
We work on natural language processing, machine learning, linguistics, and deep learning. PIs: Dan Klein, @alsuhr, @sewon__min
Joined September 2019
- Tweets 129
- Following 37
- Followers 6,528
- Likes 134
5 Photos and videos



BerkeleyNLP retweeted

Jun 11
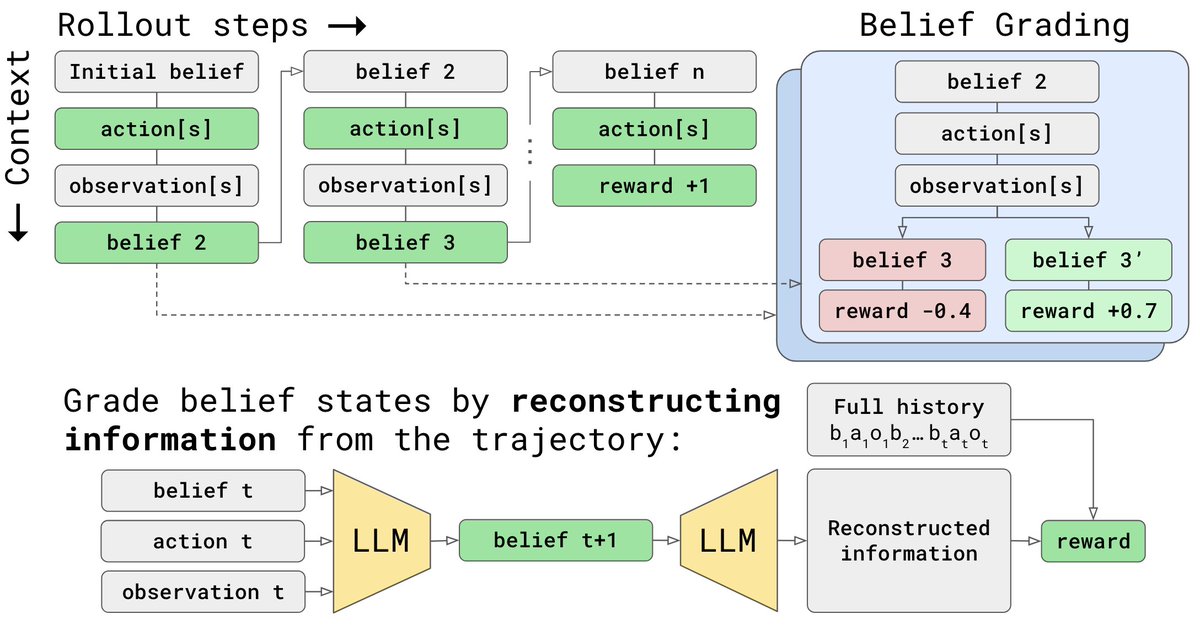
As task horizons grow, LLM contexts can’t scale forever. Self-summarization enables concise, interpretable contexts but at a significant performance cost.
Our solution: isolate and *supervise* the information content of summaries in the form of natural-language belief states 🧵
3
11
36
4,805
BerkeleyNLP retweeted

Jun 11
One day I tried tracing all of Olmo's dependencies manually. A few hours later, I realized I can't do it and gave up. Then @sadhikesaven and @CoderBak ModSleuth 🔥
Turns out Olmo and Nemotron have hundreds of dependencies that are super deep, recursive, and not easily visible. I'm glad I gave up early 😅
Spoiler: I thought this would be a one-week Claude Code project. It was not.
The hard part wasn't information extraction (which Claude Code is good at). The hard part was something much trickier. Check out the paper to learn more!
(And yes, if a model release says it used Claude Code, ModSleuth will trace that too... which means the model depends on Claude Code, which has its own dependencies, and ModSleuth itself depends on Claude Code 🤯)

LLMs are no longer created w/ human data alone. They rely on other models to generate & filter data, evaluate outputs, & guide dev work.
So what is a modern LLM built on? Olmo 3 → 89 model 183 dataset dependencies; Nemotron 3 → 273 560
We made ModSleuth to trace this. 🧵

