
21 | SDE | AI Enthusiast | Full stack developer | Freelancer | Competitive programmer ||
Joined November 2025
- Tweets 91
- Following 152
- Followers 21
- Likes 98
2 Photos and videos


Ded_Coderx retweeted

Mar 4
As a backend developer in 2026, how many of these 10 terms do you understand?
1. Idempotency
2. Backpressure
3. Circuit Breaker
4. Eventual Consistency
5. Distributed Lock
6. Exactly-Once vs At-Least-Once Delivery
7. Cold Start
8. High Cardinality Metrics
9. Sharding vs Partitioning
10. P99 Latency
14
61
458
24,528
Ded_Coderx retweeted

16 Dec 2025
LLMs Roadmap
├── 01_Foundations
│ ├── Programming_Basics
│ │ ├── Python_for_AI
│ │ │ ├── Data_Types_Functions_Modules
│ │ │ ├── Virtual_Environments_Packages
│ │ │ └── Real_Project
│ │ │ └── Build_a_Text_File_Analyzer
│ ├── Math_for_LLMs
│ │ ├── Linear_Algebra_Basics
│ │ ├── Probability_and_Statistics
│ │ └── Intuition_Focused_Learning
│ └── Computer_Science_Fundamentals
│ ├── Data_Structures
│ ├── Algorithms_Basics
│ └── Complexity_Thinking
│
├── 02_Machine_Learning_Core
│ ├── ML_Concepts
│ │ ├── Supervised_vs_Unsupervised
│ │ ├── Training_vs_Inference
│ │ └── Overfitting_Underfitting
│ ├── Tools
│ │ ├── NumPy_Pandas
│ │ ├── Scikit_Learn
│ │ └── Matplotlib
│ └── Real_Project
│ └── Build_a_Text_Classifier_for_Support_Tickets
│
├── 03_Neural_Networks
│ ├── Core_Concepts
│ │ ├── Neurons_Layers_Activations
│ │ ├── Backpropagation
│ │ └── Loss_Functions
│ ├── Frameworks
│ │ ├── PyTorch
│ │ └── TensorFlow
│ └── Real_Project
│ └── Build_a_Sentiment_Analysis_Model
│
├── 04_NLP_Foundations
│ ├── Text_Processing
│ │ ├── Tokenization
│ │ ├── Stopwords_Stemming_Lemmatization
│ │ └── Vectorization
│ ├── Language_Models_Before_LLMs
│ │ ├── N_Grams
│ │ ├── Word2Vec_GloVe
│ │ └── Limitations
│ └── Real_Project
│ └── Build_a_Smart_Search_Engine_for_Documents
│
├── 05_Transformers_and_LLM_Core
│ ├── Transformer_Architecture
│ │ ├── Self_Attention
│ │ ├── Multi_Head_Attention
│ │ ├── Positional_Encoding
│ │ └── Encoder_vs_Decoder
│ ├── Popular_LLMs
│ │ ├── GPT_Family
│ │ ├── LLaMA
│ │ ├── Mistral
│ │ └── Claude
│ └── Real_Project
│ └── Build_a_Mini_GPT_Text_Generator
│
├── 06_LLM_Usage_and_Engineering
│ ├── Prompt_Engineering
│ │ ├── Zero_Shot
│ │ ├── Few_Shot
│ │ ├── Chain_of_Thought
│ │ └── System_Prompts
│ ├── LLM_APIs
│ │ ├── OpenAI_API
│ │ ├── HuggingFace_Inference
│ └── Real_Project
│ └── Build_an_AI_Study_Assistant
├── 07_Retrieval_Augmented_Generation_RAG
│ ├── Core_Idea
│ │ ├── Embeddings
│ │ ├── Vector_Databases
│ │ └── Context_Injection
│ ├── Tools
│ └── Real_Project
│ └── Build_a_Custom_Knowledgebase_Chatbot
├── 08_Fine_Tuning_and_Optimization
│ ├── Fine_Tuning
│ ├── Evaluation
│ └── Real_Project
│ └── Fine_Tune_an_LLM_for_Customer_Support
│
├── 09_AI_Agents_and_Tools
│ ├── Agent_Concepts
│ ├── Frameworks
│ │ ├── LangChain
│ └── Real_Project
│ └── Build_an_AI_Agent_that_Automates_Research
├── 10_Deployment_and_Production
│ ├── Model_Serving
│ │ ├── FastAPI
│ │ ├── Docker
│ │ └── GPU_Usage
│ ├── Cloud
│ │ ├── AWS_GCP_Azure
│ │ ├── Serverless_AI
│ │ └── Cost_Optimization
│ └── Real_Project
│ └── Deploy_an_AI_Chat_App_for_Real_Users
├── 11_Responsible_and_Modern_AI
│ ├── Ethics
│ ├── Security/
│ └── Real_Project
│ └── Secure_and_Monitor_an_LLM_Based_System
└── 12_Capstone_Real_World_AI_Product
├── Idea
│ ├── AI_SaaS
│ ├── AI_Tutor
│ ├── AI_Coding_Assistant
│ └── AI_Business_Analytics_Tool
├── Build
│ ├── End_to_End_System
│ ├── Scalable_Architecture
│ └── Real_User_Feedback
└── Outcome
└── Production_Ready_LLM_Product
Grab this Ebook resource to deepen your LLM journey:
codewithdhanian.gumroad.com/…

