
AI Factories. Balanced Accelerationist. WEKA CAIO, CNCF kubernetes founding board, Post-PKI.
Joined July 2008
- Tweets 228,159
- Following 8,062
- Followers 8,721
- Likes 315,603
7,825 Photos and videos










Pinned Tweet

Did TokenMaxxing survive post GTC?
3
98
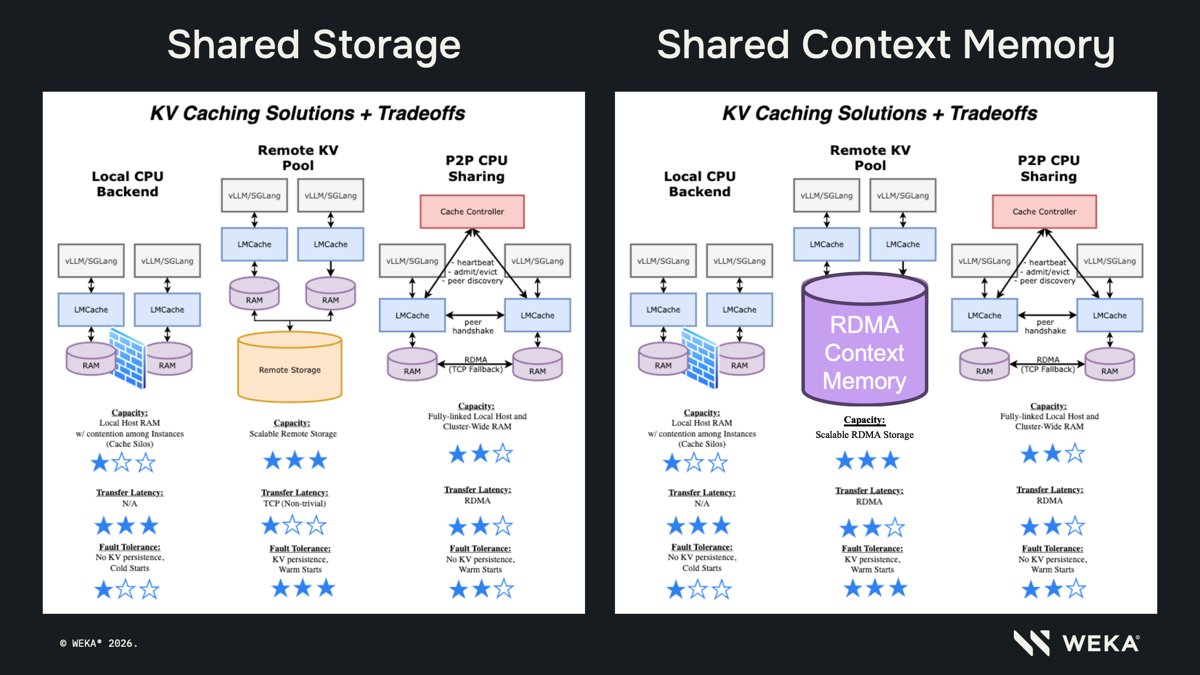
Model routing is the present and future of production AI, driven by:
- Cost
- Skill
- Availability

The layer that can route to the best AI model for the particular job is going to increase in value substantially. There are at least 3 big reasons:
* Cost optimization: there are plenty of use cases where you need frontier intelligence for some tasks and something far cheaper for others. Even in the same task you may use frontier intelligence for planning and review of the work, but an OSS or cheaper model for the bulk of the workload. This is going to be standard across large buckets of work going forward.
* Capability maximization: despite the bitter lesson and models generally getting better in the same direction, there are still lots of differences between models. Some are better at tool use, others better at coding, and others again better at certain domains of knowledge work. The ability to route between these at different times is a huge advantage.
* Risk mitigation: while the Fable situation is somewhat of a black swan, it’s possible we’re heading toward a regulatory environment where governments may restrict models at different times based on their approval mechanisms or new things they discover. This means you’re going to want flexibility in being able to deploy workloads across different providers as a form of risk mitigation.
Ultimately, it’s going to increasingly be a a strategic advantage for the applied AI layer that they can effectively route between models. Will be very interesting to see how this evolves.
1
71
Nope. Prisoner’s dilemma proves that if any actor in a transaction can achieve leverage in a transaction by simply spending more on tokens (at any cost) to gain an advantage,
they will