2
21
146
22,314
BerkeleyNLP retweeted

Jun 10
The web was never meant to be flattened into text.
Yet most web RAG systems start by parsing HTML --- a complex and lossy process.
🔥 Introducing PixelRAG: the first RAG system that retrieves and reads 30M web pages as pixels.
Instead of extracting text, PixelRAG retrieves screenshots and lets a VLM read them directly.
PixelRAG not only preserves visual information, but also outperforms text-based RAG on text-only QA benchmarks by 18.1%.
Why?
(1) HTML-to-text conversion often discards layout, structure, tables, and other useful signals.
(2) We continued pretraining a VLM on web page screenshots and turned it into a surprisingly strong visual retriever.
(3) Recent VLMs are remarkably good at understanding web pages, often with better accuracy and token efficiency than text-only pipelines.
Takeaway: HTML parsing may be one of the biggest self-inflicted bottlenecks in web RAG.
Demo below 👇
Code: github.com/StarTrail-org/Pix…
Paper: github.com/StarTrail-org/Pix…
Playground: pixelrag.ai/
25
116
693
72,037
BerkeleyNLP retweeted
Jun 10
Super excited about this work, led by @YichuanM and @andylizf ! It is possible to completely remove HTML parsing by directly retrieving and reading web screenshots through VLM.
HTML parsing is a hidden bottleneck that causes significant complexity and information loss that nobody really pays attention to, and it's so exciting that VLM progress made it possible to remove it.
Please check out this demo as well which is really cool!!! pixelrag.ai
Jun 10

The web was never meant to be flattened into text.
Yet most web RAG systems start by parsing HTML --- a complex and lossy process.
🔥 Introducing PixelRAG: the first RAG system that retrieves and reads 30M web pages as pixels.
Instead of extracting text, PixelRAG retrieves screenshots and lets a VLM read them directly.
PixelRAG not only preserves visual information, but also outperforms text-based RAG on text-only QA benchmarks by 18.1%.
Why?
(1) HTML-to-text conversion often discards layout, structure, tables, and other useful signals.
(2) We continued pretraining a VLM on web page screenshots and turned it into a surprisingly strong visual retriever.
(3) Recent VLMs are remarkably good at understanding web pages, often with better accuracy and token efficiency than text-only pipelines.
Takeaway: HTML parsing may be one of the biggest self-inflicted bottlenecks in web RAG.
Demo below 👇
Code: github.com/StarTrail-org/Pix…
Paper: github.com/StarTrail-org/Pix…
Playground: pixelrag.ai/
4
14
126
22,773
BerkeleyNLP retweeted
May 25
Really amazing results analyzing what's creative/novel vs. what's copied from Internet data, enabled by the amazing @liujc1998's Infini-gram! infini-gram.io
This is also enabled in @allen_ai's OlmoTrace allenai.org/blog/olmotrace where anyone can find matching n-grams between LLM-generated text and its training data.
May 22