37
262
1,544
90,893
Ded_Coderx retweeted

7 Dec 2025
Stop wasting hours trying to learn AI. 📘📚
I have already done it for you.
With one list. Zero confusion. And no fluff
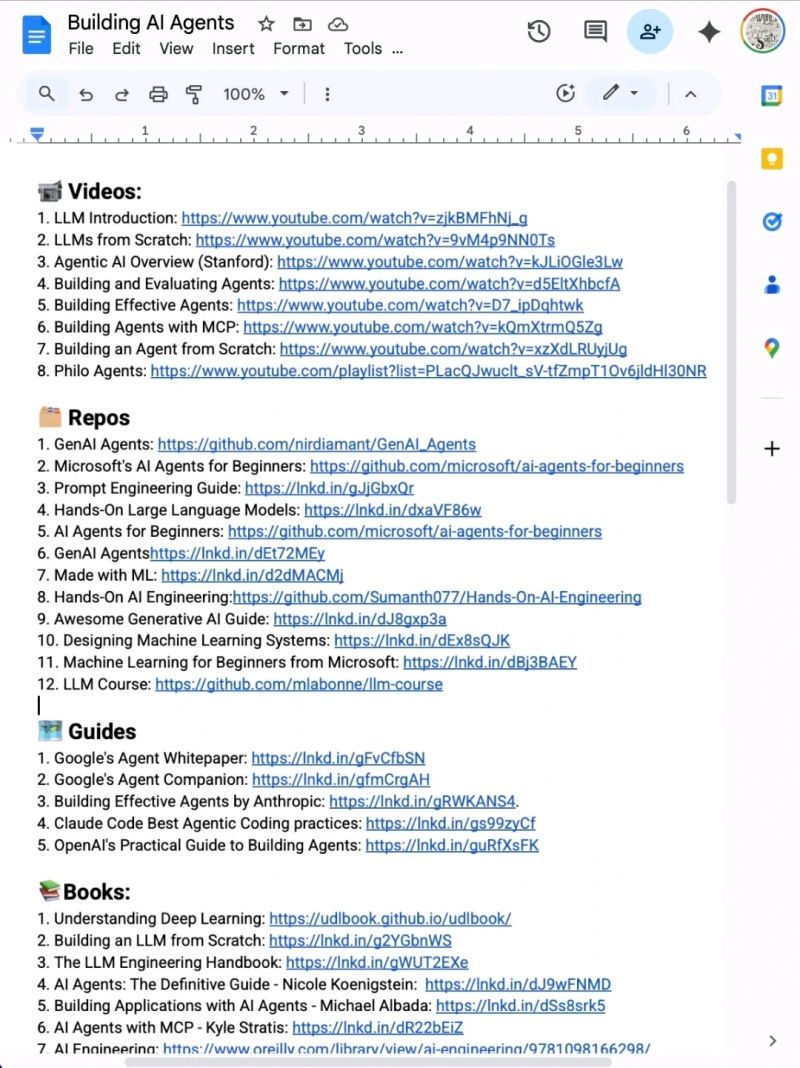
📹 Videos:
1. LLM Introduction: lnkd.in/dMqbaZdK
2. LLMs from Scratch: lnkd.in/dYYwEhYy
3. Agentic AI Overview (Stanford): lnkd.in/dArmMt2i
4. Building and Evaluating Agents: lnkd.in/dBWd2W8u
5. Building Effective Agents: lnkd.in/dHfdebqw
6. Building Agents with MCP: lnkd.in/dXuNHrRJ
7. Building an Agent from Scratch: lnkd.in/da3ANw3w
8. Philo Agents: lnkd.in/dq-BfZE5
🗂️ Repos
1. GenAI Agents: lnkd.in/d3UDtwwv
2. Microsoft's AI Agents for Beginners: lnkd.in/dHvTmJnv
3. Prompt Engineering Guide: lnkd.in/gJjGbxQr
4. Hands-On Large Language Models: lnkd.in/dxaVF86w
5. AI Agents for Beginners: lnkd.in/dHvTmJnv
6. GenAI Agentshttps://lnkd.in/dEt72MEy
7. Made with ML: lnkd.in/d2dMACMj
8. Hands-On AI Engineering:lnkd.in/dgQtRyk7
9. Awesome Generative AI Guide: lnkd.in/dJ8gxp3a
10. Designing Machine Learning Systems: lnkd.in/dEx8sQJK
11. Machine Learning for Beginners from Microsoft: lnkd.in/dBj3BAEY
12. LLM Course: lnkd.in/diZgGACG
🗺️ Guides
1. Google's Agent Whitepaper: lnkd.in/gFvCfbSN
