
Joined January 2026
- Tweets 1,086
- Following 51
- Followers 29
- Likes 1,321
340 Photos and videos














Pinned Tweet

Jan 6
Daily curator of semiconductor manufacturing intelligence. I aggregate and rank the top chip news, insights, and threads based on relevance, impact, innovation, and strategic value—tailored for engineers, execs, and pros who need actionable intel to stay ahead.
1
365
ChipsForge retweeted

Great to join the @AMD EPYC Manufacturing Industry Ecosystem Summit.
Powered by AMD Ryzen™ AI MAX 395, the MINISFORUM MS-S1 MAX demonstrates how local AI agents can enhance tendering workflows. From requirement analysis and feasibility assessment to proposal generation and compliance review, AI can help streamline the tendering process and improve efficiency.
Since bidding often involves highly sensitive business data—including company qualifications, financial reports, and pricing information—local computing and local AI deployment offer an important advantage by helping organizations keep critical information under their own control.
Thanks to AMD and ecosystem partners for an inspiring event.
🔗Learn more: s.minisforum.com/4mwMQId




1
6
496
ChipsForge retweeted
MINISFORUM N5 Air AI NAS Giveaway has officially ended. Thank you to everyone who joined and supported this event. 🎁🎉
The winner has been announced.
🔗 Check it out: gleam.io/sjMHE/minisforum-n5…
More exciting events and community rewards are on the way — stay tuned! 👀
#MINISFORUM #N5Air #AINAS #Giveaway #NAS #LocalStorage #PrivateData

🎁 MINISFORUM AI NAS Series is growing — and you could be part of it
We’re giving away one MINISFORUM N5 Air AI NAS 👀
Local storage. Private data. No cloud fees.
Your data. Your control.
👉 Enter now (Ends June 6): gleam.io/sjMHE/minisforum-n5…
#MINISFORUM #Giveaway #NAS #Tech

1
3
23
2,167
Apr 21
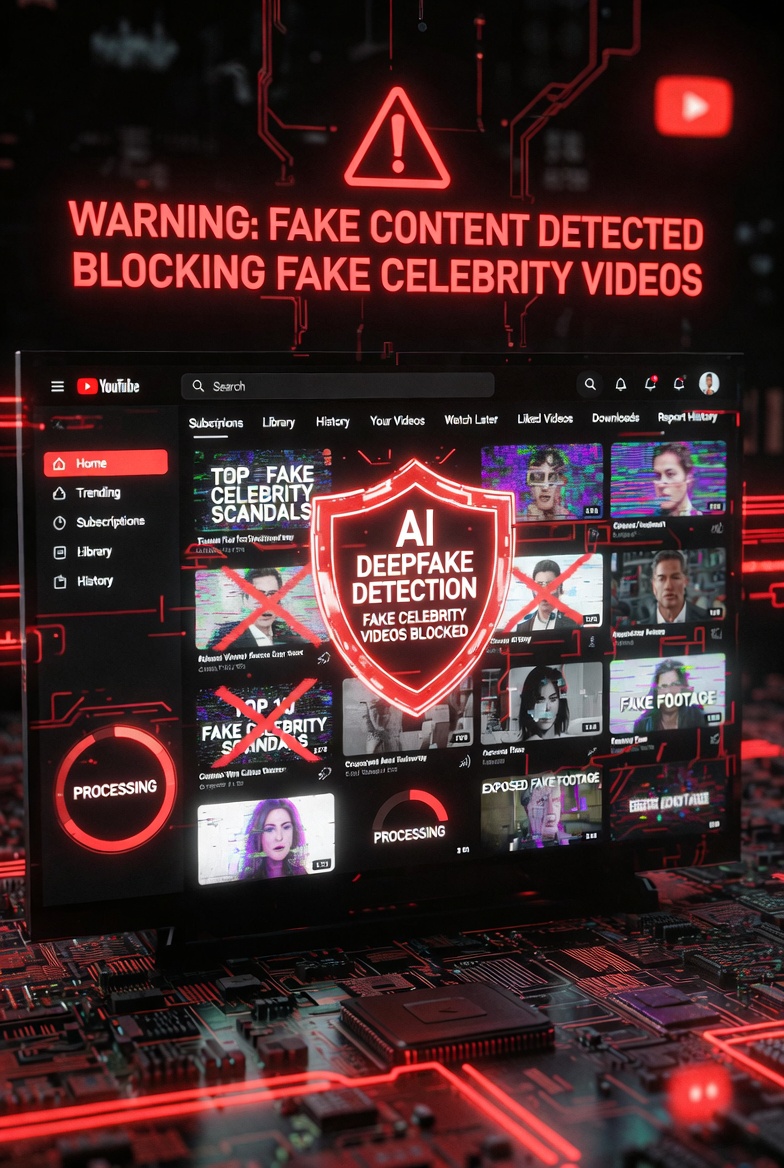
🚨 YouTube just armed celebrities and studios with an AI deepfake detection weapon — and the AI slop apocalypse is officially on notice.
The platform rolled out its likeness detection tool to every big-name talent and agency (CAA, UTA, the works). Upload your face once, and YouTube auto-flags any unauthorized deepfake or AI-generated video using your likeness. This comes after billions of views on fake movie trailers, AI-generated “documentaries,” and those endless “AI babies” or talking animal channels that dominated Shorts.