Tokens will get 90% cheaper every year as models improve and $10k desktop workstations from @dell and @apple, running open source models, drive tokens to “essentially free”
Token costs will be looked at like storage and bandwidth costs in a couple of years — which is to say you won’t think about them much.
1
93
b/acc, context platform engineer retweeted

Jun 11
Well, it was good while it lasted I guess…
Jun 10

Our Anthropic bill is about to jump from $400K → $1.4M/yr.
Not because usage exploded, but because we're about to cross 150 seats.
Past 150 seats you're forced into Enterprise tier. Seats stop including any usage, every token bills at standard API rates. At our current run rate that's 3.5x overnight.
Unfiltered thoughts on AI spend:
1. We should spend tokens to grow as aggressively as possible. But most people (me included) aren't conscious of what they're spending.
2. Visibility comes first. People see their personal number and they're shocked. I accidentally spent $4,000 in 3 days in Claude Code.
3. For engineering the spend is clearly worth it. Pay for the best model, it saves more than it costs.
4. For a lot of other roles it's questionable. Apps nobody uses, skills someone already built. No ROI.
5. Spend limits are coming. We already require approval for more tokens on our support team.
The era of token-maxxing is coming to an end.
109
90
2,330
1,202,161
b/acc, context platform engineer retweeted

Jun 13
GLM 5.2 dropped at the right time
Jun 13

what this whole mess is going to lead to is all none us entities refusing to use us models that could get cut off anytime for any reason. This verymuch hands the win to chinese bros
9
18
576
70,914

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
292
842
6,924
1,305,298
b/acc, context platform engineer retweeted

Jun 13
OpenAI now just needs to sandbag the next model release
So the US doesn't export control them
So they gain massive market share
It's imperative that all the OAI employees don't vauge hype post their next model release as the greatest thing ever
Don't know if they are capable tho
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
122
104
2,405
342,764
b/acc, context platform engineer retweeted

Jun 13
Glad to see day-0 speculators are warm welcomed by the community!
Jun 13

Congrats to @vllm_project & @lmsysorg for releasing MiniMax M3 428B on both the CUDA & ROCm stack on day 0! MiniMax M3 includes:
🟠 Block sparse attention which is 9x faster prefill over M2.7
🟠 Day 0 open MXFP8 weights
🟠 and Furthermore @Inferact released Day-0 EAGLE3 open weight draft model support
Excited to try out the performance on MiniMax M3!