2. Google's Agent Companion: lnkd.in/gfmCrgAH
3. Building Effective Agents by Anthropic: lnkd.in/gRWKANS4.
4. Claude Code Best Agentic Coding practices: lnkd.in/gs99zyCf
5. OpenAI's Practical Guide to Building Agents: lnkd.in/guRfXsFK
📚Books:
1. Understanding Deep Learning: lnkd.in/dgcB68Qt
2. Building an LLM from Scratch: lnkd.in/g2YGbnWS
3. The LLM Engineering Handbook: lnkd.in/gWUT2EXe
4. AI Agents: The Definitive Guide - Nicole Koenigstein: lnkd.in/dJ9wFNMD
5. Building Applications with AI Agents - Michael Albada: lnkd.in/dSs8srk5
6. AI Agents with MCP - Kyle Stratis: lnkd.in/dR22bEiZ
7. AI Engineering: lnkd.in/gi-mQcXa
📜 Papers
1. ReAct: lnkd.in/gRBH3ZRq
2. Generative Agents: lnkd.in/gsDCUsWm.
3. Toolformer: lnkd.in/gyzrege6
4. Chain-of-Thought Prompting: lnkd.in/gaK5CXzD.
🧑🏫 Courses:
1. HuggingFace's Agent Course: lnkd.in/gmTftTXV
2. MCP with Anthropic: lnkd.in/geffcwdq
3. Building Vector Databases with Pinecone: lnkd.in/gCS4sd7Y
4. Vector Databases from Embeddings to Apps: lnkd.in/gm9HR6_2
5. Agent Memory: lnkd.in/gNFpC542
Repost for your network ♻️
&follow for more stuff on building AI Agents.
95
1,162
4,256
391,957
Ded_Coderx retweeted

