
Open-source software/tools/datasets, news, research et al. regarding #machinelearning and #datascience, with a focus on #deeplearning.
Joined February 2012
- Tweets 3,821
- Following 811
- Followers 8,234
- Likes 5,704
386 Photos and videos







DeepLearning.Hub retweeted

Jun 10
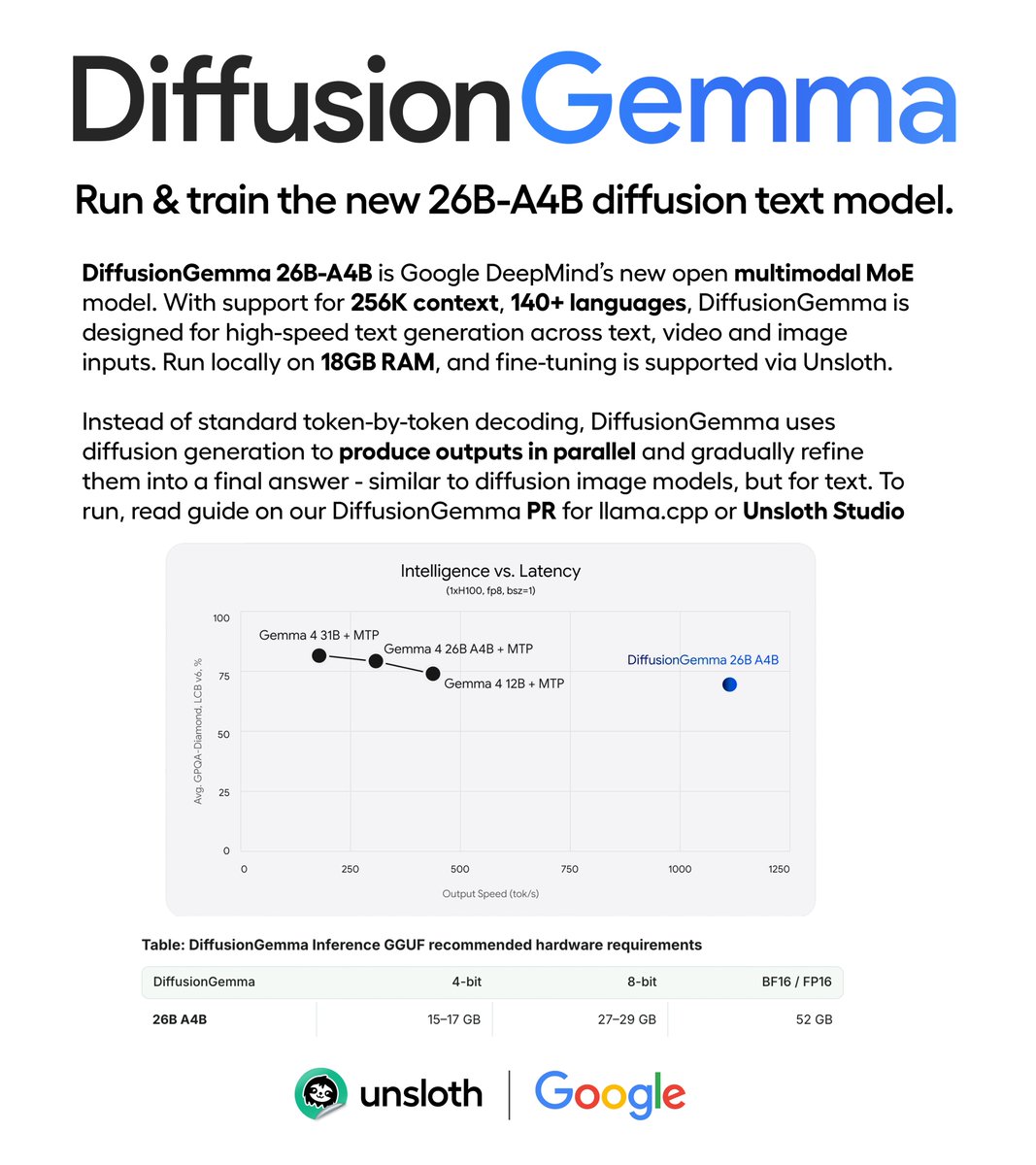
Google releases DiffusionGemma.✨
The new 26B-A4B diffusion text model runs locally on 18GB RAM.
It supports high-speed text generation, thinking, image, video and 256K context.
Run and train via Unsloth Studio.
GGUF: huggingface.co/unsloth/diffu…
Guide: unsloth.ai/docs/models/diffu…
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
65
247
1,851
322,397
DeepLearning.Hub retweeted
Jun 5
Google releases Gemma 4 QAT. ✨
You can now run Gemma 4 at 3x less memory with near original performance.
Quantization-Aware Training (QAT) makes it possible to run Gemma 4 26B-A4B on 16GB RAM.
GGUFs: huggingface.co/collections/u…
QAT Guide: unsloth.ai/docs/models/gemma…