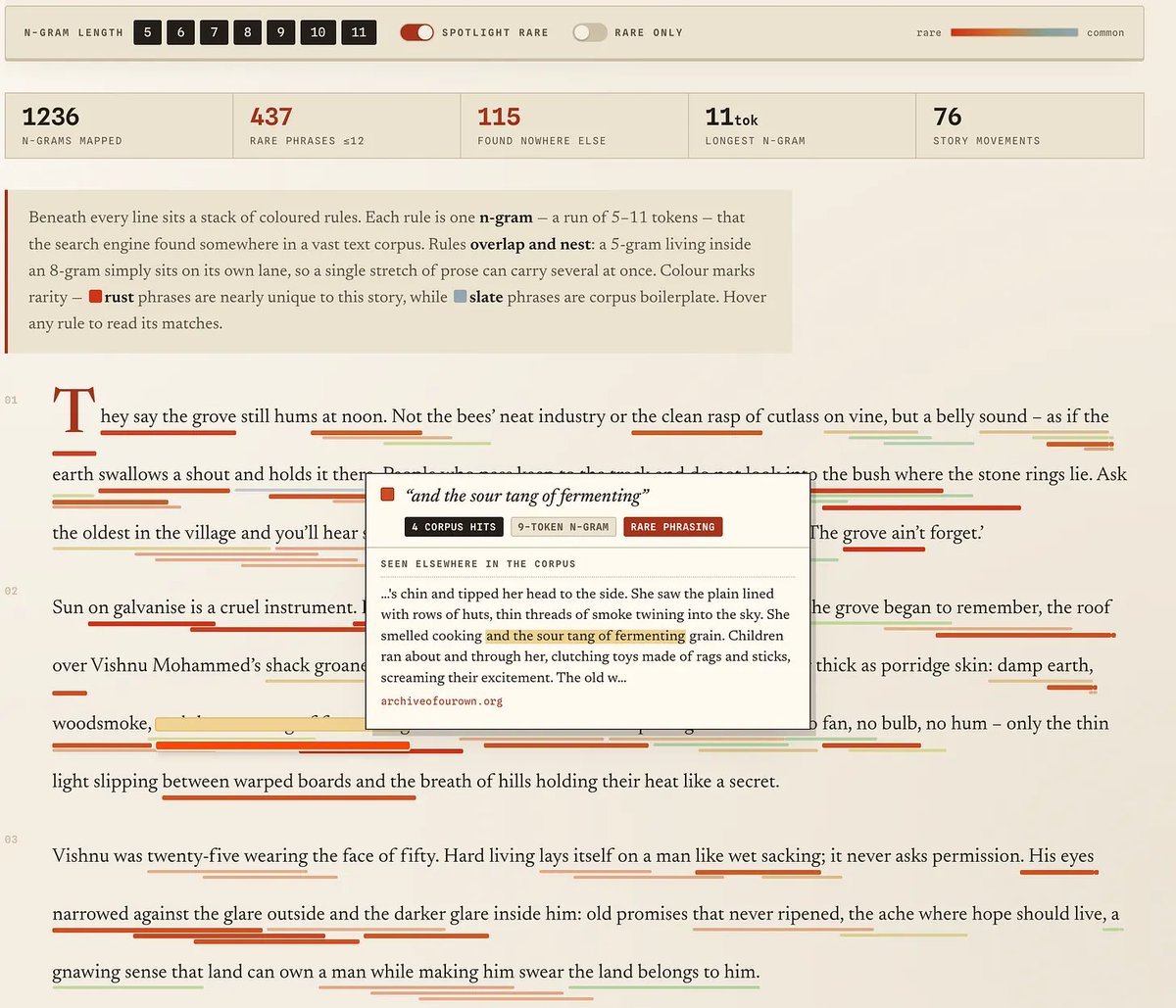
This from @TuhinChakr is brilliant. That prize winning story from Granta? Turns out it's just a bunch of random whole phrases taken directly from existing text on the internet. Tool allows you to trace those n-grams directly to their source, which is mostly random fanfiction.
tuhinchakrabarty.substack.co…
1
10
83
16,996
BerkeleyNLP retweeted

May 12
1/ Thrilled to introduce T³: a corpus for RAG over reasoning tasks, built from thinking traces.
We show that surprisingly RAG can improve reasoning— with the right corpus.
Rag with Transformed Thinking Traces T³ gain by up to 43.9% on AIME 2025-2026.
🔗 arxiv.org/abs/2605.03344 🧵

11
30
211
472,669
BerkeleyNLP retweeted

8/ For reproducibility and to enable further study of modularity in MoEs, we’re releasing EMO, baselines, and code:
Models: hf.co/collections/allenai/em…
Blog: allenai.org/blog/emo
Code: github.com/allenai/EMO
Viz: emovisualization.netlify.app
Shoutout to @AkshitaB93 @sewon__min for making this possible!
1
3
15
1,479
BerkeleyNLP retweeted
May 8
Full details results: arxiv.org/abs/2605.06663
Also check this out emovisualization.netlify.app: Our model specializes qualitatively differently (capability-level rather than lexical) -- this emerged naturally even though we didn't expose any domain prior!
3
29
2,227
BerkeleyNLP retweeted
May 8
As MoEs grow larger and sparser, they become memory-bottlenecked.
What if experts were actually composable - so you only keep the subset relevant to your task?
We show that this doesn't emerge in standard MoEs (their training makes this hard), but you can pre-train MoEs to support this kind of modularity!
I hope everyone sees the right figure from @RyanYixiang 's original post - I was so excited when I saw this result!!

