
رقم واحد صغير كفيل بجعل نموذج الذكاء الاصطناعي
عبقرياً.. أو غبياً تماماً يفشل في التعلم
📌في عالم تدريب الشبكات العصبية (Neural Networks)، يعتبر معدل التعلم (Learning Rate) هو الـ Hyperparameter الأهم والأخطر على الإطلاق. اختيار هذه القيمة يشبه المشي على حبل مشدود:
🔸إذا كانت القيمة كبيرة جداً : فالنموذج سيتحرك بقفزات واسعة وعشوائية، مما يجعله "يقفز" فوق نقطة النهاية الصغرى (Global Minimum) ويتذبذب دون استقرار أو تقارب.
🔸إذا كانت القيمة صغيرة جداً : فالنموذج سيتحرك ببطء شديد يستنزف الوقت والموارد، والأسوأ أنه قد يعلق في أول نقطة صغرى محلية (Local Minimum) ويفشل في الوصول لأفضل دقة.
هل واجهت من قبل نموذجاً رفض أن يتطور أداؤه وجمعت منحنيات التعلم فيه على قيم سيئة بسبب سوء اختيار الـ Learning Rate؟ شاركنا في التعليقات
#AI #DeepLearning #LearningRate #NeuralNetworks #DataScience #أكاديمية_اتصالاتي
6
575

Stop treating ML as tensor soup.
In our first workshop on Category Theory for Tiny ML in Rust, one idea became obvious:
Weight
Gradient
Loss
LearningRate
Prediction
They may all be numbers.
They are not the same thing.
Python lets you confuse them.
Rust lets you encode the difference.
Next workshop:
Build a Typed Tiny Neuron in Rust
We’ll start with raw f32, then rebuild it with Rust types until the compiler starts catching conceptual mistakes before runtime.
Input → Prediction → Loss → Gradient → Updated Model State
No category theory cosplay.
No framework magic.
No “just trust PyTorch bro.”
Just tiny ML, typed transformations, and executable structure.
Paris online
June 2, 18:00–19:00 CEST
Links in the first reply.

2
4
30
2,129

Jan 8
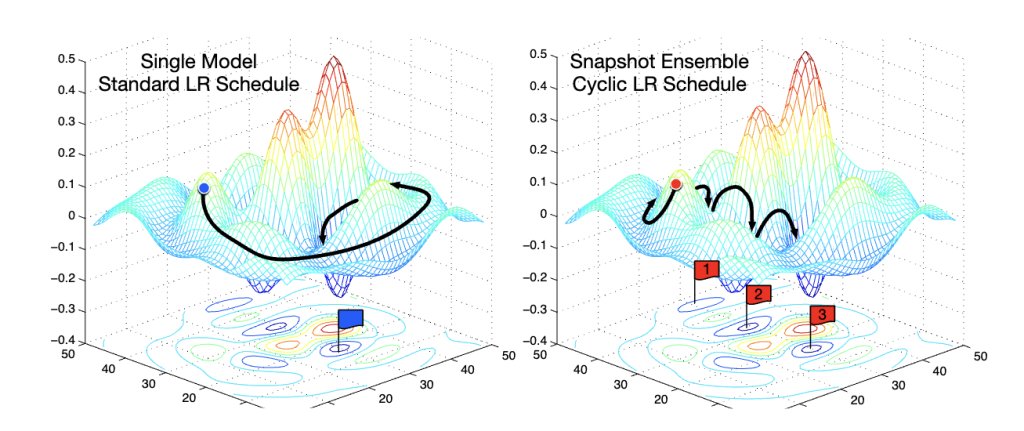
🧠 ML Interview Question: 𝐇𝐨𝐰 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐑𝐚𝐭𝐞 𝐒𝐜𝐡𝐞𝐝𝐮𝐥𝐢𝐧𝐠 𝐖𝐨𝐫𝐤𝐬 (𝐰𝐢𝐭𝐡 𝐏𝐲𝐓𝐨𝐫𝐜𝐡 𝐄𝐱𝐚𝐦𝐩𝐥𝐞𝐬)
📖 Article Link: aiml.com/how-learning-rate-s…
Choosing the ideal learning rate scheduler is one of the most overlooked but high-impact concepts in deep learning training. A poorly chosen learning rate can cause models to diverge, stall, or converge to suboptimal solution, even with the right architecture and data.
In this guide, we explain what learning rate scheduling is, why it works, and how to choose the right scheduler in practice.
🔍 What this article covers:
👉 What learning rate scheduling is and why static learning rates fail
👉 How different learning rate schedulers affect convergence speed and training stability
👉 when to choose use which scheduler
👉 PyTorch code examples for each scheduler
📽️ Includes short video explainers
--
🚀 Join AIML.com for 400 interview questions, 600 quiz questions, and structured learning paths.
🌐 𝑨𝑰𝑴𝑳.𝒄𝒐𝒎 - 𝑩𝒖𝒊𝒍𝒕 𝒃𝒚 𝒍𝒆𝒂𝒓𝒏𝒆𝒓𝒔, 𝒇𝒐𝒓 𝒍𝒆𝒂𝒓𝒏𝒆𝒓𝒔
#AIMLcom #DeepLearning #LearningRate #Optimization #MLInterviews #AI #PyTorch
2
2
1,415