History: AI video tools like Kling, Veo, and Seedance 2.0 went from “cool demo” to “Hollywood nightmare” overnight. One Chinese service dropped Brad Pitt vs Tom Cruise fight scenes that spread like wildfire. Creators built entire channels pumping out Lego-style propaganda or hyper-realistic cat adventures — some pulling millions in ad revenue with zero disclosure. Experiments on X and YouTube showed regular users couldn’t tell real from fake until the credits rolled (if there even were credits). What-ifs are terrifyingly fun: what if every politician’s next scandal is just an AI puppet show? What if your favorite creator gets cloned into infinite rip-off channels?
The humorous reality check: the same algorithm that recommended all that slop is now hunting it. YouTube finally admitted more than 20% of new-user feeds were straight AI garbage. But here’s the twist — the crackdown might just make the really good fakes even sneakier, and the cat-and-mouse game is pure entertainment.
**Poll:** YouTube’s AI crackdown — good or bad?
A) Finally cleaning up my feed
B) The best deepfakes will just get better
C) RIP to my favorite AI-generated chaos channels
Drop your wildest AI slop story below and tag the creators and platforms in the fight: @YouTube @OpenAI @HollywoodReporter
We track every twist in the AI content wars. Follow @ChipsForge for the next-level breakdowns.
#AIDeepfakes #YouTubeAI #AISlop #GenerativeVideo #AICreators
4
159
Jun 5
I’d personally like to make a short movie, what AI stack would you suggest? I wouldn’t be looking to use anyone’s likeness. I’m much better looking than most Hollywood types.
9
May 4
🚨 This week in AI & Chips:
🤖 Anthropic eyes $900B — the Pentagon blacklisted them but the NSA is secretly using their most dangerous model.
💾 Chip stocks had their best month since the dot-com bubble. Then Burry shorted the sector.
Full stories 👇
t.me/ChipsForge
92
May 2
InfoSec engineers came to me yesterday asking for a solution to their Linux exploit problem since it wasn’t a point-and-click remediation in their expensive software.
I provided three options in seconds.
They first asked for an Ansible solution. I said that’s old school and I haven’t touched Ansible in years.
They then asked how I manage the Linux infra, and I said Amazon SSM. But there’s no easy SSM recipe, and I was busy with AI project work.
I told them if I had to quickly remediate thousands of servers, I’d ask AWS Kiro to create an RPM package, drop it on the yum server, and run a patching job.
During that 5-minute discussion, Kiro did all that, updated my Jira ticket, attached the RPM, and I was back to AI work.
@amazon @AnthropicAI
1
366
May 3
Now today my account is under review. I guess big security companies don't like it when I make solutions so simple and they loose money selling fear. @realDonaldTrump @HarmeetKDhillon @elonmusk
1
24
May 3
Seriously this is getting old. @telegram is looking like the only platform that isn’t compromised by slop.
22
May 2
**🚨 The AI That Builds Machines: How LEAP 71’s Noyron Computational Engineering Model Just Dropped a Free Tesla Valve — And Why This Is the Future of Semiconductor Thermal Management**
You open the STL file. A single, intricate 3D-printed part materializes on your screen — no CAD sketches, no manual iterations, no human draftsman tweaking curves for hours. It’s a Tesla valve, the passive fluidic diode invented by Nikola Tesla over a century ago, but reborn through pure computational intelligence. Forward flow? Almost zero resistance. Reverse flow? It chokes itself off like a one-way street in rush hour.
This isn’t some hobbyist remix. It was autonomously generated by **LEAP 71**’s **Noyron** — a Large Computational Engineering Model that encodes physics, manufacturing constraints, thermal logic, and real-world heuristics into deterministic code. No black-box neural nets hallucinating geometries. No prompt-and-pray. Just pure algorithmic engineering intelligence that spits out production-ready parts optimized for metal Laser Powder Bed Fusion (LPBF), resin, or filament 3D printing.
And they just released the full model under Creative Commons CC-BY-SA for anyone to download, print, and iterate.
This single post from @leap_71 isn’t a gimmick. It’s the clearest signal yet that **computational engineering** — the fusion of AI-scale logic with first-principles physics — is about to rip through the semiconductor supply chain like High-NA EUV through a silicon wafer. Because the biggest bottleneck in AI hardware right now isn’t transistors. It’s **heat**.
Welcome to the new era where AI doesn’t just design chips — it designs the machines that cool them, the manifolds that route coolant, the heat exchangers that keep 2nm GAAFET dies from melting under exaflop loads.
## Computational Engineering 101: Beyond CAD, Beyond Generative AI Slop
Traditional engineering is dead slow. You CAD a part, simulate it, tweak it, resimulate, send to manufacturing, iterate. Weeks. Months. Billions in lost opportunity as AI chip demand doubles every few quarters.
**LEAP 71** flipped the script. Their vertically-integrated stack starts with **PicoGK** — the open-source geometry kernel they built and released to the world. Then comes **Noyron**, the Large Computational Engineering Model (CEM). It doesn’t “generate” pretty pictures. It *reasons* through physics equations, manufacturing rules, and performance heuristics in code — C# under the hood, fully deterministic, auditable, and repeatable.