Jun 5
We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
93
413
2,898
248,005
DeepLearning.Hub retweeted
Jun 4
2-bit Gemma 4 12B GGUF, only 4.66 GB on disk, managed to cite 15 sites from a single prompt.
Try this locally on >6GB RAM via Unsloth Studio.
GitHub: github.com/unslothai/unsloth
Jun 3

Gemma 4 12B can now run locally on just 8GB RAM via Dynamic GGUFs.
Google's new model, Gemma 4 12B Unified supports image, audio and 256K context.
You can run and train the model via Unsloth Studio.
GGUF: huggingface.co/unsloth/gemma…
Guide: unsloth.ai/docs/models/gemma…

45
194
1,628
140,742
DeepLearning.Hub retweeted
Jun 3
Gemma 4 12B can now run locally on just 8GB RAM via Dynamic GGUFs.
Google's new model, Gemma 4 12B Unified supports image, audio and 256K context.
You can run and train the model via Unsloth Studio.
GGUF: huggingface.co/unsloth/gemma…
Guide: unsloth.ai/docs/models/gemma…
Jun 3
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

96
380
2,819
348,701

Today we’re introducing Gemma 4 12B — our latest open model that brings advanced agentic reasoning, vision and audio directly to your laptop.
It delivers performance nearing our larger Gemma models with a much smaller total memory footprint, while being small enough to run locally with just 16GB of VRAM. It’s open and accessible for everyone to use under a permissive Apache 2.0 license.
This is all made possible by our new, unified architecture that removes separate multimodal encoders. Here’s how we did it 🧵

ALT Promotional graphic on a black background featuring the large blue text "Gemma 4 12B" above smaller white text that reads "Unified Transformer." A glowing blue ribbon containing multi-modal icons (representing images, text, and audio) flows from the left into a central point, branching out into a complex, luminous blue neural network map on the right.
249
1,255
9,375
876,957
DeepLearning.Hub retweeted

May 20
Cohere dropped Command A 🔥
> 25B/219B MoE vision language model
> supports 48 languages with efficient tokenizer
> tool-calling/agentic 128k context window
> transformers day-0 support 🤗
free license 💗