MoEs are everywhere in frontier models, and they are deployed as a monolith system.
But many applications only need a narrow slice of capabilities, e.g., math, code, biomedical, etc.
So what if "modularity" is actually the missing opportunity for MoEs?
Today, we're releasing EMO: an end-to-end pretrained MoE where modularity emerges naturally, enabling selective use of experts!

4
43
326
49,121
BerkeleyNLP retweeted
MoEs are everywhere in frontier models, and they are deployed as a monolith system.
But many applications only need a narrow slice of capabilities, e.g., math, code, biomedical, etc.
So what if "modularity" is actually the missing opportunity for MoEs?
Today, we're releasing EMO: an end-to-end pretrained MoE where modularity emerges naturally, enabling selective use of experts!
Today we’re releasing EMO, a new mixture-of-experts (MoE) model trained so modular structure emerges directly from data without human-defined priors.
EMO can use a small subset of its experts for a given task while keeping near full-model performance. 🧵

7
73
530
115,357
BerkeleyNLP retweeted
Apr 25
I will give two talks at ICLR workshops!! 🇧🇷
Sunday 9:40-10:10:
"LLMs for Distributed Data Use" @ Workshop on Data Problems in Foundation Models (Room 203 A/B)
Monday 15:30–16:05 :
"Are Mixture-of-Experts Modular? Why It Matters and How to Fix It" @ ICBINB Workshop (Room 201 C)
Both happened to be related to MoEs, but tackle two completely different questions → some say hi!
2
9
130
12,745
BerkeleyNLP retweeted

Apr 20
Imagine you fully post-trained "YourModel v1". Then, you've got better data — math, code, tool use, safety — and you want to improve it.
Today, that usually means retraining the whole model.
But what if new data could be added modularly, with a fixed cost each time?
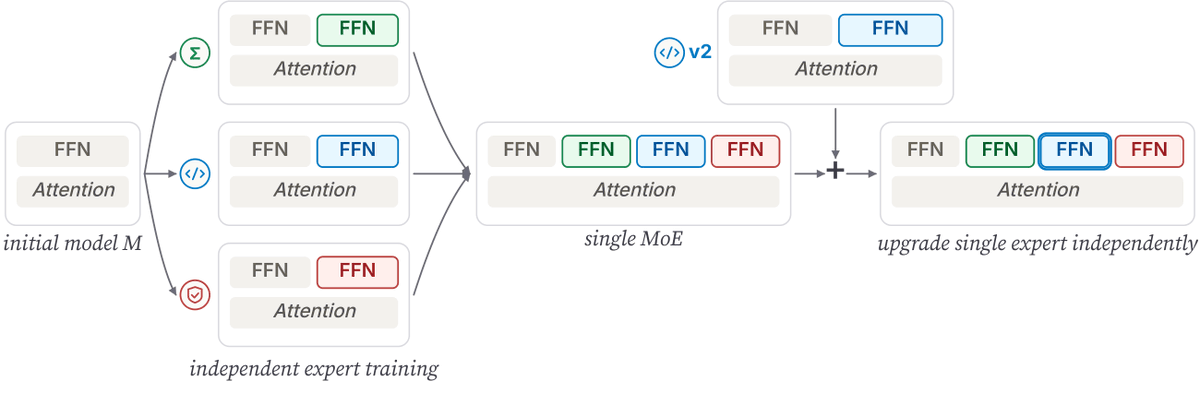
Last year, we introduced FlexOlmo, a novel way to train parts of a model independently then combine them later.
BAR builds on that idea for a harder problem: how to keep improving a model without having to retrain each time. 🧵

