
Expert AI for advanced industries
Joined March 2023
- Tweets 259
- Following 22
- Followers 5,207
- Likes 303
98 Photos and videos












Pinned Tweet

Jan 27
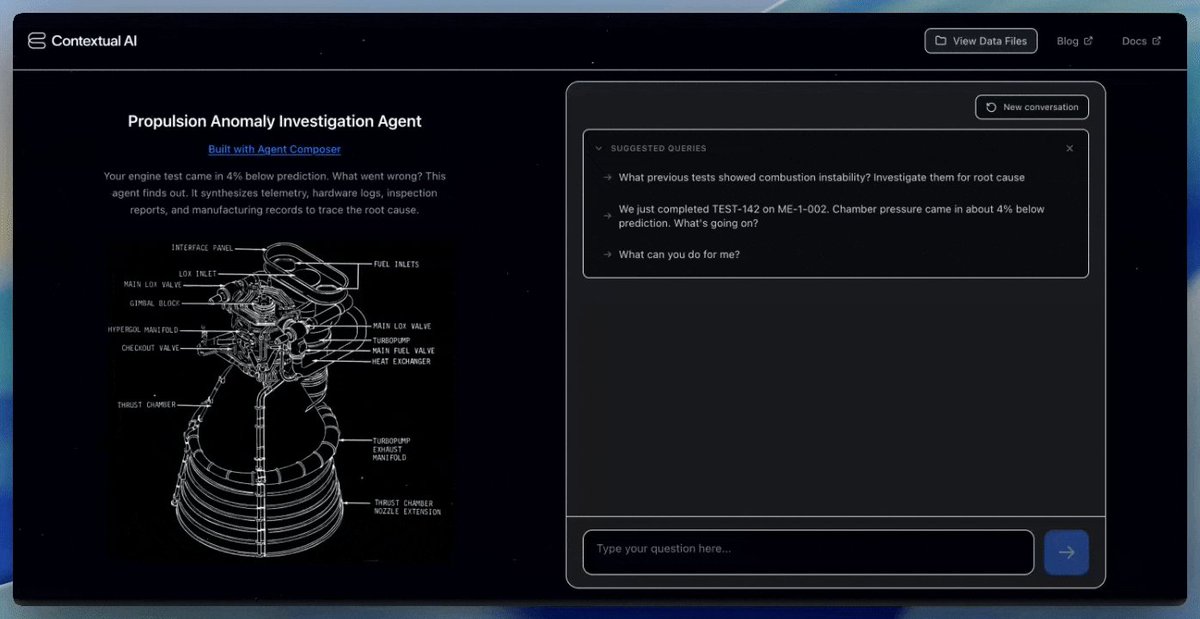
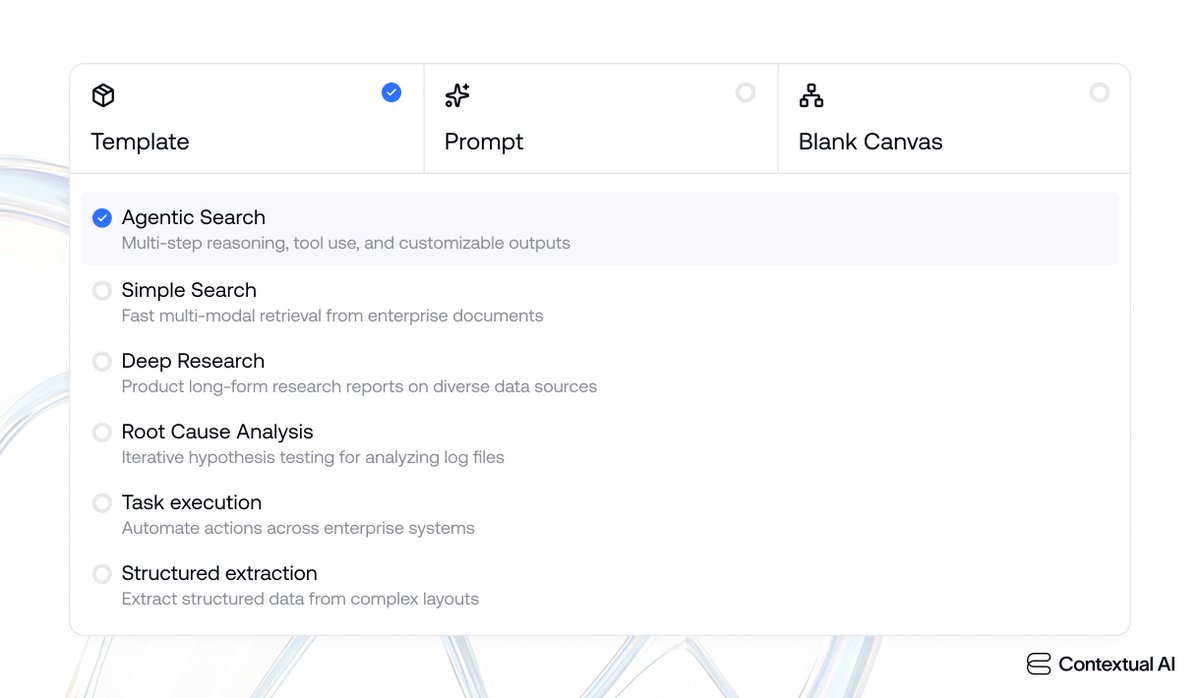
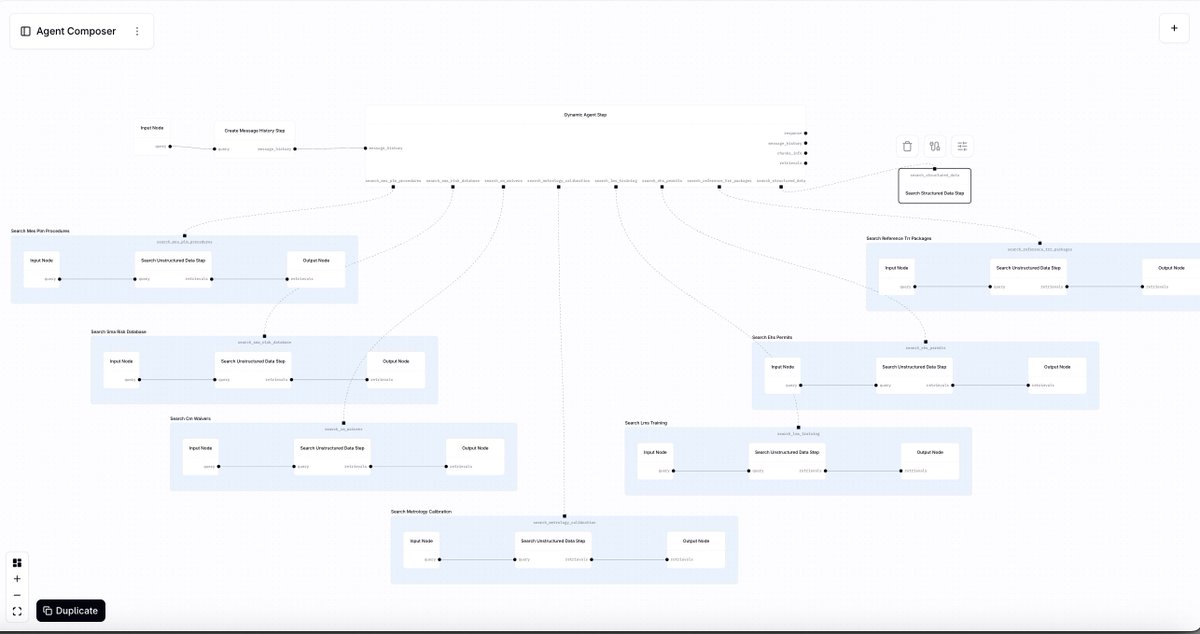
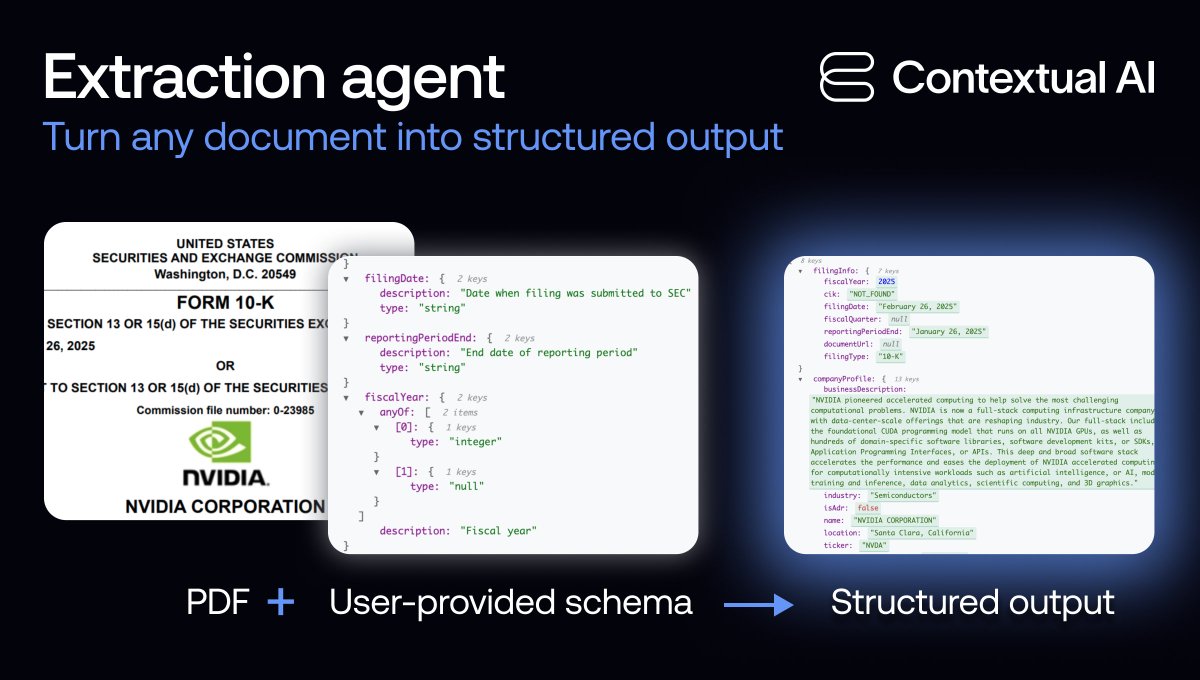
Announcing Agent Composer: AI that works when it actually IS rocket science.
Technical teams can now automate the routine (but complex) tasks that used to take hours every week—root cause analysis, production planning, test code generation— and reduce them down to minutes, so you can get your real work done.
Here's how we solved the AI context problem for hard engineering tasks (like rocket science 🚀)
🧵
29
47
500
1,552,217
Apr 1
Stop spending days manually root-causing infotainment failures across a dozen subsystems and three different teams.
Generic AI breaks here — logs are too large, too fragmented, too system-specific.
Our multi-agent workflow processes multiple subsystem logs simultaneously and delivers a complete root cause report in minutes — no file size limits, any format, grounded in your debug specs.
Try it → demo.contextual.ai
2
5
756
Contextual AI retweeted

