
cs & fin @RUC1937 | ➡️ @aclmeeting 26'
Joined February 2025
- Tweets 29
- Following 67
- Followers 43
- Likes 22
7 Photos and videos




Pinned Tweet

Jun 11
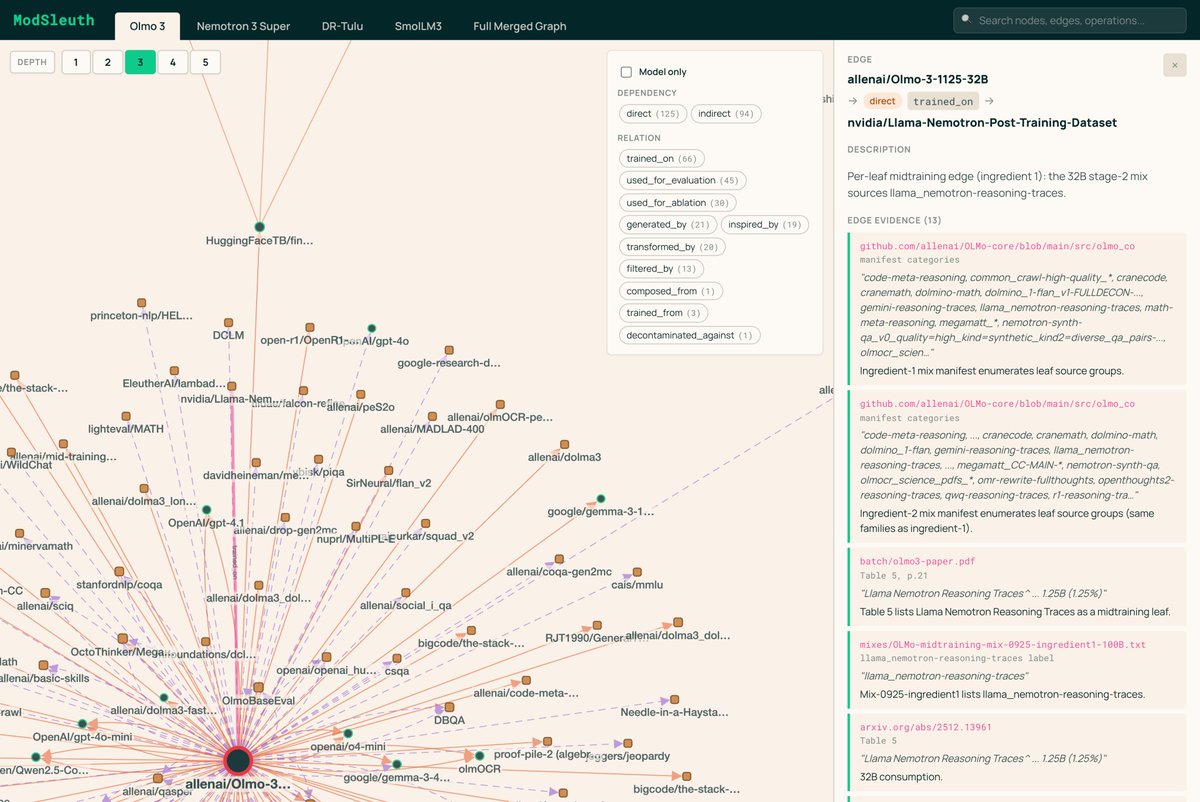
Today, LLMs are no longer built from human data alone. They rely on other LLMs to generate training data, filter corpora, evaluate outputs, provide rewards, and guide development decisions. So how many models and datasets is a modern LLM built on?
• OLMo 3 → 89 model 183 dataset dependencies
• Nemotron 3 → 273 model 560 dataset dependencies
How did we find it out? We built ModSleuth. 🧵

LLMs are no longer created w/ human data alone. They rely on other models to generate & filter data, evaluate outputs, & guide dev work.
So what is a modern LLM built on? Olmo 3 → 89 model 183 dataset dependencies; Nemotron 3 → 273 560
We made ModSleuth to trace this. 🧵

1
6
12
32,614
Jun 12
Johnny’s talk is super impressive and I highly recommend it!