5
18
139
19,638
BerkeleyNLP retweeted
Feb 17
Exciting results on open-source modes for IMO-level problems - congratulations to @aviral_kumar2 and everyone involved!! Great to see @wenjie_ma's ProofGrader (proofgrader.github.io) integrated into the development ✨
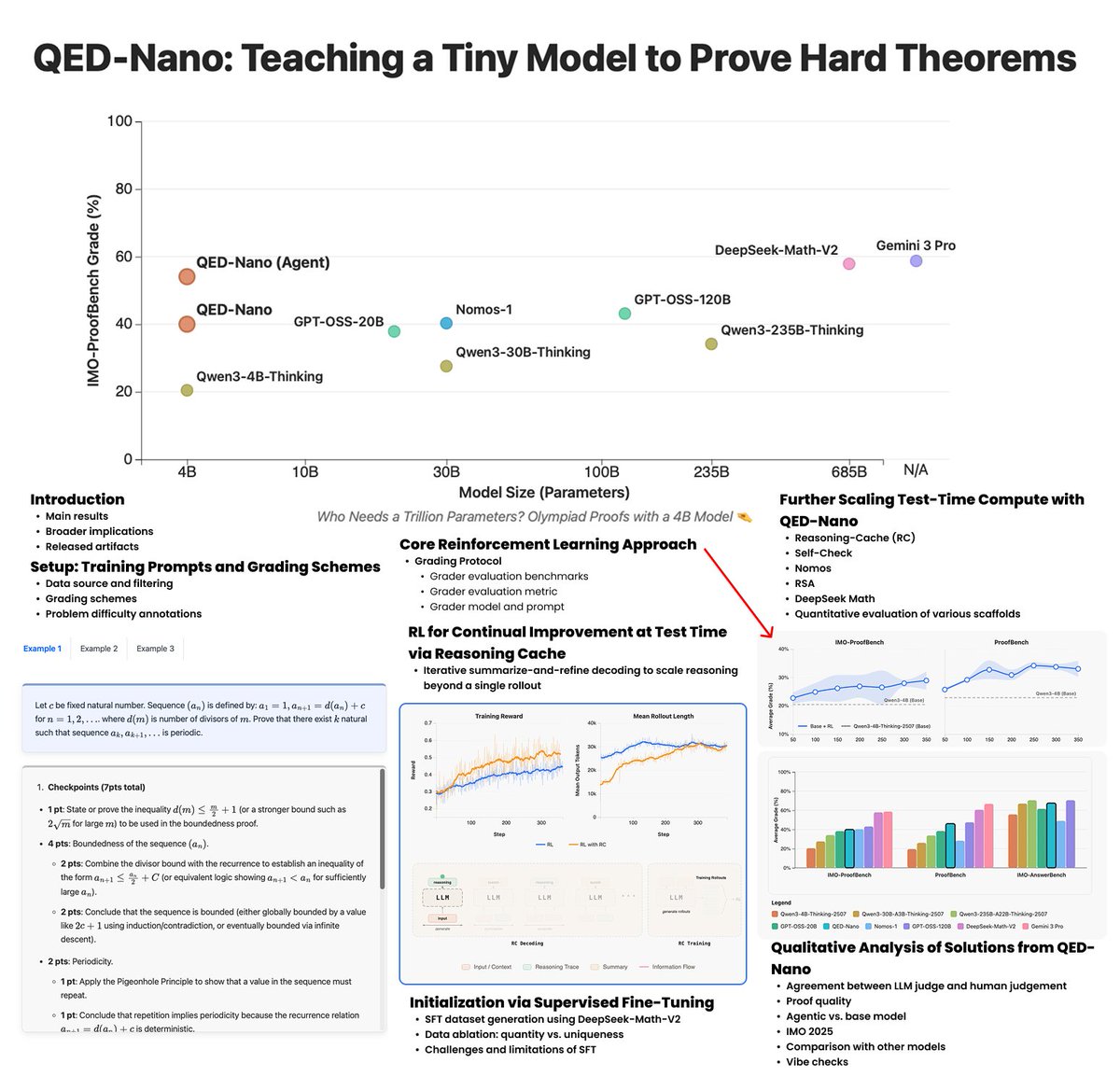
Feb 15