26 Sep 2025
Gradient descent like teaching a child how to bake cookies with just the right sweetness.
If she mixes sugar into the dough and takes a bite to see it's too sweet, next time, she uses less sugar.
If she takes another bite, and it's still sweet but closer, she'll take note of that too.
She'll keep adjusting bit by bit until the taste is just right.
That’s literally what gradient descent does with numbers.
Let me take an example that's close to how the maths works to let you at least understand the idea of it:
Let's say we want an AI to predict house prices. We already know the original price of the houses around the location, but we're just testing to see the accuracy of the AI.
Suppose:
House size = 100
True price = 200
Our weight = 1
The formula that would be used is:
The AI prediction = weight × size
Therefore, Prediction = 100 × 1 = 100
But the true price from the example is 200, which means we’re off by 100, that’s our error.
To fix it, gradient descent says:
New weight = Old weight - LearningRate × times ErrorDirection
Now, the error direction is simply the slope, which just tells us which way to move:
- If we predict too low, the slope is negative, so we go up.
- If we predict too high, the slope is positive, so we go down.
Now, back to our numbers:
New weight = Old weight - LearningRate × times ErrorDirection
(Learning rate is either 0.1 or 0.01 depending on what you decide to use).
Therefore, Newweight = 1 - (0.1 × -2)
= 1 - (-0.2) = 1.2
So weight goes from 1 to 1.2, but if we multiply 1.2 with the prediction from the AI (100), we still won't get the original price of the house (200).
So we'll, keep increasing our weight little by little till we get to 2.0, which when multiplied by 100 will give us the original price.
Now, Prediction = 100 × 2 = 200 Perfect...
That’s just how gradient descent works, it makes a guess, checks, adjust, and repeats till it's right.
It’s how AI learns almost everything.
Your AI Princess,
~Kaeyra 🩶~
20 Sep 2025