I uploaded a re-recording of my defense here: youtube.com/watch?v=NtNl_m1w…
There are 3 parts:
1. Why you should spike, from the legal and statistical perspective
2. The Hubble models, a suite of open-source models to study spiking
3. Correcting test set contamination with spiking
1
3
1,148
Haoxiang Sun retweeted

Jun 11
Today, LLMs are no longer built from human data alone. They rely on other LLMs to generate training data, filter corpora, evaluate outputs, provide rewards, and guide development decisions. So how many models and datasets is a modern LLM built on?
• OLMo 3 → 89 model 183 dataset dependencies
• Nemotron 3 → 273 model 560 dataset dependencies
How did we find it out? We built ModSleuth. 🧵

LLMs are no longer created w/ human data alone. They rely on other models to generate & filter data, evaluate outputs, & guide dev work.
So what is a modern LLM built on? Olmo 3 → 89 model 183 dataset dependencies; Nemotron 3 → 273 560
We made ModSleuth to trace this. 🧵
2
13
68
10,214
Jun 11
Today, LLMs are no longer built from human data alone. They rely on other LLMs to generate training data, filter corpora, evaluate outputs, provide rewards, and guide development decisions. So how many models and datasets is a modern LLM built on?
• OLMo 3 → 89 model 183 dataset dependencies
• Nemotron 3 → 273 model 560 dataset dependencies
How did we find it out? We built ModSleuth. 🧵
LLMs are no longer created w/ human data alone. They rely on other models to generate & filter data, evaluate outputs, & guide dev work.
So what is a modern LLM built on? Olmo 3 → 89 model 183 dataset dependencies; Nemotron 3 → 273 560
We made ModSleuth to trace this. 🧵
1
6
12
32,614
Jun 11
4/ Across 4 open-source releases, ModSleuth recovers 1,060 source-verified dependencies, with chains up to 8 hops deep. This graph also surfaces findings that are hard to find manually:
• License-relevant multi-hop paths
• Train-evaluation coupling
• Mismatches between papers, cards, and code
1
124
Jun 11
Demo: modsleuth.cal-data-audit.org
Code: github.com/cal-data-audit/mo…
Paper: arxiv.org/abs/2606.12385
Built at UC Berkeley EECS, BAIR, and Berkeley NLP. @Berkeley_EECS @berkeley_ai @BerkeleyNLP
This project was co-led with @sadhikesaven - I couldn’t have pulled this off without his incredible partnership. Also a huge thanks to our advisor @sewon__min for her invaluable guidance and support throughout the whole process! 🙌 We are also incredibly grateful to Kyle Lo, Noah Smith, Hanna Hajishirzi, Rishi Bommasani, and the wider SM group & Ai2 members for their constructive feedback.
We’d love to hear your thoughts! Let’s build a more transparent LLM ecosystem together.
122
Haoxiang Sun retweeted

May 27
Flash-KMeans was only the beginning.
Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators.
Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML).
Blog: flashml-org.github.io/
Code: github.com/FlashML-org/flash…
47
236
1,606
865,900
Haoxiang Sun retweeted

Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.

33
154
1,230
222,062
Haoxiang Sun retweeted

MoEs are everywhere in frontier models, and they are deployed as a monolith system.
But many applications only need a narrow slice of capabilities, e.g., math, code, biomedical, etc.
So what if "modularity" is actually the missing opportunity for MoEs?
Today, we're releasing EMO: an end-to-end pretrained MoE where modularity emerges naturally, enabling selective use of experts!