2
49
6,080
b/acc, context platform engineer retweeted

Jun 12
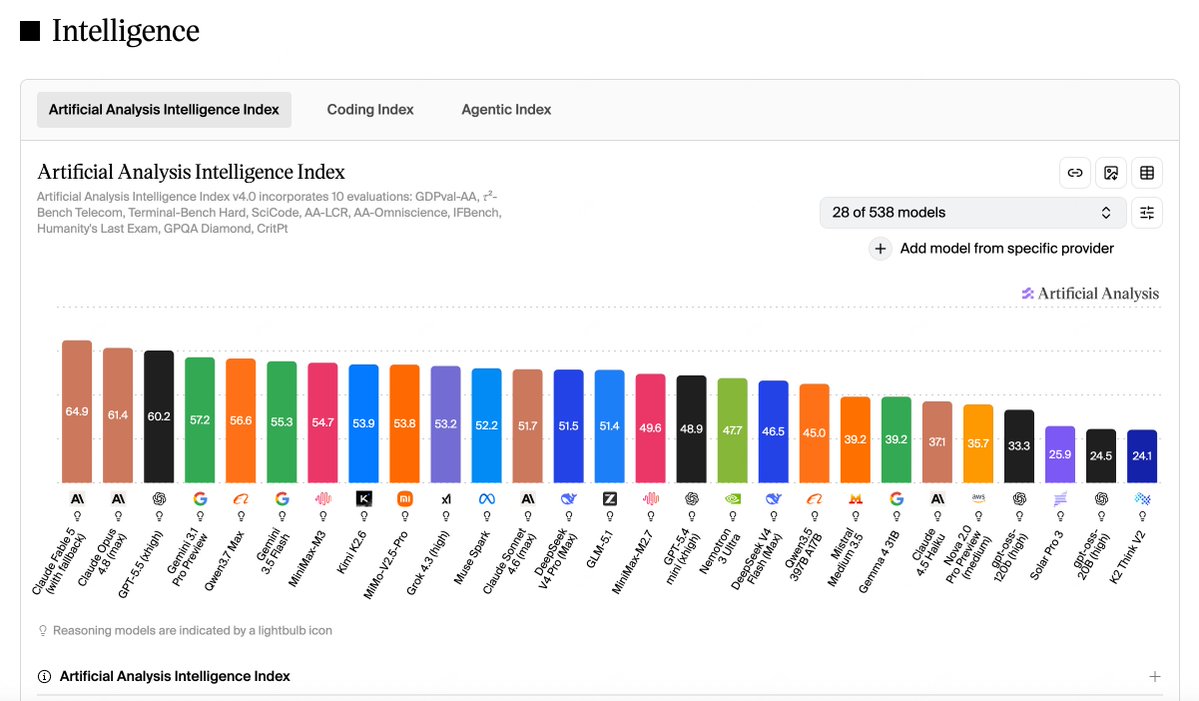
MiniMax M3 weights are live.
#1 open-weights model on the AA Intelligence Index.
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
20
23
399
25,916
b/acc, context platform engineer retweeted
Jun 12
🎉 Congrats to @MiniMax_AI on releasing MiniMax M3! Frontier coding and agentic capabilities, native image and video input, computer use, and a 1M-token context window, all in a single open model.
At the heart of M3 is MSA, a new sparse attention architecture: instead of attending densely over the full KV cache, each query scores 128-token KV blocks and runs attention only over the top blocks. That is what makes 1M-token context practical to serve.
M3 runs in vLLM with day-0 support, verified on NVIDIA and AMD hardware:
✨ MSA sparse attention with dedicated prefill and decode kernels
✨ 1M-token context serving with prefix caching and chunked prefill
✨ BF16 and MXFP8 checkpoints, with MoE backends for both Hopper and Blackwell
✨ Native multimodal input (image video)
✨ Tool calling, reasoning parsing, and thinking-mode control for agent workloads
Day-0 support like this is a true team effort. Grateful to the teams at @MiniMax_AI, @NVIDIAAI, @AIatAMD, and @inferact, and to the vLLM community for making it happen. 🙏
Deep dive into the implementation, kernel work, and deployment recipes:
🔗 vllm.ai/blog/2026-06-12-mini…
Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
4
31
299
37,080

b/acc, context platform engineer retweeted

Citadel Securities just put institutional weight behind what the AI bulls won't say out loud.
In a new macro note titled "Tokenomics," Citadel makes the argument plainly: even the most powerful technology on earth still has to pass through the boring discipline of cost curves, capacity limits, and marginal returns.
The evidence is piling up:
– Amazon removed its token usage leaderboard
– Microsoft cancelled Claude Code subscriptions
– Multiple companies reporting unexpectedly massive token bills
Their conclusion is the part that matters.
Adoption is no longer about what AI can do in principle. It's becoming about the price and scarcity of the inputs needed to run it at scale. Compute. Power. Cooling. Memory bandwidth. Inference budgets. All real, all binding constraints.
And here's the kicker from the chart.
The Silicon Data LLM Token Expenditure Index, a benchmark for how much the market is actually spending on AI tokens, has started rolling over. Citadel reads it as a shift toward cheaper models. Companies substituting away from expensive frontier AI toward "good enough" alternatives.
That's economics 101 doing what it always does. When the price of something rises, people use less of it, or find a cheaper version.
Citadel sees a bifurcation forming. Frontier AI concentrated among a few firms with the balance sheets to absorb the cost. Everyone else quietly downgrading to simpler, cheaper models.
This is the part of every technology revolution the early narrative ignores.
The technology being real was never the question.
The question was always whether the economics could carry the valuations.
When one of the most sophisticated trading firms on earth starts writing about AI in the language of cost curves and rationing instead of limitless demand, the conversation has quietly changed.
The hype was about what AI could do.
The reckoning is about what it costs.

