
Joined October 2022
- Tweets 120
- Following 583
- Followers 322
- Likes 739
9 Photos and videos



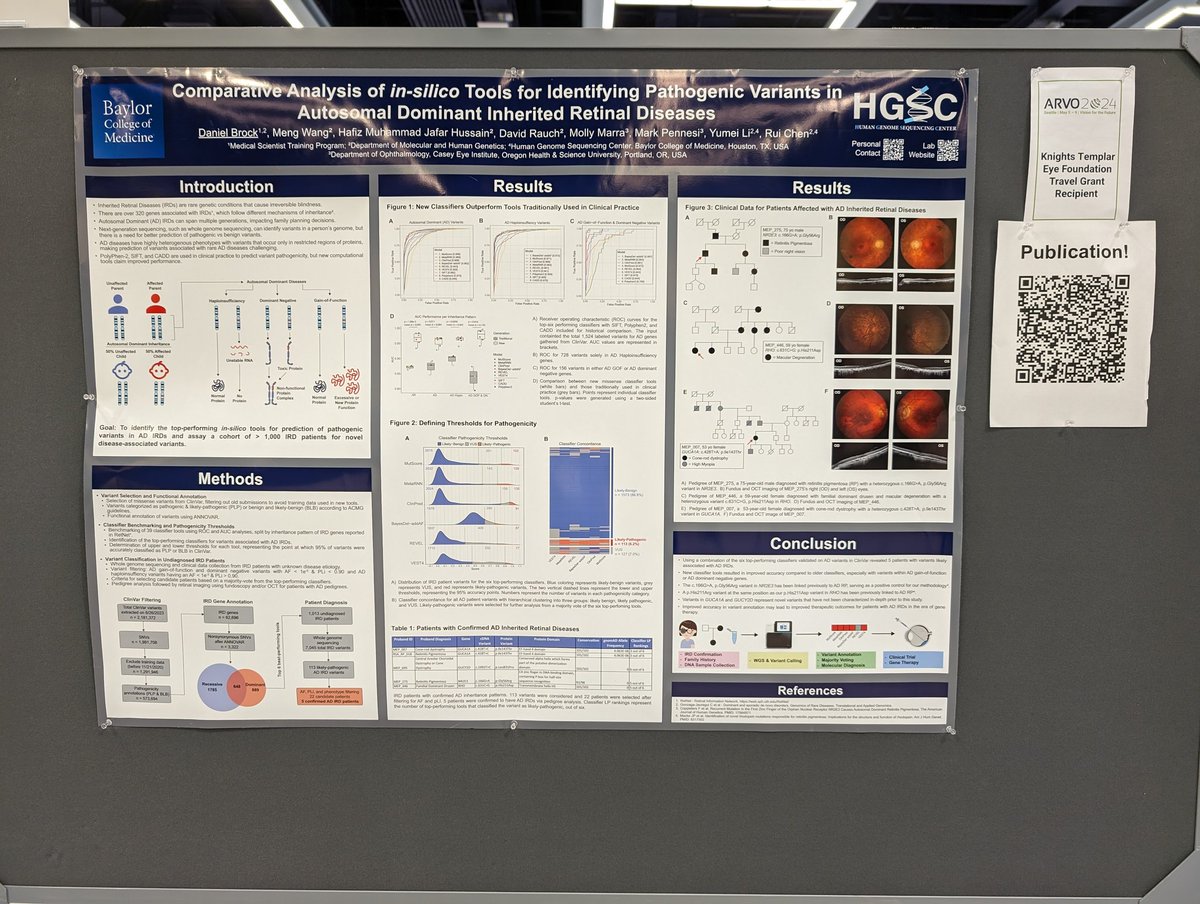





Pinned Tweet

8 Mar 2024
New publication!
How can you tell if a variant is pathogenic? We benchmarked several computational tools to predict the pathogenicity of autosomal dominant inherited retinal diseases. We identified the top-performing tools and found some new variants!
academic.oup.com/hmg/advance…
2
17
1,187
Daniel Brock retweeted

Apr 15
Great MSTP showing at the McNair symposium yesterday, highlighted by a talk from Josh Keefe on postCABG a fib.