Mar 5
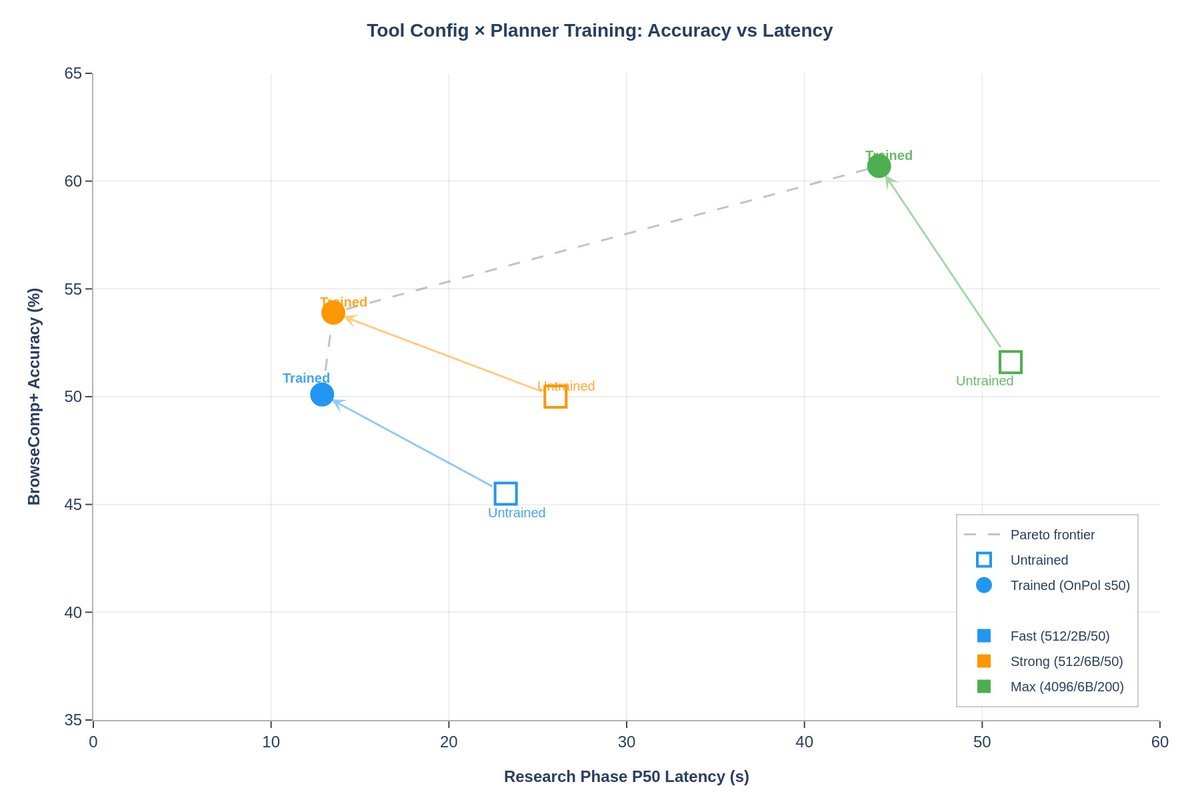
Search agents, whether they're powering deep research, or multi-step QA over a private corpus, spend most of their time and compute in the research loop: query, search, reason, repeat.
We wanted to make that loop faster and more accurate. So we optimized two things jointly: the retrieval stack itself, and the planner that decides when and how to search.
A trained planner on our fastest retrieval config matches an untrained planner on the most expensive one, at half the latency. Every arrow in this plot points up and to the left. [1/n]
3
9
59
74,276
Mar 5
Stop spending 8 hours manually root-causing semiconductor device failures.
Generic AI breaks here — logs are too large, error codes too device-specific.
Our agentic workflow processes multiple logs simultaneously and delivers a complete root cause report in 20 min or less — no file size limits, any format, grounded in your device specs. 🚀
Try it → demo.contextual.ai
5
7
629
Feb 6
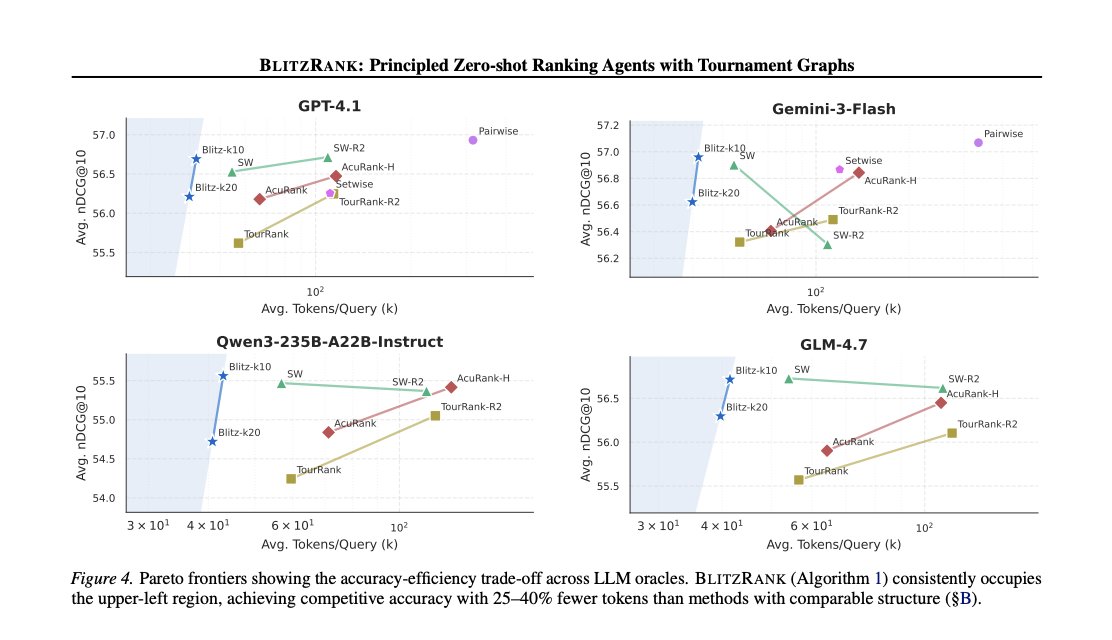
Excited to share our latest breakthrough: ⚡BlitzRank!
This innovative LLM reranker optimizes token usage with tournament graphs, delivering 25-40% efficiency gains while maintaining top-tier quality across benchmarks.
Huge props to @sheshanshag and @Thienhn97 for this excellent work.
Check it out: blitzrank.ai/