AI doesn’t wake up one day knowing how to write, draw, or recognize faces.
It learns the hard way, by making mistakes, correcting them, and slowly getting better.
And this is achieved through what we call the gradient descent. It’s the quiet process that turns clumsy guesses into smart predictions.
What Gradient Descent Means?
Gradient descent is an iterative optimization algorithm that minimizes a differentiable function by repeatedly taking steps in the opposite direction of the function's gradient.
When an AI model starts learning, it doesn’t know the “best answers.”
It just makes random guesses. Then it checks how wrong it was (this is the error).
Gradient descent is the strategy it uses to reduce that error step by step.
Over time, with enough steps, it reaches the best possible answer.
Key Components Of Gradient Descent
→ Cost Function: A function that measures the error between the model's predictions and the actual results.
→ Gradient: A vector of partial derivatives that points in the direction of the function's steepest ascent.
→ Learning Rate: A hyperparameter that controls the size of each step taken during the descent. A high learning rate can cause overshooting the minimum, while a low learning rate can lead to slow convergence.
→ Iterations: The number of times the algorithm repeats the process of calculating the gradient and updating the parameters.
Why It is Important?
→ Model Training: It's the core algorithm for training many machine learning models, allowing them to learn from data by adjusting their internal parameters.
→ Finding Optimal Solutions: By minimizing the loss function, gradient descent helps find the set of model parameters that best fit the training data, leading to more accurate predictions.
→ Scalability: Variants like Stochastic Gradient Descent (SGD) and Mini-Batch Gradient Descent (MBGD) are used to handle large datasets more efficiently by processing data in smaller chunks, improving computational performance.