3
7
721
Daniel Brock retweeted

Apr 14
From our physician-scientist development category:
doi.org/10.1172/jci.insight.…
Daniel C. Brock @DanielCBrock Cynthia Y. Tang @_CynthiaTang & team @A_P_S_A analyzed 36,298 applicants, reporting dual-degree training shapes residency application strategies, interview rates, specialty choice, and program prestige. Deborah Rupert @DoubleDocDDR, Toni Darville @darville_toni, Caroline Jansen @careyjans, Elias Wisdom @EliWisdom16
#MedicalEducation #ResidencyMatch #PhysicianScientists
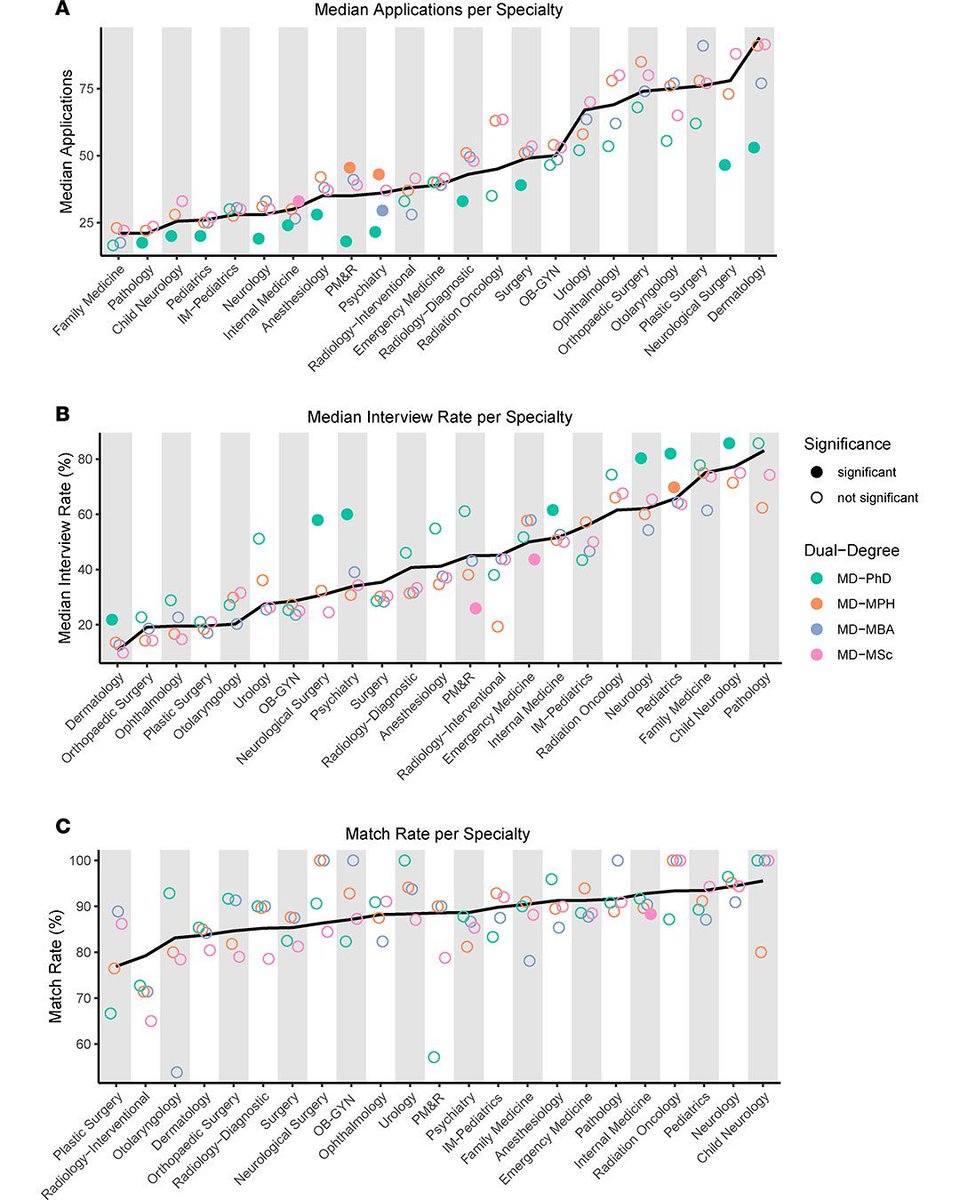
5
15
1,246
Daniel Brock retweeted

