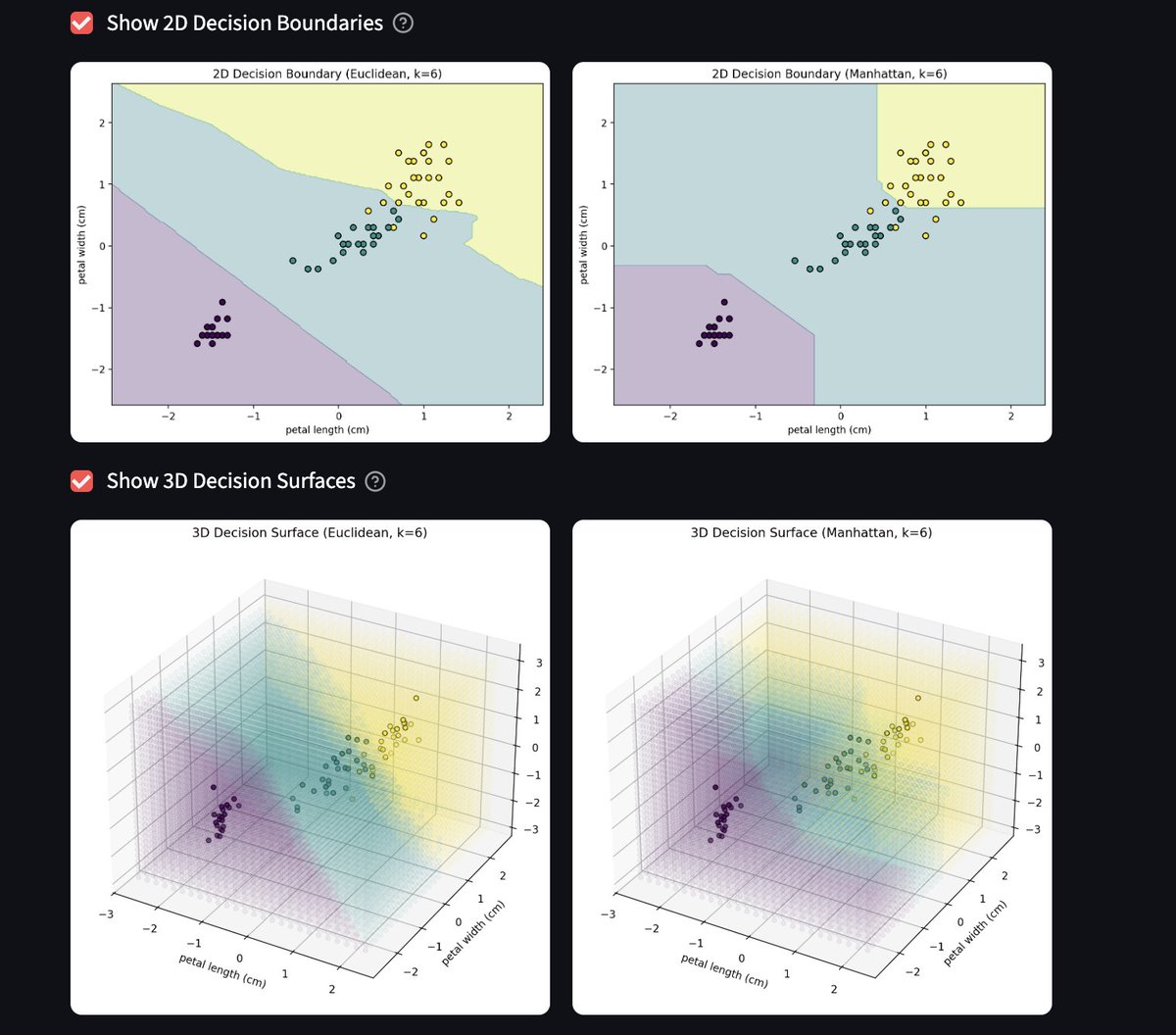
K-Nearest Neighbors in Action 🌺
Built an interactive Iris Classifier with Streamlit scikit-learn to show how even “simple” ML can shine:
🔹 K-NN with Euclidean & Manhattan metrics
🔹 10-fold CV for robust accuracy
🔹 Interactive sliders & visuals (decision boundaries, confusion matrices, pairplots)
Sometimes fundamentals > hype 🚀
#Python #DeepLearning @DeepLearningAI #NeurIPS2025 #CNN #ResNet #NeuralNetworks #LLMs #RAG @streamlit @ProjectJupyter
1
2
104
12 Sep 2025
🚀 Exploring MNIST with Dimensionality Reduction: Interactive Web App
I built a FastAPI app to visualize PCA, t-SNE, and UMAP on MNIST (3k–10k digits) in 2D & 3D.
🔍 Highlights
• UMAP 2D has the best clustering (Silhouette ≈ 0.35)
• PCA’s top 3 comps explain ~14.5% variance → data is non-linear
• t-SNE/UMAP preserve local structure (Trustworthiness ≈ 0.95)
🎨 Features
• Interactive Plotly 2D/3D scatter plots
• Scree & Silhouette charts (#ChartJS)
• Sleek #TailwindCSS UI
⚡ Runs in ~10–30 s on Colab A100; optimized for speed & stability.
Check it out, with different sample sizes, and share ideas for new datasets!