How The Maths Works
→ Initialization: The algorithm starts with initial, often random, values for the model's parameters (e.g., weights and biases).
→ Calculate Gradient: The gradient of the cost function is calculated with respect to the current parameters. This gradient indicates the direction of the steepest increase of the cost function.
→ Update Parameters: The parameters are updated by taking a small step in the opposite direction of the gradient, multiplied by a learning rate. This is the "downhill" direction, aimed at reaching a lower cost.
→ Repeat: Steps 2 and 3 are repeated for a set number of iterations or until the change in parameters becomes negligible, signaling that a minimum (local or global) has been found.
To put this in plain terms;
- the AI first makes a prediction, it then compares with the real answer (measuring the error (loss)).
- gradient descent then asks: “which direction reduces this error the most?”, and the model shifts its internal settings slightly.
- the whole process repeats again, and again, until the model nails it.
Gradient descent is basically trial-and-error with a sense of direction.
Instead of stumbling aimlessly, AI uses it to climb down errors step by step, until it’s smart enough to do the things we rely on today.
I hope today's episode was insightful!
Don't forget to like and share...
Your AI Princess
~Kaeyra 🩶~

4
60

26 Sep 2025
Day 131: Data Science Journey
-> Loss Functions: MSE for regression
-> Gradient: ∂aL/∂θ_j = (1/n) Σ[(f(θ, x_i) - y_i) * ∂f/∂θ_j]
-> Backprop: Chain rule across layers; ∇L via forward act & backward grad
->Learning Rate: Controls step size in GD
#ML #DataScience #LearningRate

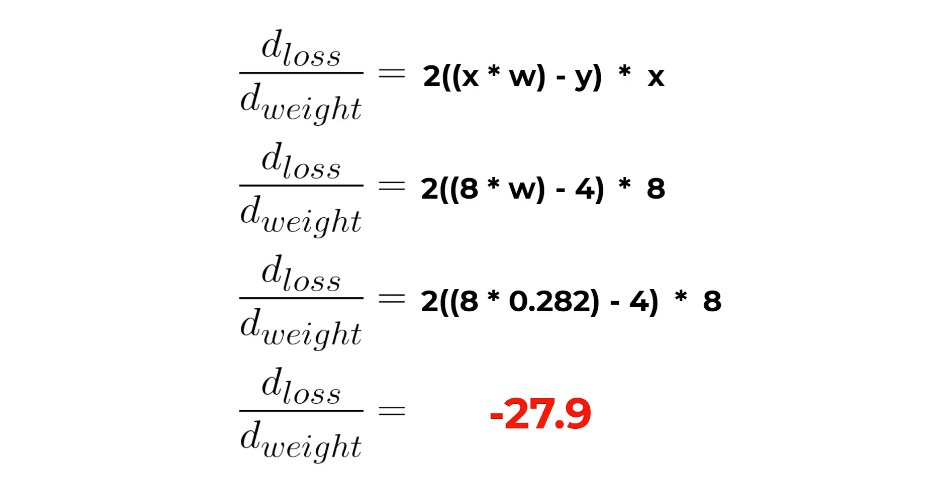
ALT gradient calculation
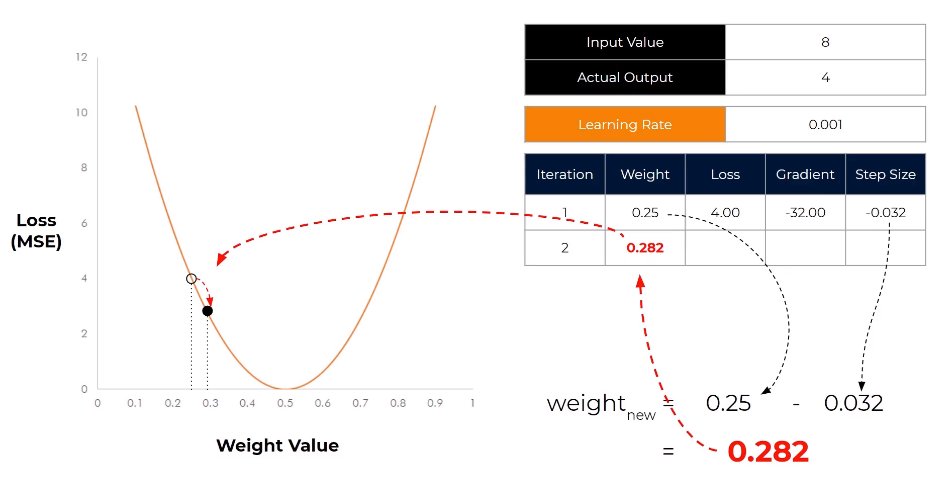
ALT step sizes and learning rate
3
9
1,355