We found a surprisingly large technical artifact hiding in a widely-used scRNA-seq technology.
In all Flex v1 datasets we’ve analyzed, we see hundreds of DE genes between probe set barcodes.
More on why this matters and what to do about it below:
biorxiv.org/content/10.64898…
(1/n)
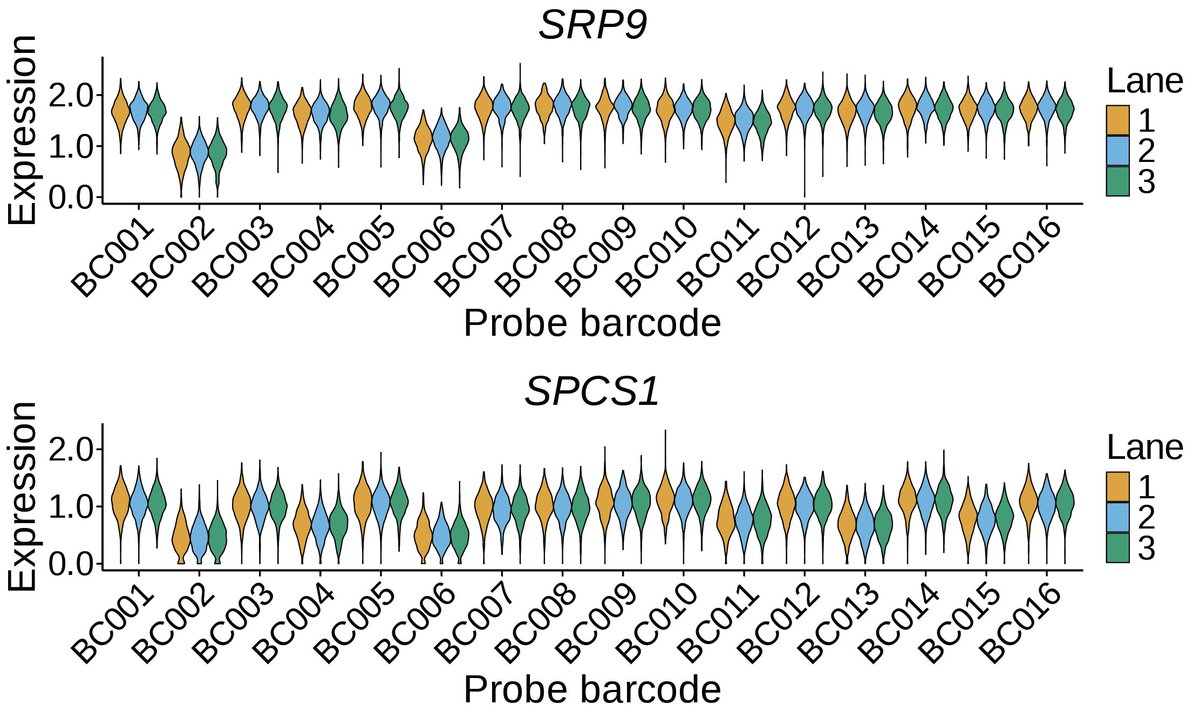
3
75
226
52,263
Daniel Brock retweeted
Mar 15
Check out this publication by our student @DanielCBrock Dual‑Degree Pathways in the Residency Match: A Comparative Analysis of Application Behaviors and Outcomes - PubMed pubmed.ncbi.nlm.nih.gov/4171…
1
4
232
Feb 27
Just in time for match day, we studied how dual-degree students navigate residency apps.
The outlook for MD-PhDs #doubledocs is bright!
We also analyzed MD-MPH, MBA, and MSc outcomes.
Great work by the @A_P_S_A team, @_CynthiaTang @DoubleDocDDR @careyjans @EliWisdom16
Dual-degree training shapes application strategy, interview yield, specialty choice, and matched program characteristics. Read more: insight.jci.org/articles/vie…
#MedEd #ResidencyMatch #MatchDay @A_P_S_A @JCI_Insight