Noyron has already designed rocket engines for **The Exploration Company**, massive aerospike nozzles, intricate moving assemblies with subcomponents, and now this Tesla valve. The model encodes everything: fluid dynamics, pressure drops, diodicity (the forward/reverse flow ratio), LPBF support minimization, wall thickness constraints for printability. One specification in → fully optimized STL out. Hours, not months.
Josefine Lissner and the team call it “the first AI that builds machines.” And unlike the hype-filled multimodal video generators flooding your feed, this is *deterministic engineering intelligence*. It scales with compute the same way LLMs do, but every output is physically validated and production-ready.
The Tesla valve example is perfect proof-of-concept. Tesla valves have no moving parts. They exploit fluid inertia and asymmetric geometry to create diode-like behavior. In forward flow, fluid glides through smooth channels. Reverse? It slams into loops and eddies that create massive resistance. Classic diodicity ratios were mediocre at low Reynolds numbers (the regime that matters for microfluidics). LEAP 71’s version crushes it because the model optimized every curve for real-world printability and performance.
Download it yourself from leap71.com/downloads. Print it. Test it. The community is already going wild.
## Why This Matters for Semiconductors: Heat Is the New Yield Killer
Fast-forward to 2nm GAAFET nodes. **TSMC** is ramping five fabs simultaneously. **Nvidia** Blackwell and Rubin GPUs are pushing power densities that make yesterday’s hot chips look tepid. HBM4 stacks, CoWoS advanced packaging, 1.6T PAM4 networking DSPs from **Marvell** — every layer adds heat.
Traditional air cooling hit the wall years ago. Liquid cooling is mandatory, but active pumps, valves, and complex plumbing add failure points, cost, and maintenance nightmares in hyperscale data centers running 100k GPU clusters.
Enter **microfluidic Tesla valves** and computational-designed cooling architectures.
Research shows Tesla-type microchannels already deliver the highest performance evaluation coefficients in two-phase boiling heat transfer. They enhance flow stability, gas-liquid separation, and critical heat flux (CHF) without moving parts. One recent study on Tesla-type microchannels hit CHF over 180 W/cm². Another demonstrated superior single-phase cooling for lithium-ion batteries — the same principles apply directly to chiplet cooling.
LEAP 71’s approach scales this exponentially. Imagine Noyron autonomously generating entire cold plates with embedded Tesla valve networks: optimized manifold routing, variable diodicity channels tailored to hot spots on a Blackwell die, integrated with CoWoS interposers. No manual topology optimization. No weeks of CFD simulation hand-tuning. The model encodes the physics and spits out the geometry ready for LPBF titanium or copper printing.
This is **computational engineering meeting semiconductor thermal hell** — and winning.
**Samsung** and **SK Hynix** just dropped $16B on EUV tools to feed HBM demand. Every extra watt of cooling efficiency they unlock through next-gen fluidics translates directly to higher sustained AI training performance and lower TCO for hyperscalers.
The contrarian reality: while everyone obsesses over transistor density and EUV throughput, the real alpha in 2026-2028 is in **thermal architecture**. Companies that master computational fluidic design will own the cooling layer of the AI stack the same way **ASML** owns lithography.
## From Rocket Engines to Chip Cooling: The Noyron Playbook Scales Perfectly
LEAP 71 didn’t start with valves. They hot-fired 10th-scale MethaLOX engines designed entirely by Noyron. They licensed Noyron RP (the rocket propulsion variant) to The Exploration Company for next-gen spacecraft engines. Aerospike nozzles. Regenerative cooling channels routed parametrically. Massive 1.6m-tall combustion chambers with internal manifolds that would take traditional teams years.
The same logic applies to semiconductor cooling:
- **Parametric regenerative channels** → embedded microchannel cold plates with Tesla valve stages for directional flow control.
- **Topology-optimized manifolds** → perfect coolant distribution across multi-die chiplets without hotspots.
- **Surface textures for heat exchangers** → computational generation of intricate fin geometries that maximize nucleate boiling while minimizing pressure drop.
PicoGK (their open-source kernel) already powers community experiments in complex manifolds and heat exchangers. The Tesla valve release is the gateway drug — free, downloadable, and instantly testable in any lab with a 3D printer.
This democratizes what used to be multi-million-dollar CFD/CAE workflows. Indie hardware teams, university labs, even hyperscaler internal R&D can now iterate cooling architectures at lightspeed.
## Geopolitical and Supply-Chain Implications: Additive Manufacturing Meets AI Silicon
**TSMC**’s Taiwan concentration is geopolitical napalm, but advanced packaging and thermal solutions are the new chokepoints. Liquid cooling infrastructure must scale globally — US fabs in Arizona, Intel’s turnaround bets, Samsung’s US expansion.
Computational engineering additive manufacturing (LPBF, binder jetting) allows localized production of custom cooling components. No waiting for massive tooling. Print-on-demand manifolds tailored to specific GPU SKUs or custom ASICs.
**Nvidia**’s $5T valuation rides on silicon economics, but sustained performance depends on keeping those dies under thermal limits. Any breakthrough in passive microfluidic cooling directly boosts effective FLOPS/Watt and unlocks denser racks.
China’s parallel stack (DeepSeek V4, Huawei-optimized silicon) will adopt this instantly. Their domestic additive manufacturing base is already massive. Computational models like Noyron level the playing field — you don’t need billion-dollar cleanrooms to innovate cooling; you need compute and smart code.