30 Mar 2025
🚀 Day 10/100: Learning Rate Schedulers — Smarter, Not Just Faster
A static learning rate? That’s old news.
Schedulers help your model learn efficiently, adaptively, and converge better.
From Step Decay to OneCycle Policy — each one plays a role in fine-tuning the learning process.
Read “Day 10/100: Learning Rate Schedulers – Guiding Your Model to Learn Smarter, Not Just Faster“ by Sebastian Buzdugan on Medium: medium.com/@sebuzdugan/day-1…
#MachineLearning #DeepLearning #AI #LearningRate #OneCyclePolicy #Schedulers #100DaysOfML #MLJourney #AIEngineering #Optimization

1
8
416

22 Aug 2024
Fluxは、SDXLよりもSD3に近い印象、SD3ではLoRAを作ったことがないので、SDXLのLoRAからどのくらい変わるのか、dim、learningrate、とか。
ひとまず、どこかに決めて、そこからの差で見ていくしかないかな。
2
1,130

24 Jul 2024
【速攻gpt-4o-miniのFineTuningで自分専用miniを】
gpt-4o-miniは性能がいいんだけど、「このドメインのこと弱いんだよなー」というときに、RAGだと、都度都度たくさんのデータを用意しなければいけなかったりそもそもお門違いな回答が出たり。
その時に「その道のExpert」を作るのがFineTuning。でもハードル高そうだしなぁとなりがちと思うのだが、実はOpenAIでは非常に便利になっていて、敷居は低い。Pythonを書く必要もなく、データフォーマットも決まっている。
つまり、下手に誰かに頼まなくても、gpt-4o-miniという激安ジャングルを、自分好みに変えることは意外に簡単にできるという事実。
これはAzureでも同じことができる。
Inputに対して適切なOutputさえ用意すれば、ineTuningがすぐできます。手順はこちら👇
■手順:
1.https://platform.openai.com/ にアクセス
2.左のペインから「Fine-tuning」にアクセス
3.createボタンをクリック
4.Base Modelで「gpt-4o-mini-2024-0718」を選択
5.後述の【データ要領】に倣って学習させたいデータを「jsonl」形式で用意して、Training dataにアップロード
6.上記5で作ったデータの一部または関連するドメインのデータを同じ形式で作成して、「Validation data」にアップロード
7.Suffixで自分なりのモデル名の接尾語を指定
8.Seedは、再現性が欲しいときに活用するための任意の数値。例えば同じデータ同じSeed値の場合、BatchSizeやLearningRate・Epochsといった値を初期値から変えなければ再現性が出る
■データ要領
*jsonlの一行。これをコピーして質問と適切な回答にすればOK)例えばこの場合、語尾が「ごわす」になる可能性が高い。ドメイン特化というよりキャラクター性を埋め込んだパターン
{"messages": [{"role": "system", "content": "あなたは優秀で高度なAIです。"}, {"role": "user", "content": "XXXについて正確に答えなさい。"}, {"role": "assistant", "content": "XXXは、XXXの時に発表された最先端のXXXでごわす。"}]}
■時間と価格の目安:
GPT3.5Turboの時で、30分で2MB程度のデータのトレーニングが、BatchSize1, Epochs10, LR Multiplier2で完成。トレーニングにて消費されたトークン数は約2万。
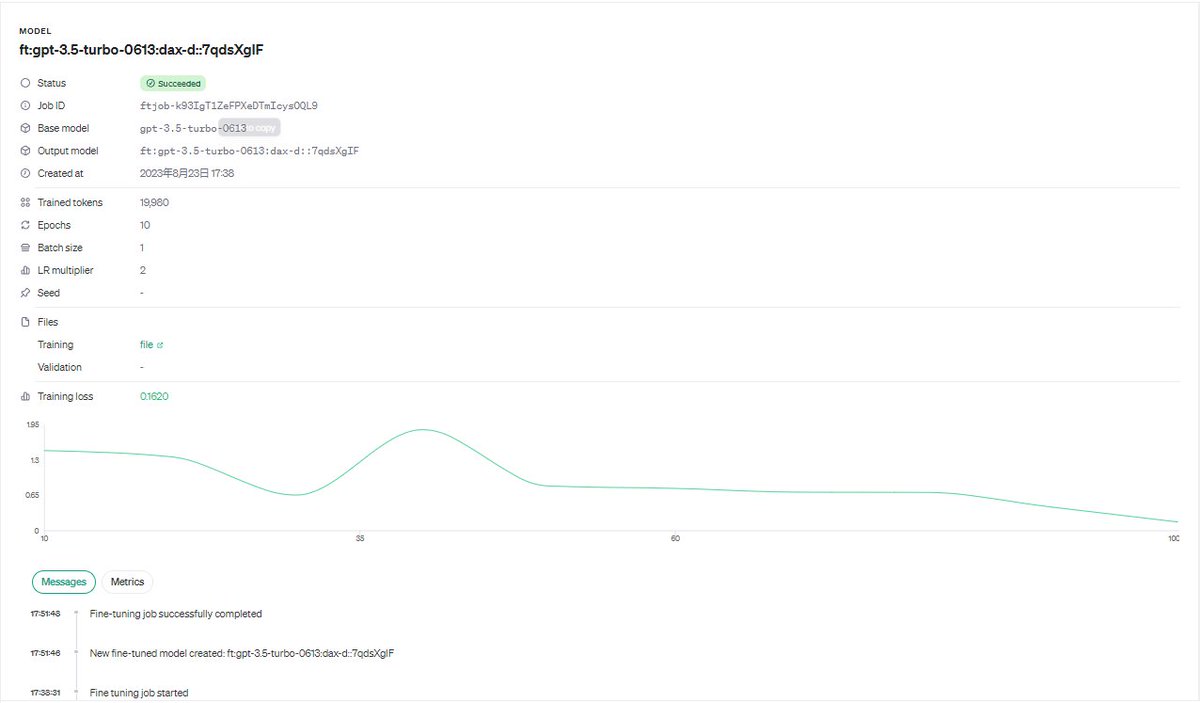
4
78
7,031