4
16
2,252
Daniel Brock retweeted

Feb 17
Inspired by @JswLab, we generated a mini Genome-wide Perturb-seq, using just two 10x lanes (!).
Far too much data for one tweet (or one Figure), but it works beautifully.
The ability to assess the molecular function of every gene in an afternoon is mind-boggling
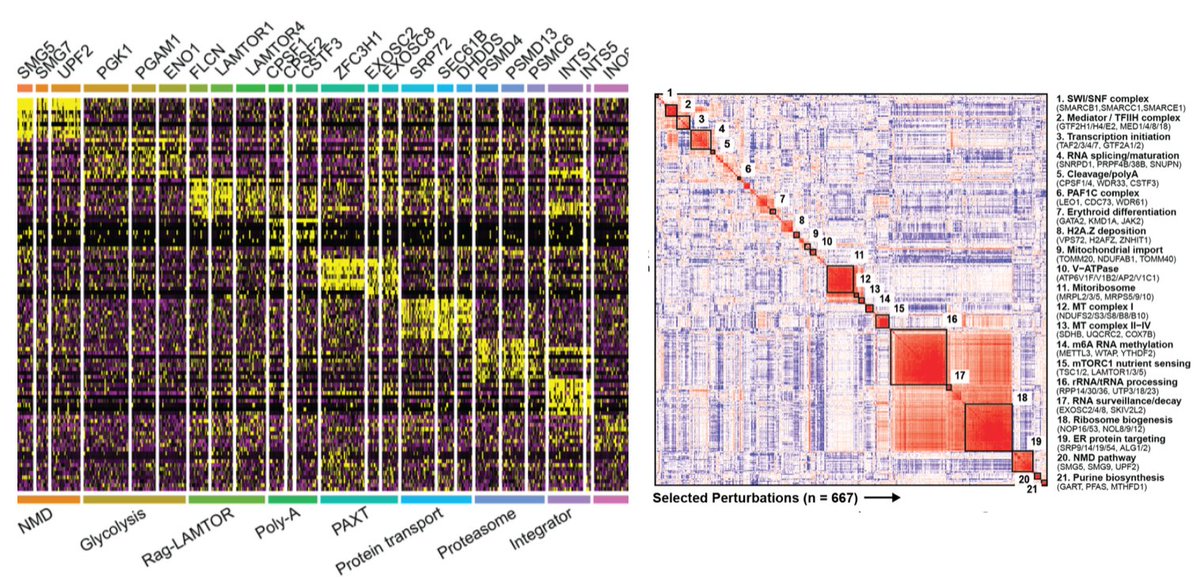
1
32
181
12,093
Daniel Brock retweeted

19 Jul 2025
1/ You're not just sequencing single cells.
You're sequencing the soup they're in.
Ambient RNA is everywhere in single-cell RNA-seq. Here's how to fix it.

2
21
200
22,134
Daniel Brock retweeted

7 Jul 2025
DNA methylation goes spatial! Introducing Spatial-DMT: a technology that co-profiles DNA methylation and transcriptome in the same tissue section. A fantastic collaboration with @zhouwanding lab. Kudos to Chin Nien Lee @ChinNLee2021 and Hongxiang Fu! biorxiv.org/content/10.1101/…
8
45
172
21,908

An AI model developed by Google DeepMind could help scientists make sense of the non-protein-coding part of the genome
go.nature.com/4es61QU
4
61
277
32,124
Daniel Brock retweeted

17 May 2025
I used to spend months agonizing over my research direction.
Now, I can find a compelling PhD topic in just one day.
The secret? This guide:

ALT The guide from Lennart Nacke outlines an 8-step process for PhD students to choose a compelling research topic, covering everything from exploring personal interests to using AI tools, while ensuring originality and feasibility.
2
128
538
46,500
7 May 2025
Drop by poster B0008 today to learn about genetic risk factors for retinal detachment! We found that variants in VSX2 were associated with an increased risk of retinal detachment in the UK Biobank.
Shout out to my PIs Ben Frankfort and Ryan Dhindsa!
@ARVOinfo #visionscience
2
22
599
Daniel Brock retweeted

26 Apr 2025
Today at the #JointMeeting2025, Svetlana Mojsov, 2024 #LaskerLaureate, gave an impressive overview of how her research on GLP-1 revolutionized the field of glucose metabolism. Her findings led to development of novel therapeutics for #diabetes and #obesity. @A_P_S_A

2
4
34
1,644

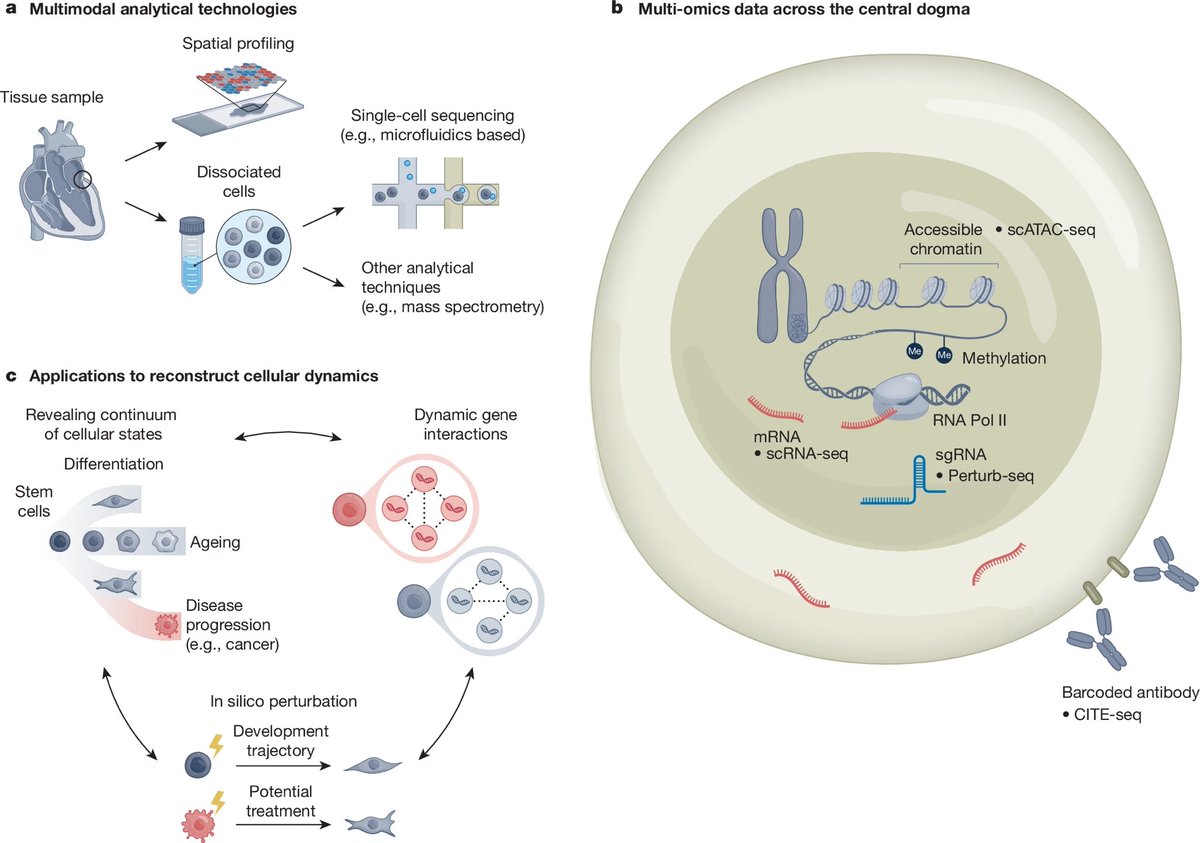
🚀 Our perspective is out in @Nature!
We present a roadmap for Multimodal Foundation Models (MFMs) — large AI models pretrained across multi-omics and multi-timepoint data — to serve as the computational backbone for building virtual cells.
Read the full paper in Nature: nature.com/articles/s41586-0…
🔍 Why MFMs?