**New research: Introducing ⚡BlitzRank**
Current LLM rerankers waste tokens on information they already have. If A > B and B > C, you already know A > C, existing methods don’t track this.
BlitzRank fixes this. It uses tournament graphs to extract maximal information from each LLM call.
📊 Pareto-optimal across 14 benchmarks × 5 LLMs
⚡ 25–40% fewer tokens than comparable methods
⚡ 7× cheaper than pairwise at near-identical quality
1
2
11
1,389
Contextual AI retweeted
**New research: Introducing ⚡BlitzRank**
Current LLM rerankers waste tokens on information they already have. If A > B and B > C, you already know A > C, existing methods don’t track this.
BlitzRank fixes this. It uses tournament graphs to extract maximal information from each LLM call.
📊 Pareto-optimal across 14 benchmarks × 5 LLMs
⚡ 25–40% fewer tokens than comparable methods
⚡ 7× cheaper than pairwise at near-identical quality
4
20
72
18,934
Feb 5
❌ Stop manually searching semiconductor datasheets, support logs, and device files to troubleshoot customer issues.
Use context-aware AI that automates research in minutes, not hours—investigating vague questions, synthesizing answers, and verifying sources with bounding box attribution
⚡️ Try the Raspberry Pi docs agent or build your own in minutes: demo.contextual.ai/customer-…
1
3
3
1,066
Contextual AI retweeted