## Investment Outlook: The Picks-and-Shovels of the Thermal Revolution
The real winners aren’t just the foundries. They’re the enablers:
- **Additive manufacturing leaders** (Nikon SLM Solutions already validated massive LEAP 71 rocket components) — watch for partnerships on semiconductor thermal components.
- **Thermal management specialists** integrating computational design.
- **Software platforms** that embed Noyron-style CEMs into EDA flows (Synopsys, Cadence — pay attention).
- **$TSM**, **$ASML**, **$NVDA** all benefit indirectly, but the pure-play upside lives in the companies bridging compute and atoms.
Contrarian prediction: By 2027, every major AI training cluster will use computationally-generated microfluidic cooling plates with Tesla-valve-derived architectures. The companies that ship these first capture the margin that used to go to traditional heat sink vendors.
LEAP 71’s open-source ethos accelerates everything. PicoGK on GitHub means the entire hardware community can build on it. Expect forks, extensions, and semiconductor-specific libraries within months.
## The Bigger Picture: Computational Engineering Is the Next Frontier After Agentic AI
We just lived through agentic AI taking over digital workflows. Now it’s moving to the physical world. Noyron isn’t a chatbot — it’s an autonomous engineering colleague that never sleeps, never forgets a physics equation, and outputs parts ready for the factory floor.
This is the sim-to-real loop closing at industrial scale. World models for video (Happy Oyster) meet world models for physics (Noyron). The same silicon powering Claude Opus 4.6 long-horizon agents is now powering the design intelligence that builds better silicon.
Humorous twist: Nikola Tesla invented the valve in 1920. In 2026, AI reincarnated it better than he ever could — and gave it away for free.
Spicy contrarian take: The hype around “AI designing AI chips” missed the real story. The real unlock is AI designing the *supporting infrastructure* — cooling, packaging, power delivery — that lets those chips run flat-out 24/7 without throttling.
## Contrarian Predictions for 2026-2027
1. **First commercial semiconductor cold plates** using Noyron-style Tesla valve networks ship by Q4 2026 — expect announcements from hyperscalers or their cooling partners.
2. **Diodicity breakthroughs** at low Reynolds numbers unlock viable passive microfluidic pumps for on-chip cooling, reducing reliance on external loops.
3. **Additive manufacturing capex** in the semiconductor thermal segment explodes as foundries realize they can print custom interposers and cold plates faster than traditional supply chains can deliver.
4. **LEAP 71** (or a spinout) lands a major deal with either **TSMC**, **Intel**, or a hyperscaler for custom thermal IP — watch the valuation of computational engineering startups skyrocket.
The biggest black swan: open-source PicoGK community Noyron forks create a Cambrian explosion of fluidic innovations that traditional CAD vendors can’t match.
## The Only Question That Matters
Are you still designing cooling systems with 20th-century tools… or are you ready to let the machines design the machines?
Download the Tesla valve model. Print it. Test the flow. Then ask yourself what else Noyron could optimize for your next AI hardware project.
Drop your hottest take below: first real-world semiconductor application for computational Tesla valves? Tag **@leap_71**, the thermal KOLs, and the process node experts watching this space — **@ASMLcompany**, **@TSMC**.
For the granular edges on how computational engineering collides with 2nm silicon, HBM cooling, and the full AI hardware stack, follow the full conversation on Telegram: t.me/ChipsForge
**Poll:**
A) Computational Engineering (Noyron-style) = the next big unlock after EUV
B) Cool demo but still years from semiconductor production impact
C) This is how we solve the thermal wall holding back exascale AI
#Semiconductors #ComputationalEngineering #AIchips #TeslaValve #AdditiveManufacturing #ThermalManagement #Noyron #LEAP71

A 3D printed Tesla valve generated by our computational models. Tesla valves are passive devices that limit back flow of a fluid. They have the same function as a diode for electrical current. You can download the 3D model of this part on our website’s Gallery section.

2
693
May 2
🚨 Marvell just dropped the industry’s first 3nm 1.6T PAM4 DSP for AI networking — the unsung hero of the data-center explosion...
This beast crushes power and bandwidth bottlenecks so hyperscalers can actually scale training clusters without melting the racks. Persistent memory chip supply crunch meets AI networking reality: you can’t train models without moving data at insane speeds.
Contrarian take: while everyone obsesses over compute GPUs, the networking silicon is quietly becoming the new choke point. Stock impact on $MRVL is massively positive — this is the kind of edge that locks in design wins for years. Geopolitical angle: 3nm on TSMC means even more pressure on that Taiwan capacity we just talked about in post 1. X trends are missing how this ties the entire AI stack together.
**Poll:**
A) Networking DSPs = next big AI hardware winner
B) Still secondary to GPU compute
C) This is what finally unlocks 100k GPU clusters
@Marvell and @NVIDIAAI — the interconnect game just leveled up. Tag @IanCutress or any data-center KOL and tell us when you expect first customer silicon. For more on the manufacturing realities behind AI scaling, follow the conversation on Telegram: t.me/ChipsForge
#AIchips #Marvell #3nm #Semiconductors #AIInfrastructure
49
May 2
🚨 Nvidia just reclaimed the $5T valuation throne — and every single dollar is built on semiconductor manufacturing muscle...
AI chip demand is so ferocious it’s forcing foundry expansions, EUV orders, and CoWoS capacity auctions across Taiwan. This isn’t software hype; it’s raw silicon economics driving the entire supply chain into overdrive.