116
491
2,560
480,248
b/acc, context platform engineer retweeted
Jun 10
Congrats to @GoogleDeepMind on DiffusionGemma 🎉 A 26B diffusion language model on the Gemma4 backbone, and the first dLLM natively supported in vLLM.
It denoises 256-token blocks in parallel instead of generating one token at a time: 1200 output tok/s at batch size 1 on a single H200 (FP8).
Built on model runner v2's ModelState plus the existing speculative decoding path, with minimal scheduler or runner changes. FP8 and NVFP4 checkpoints are on the @RedHat_AI hub. Thanks to the @GoogleDeepMind, @RedHat_AI, and @NVIDIAAI teams!
🔗 vllm.ai/blog/2026-06-10-diff…
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
14
50
520
38,831
b/acc, context platform engineer retweeted

Jun 11
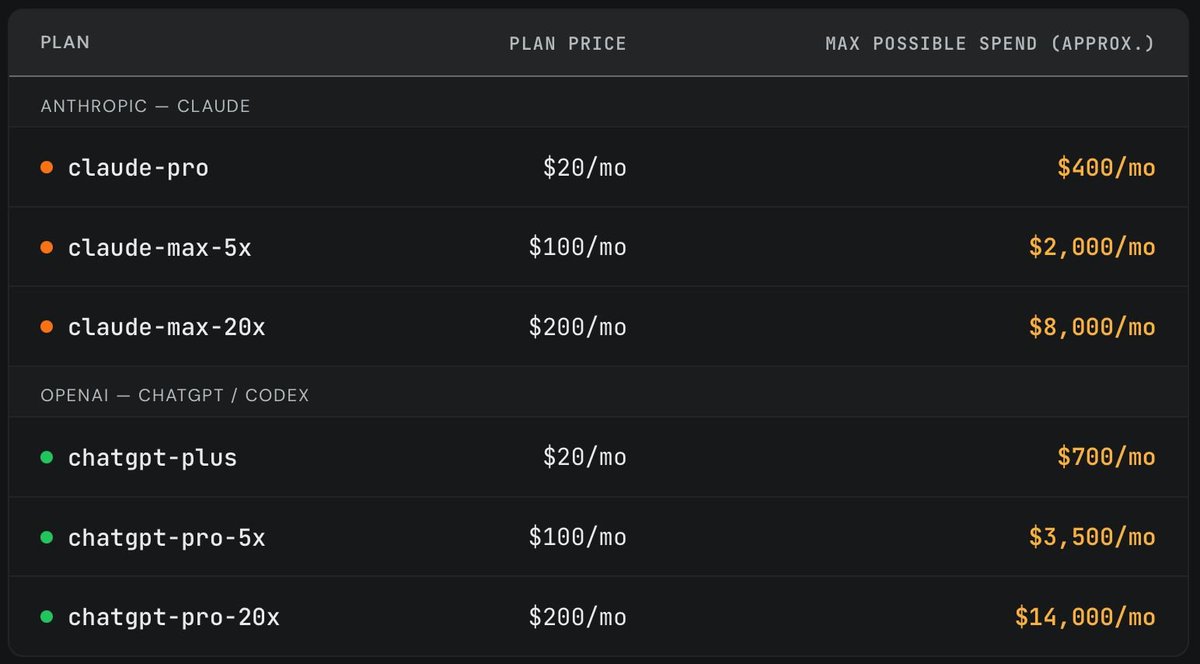
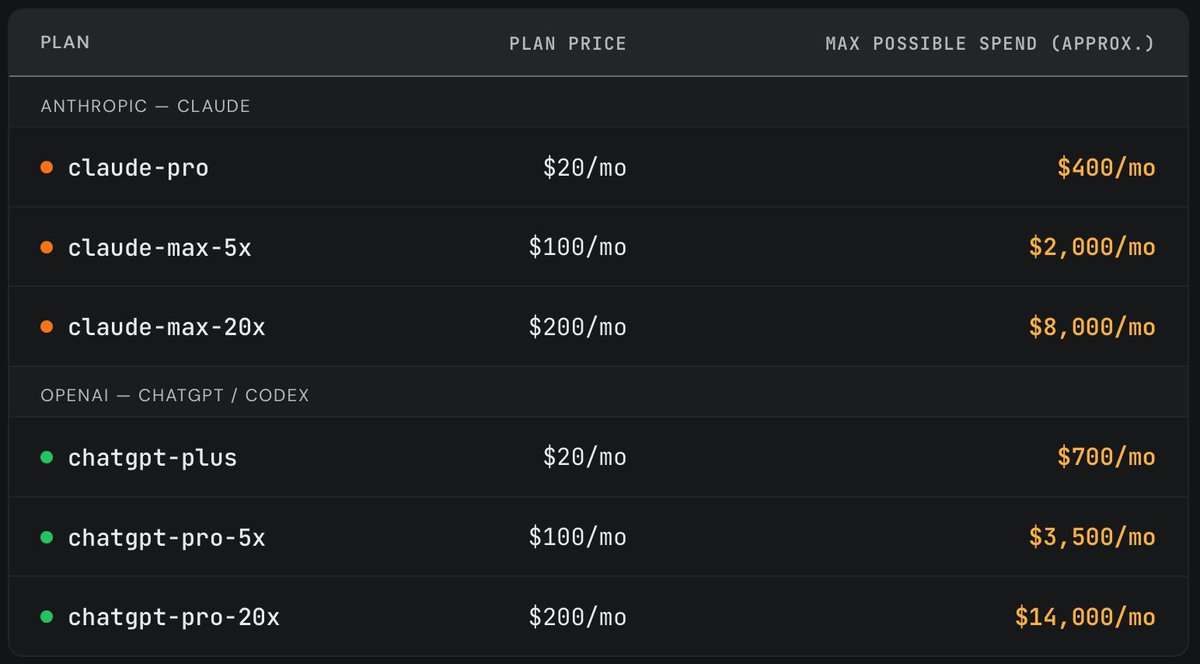
Subscription plans are massively subsidized.
And by massively, I mean absurdly:
Claude Max 20x: $200/month, with usage reportedly worth around $8,000
ChatGPT Pro 20x: $200/month, with usage reportedly worth around $14,000
Jun 10
Recently, we purchased one of each Anthropic/OpenAI subscription plan and randomly ran long horizon coding tasks until we exhausted the weekly limit. It's widely believed that a $200/month plan maxes out at ~$2000/month worth of tokens (assuming API pricing). However, we found that the subscriptions are actually far more generous. (2/4)
327
273
4,360
1,519,540
b/acc, context platform engineer retweeted