Today we’re releasing EMO, a new mixture-of-experts (MoE) model trained so modular structure emerges directly from data without human-defined priors.
EMO can use a small subset of its experts for a given task while keeping near full-model performance. 🧵

7
73
530
115,388
Haoxiang Sun retweeted

May 3
Failed Agent experiments can be publishable too🤯
Introducing ICML 2026 Workshop Failure Modes in Agentic AI!
We welcome negative results, failed rollouts, debugging traces, reproducible failure cases, and analysis of why agents break.
📍FAGEN @ ICML 2026
🗓 Submission deadline: May 8 11:59 PM AOE
🗓 Notification: May 15
🔗fmai-workshop.github.io
Find it. Reproduce it. Trace it. Fix it.
We also welcome relevant ICML submissions, especially papers with strong insights that may not have found the right home in the main track!

1
18
65
15,647
Haoxiang Sun retweeted

Apr 24
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

1,649
7,637
45,739
9,878,944
Haoxiang Sun retweeted
Apr 20
Imagine you fully post-trained "YourModel v1". Then, you've got better data — math, code, tool use, safety — and you want to improve it.
Today, that usually means retraining the whole model.
But what if new data could be added modularly, with a fixed cost each time?
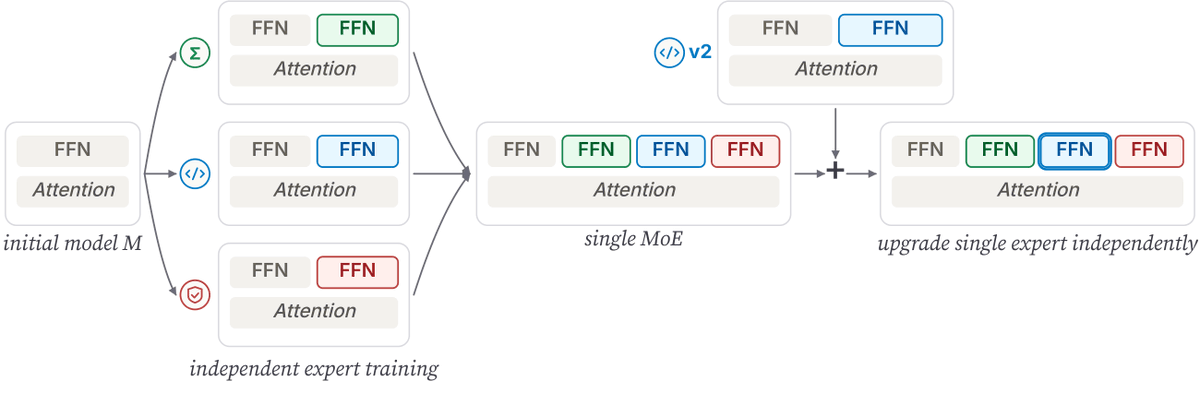
Last year, we introduced FlexOlmo, a novel way to train parts of a model independently then combine them later.
BAR builds on that idea for a harder problem: how to keep improving a model without having to retrain each time. 🧵