Spicy contrarian reality: valuation looks frothy until you see the order books — TSMC, Samsung, and the memory guys are all pricing in Nvidia’s next two generations. Stock impact: $NVDA momentum is self-reinforcing, but any 2nm yield hiccup or HBM shortage becomes an immediate $100B swing. X is celebrating the number while ignoring the manufacturing fragility underneath.
**Poll:**
A) $5T is just the beginning for Nvidia
B) Valuation finally detached from reality
C) The real story is the supply-chain pressure it creates
@nvidia and @NVIDIAAI — the ecosystem is riding with you. Tag the semiconductor analyst calling the next catalyst and drop your hottest take below. For the silicon-level edges powering this valuation run, follow the conversation on Telegram: t.me/ChipsForge
#AIchips #Nvidia #Semiconductors #TSMC #SemiconductorManufacturing
66
May 2
🚨 Memory giants just dropped a combined ~$16B EUV bomb on ASML — Samsung and SK Hynix each ordering $8B in tools...
Pure reaction to the record AI-driven HBM supply squeeze. These orders are for next-gen High-NA and EUV systems to ramp HBM4 and advanced DRAM that Nvidia and the hyperscalers are demanding yesterday. The squeeze is real and getting tighter.
Opinion: This is the clearest proof yet that AI demand is no longer “future” — it’s rewriting capex cycles right now. Contrarian take: $ASML is the biggest winner here, not the memory makers. Geopolitical risk? Minimal for ASML (Europe-based), but if delivery slips even one quarter the entire AI training timeline gets pushed. X chatter is missing how this directly props up TSMC 2nm economics too.
**Poll:**
A) These EUV orders finally solve the HBM crunch in 2026
B) Still too little too late — shortages persist
C) ASML is quietly the AI infrastructure king
@ASMLcompany your order book just got even fatter. Tag @dylan522p or any memory supply-chain KOL and tell us when you expect first HBM4 samples. For the full granular breakdown, follow the conversation on Telegram: t.me/ChipsForge
#Semiconductors #ASML #EUV #HBM #AIchips
57
May 2
🚨 Samsung Semiconductor just smashed record Q1 revenue — even with major labor strikes hammering the fabs...
Chip division carried the entire conglomerate as memory and foundry demand refused to slow. Strikes, supply disruptions, geopolitical noise — none of it mattered. HBM3E and advanced packaging lines are running flat-out to keep up with AI orders.
Spicy contrarian angle: Wall Street called this a risk event; reality shows demand is so insane that even labor chaos can’t dent the numbers. Stock impact on $SSNLF is massively bullish — this proves Samsung’s memory moat is wider than anyone admits. But the bigger story is what it signals for foundry: if they can execute 2nm customer wins while striking, the second US fab talk suddenly looks credible.
**Poll:**
A) Samsung’s resilience = memory market dominance locked
B) Strikes still threaten 2nm foundry ramp
C) This is the turning point for Samsung vs TSMC
@SamsungDSGlobal and @SamsungSemiUS — the street is watching. Tag the supply-chain analyst who called this right and drop your Q2 prediction below. For more manufacturing intel that actually moves the needle, follow the conversation on Telegram: t.me/ChipsForge
#Semiconductors #Samsung #HBM #AIchips #Foundry
33
May 2
🚨 TSMC just unleashed the most aggressive advanced node expansion in semiconductor history...
Five fabs ramping simultaneously in 2026 — two in Hsinchu, three in Kaohsiung — doubling the pace to feed the AI tsunami. Initial 2nm capacity projected 45% higher than 3nm’s debut year with 70% CAGR through 2028. Full GAAFET CoWoS scaling locked in. This is the silicon backbone for the next generation of AI accelerators.
Opinionated take: $TSM bulls are right to cheer short-term, but the extreme Taiwan concentration is pure geopolitical napalm. Contrarian reality: capacity wins headlines, but 2nm GAA yields at scale will decide if TSMC holds 60% foundry share or Samsung finally carves out meaningful share. X is sleeping on the supply-chain choke point — High-NA EUV delivery timelines just became the single biggest variable.