#DataScience #MachineLearning #DimensionalityReduction #PCA #tSNE #UMAP #MNIST #Python #FastAPI
1
1
2
93
12 Sep 2025
2️⃣ t-SNE : t-distributed Stochastic Neighborhood
🔹 t-SNE on MNIST
Non-linear embedding for local structure.
✨ Insights
• Clear digit clusters in 2D/3D
• Silhouette: 0.22 (2D), 0.15 (3D)
• Trustworthiness ~0.96
• Runtime ~23 s for 10k digits
💡 Great for visualizing neighborhoods — not ideal for new-sample inference.
#tSNE #MNIST #DimensionalityReduction #MachineLearning


1
1
2
73
12 Sep 2025
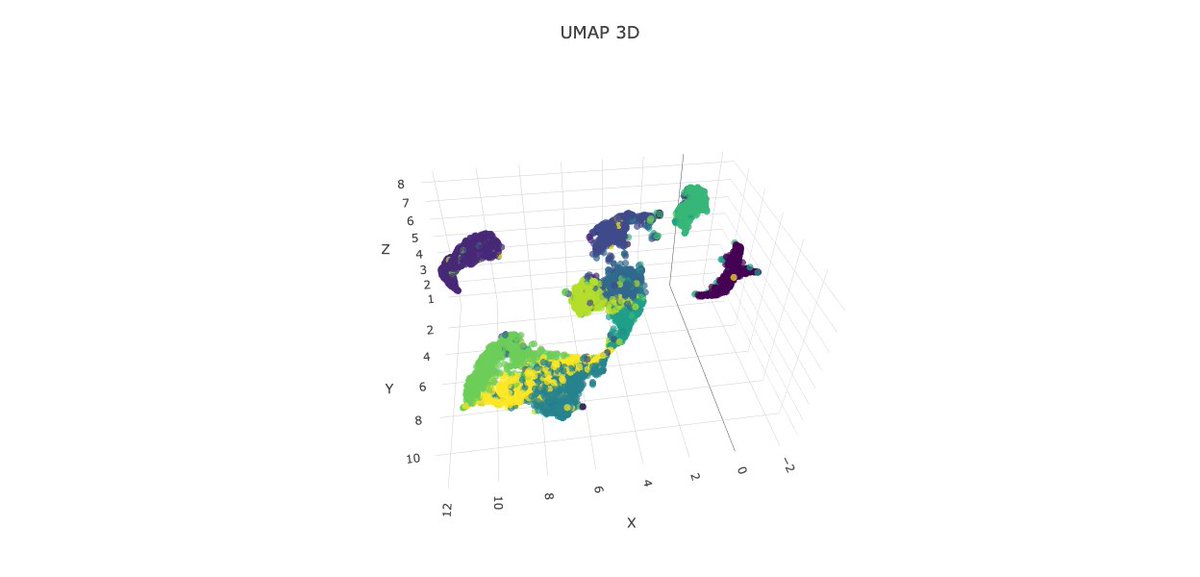
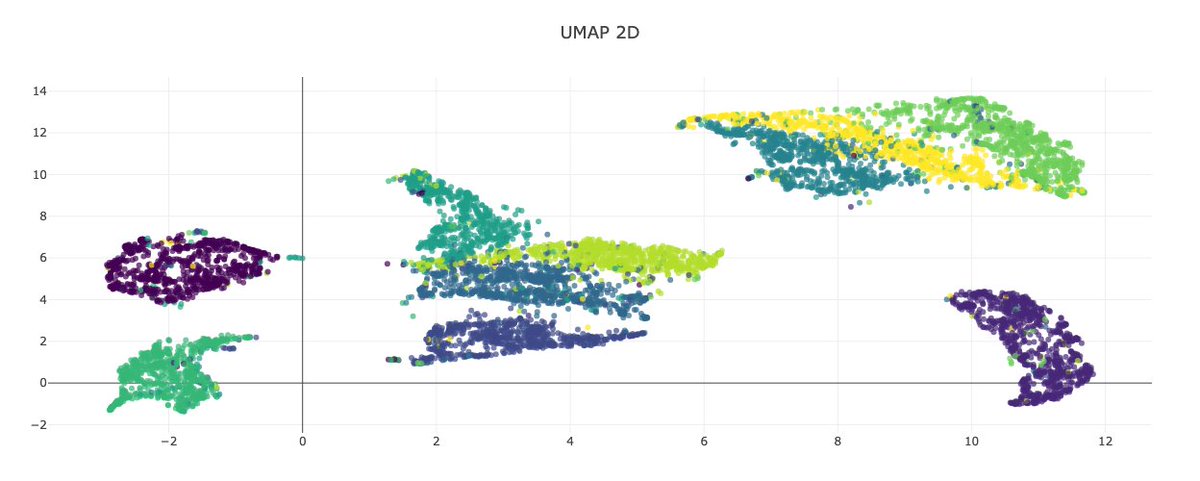
🔹 UMAP : Uniform Manifold Approximation and Projection
Balances local & global structure, scalable & robust.
✨ Insights
• Best clustering: Silhouette 0.35 (2D), 0.33 (3D)
• Trustworthiness ~0.95
• Runtime ~28 s for 10k digits
🏆 UMAP gives the clearest separation of digits while staying efficient.
#UMAP #DataScience #MachineLearning #MNIST
1
2
55