Jun 10
Recently, we purchased one of each Anthropic/OpenAI subscription plan and randomly ran long horizon coding tasks until we exhausted the weekly limit. It's widely believed that a $200/month plan maxes out at ~$2000/month worth of tokens (assuming API pricing). However, we found that the subscriptions are actually far more generous. (2/4)
182
571
6,025
3,449,418
b/acc, context platform engineer retweeted
Jun 10
🎉 Excited to see Inferoa from @agenticin.
It builds a community agent harness on the vLLM stack, with the agent loop shaped by inference economics: prefix-cache discipline, context optimization, and routing across self-hosted and frontier models.
Looking forward to seeing how developers extend it. 🚀

Introducing Inferoa: Inference-native Tokenmaxxing Agent Harness built for Loop Engineering.
Building around @vllm_project to run recursive long-horizon tasks with discipline, and context optimization via #codegraph #rtk etc.
Try it at @ProductHunt!
producthunt.com/products/inf…
4
5
58
9,296
b/acc, context platform engineer retweeted

Jun 10
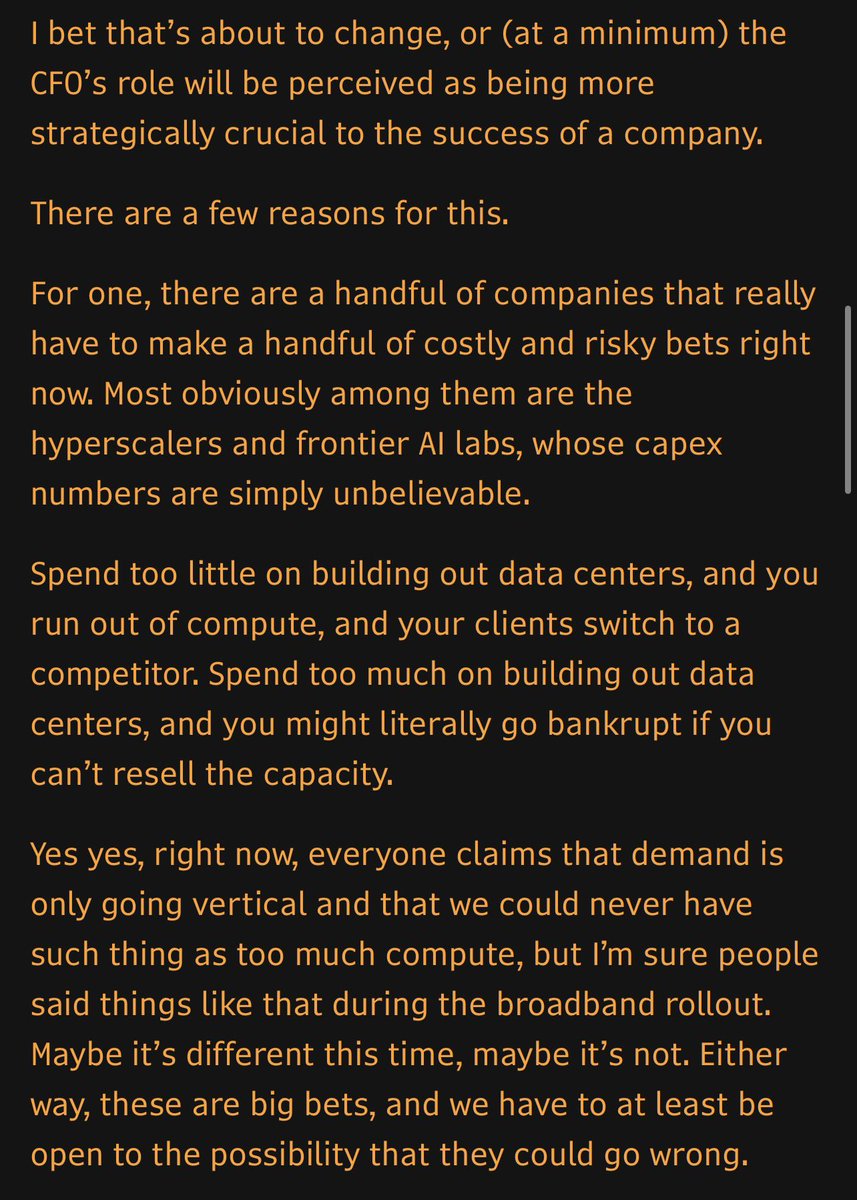
THE AGE OF THE ROCKSTAR CFO
I usually don’t post takes. But in today’s newsletter I wrote a take about why the CFO will be seen as more strategic than ever as companies face new and interesting questions on both capex and opex



19
30
247
238,707
b/acc, context platform engineer retweeted

Jun 9
Super excited to announce that @arcee_ai is the first major American AI lab to replace AWS S3 with Hugging Face for ALL their models and datasets, public AND private 🔥🔥🔥
Multi-million $ partnership to support American open-source AI, let’s go!

41
60
513
60,789
b/acc, context platform engineer retweeted

Jun 9
Want to work on a datacenter with 1k GPUs?
I'm hiring people to write code for our small 500kw cluster (~3MW in couple years). You'll work with things like SLURM, PyTorch, NFS, Linux, miniray, minikeyvalue.

29
26
570
41,615
b/acc, context platform engineer retweeted

Jun 8
If you've adopted AI at your company but haven't seen any tangible results, read this 1990 article: "The Dynamo and the Computer" by Paul David.
When electricity first arrived, factories that "adopted" it barely got faster. They just swapped the steam engine for an electric one and ran everything else exactly as before: same machine layout, same workflow, same management. Electricity in, no real gains out.
The most common mistake with any new technology is to drop it into the old organization and then declare the transformation done.
The real leap came decades later, when each machine got its own small motor. Suddenly machines no longer had to be lined up around one central drive shaft. They could be rearranged around the actual flow of work.
The productivity gains didn't come from electricity. They came from REDESIGNING THE ENTIRE FACTORY around it.
AI is the same. Bolting it onto your existing process gets you a faster steam engine. The payoff comes when you redesign the work itself.
(link to paper in comments)