Jan 28
Contextual AI just killed n8n.

8
8
135
13,636
Jan 27
Announcing Agent Composer: AI that works when it actually IS rocket science.
Technical teams can now automate the routine (but complex) tasks that used to take hours every week—root cause analysis, production planning, test code generation— and reduce them down to minutes, so you can get your real work done.
Here's how we solved the AI context problem for hard engineering tasks (like rocket science 🚀)
🧵
29
47
500
1,552,217
Jan 27
Here are some examples of cool use cases we've built with our customers:
- An advanced manufacturer reduced root-cause analysis from 8 hours to 20 minutes by automating sensor data parsing and log correlation.
- A global strategy consulting firm reduced manual research from hours to seconds, giving consultants access to relevant case work, answers to complex questions, and prior examples.
- A tech-enabled 3PL provider achieved 60x faster issue resolution by providing instant answers across their entire internal knowledge base.
- A specialty chemicals manufacturer reduced product research from hours to minutes with agents that search patents and regulatory databases.
- A test equipment maker generates test code in minutes instead of days by translating procedures into control logic.
1
3
1,620
Jan 27
Check out the link our bio to learn more about the launch 🚀
1
1
1,452
Contextual AI retweeted

Jan 8
Last month, I dove deep with @swyx on @latentspacepod about the state of context engineering, and scaling it as a full-stack discipline with benchmarks, tooling, and enterprise deployments. Hosted by @LaudeInstitute on the rooftop of the Hard Rock Cafe during @NeurIPSConf (my 5th!), and my first interview in sunglasses! Catch the full video from sunny San Diego here: youtube.com/watch?v=tSRqTerZ….
We unpacked the rapid evolution of context engineering, how agentic RAG became the baseline, why context rot is cited in every blog but industry benchmarks at real scale (100k documents, billions of tokens) are still rare, sub-agents with turn limits and other explicit constraints, instruction-following re-rankers for precision at scale, KV cache strategies for multi-turn agents, and why 2026 will shift to end-to-end system designs over component tweaks.
For more details on the blogs, papers, and events that shaped Context Engineering in 2025 (as we referenced in our chat), join @ContextualAI's webinar next week on 1/13! Sign up here: linkedin.com/events/contexte…
4
5
28
13,525
Contextual AI retweeted

21 Dec 2025
🛠️ @ContextualAI is proving what’s possible when you combine open models with highly scalable infrastructure. By fine-tuning Llama 3.1 70B on Google Cloud, they’ve built a "grounded" language model that reduces hallucinations and automates complex workflows. See how they did it → goo.gle/3Y0zZnN

3
12
1,496
18 Dec 2025
We are excited to share several new SOTA integrations with @trychroma:
- Parser, to load your unstructured documents directly into Chroma
- Reranker, to optimize your retrieved context within your context window
- LMUnit, natural language unit tests to evaluate your Agent, LLM, or RAG system’s performance
Contextual AI 🤝 Chroma: Working together to help you reduce context rot
docs.trychroma.com/integrati…
3
4
675
Contextual AI retweeted

8 Dec 2025
“Garbage in, information out,
is what we really want from AI”
@douwekiela of @ContextualAI
#FortuneBrainstormAI


3
4
1,361
5 Dec 2025
This year's @NeurIPSConf marks 5 years since the original RAG paper was presented at NeurIPS 2020. Our CEO and co-founder, @douwekiela, was a co-author on that work.
While RAG was an important step forward, retrieval is just one piece of a much larger puzzle. At Contextual AI, we're tackling the broader context problem. We're optimizing context engineering for dynamic agents with state-of-the-art accuracy, enterprise features, and production-ready scale.
Looking forward to the next 5 years.
1
1
3
664
Contextual AI retweeted