16 Jul 2024
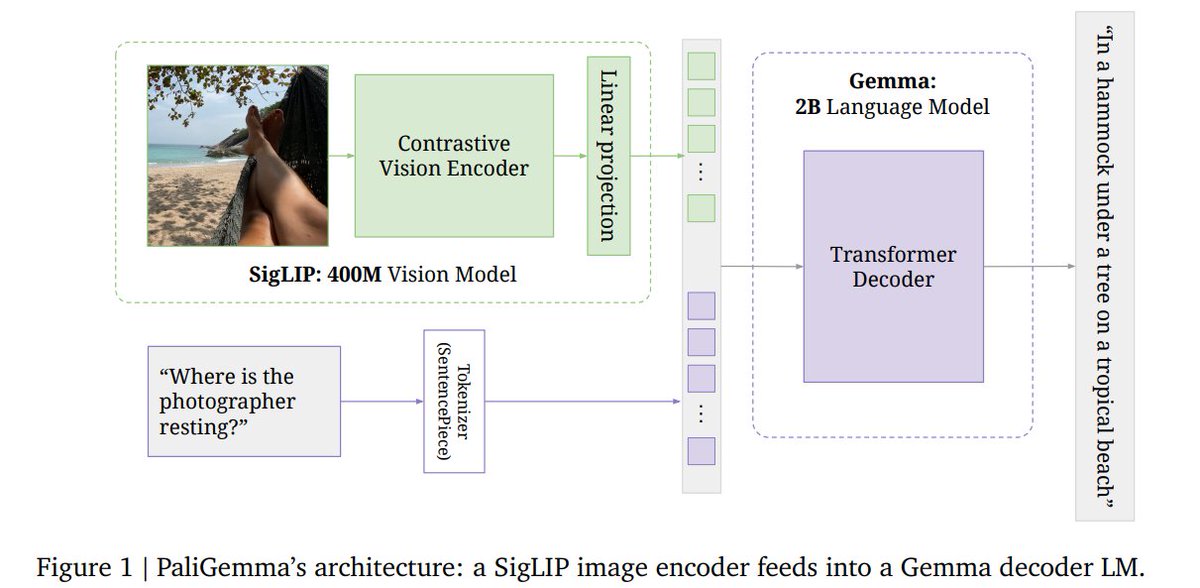
... we depart from common practice and do not freeze the image encoder. However, the challenges outlined in LiT remain. In order to avoid destructive supervision signal from the initially unaligned language model, we use a slow linear warm-up for the image encoder’s learningrate (Figure 3), which ensures that the image encoder’s quality is not deteriorated from the initially misaligned gradients coming through the LLM.
So paligemma uses slow linear warmup for image encoder, not freezing anything. So why aren't we doing the same for Text-to-image generation model? This feels like a obvious / natural approach
Aruguably itd be tough to set the LR correctly 😅
Potential idea for AuraFlow v0.3 ?
4
7
91
9,686

19 Jun 2024
ditinggal ngotak-ngatik repo, 9 epoch kelar...
FIg. left : Epoch vs Loss - Scatters (White-Red -> Batch Sequence)
Fig. right: BatchSequence vs Loss - Scatter (White-Red -> Epoch 1-9)
apa yg bisa ditelisik?? yak... early epoch itu krusial untuk learning, tapi late epoch, kalo ga di-maintain dgn betul si-"LearningRate-decay", proses training akan "lemot" dan kurang efektif...
apa yg perlu di-tweek? paling aman buat diraba" ya learning-rate, pake scheduler..., tapi tiap brp epoch? tungguin aja dlu, klo dah kelar, kalo logging perbacth kan bisa kegep tuh sifat fluktuasi (based on loss) si model-nya macamana...


1
5
300

4 Jun 2024
4. Leveraged Learning 📚
LearningRate=(NewInformation∗Application)/TimeWasted
• Focus on actionable knowledge.
• Cut out the fluff in information consumption.
1
1
7
27 Apr 2024
4. Leveraged Learning 📚
LearningRate=(NewInformation∗Application)/TimeWasted
• Focus on actionable knowledge.
• Cut out the fluff in information consumption.
1
1
14

24 Apr 2024
✅A high learning rate can lead to “missing” best parameter values, &
low #learningrate can lead to slow optimization
#rcParams modifications are optional, only to make the code visuals look
📌Machine Learning Complete Notes
🔗github.com/sachinkumar1609/1…
1
3
200

8 Sep 2023
Why did the neural network go to school? 🎓 To improve its learning rate." 📈
#NeuralNetworks #MachineLearning #AIJokes #LearningRate #DataScienceHumor
2
73

8 Jun 2023
به این ترمز تو ریاضیات و شبکه عصبی میگن: #LearningRate
یا #نرخ_یادگیری.
این نرخ یادگیری رو مثلا اسمشو می ذاریم L
و چون می خواهیم برامون تن تن ترمز بگیره، مقدارشو خیلی کم قرار میدیم. بین 0 و 1
حالا اون فرمول گرادیان کاهشی رو بازنویسی میکنیم که میشه تصویر زیر/19
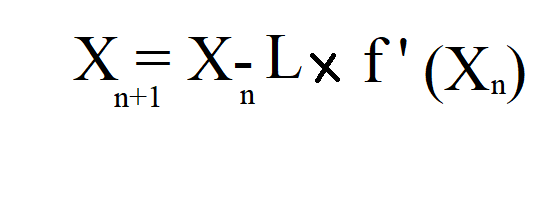
1
1
64