146
752
4,227
285,724
b/acc, context platform engineer retweeted
Jun 9
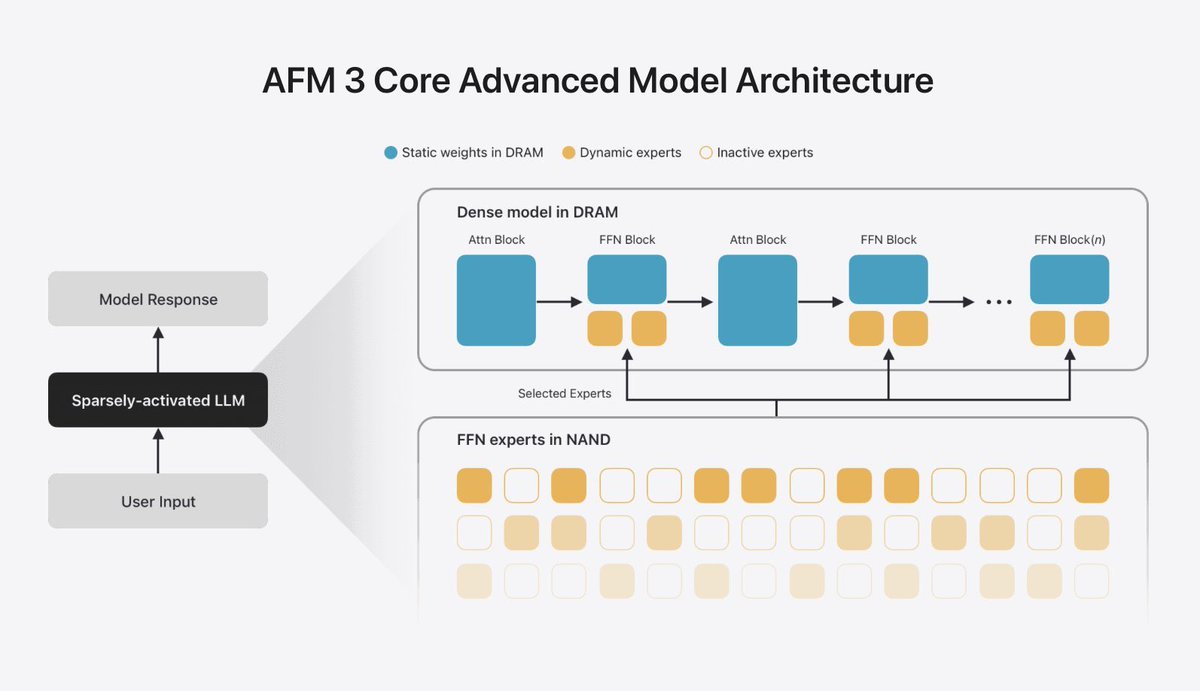
Interesting approach from Apple
They are storing the shared attention block in the DRAM
While the FFN weights stay in NAND and are loaded in the DRAM, depending on the request
Apple is facing 3 constraints -
1) Limited DRAM size
2) Large model size (20B params)
3) Slow NAND read speed
A super small model (sub 8B) won't be that useful, but they can't store a 20B model in DRAM (due to memory shortage). They also have to manage the KV cache overhead. If they streamed the weights completely through iPhone SSD, then it would take 2.5 seconds to generate just 1 token (0.4 tokens/s)
So the big thing here is that a normal MoE activates different experts based on every token, but in Apple's case, a sparse mask predictor decides which parameters to activate based on the request/prompt, locks it in, and loads it into the DRAM (1B-4B depending on the request). They basically convert a 20B MoE (with 1B-4B active) into a dense 1B-4B param model for a request.
The tradeoff:
They are basically adding 0.3-1.5 seconds (1B to 4B params loaded) of latency to TTFT time by loading FFN weights from NAND to SSD per request (read speed is around 1.5-1.7 GB/s for iPhones) and taking a hit to performance
They will get around 15-50 tokens/s of decode speed (depending on params loaded)
Ideally, smartphones would come with 24-32 GB of RAM so that 20B param models could be loaded, but memory shortage won't allow it to happen
But, their competitor here is ChatGPT Instant, which is a much smarter model that runs at 200 tokens/s and has a TTFT of 0.8 seconds (Apple's TTFT will be around 0.5-2 seconds, and decode speed is around 15-50 tokens/s), and is also free
Apple's AFM on device models will be great for privacy-focused tasks. They get beaten by cloud models on other benchmarks (perf, speed, quality)

I’m curious whether Apple’s FFN NAND-like approach reduces the mobile DRAM requirement needed for on-device AI.
If so… why doesn’t Nvidia use this kind of technology? Wouldn’t that mean the 128GB in N1X is overkill?
20
42
426
63,072