3
8
94
7,173
DeepLearning.Hub retweeted
May 19
4-bit Qwen3.6 MTP GGUF managed to search 70 sites from a single prompt.
Try this locally on 20GB RAM via Unsloth Studio.
Unsloth now supports auto MTP speculative decoding & auto-selects the best MTP settings for your device (Mac, CPU, GPU).
GitHub: github.com/unslothai/unsloth
38
122
1,009
71,603
DeepLearning.Hub retweeted
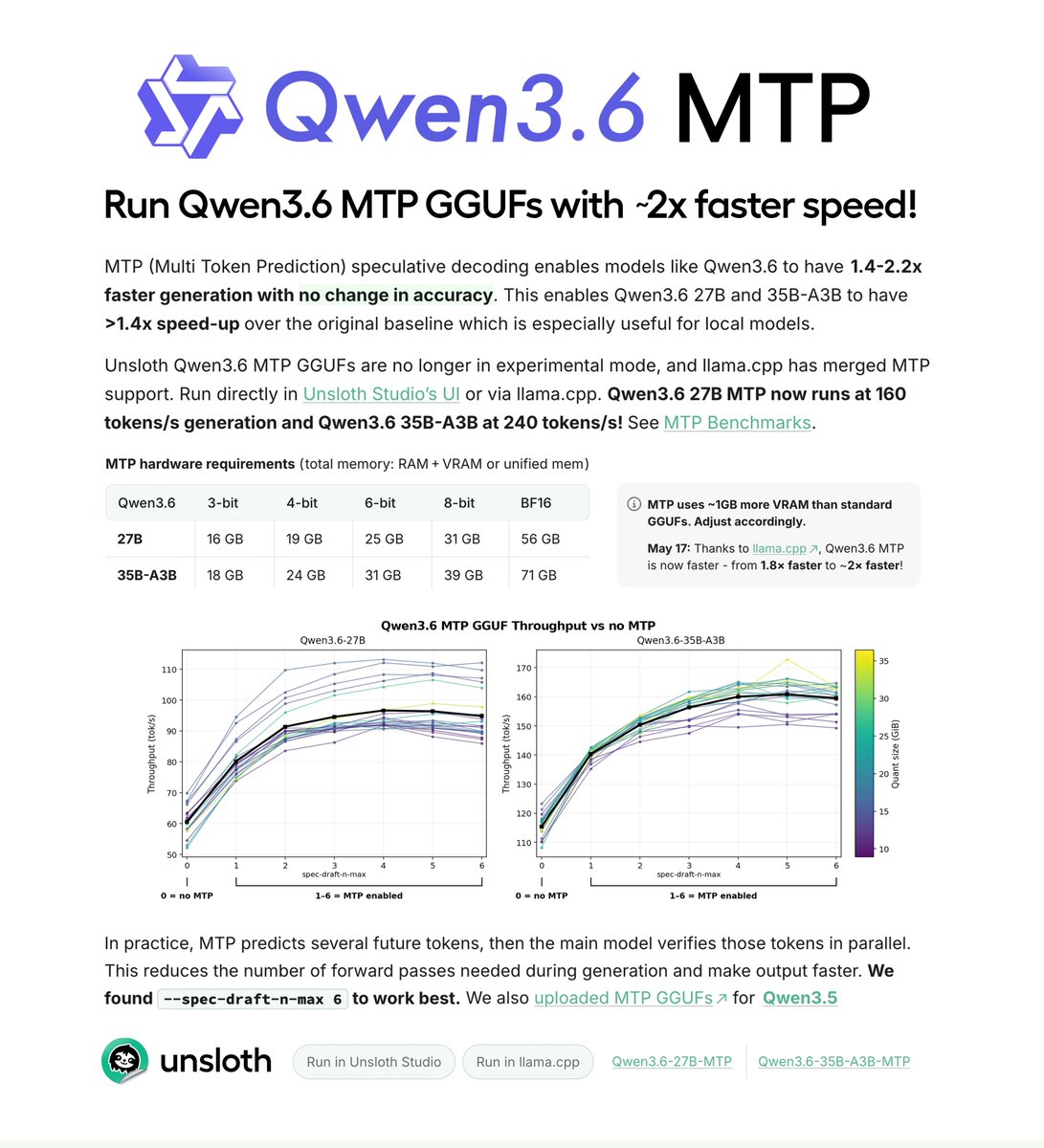
May 18
Qwen3.6 now runs 2x faster with MTP GGUFs! Run locally on just 18GB RAM. ⚡️
MTP enables Qwen3.6 to generate ~1.4–2.2× faster with no accuracy change.
Qwen3.6-27B MTP runs at 160 tokens/s. 35B-A3B reaches 240 t/s.
GGUFs: huggingface.co/unsloth/Qwen3…
Guide: unsloth.ai/docs/models/qwen3…
132
301
2,475
140,955
DeepLearning.Hub retweeted