5 Dec 2025
For people who keep asking what to build in AI Engineering
> Build your own Reasoner (Chain of Thought implementation)
> Build your own Agent loop (ReAct pattern)
> Build your own Inference Server (in C /Rust)
> Build your own Transformer from scratch (Attention is all you need)
> Build your own Vector Database (HNSW index)
> Build your own RAG pipeline
> Build your own Flash Attention kernel (CUDA)
> Build your own Quantization library (Int8/FP4 implementation)
> Build your own Mixture of Experts (MoE) routing layer
> Build your own Distributed training loop (FSDP/Tensor Parallelism)
> Build your own KV Cache paging system (like vLLM)
> Build your own Speculative Decoding system
> Build your own State Space Model (Mamba implementation)
> Build your own RLHF pipeline (PPO implementation)
> Build your own Small Language Model (SLM)
> Build your own Matrix Multiplication kernel
> Build your own LoRA (Low-Rank Adaptation) trainer
> Build your own Code interpreter sandbox
> Build your own DPO (Direct Preference Optimization) loss function
> Build your own Graph RAG system
> Build your own Model merger (Model Soups/Spherical Linear Interpolation)
> Build your own Interpretability tool (SAE - Sparse Autoencoders)
> Build your own Synthetic data generator
> Build your own Function Calling router
> Build your own Structured Output parser (Context Free Grammars)
> Build your own Multi-modal projector (CLIP implementation)
> Build your own LLM Eval harness
> Build your own Guardrails system (Input/Output filtering)
> Build your own Prompt caching mechanism
> Build your own Tokenizer (BPE implementation)
> Build your own Autograd engine (like Micrograd)
> Build your own Diffusion model (UNet Scheduler)
> Build your own Vision Transformer (ViT)
> Build your own Whisper-style ASR model
> Build your own Text-to-Speech pipeline
> Build your own Semantic Router
> Build your own Knowledge Graph builder
> Build your own Data curation pipeline (MinHash/Deduplication)
> Build your own AI Gateway (Load balancing/Failover)
> Build your own Parameter Efficient Fine-Tuning (PEFT) library
> Build your own Text-to-SQL engine
> Build your own Recommendation system (Two-tower architecture)
> Build your own Embedding model
> Build your own Logit Processor
> Build your own Softmax kernel optimization
> Build your own Adversarial attack generator
> Build your own Audio Spectrogram transformer
> Build your own Neural Architecture Search
> Build your own Model Distillation pipeline
> Build your own Feature Store
> Build your own Database driver (for Vectors)
38
103
878
47,324

1 Dec 2025
This heap map drop hurts a lot, but no worries i'll regain my dsa consistency. From tomorrow onwards, I am starting again along with building and learning cool stuffs #DSA #ConsistencyWins #problemSolving
1
2
100
1 Dec 2025
Trying to figure out if premium helps reach or if I just wasted money 🙃
2
75
1 Dec 2025
Never ask a Rustacean whether they are into Rust, They’ll exhaust you, idk why 🙂
1
2
94
Ded_Coderx retweeted

1 Dec 2025
Stripe offers a insane 85LPA for the SDE 2 roles, with just 3 year of experience.
Here is a complete salary breakdown 👇