5
18
139
19,639

wrote a guide on getting compute grants as a student, something I wish I did more at the beginning of my PhD. It's honestly one of the highest ROI things you can do as a student (we've gotten 100k gpu hrs for roughly 2 weeks of work writing).
nightingal3.github.io/blog/2…
16
200
1,384
237,421
Haoxiang Sun retweeted
Jan 27
AlphaGo’s 10-year anniversary today — huge milestone for RL!
Small serendipity: it’s also 1 year since we released 𝐑𝐀𝐆𝐄𝐍, our LLM Agent RL framework.
Some thoughts on the past decade of RL, plus a major 𝐑𝐀𝐆𝐄𝐍 update on reasoning collapse in Agent RL coming soon.
1/
Ten years ago, on Jan 27, DeepMind brought AlphaGo to the world.
Back then, RL felt mythic. For the first time, it reached top professional-level in a domain that demands long-horizon planning -- already gone 5–0 against the European champion.
That moment made a lot of people truly believe this: a policy can “grow out of interaction” instead of being hand-coded or hand-taught.
One year ago, on Jan 27, we released RAGEN, an RL codebase for LLM agents.
We started applying RL with verifiable rewards beyond ‘winning a game’ to large reasoning models that can plan and interact with the world. RL
is no longer just about winning inside a closed board. It now plays out in a more open, long-horizon training loop that can resemble parts of the real world.
But in this year, we also saw a quieter kind of collapse.
It does not always look like failure. Sometimes it looks stable. Sometimes it even looks safer and more consistent. Yet the policy slowly turns into a “persona”, a “template”, a “low-effort sense of security”.
So I’ve increasingly felt that 𝐑𝐀𝐆𝐄𝐍 isn’t just a system. For me, it reads more like the second half of a decade-long thread I’ve been watching unfold.
The first half: “RL can learn reasoning.”
The second half: “RL can also quietly collapse if we don’t have the right diagnostics.”
It feels like a time marker: ten years later, we’re finally forced to look beyond reward and ask what stays input-conditioned—and what drifts.
2/
If I use this coincidence as an anchor, I would split the last decade of RL into three chapters.
The AlphaGo era: RL proved itself on long-horizon planning. It proved policies can emerge from interaction;
The RLHF era: RL moved from winning games to alignment. It became a core mechanism that makes language models track human preferences. It became a key part behind many products today;
The LLM Agent RL era: RL enters closed-loop, multi-turn self-training. The LLM agent learns more than answers. It learns plans, tools, revisions, reflection, and behavioral consistency across longer time scales.
Put together, these chapters point to a missing piece for me: we still lack a clear, shared vocabulary and practical gauges for “failure modes in LLM Agent RL”.
Progress has been fast on the capability side. But the language and gauges for how LLM agents degrade—especially in closed-loop training—still feel less settled.
That’s the piece we’ve been trying to put words and measurements to this year.
3/
A decade after AlphaGo, a lot of the attention and resources in RL do seem to be shifting from closed worlds like board games toward systems like LLM agents.
At the same time, closed-loop self-training can introduce a more systemic risk. In a loop of self-sampling and self-updating, a model can gradually settle into a “task-insensitive but cheaper” strategy.
It does not look terrible. It may even look safe and consistent. But it slowly loses prompt “discriminability”. It can lose the property that makes reasoning actually change with the input.
I like to define this with one sentence: “training continues, but learning is idling”.
Rewards still move. Gradients still update. But the information is already dry. The policy solidifies toward templates, inertia, and risk-avoidance.
One transferable takeaway from our year with 𝐑𝐀𝐆𝐄𝐍 is this:
In LLM Agent RL, it’s not enough to only watch the reward or success rate. You must also watch whether “input-conditioned information” is still flowing. You must watch whether the LLM agent is still sensitive to the task.
We are now preparing a new version of 𝐑𝐀𝐆𝐄𝐍. You do not need to believe any result in advance. But we will make this line much clearer: how the battlefield shifts, how the new collapses happen, and which diagnosis view is the most actionable.
4/
Here I want to write something more personal, because this part wasn’t “thought up”. It was almost collided into.
Right before writing this, I was sprinting on the new 𝐑𝐀𝐆𝐄𝐍. After days of deadline pressure, I finally took a breath and noticed the date coincidence. Thinking about the past year, I started crying. When I actually began typing, the tears had just stopped.
I looked at the time. It was 5pm, Jan 20, 2026, and my screen had gone dark. The contrast made the point feel sharper.
This year wasn’t about “one more loss term” or “one more trick”. It was about a latent variable that kept showing up in closed-loop LLM Agent RL, but is hard to name cleanly: whether the agent’s reasoning is still tied to the input.
Training can keep running while reasoning drifts into templates, inertia, and avoidance. Reward can still move while prompt discriminability quietly erodes.
“More stable, more certain” can sometimes just mean “less sensitive, less distinctive”. Collapse is rarely a sudden crash. It’s usually a slow drift that looks fine from the outside.
That’s what I mean by a quiet failure mode. Not bad news, just something we’d benefit from better gauges for.
And on a personal note, learning to notice this earlier has changed how I work. The hits still come. I just recover faster, and keep moving.
5/
Then I looked back at the past year’s timeline and noticed another coincidence.
DeepSeek-R1 landed on Jan 20, 2025 — the same date I happened to notice the AlphaGo/RAGEN alignment.
I’ll treat it as coincidence, but it did make the moment feel unexpectedly vivid.
Since then, I’ve been jokingly calling 01/20 my “dark mode day”.