May 14
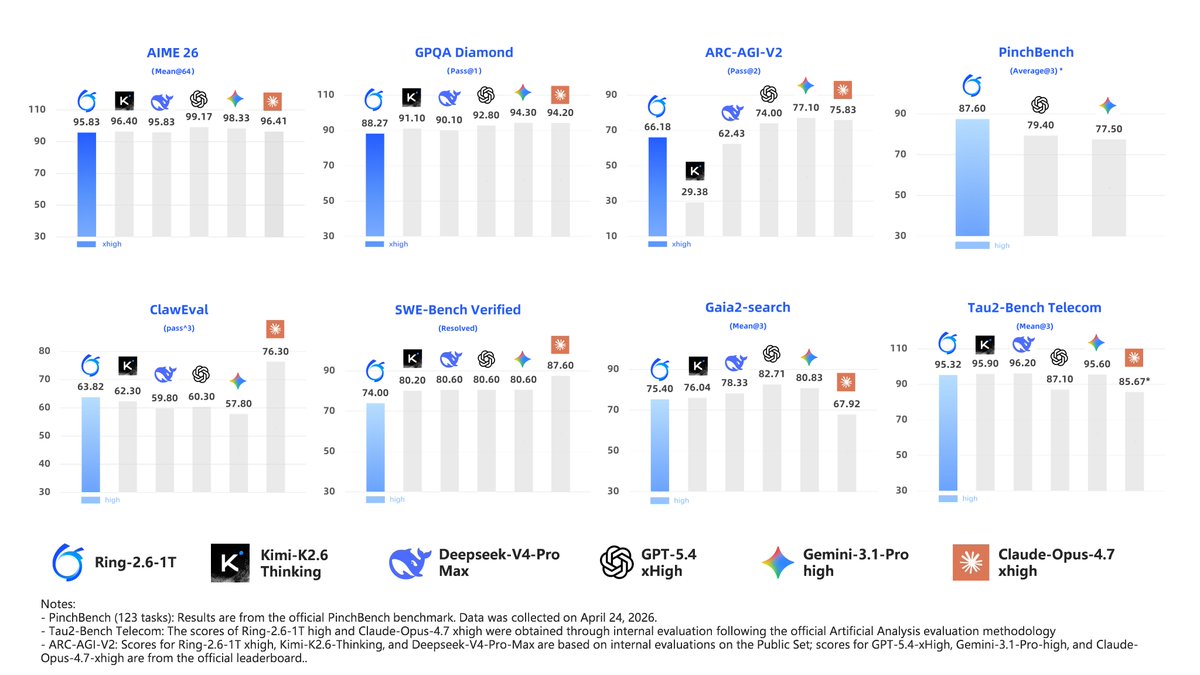
Ant group just dropped Ring-2.6-1T 🔥 1T reasoning model, built for real world agent workflows.
✨ MIT license
✨ 128K >> 256K context (YaRN)
✨ Async RL IcePop training architecture
✨ Dual reasoning effort: "high" for fast agent loops, "xhigh" for deep reasoning = Better cost/performance tradeoff 👀
2
14
109
8,892
DeepLearning.Hub retweeted