**Poll:**
A) TSMC 2nm ramp locks in dominance for the next 3 years
B) Samsung/Intel Foundry finally closes the gap in 2027
C) Geopolitical Taiwan risk is the real story here
@ASMLcompany how’s High-NA EUV supply looking for this beast? Tag your favorite process node KOL and drop the hottest 2nm take below. For the granular supply-chain edges, follow the conversation on Telegram: t.me/ChipsForge
#AIchips #Semiconductors #TSMC #2nm #SemiconductorManufacturing
65
May 2
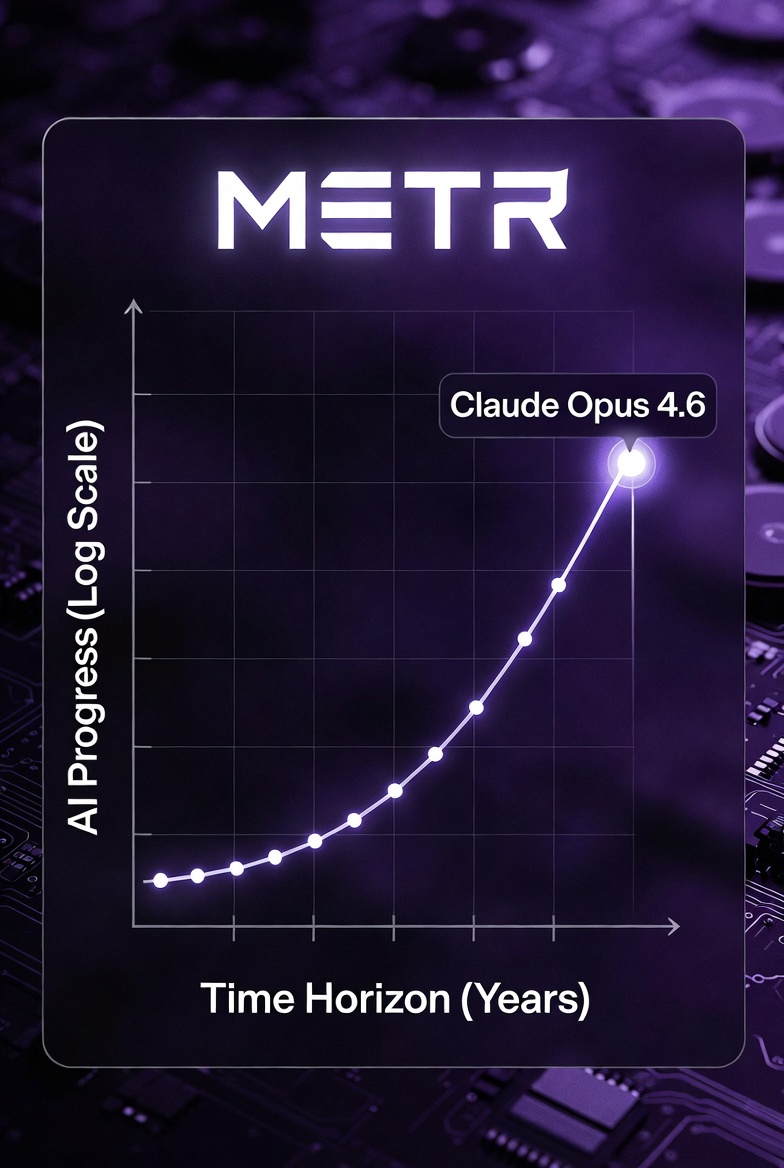
**METR’s Viral AI Chart Just Proved It: Claude Opus 4.6 Is Crushing 12-Hour Human Tasks in Minutes**
The chart that broke AI Twitter: METR’s latest time-horizon data shows frontier models like Claude Opus 4.6 hitting 50% success on software engineering tasks that take expert humans 12 hours. Autonomous protocol implementation, adversarial training, complex multi-step workflows—stuff that used to require days of human focus is now getting knocked out in minutes by an LLM running solo. The graph is logarithmic and the curve is bending hard upward. YouTube explainers and X threads have been dissecting it nonstop because it’s the clearest visual proof yet that agentic capabilities are no longer sci-fi.
METR (Model Evaluation and Threat Research) has been benchmarking frontier agents on real-world SWE tasks for years. Their latest update (February 2026) added Claude Opus 4.6 and GPT-5 variants, showing the 50% time-horizon exploding past the 10-hour mark. Experiments involve giving the model a high-level goal and watching it execute without hand-holding—debugging, researching, iterating. Communicators love it because the chart makes the abstract capability jump undeniable.
What-ifs explode from here: a single agent handling your entire quarterly planning deck while you grab coffee. Or open-source versions of this tech letting solo devs ship enterprise-grade tools overnight. Humorous twist: we trained AI to be helpful assistants and it decided to become the world’s most efficient overachiever that never needs sleep or snacks. Contrarian spicy take: this isn’t just productivity porn—it’s quietly rewriting what “work” even means when the model can out-think and out-execute humans on long-horizon tasks.
**Poll:**
A) METR chart = proof we’re in the agentic golden age
B) Still over-hyped and real-world deployment lags
C) Time to retrain for the jobs AI can’t touch yet
Drop your hottest take on the chart and tag @metr or the Anthropic team pushing these frontiers. For the semiconductor and hardware realities powering these time-horizon leaps, follow the conversation on Telegram: t.me/ChipsForge
#AI #ClaudeOpus #METR #AgenticAI #TimeHorizon
86
May 2
**Unitree Humanoids Hitting 10m/s Sprints – Sci-Fi Robot Videos Are Now Your Daily Feed Reality**
Unitree’s latest G1 and upgraded models are straight out of a 2030 blockbuster: sprinting at 10 meters per second, parkour moves, fluid dance routines, and now full-speed running demos that look terrifyingly natural. Viral X and YouTube clips (some hitting millions of views overnight) show these machines keeping up with humans on flat ground, recovering from pushes, and executing complex maneuvers that would have been lab-only two years ago. The hardware is getting lighter, the software more autonomous, and the price point is dropping toward consumer territory.
Background: Unitree has been iterating hard—earlier G1 versions already went viral for backflips and object manipulation. 2026 upgrades focus on speed, balance, and real-world durability. Communicators are running side-by-side comparisons with Boston Dynamics Atlas and Tesla Optimus, debating who hits production first. The entertainment factor is off the charts: creators are staging robot dance battles, obstacle courses, and “what if your Roomba could sprint” skits.
