
Joined November 2021
- Tweets 587
- Following 325
- Followers 706
- Likes 1,973
205 Photos and videos
















FLORENCE center for DATA SCIENCE retweeted

Apr 2
📢 STATS UNDER THE STARS 9 IS COMING! 🌟
📍 Rome, Sapienza University of Rome – Department of Statistical Sciences
📅 Night between June 21-22, 2026
🔗 Website: sites.google.com/view/sus-20…
#SUS9 #StatsUnderTheStars #DataScience #Statistics #SIS2026 #SISFENStat #YoungSIS #AI
1
1
109
FLORENCE center for DATA SCIENCE retweeted
Mar 9
📢We’re excited to share that StaTalk 2026 is coming on 21–22 May 2026 at the University of Turin!
✨For researchers & students
🗓️21–22 May 2026
💻Register & submit abstracts now! sites.google.com/view/statal…
#StaTalk2026 #Statistics
1
1
119
FLORENCE center for DATA SCIENCE retweeted
Post-selection inference studies how to perform valid statistical inference after a model, variable set, or hypothesis has been chosen using the same data. Classical theory assumes the model is fixed in advance, but modern workflows first select features, tune hyperparameters, or choose networks, which introduces hidden bias. Post-selection theory corrects for this by conditioning on the selection event and using tools from probability, such as truncated distributions, martingales, and selective likelihoods, to recover valid p-values and confidence intervals. In statistics, it enables honest inference after LASSO, stepwise regression, and data-driven model choice. In machine learning, it is crucial for feature selection, neural architecture search, and adaptive pipelines, where naïve uncertainty estimates are misleading. In deep learning, post-selection ideas support reliable evaluation and interpretability. By accounting for data reuse, post-selection inference restores trust in conclusions drawn from complex, adaptive learning systems.
share.google/hmMCFXovg4yqKzI…

2
11
77
3,992
FLORENCE center for DATA SCIENCE retweeted

Jan 28
PSA I've left MIT for Harvard now
Jan 27

🚨 Your AI is lying to you with complete confidence.
Harvard & MIT just proved ChatGPT hallucinates 110% less when you force it to argue with itself.
The technique is called "Recursive Meta-Cognition" and it's embarrassingly simple.
Here's how to make AI actually think:

18
2
257
35,302
📢 FDS–DiSIA Seminar
Peter McCullagh (University of Chicago)
Title: Statistics of speciation and the evolution of reproductive isolation
🗓 Jan 30, 2026 | 11:00📍 DiSIA, Room 205 (Florence)
In person, open to all.
#Statistics #DataScience
1
43
FLORENCE center for DATA SCIENCE retweeted

9 Dec 2025
Will 2026's hottest new job be "AI phronestician"?
tinyurl.com/ye23a4ce

3
1
464
FLORENCE center for DATA SCIENCE retweeted

Jan 2
"Learning to break down problems into smaller pieces is one of the most important skills in computer science/life." — Addy Osmani (@addyosmani)
8
30
186
13,127
FLORENCE center for DATA SCIENCE retweeted
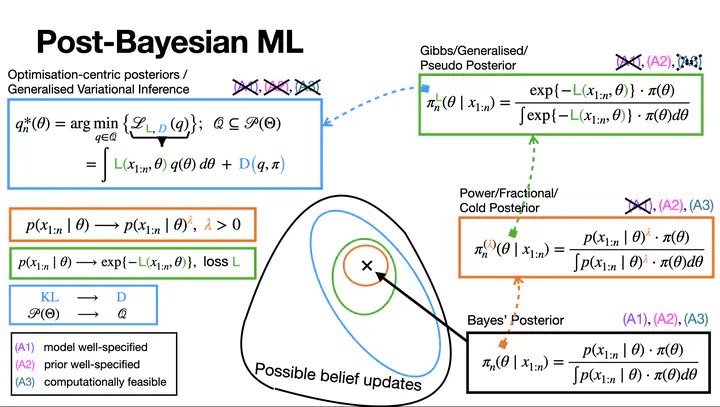
Bayesian machine learning is an approach to modeling and inference that treats unknown parameters and predictions as random variables and updates beliefs using Bayes’ rule as new data arrives. Instead of producing single best guesses, it produces full probability distributions that quantify uncertainty. In probability theory, Bayesian ML builds directly on conditional probability, likelihoods, and prior distributions, providing a coherent framework for learning from data. In machine learning, it powers methods such as Bayesian neural networks, Gaussian processes, and probabilistic graphical models, enabling robust prediction, uncertainty estimation, and principled model comparison. In real life, Bayesian ML is used in medicine, finance, robotics, and recommendation systems, where decisions must be made under uncertainty and models must adapt as evidence accumulates.
Image: share.google/R4mi0AVfeKLeZbm…
6
110
747
29,931
FLORENCE center for DATA SCIENCE retweeted