May 13
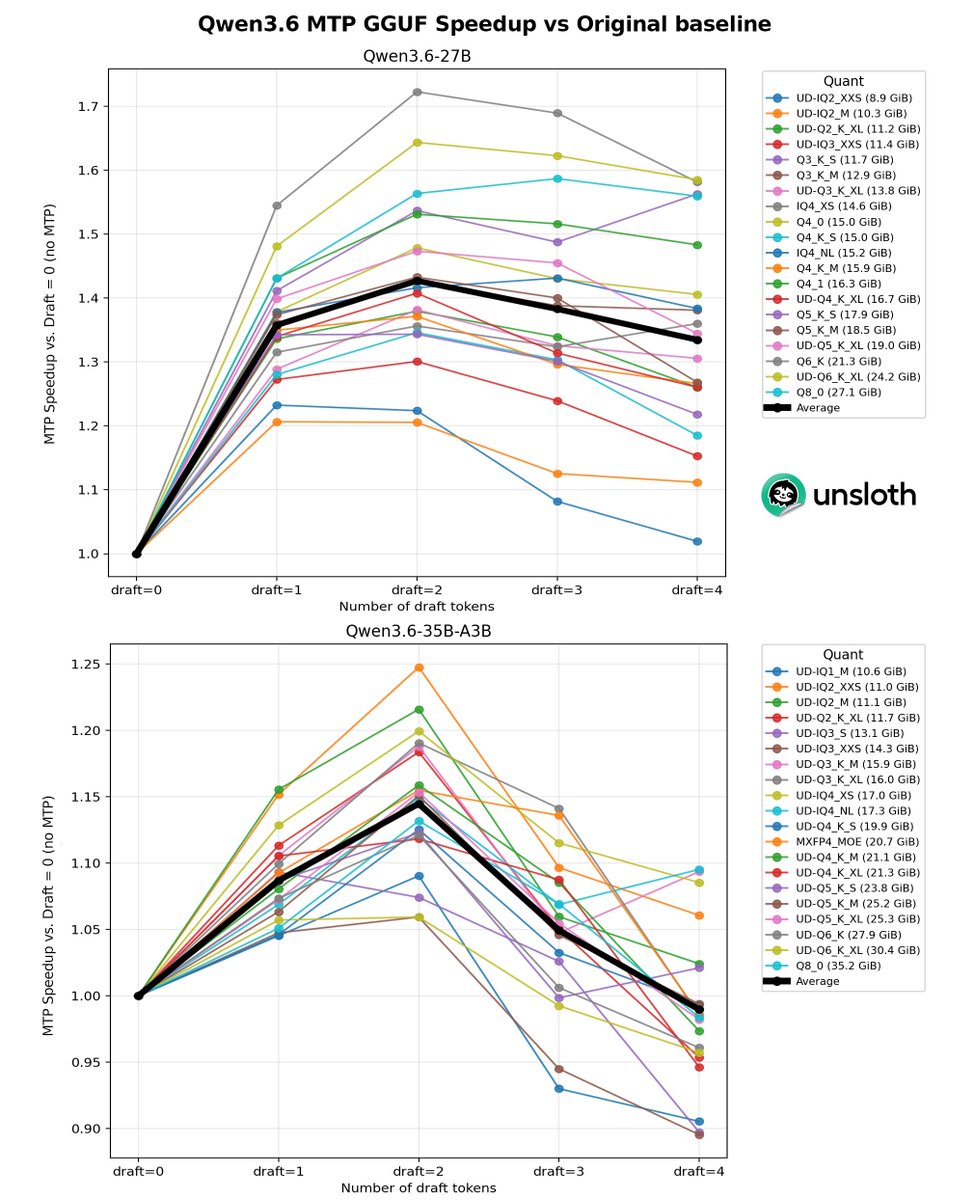
We released experimental MTP Qwen3.6 Unsloth GGUFs!
Qwen3.6 27B MTP now runs at 140 tokens/s. Qwen3.6 35B-A3B MTP gets 220 tokens/s generation on a single GPU.
Qwen3.6 27B and 35B-A3B have >1.4x speed-up over the original GGUFs without any change in accuracy.
Guide GGUFs Benchmarks: unsloth.ai/docs/models/qwen3…
In terms of average speedup, we see a 1.4x for dense models at draft tokens = 2 and for the MoE around 1.15 to 1.2x.
We do not recommend more than 2 draft tokens because the acceptance rate drops precipitously from 83% to 50% with 4 draft tokens, and the forward passes for MTP become less beneficial.
Use `--spec-type mtp --spec-draft-n-max 2`
Thanks to Aman for github.com/ggml-org/llama.cp…!
60
117
785
123,758
DeepLearning.Hub retweeted