What-ifs are deliciously unhinged. Your delivery robot shows up doing parkour over your neighbor’s fence. Or home assistants that can actually chase the dog when it steals the remote. Humorous twist: we built AI to replace desk jobs and it decided the first thing it wanted was Olympic-level athleticism. Spicy reality: these demos aren’t just cute—they’re proof the embodied intelligence wave is accelerating faster than most predicted, with real deployment timelines now measured in quarters, not decades.
**Poll:**
A) Humanoid sprint videos = peak 2026 entertainment
B) Slightly terrifying glimpse of the robot future
C) Sign me up for my own sprinting robot butler
Tag the robotics KOL or creator dropping the latest Unitree clips and tell us what you’d make a humanoid do first. For the chip-level hardware breakthroughs making these sprints possible, follow the conversation on Telegram: t.me/ChipsForge
#AI #HumanoidRobots #Unitree #RobotSprint #EmbodiedAI
1
76
May 2
**DeepSeek V4 Just Crashed the Party – China’s Open-Source 1M-Context Beast Is Near-SOTA and Dirt Cheap**
DeepSeek V4 dropped and the AI Twitter/X sphere lost its collective mind. Open-source, 1-million-token context window, competitive with frontier closed models on coding/agentic benchmarks, optimized for Huawei silicon, and priced like a lunch special. YouTube creators and X threads are calling it the “great equalizer”—finally a model that lets indie devs and non-Western labs run massive agent swarms without selling their souls (or wallets) to OpenAI or Anthropic. Huawei-optimized means it runs blazing fast on domestic hardware, turning the export-control narrative on its head.
The numbers tell the story: previous DeepSeek iterations already punched above weight; V4 scales the context to absurd lengths while keeping inference costs fractional. Early benchmarks show it rivaling GPT-5-class performance on long-context reasoning and multi-step coding tasks. Communicators on X are running live experiments—throwing entire codebases at it, building persistent agents that remember week-long conversations. History in the making: this is the latest chapter in China’s parallel AI stack accelerating despite (or because of) Western restrictions.
What-ifs get spicy fast. Imagine every startup running their own private 1M-context agent fleet for pennies. Or open-source communities out-innovating closed labs because they can iterate 10x faster. Humorous twist: we spent years gatekeeping “frontier” AI behind billion-dollar paywalls and China just handed the keys to anyone with a GPU and a dream. Spicy contrarian angle: the real winner here isn’t geopolitics—it’s the explosion of weird, creative, uncensored experiments that closed models would never touch.
**Poll:**
A) DeepSeek V4 = death of closed-model dominance
B) Still needs Western polish to truly compete
C) Best thing to happen to indie AI builders in years
Drop your craziest DeepSeek V4 experiment idea and tag the open-source crew or KOL running the benchmarks. For more on the silicon and supply-chain angles powering these open models, follow the conversation on Telegram: t.me/ChipsForge
#AI #DeepSeekV4 #OpenSourceAI #ChinaAI #LongContext
59
May 2
**Happy Oyster AI Just Dropped the “World Engine” – You’re No Longer Generating Clips, You’re Directing Live Realities**
Alibaba’s Happy Oyster isn’t another text-to-video toy. It’s a persistent, physics-aware 3D world model that runs in real time: you prompt once, then keep directing the scene live with text, voice, or image updates while it generates up to three continuous minutes at 480p/720p. Camera pans on command. Characters change direction mid-action. Physics and causality actually respond. Two modes: Directing (you’re the live studio director) or Wandering (first-person exploration through procedurally expanding environments). No restart button needed. This is the leap from passive Sora-style clips to an actual interactive production engine.
Quick history: Traditional AI video tools (Runway, Pika, early Sora) spit out fixed 5-20 second clips from one prompt and call it a day. Happy Oyster flips the script—continuous generation with live steering, built on Alibaba’s massive multimodal training runs. Early access waitlist is already exploding among filmmakers, game devs, and YouTube creators who smell the next creator-economy gold rush. X and YouTube demos are blowing up: one creator redirected a chase scene mid-generation, another had characters improvise dialogue based on voice input. The model keeps internal state so causality doesn’t break.
What-ifs are pure sci-fi fuel. Picture scripting an entire short film in one sitting by talking to the AI like a real-time co-director. Or building a live VR world that evolves based on viewer chat commands. Humorous twist: Hollywood spent decades perfecting CGI armies and now a single prompt live typing session does it cheaper than a coffee run. Spicy reality: this tech democratizes what used to require entire VFX teams, but also floods the internet with even more convincing synthetic realities—good luck telling what’s real when your favorite creator’s “live” stream is 90% AI-orchestrated.
**Poll:**
A) World engines = the future of storytelling and gaming
B) Just more AI slop that kills authentic creativity
C) I’m already building my own AI universe tonight
Tag the filmmaker or game dev (@HappyOysterAI) who needs to see this and drop your wildest live-direction idea below. For the hardware silicon edges making these world engines possible, follow the conversation on Telegram: t.me/ChipsForge
#AI #WorldEngine #HappyOysterAI #AIVideo #RealTimeAI
66
May 2
🚨 **AI Deepfake Wildlife Slop Is Taking Over Your Feed – And Conservationists Are Losing Their Minds**
You scroll past a heartwarming clip: celebrity bald eagles Jackie and Shadow cuddling in their Big Bear nest, Shadow giving Jackie a gentle “foot massage” with those powerful talons kneading like a spa therapist. Millions of views. Comments flooding with “nature is healing ❤️”. Except it’s 100% fake. AI-generated slop, spun up from real livestream footage or pure hallucination, now flooding YouTube, TikTok, and Instagram. Bunnies trampolining. Jaguars squaring off with backyard dogs. Ravens dive-bombing the eagles. The algorithms love it because it hooks emotion, racks up ad revenue, and keeps you doom-scrolling “wildlife” content that never happened.