Biology is inherently multimodal, and molecular layers are deeply interconnected and context-specific. MFMs aims to integrate these layers to uncover shared biological principles that govern diverse cell states, offering a unified substrate for downstream inference.
🧠 What’s new?
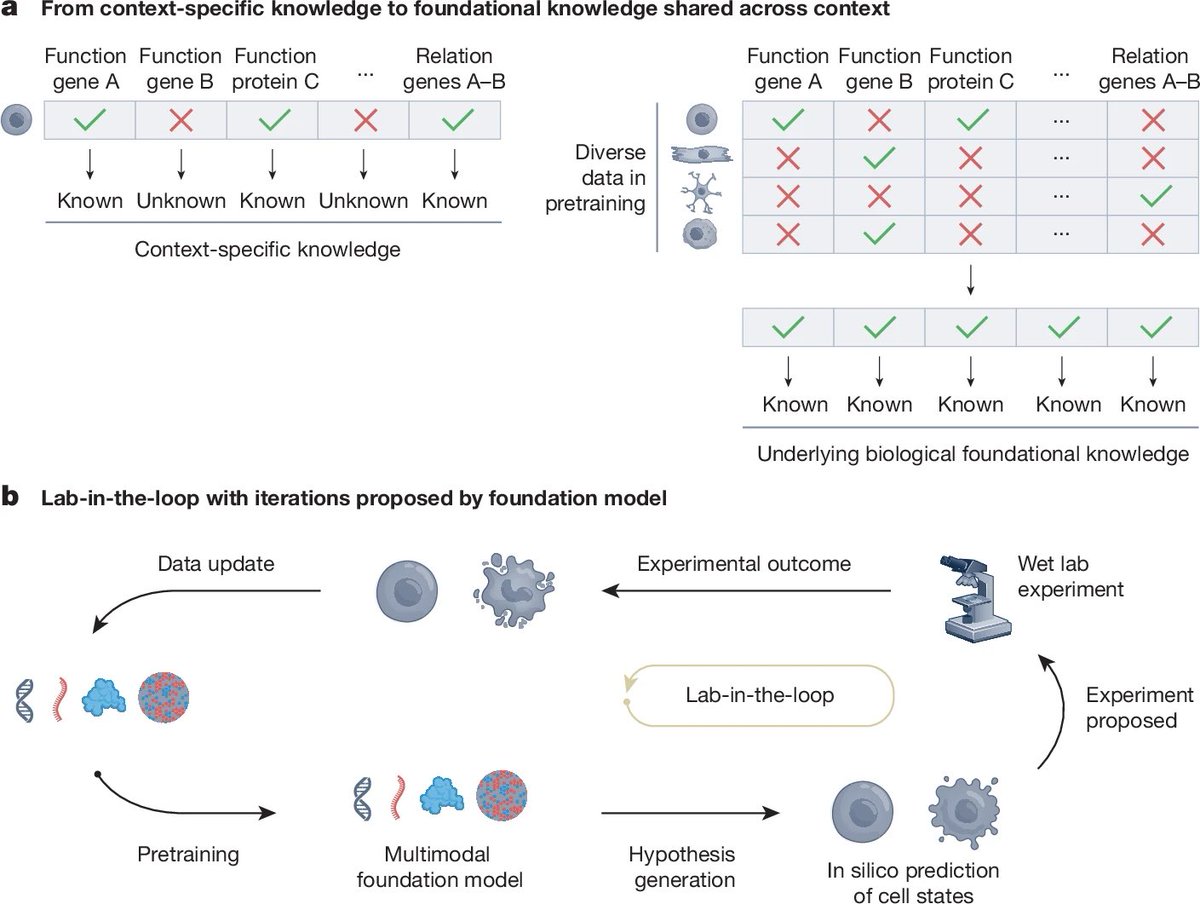
💡 From hypothesis-driven to data-centric workflows: MFMs shift biology’s paradigm. Instead of crafting bespoke models for narrow tasks, we can now pretrain over massive datasets, distill foundational knowledge, and refine insights through lab-in-the-loop experimentation—where models guide experiments, and experiments update models.
🧬 Conditional gene regulation: MFMs go beyond static models. By training across multiple omics layers (e.g., chromatin accessibility, transcriptomics), they can learn context-specific gene functions and regulatory programs—key to understanding development and disease.
🧪 In silico perturbation: Biology’s combinatorial complexity is immense—thousands of genes, millions of interactions. MFMs provide a framework to simulate perturbations before wet-lab execution. Trained on CRISPR perturb-seq data, they can predict molecular responses across cell types, tissues, and time—enabling programmable biology at scale.