1 Dec 2025
Agents can do GraphRAG with the right set of tools.
1 Dec 2025

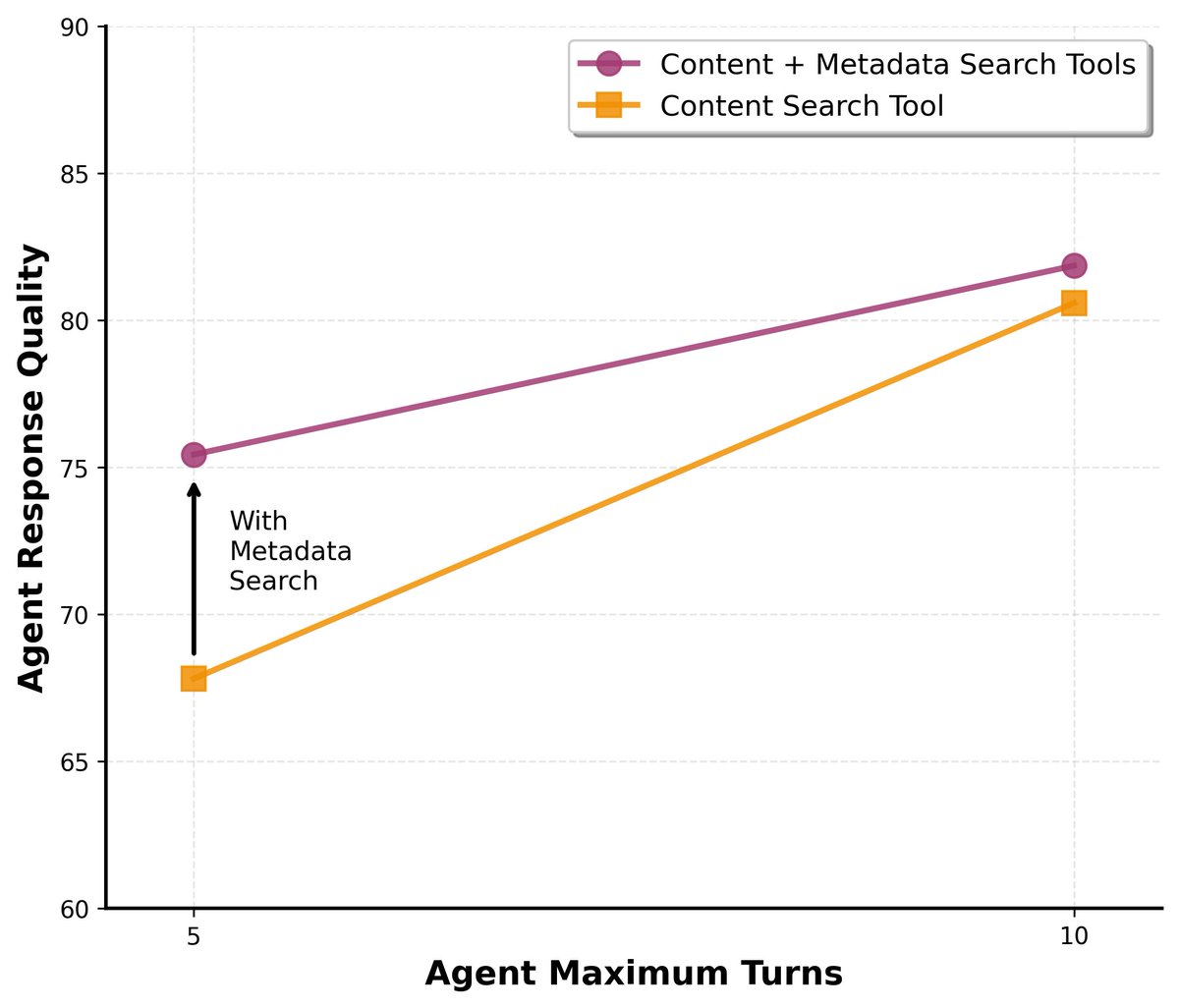
An agentic alternative to GraphRAG.
We built a Metadata Search Tool to solve reference traversal without the rigid complexity of static graphs.
The result? Agents resolve complex queries in fewer steps with higher accuracy.
🧵 1/4
1
1
7
1,073
Contextual AI retweeted

1 Dec 2025
An agentic alternative to GraphRAG.
We built a Metadata Search Tool to solve reference traversal without the rigid complexity of static graphs.
The result? Agents resolve complex queries in fewer steps with higher accuracy.
🧵 1/4
1
5
12
2,392