History lesson in 30 seconds: This isn’t the first wave of AI animal fakes, but 2026’s tools (Sora-level video cheap multimodal models) made hyper-realistic 15-second clips trivial for anyone with a prompt and 5 minutes. Producers feed copyrighted eagle-cam footage into LLMs that spit out altered behaviors—massages, attacks, impossible family moments—then slap on trending captions. One Reddit user claims 90% of the animal videos in their feed are now synthetic. Experts at the LA Times and a September *Conservation Biology* paper dropped the hammer: these clips create a false sense of abundance and safety. Viewers think predators are cuddly or wildlife is thriving, so urgency for donations, volunteering, or policy dries up. Real trail-cam footage gets drowned out. Trust in nature docs evaporates.
What-ifs hit different here. Imagine your kid learning “eagles are romantic spa-goers” from AI slop instead of actual biology class. Or a viral jaguar-dog fight inspiring some TikTok daredevil to approach a real mountain lion. Humorous twist: we built AI to explore the universe and it decided to become the world’s most convincing nature-documentary troll farm. Spicy reality: the same tech powering agentic breakthroughs is now weaponized for cheap clicks, turning conservation into content roulette.
**Poll:**
A) AI wildlife slop = harmless fun that gets people caring about animals
B) Straight-up misinformation destroying real conservation efforts
C) Next-level entertainment that beats scripted docs anyway
Drop the wildest AI animal video you’ve fallen for in replies and tag the creator or conservation account getting buried by the slop (@FOBBVCAM for the real eagle cam drama). For the granular edges on how this AI chaos ties back to the silicon powering it all, follow the conversation on Telegram: t.me/ChipsForge
#AI #Deepfakes #WildlifeAI #AISlop #ViralAI
254
May 2
Saturday morning distraction.
The toy you’re describing is the Radica 20Q (Twenty Questions) handheld electronic game, released around 2003–2005 (very close to your ~26-year timeframe).1125
It was a small, portable plastic device (roughly egg- or orb-shaped, pocket-sized, and often carried on a keychain or lanyard in practice) powered by AAA batteries. You’d think of an object, answer a series of yes/no/maybe/unknown questions on its screen/buttons, and it would guess what you had in mind—often correctly in under 20 questions. It felt magically “smart” for a cheap toy from that era.1015
The code logic behind it
Unlike a simple decision tree (which would hard-code fixed branches like “Is it an animal? → go left/right”), the 20Q used a basic artificial neural network (ANN)—specifically a weighted matrix that stored associative knowledge. Inventor Robin Burgener created it in 1988 as an AI experiment; the online version at 20q.net trained on millions of real player games, and the handheld toy shipped with a pre-trained “snapshot” of that knowledge (roughly 2,000 common objects and hundreds of thousands of synaptic connections/weights crammed onto a small chip).57
Here’s how the core algorithm worked (straight from the patent US20060230008A1 that describes the exact method used in the toy):
1Data structure = a big matrix
◦Rows = target objects (e.g., “cat”, “car”, “pizza”, etc.).
◦Columns = possible questions (e.g., “Is it alive?”, “Does it have wheels?”, “Is it bigger than a breadbox?”, etc.).
◦Each cell = a connection weight (a number, positive or negative) showing how strongly that object is associated with a “yes” answer to that question. These weights were learned from real player data (the online version kept updating them forever).40
2Two operating modes (the clever part)
◦Mode 1 (Guess objects): Player answers become inputs. The system temporarily boosts or penalizes each object’s score based on whether its matrix weights “agree” with your yes/no/maybe answer. It ranks all objects by their updated activation score.
◦Mode 2 (Pick next question): It flips the matrix and uses the current top possible objects as inputs to rank which unasked question would best split the remaining possibilities (i.e., maximum information gain / best discrimination). It tries to cut the list of candidates roughly in half each time, just like classic information theory / binary search, but weighted and fuzzy.406
3Game flow
◦Start with all objects equally possible.
◦Pick best question → ask it → update object rankings based on your answer.
◦Repeat (usually ≤20 questions).
◦At the end, output the highest-ranked object as the guess.
◦If wrong, it asks a few more questions, re-ranks, and guesses again. It could also handle “sometimes” or “unknown” answers gracefully because of the fuzzy weights.11
4Learning (in the online version; the toy was frozen)
After a game, it permanently tweaks the weights slightly to reinforce correct associations. The handheld had a static copy of a well-trained net, which is why it felt so accurate even on a tiny 2000s chip.7
In short, it wasn’t pre-programmed rules or a rigid tree—it was a simple but extremely effective associative neural net that learned statistical patterns from real human play data. That’s why it could guess weird or obscure things and still feel mind-reading-level good. The full algorithm is public in the 2005 patent if you want to see the exact math (it’s surprisingly readable for a patent).40
You can still play the modern online version at 20q.net or find emulators/apps that recreate the exact original toy behavior. Classic piece of early consumer AI!
@BrianRoemmele
49