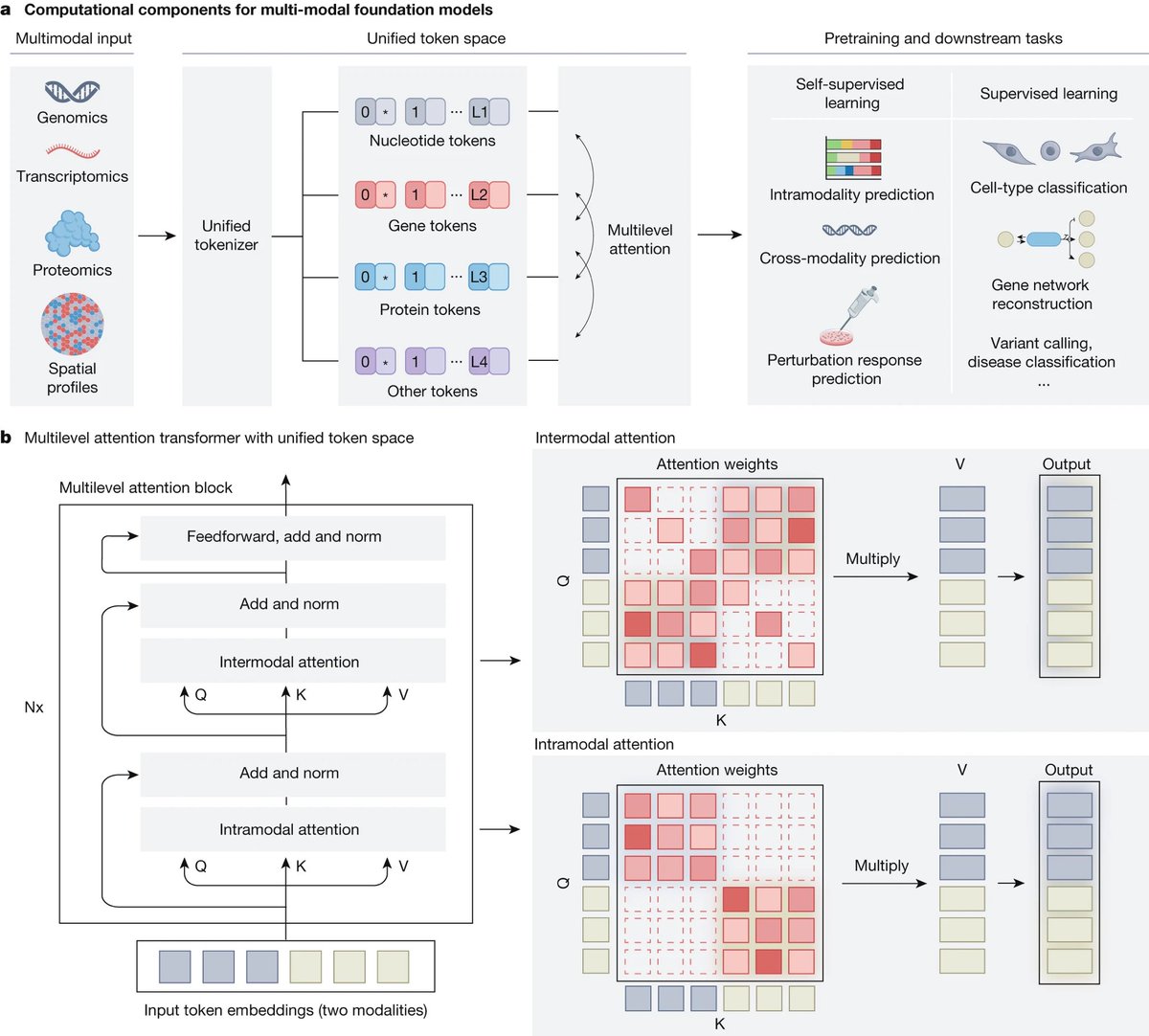
⚙️ What makes MFMs possible?
Envisioned techniques include:
- Unified tokenization from nucleotides to pathways
- Hybrid attention across intra- and inter-modal interactions
- Prompt-driven multitasking for temporal prediction, conditional generation, and modality translation
- Human knowledge integration from curated databases and biomedical literature
These design principles translate the architecture of foundation models into the molecular domain.
⚠️ What are the challenges?
MFMs aren’t just about scale—they demand accessibility, reliability, and transparency.
- Low-resource learning techniques (e.g., LoRA, adapters) are vital for democratizing training
- Human-agnostic benchmarks are needed, as conventional labels may punish models that uncover novel biology
- Uncertainty modeling is essential to mitigate hallucinations and increase scientific trust
Interpretability and ethical stewardship must be foundational in this emerging ecosystem.
Kudos to all co-authors for the collective effort and vision: @HOATIANCUI1, @Alejandro__TL, @mariabrbic, @JulioSaezRod, @simocristea, @genophoria, @mo_lotfollahi, @fabian_theis.
Let’s build the future of virtual cells together.