We trained a tiny 4B model to reason for millions of tokens through IMO-level problems.
Heaps excited to share our new blog post covering the full pipeline, from distilling the 🐳 to augmenting RL with a reasoning cache that unlocks extreme inference-time scaling for theorem proving.
huggingface.co/spaces/lm-pro…
11
83
11,951
BerkeleyNLP retweeted
12 Dec 2025
Really excited about this work!! As a retrieval person, having a pre-training-scale retrieval index in an academic setting has long been a dream, and I thought it would be too difficult / infeasible. Collaborating with systems experts made it possible much earlier than I expected. Huge thanks to the students driving this: @YichuanM and @jinjianliuu !
12 Dec 2025
(1/N) 🚀 DS-Serve is a framework for efficient, scalable neural retrieval — it turns any in-house dataset (<1T tokens) into a high-throughput (up to 10,000 QPS), low-latency (<100ms), memory-efficient (<200GB RAM) retrieval system with a web UI and API.
With DS-Serve, we publicly deployed a 400B-token datastore of high-quality LLM pretraining data (2B vectors), spanning academic resources — and it matches commercial search endpoints on our benchmarks at extremely low latency and high throughput.
Try it out: api.ds-serve.org:30888/ui
Blog: berkeley-large-rag.github.io…
Work from UC Berkeley ( @BerkeleyNLP & @BerkeleySky) with collaborators at UW & UIUC!
5
16
119
23,326
BerkeleyNLP retweeted
12 Dec 2025
(1/N) 🚀 DS-Serve is a framework for efficient, scalable neural retrieval — it turns any in-house dataset (<1T tokens) into a high-throughput (up to 10,000 QPS), low-latency (<100ms), memory-efficient (<200GB RAM) retrieval system with a web UI and API.
With DS-Serve, we publicly deployed a 400B-token datastore of high-quality LLM pretraining data (2B vectors), spanning academic resources — and it matches commercial search endpoints on our benchmarks at extremely low latency and high throughput.
Try it out: api.ds-serve.org:30888/ui
Blog: berkeley-large-rag.github.io…
Work from UC Berkeley ( @BerkeleyNLP & @BerkeleySky) with collaborators at UW & UIUC!
5
52
174
66,769
BerkeleyNLP retweeted

20 Oct 2025
✨Introducing ECHO, the newest in-the-wild image generation benchmark!
You’ve seen new image models and new use cases discussed on social media, but old benchmarks don’t test them!
We distilled this qualitative discussion into a structured benchmark.
🔗 echo-bench.github.io
4
31
129
47,364
BerkeleyNLP retweeted
17 Oct 2025
Super excited about @wenjie_ma's work on verifying math proofs!
✅ 24 competitions, 3 SoTAs (o3, Gemini-2.5-Pro, R1)
✅ Strong evaluator -- a carefully designed evaluator with simple ensemble beats agentic ones
✅ Strong best-of-n performance
Check out the paper & website!
17 Oct 2025

LLMs solving math benchmarks with verifiable answers like AIME? ✅
LLMs solving math proofs? ❌ Still an open problem.
RL works great for final-answer problems, but proofs are different:
- Often no single checkable answer
- Correct answers can hide flawed reasoning
The key bottleneck: reliable proof evaluation. Without a good evaluator, we can't automatically evaluate or train better "provers."
Our new work tackles this challenge step by step. 🧵
📄 Paper: arxiv.org/pdf/2510.13888
3
12
116
32,364
BerkeleyNLP retweeted

17 Oct 2025
LLMs solving math benchmarks with verifiable answers like AIME? ✅
LLMs solving math proofs? ❌ Still an open problem.
RL works great for final-answer problems, but proofs are different:
- Often no single checkable answer
- Correct answers can hide flawed reasoning
The key bottleneck: reliable proof evaluation. Without a good evaluator, we can't automatically evaluate or train better "provers."
Our new work tackles this challenge step by step. 🧵
📄 Paper: arxiv.org/pdf/2510.13888
9
37
196
60,438

Happy to announce the first workshop on Pragmatic Reasoning in Language Models — PragLM @ COLM 2025! 🧠🎉
How do LLMs engage in pragmatic reasoning, and what core pragmatic capacities remain beyond their reach?
🌐 sites.google.com/berkeley.ed…
📅 Submit by June 23rd
6
20
94
57,991
BerkeleyNLP retweeted

16 May 2025
Last day of PhD!
I pioneered using LLMs to explain dataset&model. It's used by interp at @OpenAI and societal impact @AnthropicAI
Tutorial here. It's a great direction & someone should carry the torch :)
Thesis available, if you wanna read my acknowledgement section=P
30
35
541
57,900