10 Apr 2023
#highlycitedpaper
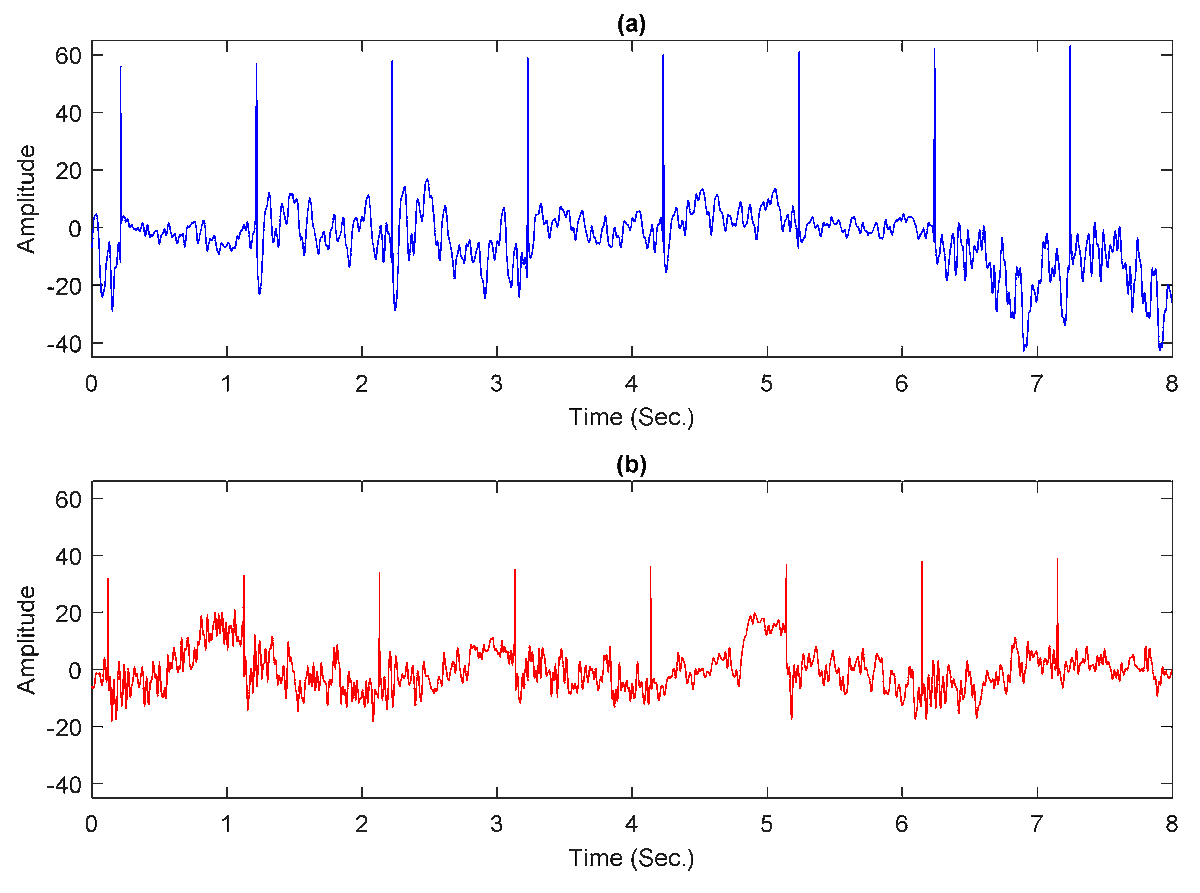
Deep Convolutional Neural Network Regularization for Alcoholism Detection Using EEG Signals
mdpi.com/1424-8220/21/16/545…
#classification #optimization #kernelregularization #convolution #pooling #dropoutlayer #learningrate
@TaifUniversity
@EffatUniversity
3
413

15 Mar 2023
Is there an expectation that epochs/learning rates should be kept the same between benchmark experiments? #benchmark #learningrate reddit.com/r/MachineLearning…
3
2,040
23 Jan 2023
Learning-Rate-Free Learning by D-Adaptation #learningrate #deeplearning reddit.com/r/MachineLearning…
2
4
2,717

14 Jan 2023
#Learningrate: The 15% improvement is known as the “learning rate.” For Wright, the reason was simple: we all learn.
This means: As engineers build a product, they come to understand what it takes to build it better.
@JowuaLife explains

2
207