18
166
561
75,324

News: NIH researchers develop eye drops that slow vision loss in animals nih.gov/news-events/news-rel…
9
27
82
16,566
Daniel Brock retweeted

10 Mar 2025
Amazing @A_P_S_A South Regional Meeting this year! It was a treat talking to undergrads about the work we do @BCM_MSTP @BCMFromtheLabs and providing mentorship/guidance on their next steps as future physician scientists. And huge shoutout to our amazing chair @DanielCBrock!




2
3
12
916
Daniel Brock retweeted
3 Mar 2025
Long-range enhancer-controlled genes are hypersensitive to regulatory factor perturbations cell.com/cell-genomics/fullt…

1
16
85
7,067
Daniel Brock retweeted
27 Feb 2025
Check out our two new papers with new single-cell tech/methods/data!
1. Phospho-seq: Multi-modal profiling of intracellualar proteins
nature.com/articles/s41467-0…
2. Systematic Perturb-seq of signaling regulators (2.6M cells, 6 cell lines, 1500 perturbations)
nature.com/articles/s41556-0…
3
84
343
29,540
25 Feb 2025
Thrilled the APSA South Regional Meeting was a success! 🎉
Huge thanks to attendees, organizers, @BCM_MSTP & @TexasChildrens hosting, and @A_P_S_A for making it happen!
Interested in hosting next year’s meeting? DM me—we’ve got resources to share! #APSA #PhysicianScientists



3
20
744
Daniel Brock retweeted
21 Feb 2025
Fabulous energy here today as we host the south regional APSA conference. Kudos to the student organizers for a great turnout!




3
9
631
Daniel Brock retweeted

5 Jan 2025
Spliceopathies are a group of rare diseases caused by inborn errors in RNA splicing mechanisms. The causative mutations could be challenging to identify as they are often noncoding and sit within snRNA genes. Here the authors use a transcriptomics-first approach to screen individuals with undiagnosed rare diseases with aberrant transcriptomic profile and then investigate the genetic cause, successfully diagnosing five individuals with snRNA mutations.
Arriaga, Mendez et al. medRxiv
medrxiv.org/content/10.1101/…
1
13
50
5,372