29 Dec 2025
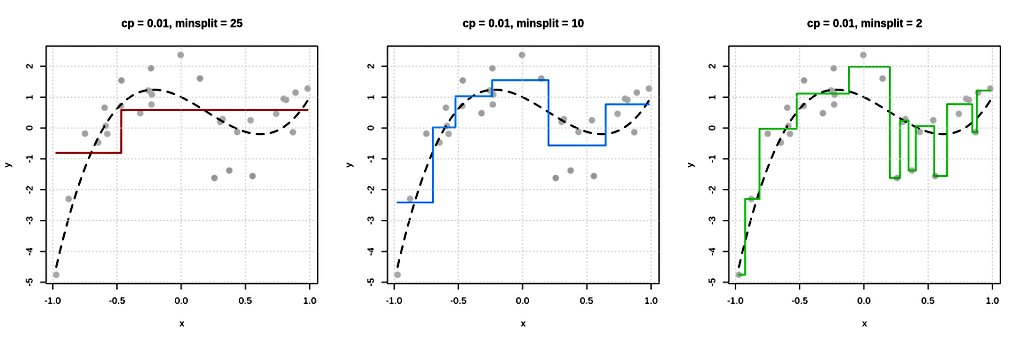
Nonparametric regression (f̂ = arg min ∥y − f(x)∥² λ∥f∥²_H) is a flexible approach to modeling the relationship between inputs and outputs without assuming a fixed functional form, allowing the data itself to determine the shape of the curve. In probability theory, it is studied through kernel estimators, splines, and Gaussian processes, which describe how random functions can be estimated and how uncertainty behaves as sample size grows. In machine learning, nonparametric regression powers methods such as k-nearest neighbors, kernel ridge regression, and Gaussian process regression, enabling accurate prediction in complex, high-dimensional settings. In real life, it is used in economics, medicine, climate science, and engineering to uncover trends, forecast outcomes, and make decisions when the true underlying relationship is unknown or too complicated to be captured by simple formulas.
Image: share.google/TxX6kASyd4LY3xL…
3
45
265
16,961

31 Dec 2025
Thank you, 2025, for all the models that were perfect on training data and then failed spectacularly. Overfitting keeps us humble. Also, thank you for making “it depends” the correct answer more often than not. In 2026, may we at least know WHAT it depends on. 🥳 #datascience
1
2
6
148
FLORENCE center for DATA SCIENCE retweeted

13 Dec 2025
My online free collaborative textbook is here: chabefer.github.io/STCI/ feedback welcome :D
Statistical Tools for Causal Inference
This is an open source collaborative book.
chabefer.github.io 8
23
1,803
FLORENCE center for DATA SCIENCE retweeted

1 Dec 2025
E-learning: come viene utlizzata l’intelligenza artificiale nella formazione delle aziende? infodata.ilsole24ore.com/202…
2
3
118
FLORENCE center for DATA SCIENCE retweeted
5 Dec 2025
Interesting:

16
474
3,219
121,614
FLORENCE center for DATA SCIENCE retweeted

4 Dec 2025
Tensors are instrumental in physics, machine learning and even biology. Einstein once begged a friend to help him understand them, fearing he was going mad. Joseph Howlett explains how they work: quantamagazine.org/the-geome…
20
240
1,387
76,960
FLORENCE center for DATA SCIENCE retweeted

25 Nov 2025
Oggi è stato consegnato il Premio di Laurea “Eleonora Guidi” per onorare la memoria della giovane vittima di femminicidio. #UNIFI ribadisce così il proprio impegno nella prevenzione e nel contrasto della violenza di genere.
#StopAllaViolenza #ParitàDiGenere



1
3
379
25 Nov 2025
On the International Day for the Elimination of Violence Against Women, we are reminded of the work still ahead and the responsibility we share. We can help create a world where every woman feels safe, respected, and free to live, study, and work without fear #EndVAW
1
1
34
FLORENCE center for DATA SCIENCE retweeted

14 Nov 2025
Book PDF (730 pages) :
"High-Dimensional Data Analysis with Low-Dimensional Models" by Wright & Ma
👉PDF: book-wright-ma.github.io/
Preface by E. Candes

7
195
1,085
47,004
FLORENCE center for DATA SCIENCE retweeted

12 Nov 2025
We’re at the European Parliament, where ERC grantees meet MEPs to bridge frontier research and policy.
Tune in on Wed 12 Nov at 14.30 europarl.europa.eu/streaming…
Who benefits from such exchanges? Hear from ERC President Maria Leptin.
1
5
18
2,963
On 23 Oct 2025 we welcomed colleagues from @OsloMet to the Florence Center for Data Science. Many thanks for a stimulating day of discussion — we look forward to future collaboration. Photo: lunch with the FDS Think Tank. #AcademicCollab #DataScience
1
2
79
FLORENCE center for DATA SCIENCE retweeted

8 Nov 2025
Our brilliant job market candidates!
eui.eu/en/academic-units/dep…

4
10
779