2
12
51
52,370


Haoxiang Sun retweeted

28 Apr 2025
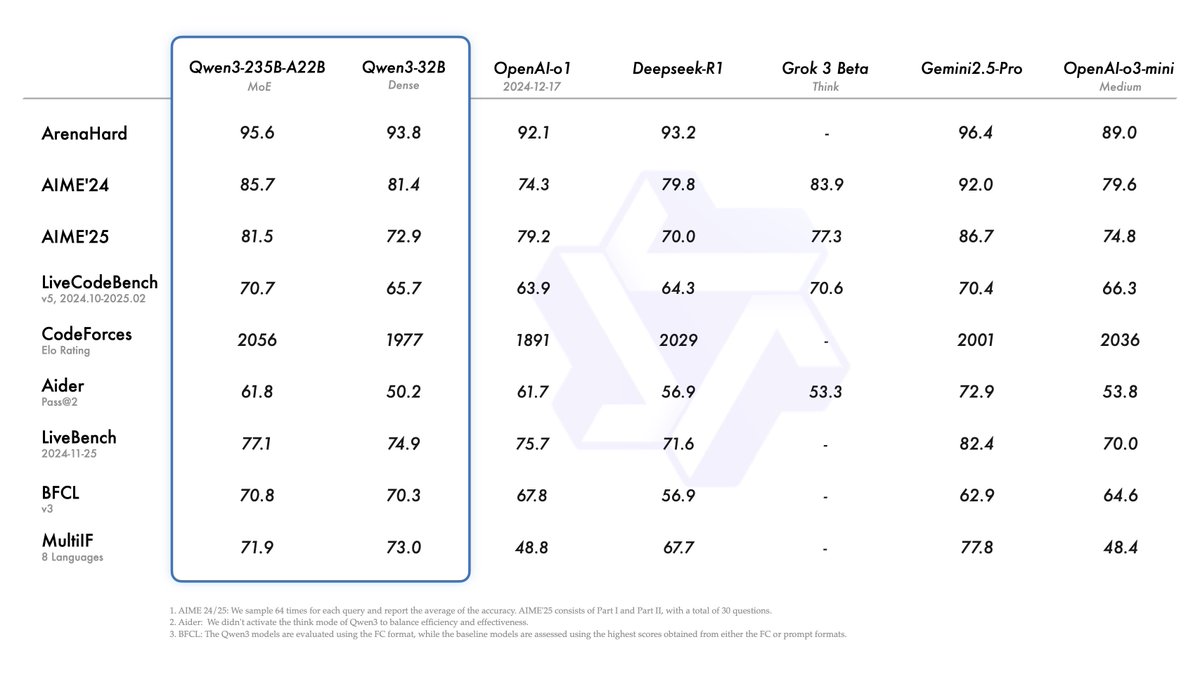
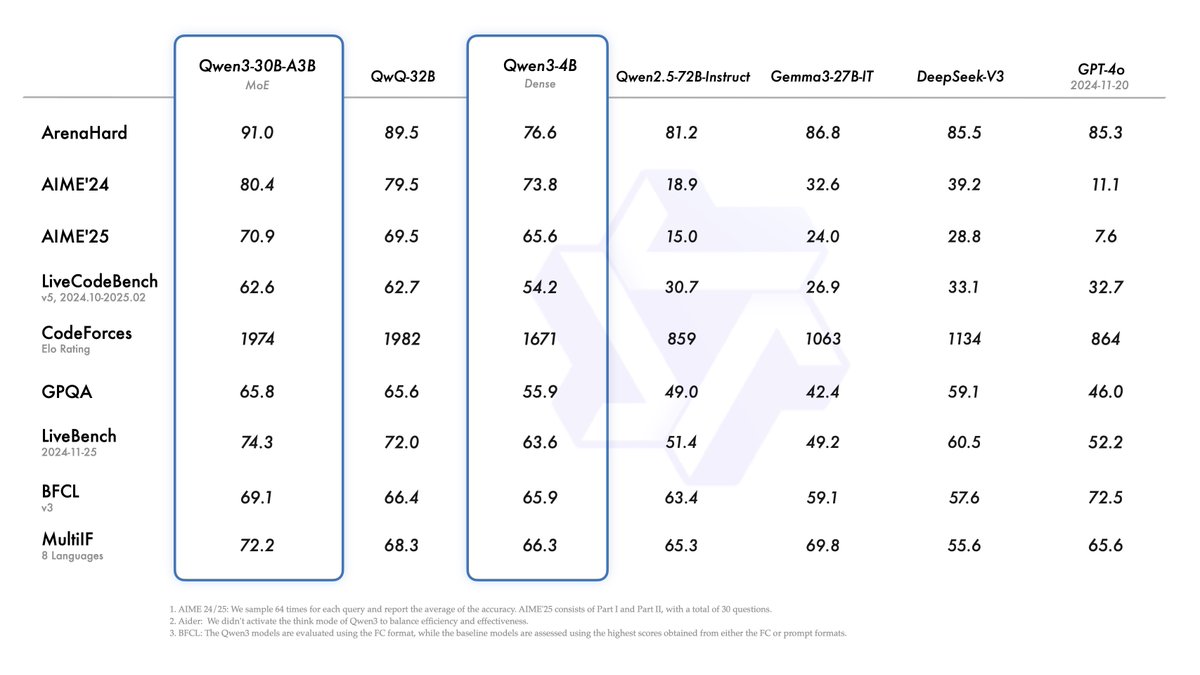
Introducing Qwen3!
We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general capabilities, etc., when compared to other top-tier models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. Additionally, the small MoE model, Qwen3-30B-A3B, outcompetes QwQ-32B with 10 times of activated parameters, and even a tiny model like Qwen3-4B can rival the performance of Qwen2.5-72B-Instruct.
For more information, feel free to try them out in Qwen Chat Web (chat.qwen.ai) and APP and visit our GitHub, HF, ModelScope, etc.
Blog: qwenlm.github.io/blog/qwen3/
GitHub: github.com/QwenLM/Qwen3
Hugging Face: huggingface.co/collections/Q…
ModelScope: modelscope.cn/collections/Qw…
The post-trained models, such as Qwen3-30B-A3B, along with their pre-trained counterparts (e.g., Qwen3-30B-A3B-Base), are now available on platforms like Hugging Face, ModelScope, and Kaggle. For deployment, we recommend using frameworks like SGLang and vLLM. For local usage, tools such as Ollama, LMStudio, MLX, llama.cpp, and KTransformers are highly recommended. These options ensure that users can easily integrate Qwen3 into their workflows, whether in research, development, or production environments.
Hope you enjoy our new models!
346
1,571
8,031
2,214,936
Haoxiang Sun retweeted
23 Apr 2025
Why does your RL training always collapse?
In our new paper of RAGEN, we explore what breaks when you train LLM *Agents* with multi-turn reinforcement learning—and possibly how to fix it.
📄 github.com/RAGEN-AI/RAGEN/bl…
🌐 ragen-ai.github.io/
1/🧵👇

8
86
435
100,655

Introducing OpenAI o3 and o4-mini—our smartest and most capable models to date.
For the first time, our reasoning models can agentically use and combine every tool within ChatGPT, including web search, Python, image analysis, file interpretation, and image generation.
830
1,693
10,424
3,719,715
GPT-4.1 in the API
openai.com/live/
318
505
3,976
950,867