May 11
Computer use with any model
Hermes Agent × @trycua
105
133
2,077
1,089,041
DeepLearning.Hub retweeted

Trending repository of the day 📈
hermes-agent by nousresearch
The agent that grows with you
Last 24h: 2,065 ⭐
Total: 145,790 ⭐️
github.com/NousResearch/herm…
3
19
1,374
DeepLearning.Hub retweeted
May 11
🆕 Hugging Face 🤝 Hermes Agent 🔥
> we added Hermes Agent to local apps: run it locally with any compatible GGUF/MLX model
> shipped native traces support for Hermes Agent: visualize your Hermes traces directly on the Hub
Very soon most agents will run locally and we want to accelerate things as much as we can ⚔️

34
71
620
103,481
DeepLearning.Hub retweeted

May 5
Excited to introduce Gemma 4 Multi-Token Prediction Drafters⚡️Accelerated inference right in your pockets
- Up to a 3x speedup
- Same quality guarantees
- Available in your favorite open-source tools
46
120
1,027
149,547
DeepLearning.Hub retweeted

May 4
somebody made a huggingface model visualizer!! just plug in the url and explore at any granularity
36
360
3,044
161,326
RT @UnslothAI: You can now run open LLMs in Claude Code, Codex and OpenClaw via Unsloth.
Use Gemma 4 and Qwen3.6 GGUFs for local agentic c…
6
10
DeepLearning.Hub retweeted

Apr 27
We're open-sourcing Asimov v1, a humanoid robot.
With Asimov v1, you can build, train on, and make it your own humanoid robot. It's the first step of building a humanoid labor force for the rest of us.
Asimov v1 is 1.2 m tall, 35 kg, with 25 actuated degrees of freedom. Structural parts machined in 7075 aluminium and 3D-printed in MJF PA12 nylon.
We're releasing the mechanical design and simulation files. Ready for locomotion policy training out of the box.
The BOM is open too. Source everything yourself, or order the DIY Kit. All components, ready to assemble. $499 deposit, $15,000 target price. Ships end of summer 2026.
GitHub: github.com/asimovinc/asimov-…
Manual: manual.asimov.inc
DIY Kit: asimov.inc/diy-kit
Most humanoid robots are controlled by the companies that build them. Asimov v1 is built for the rest of us. Build it, test it, and share your feedback with the community.
50
277
1,738
326,669

Nemotron 3 Nano Omni is available locally on Ollama!
This requires the latest Ollama 0.22 release.

Meet Nemotron 3 Nano Omni 👋
Our latest addition to the Nemotron family is the highest efficiency, open multimodal model with leading accuracy.
30B parameters. 256K context length. 🧵👇
37
42
426
51,301

Apr 28
RT @UnslothAI: NVIDIA releases Nemotron-3-Nano-Omni, a new 30B open multimodal MoE model.
Nemotron-3-Nano-Omni-30B-A3B is the strongest om…
3
15
DeepLearning.Hub retweeted
Apr 24
DeepSeek releases DeepSeek-V4. 🐋
- DeepSeek-V4-Pro: 1.6T params
- DeepSeek-V4-Flash: 284B params
DeepSeek-V4-Pro rivals Claude-Opus-4.6-Max, GPT-5.4-xHigh and Gemini-3.1-Pro-High.
They support 1M context length, thinking and set new records for Codeforces.

Apr 24

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

48
133
1,126
79,570