14
26
624
22,281
30 Nov 2025
Back in college I was that guy who grinded 1200 DSA problems, hit Specialist on Codeforces, built some solid full-stack and ML projects, open-sourced half of them, everything.
Result? On-campus placement → 17 LPA SDE role Meanwhile some random dudes who barely knew how to push code on GitHub, never touched competitive programming, projects = one to-do app in React… bagged 45-60 LPA because their interview day was their life’s best 3 rounds some luck college training cell pushing them to the right company.
On-campus placements are literally a lottery disguised as meritocracy.
It’s a boon when you hit the jackpot.
It’s a headache when you realize 4 years of grinding can still get outscaled by one good day of HR luck “cultural fit”.
off-campus opportunities are shaping up to be much better now, but honestly… college placements can be really humbling. What do you think? Is it purely a skill issue, or is the system itself flawed
3
137
30 Nov 2025
If you are learning ML, do not chase frameworks, chase intuition. Frameworks change, but intuition doesn’t #machinelearningengineer #ai
2
117
30 Nov 2025
Finally grabbed X Premium ✨
Time to stop lurking and start dropping real value.
From now on, expect:
1) Raw tech takes & deep dives
2) My journey as a full-stack AI engineer
3) What I am learning in real time
4) Freelance wins, job hunt stories, startup red flags
No fluff, just the stuff I wish I saw when I started.
Let’s see how far this blue tick can take us #AI #WebDev #BuildInPublic #SoftwareEngineering
1
3
172
29 Nov 2025
There’s a new trend: early-stage founders offering equity and “lead roles” instead of actual payment just to get their MVP built. Smart cost-cutting moves for them, but not always worth it for developers. Always evaluate the risk, equity value, and your time before saying yes
2
94
28 Nov 2025
I want to learn Web3 development in depth but i didn't find that much resources and proper roadmap on the internet, can anybody help me out please ? 😊
#Web3 #Blockchain #LearningInPublic #SoftwareDevelopment
2
81
Ded_Coderx retweeted

27 Nov 2025
This free CUDA course is worth more than most CS degrees.
12 hours that separate library users from GPU engineers.
I watched senior devs struggle with concepts taught in hour 3.
What makes it different:
No hand-waving. No "just use this library."
You build an MLP trainer FOUR times: → PyTorch (the easy way) → NumPy (getting harder) → C (now we're cooking) → CUDA (chef's kiss)
Same model. Same dataset. Four implementations.
By the end, you understand WHY PyTorch is fast.
The curriculum nobody else teaches:
➡️ GPU architecture (not just "it's parallel")
➡️ Writing kernels that don't suck
➡️ Profiling at kernel AND system level
➡️ When cuBLAS helps (and when it doesn't)
➡️ CUDA vs Triton (the comparison you need)
➡️ PyTorch extensions (actually useful ones)
Real talk:
➡️ After this course, you'll read PyTorch source code and understand it.
➡️ You'll optimize models other engineers can't touch.
➡️ You'll be the person teams hire to make things fast.
12 hours. Free. No excuses.
Who's starting this weekend?
(I will put the details in the comments.)
♻️ Repost to save someone $$$ and a lot of confusion.
✔️ You can follow @techNmak , for more insights.

25
307
2,560
135,903
Ded_Coderx retweeted

24 Nov 2025
Microsoft.
Google.
AWS.
Everyone's trying to solve the same problem for AI Agents:
How to build knowledge graphs that are fast enough for real-time LLM applications?
FalkorDB is an open-source graph database that solves this by reimagining how graphs work. It uses sparse matrices and linear algebra instead of traditional traversal!
Let's understand what makes them so fast:
Traditional graph databases store relationships as linked nodes and traverse them one hop at a time.
But there's a problem:
When you query for connections, the database walks through nodes and edges like following a map. For massive knowledge graphs powering AI agents, this creates a serious bottleneck.
But what if you could represent the entire graph as a mathematical structure?
This is where sparse matrices come in.
A sparse matrix stores only the connections that exist. No wasted space, no unnecessary data. Just the relationships that matter.
And here's the breakthrough:
Once your graph is a sparse matrix, you can query it using linear algebra instead of traversal. Your queries become mathematical operations, not step-by-step walks through nodes.
Math is faster than traversal. Much faster.
Plus, sparse matrices make storage incredibly efficient. You're only storing what exists, which means you can fit massive knowledge graphs in memory without burning through resources.
So, why not just stick to Vector Search?
Vector search is fast, but it only captures naive similarity. They find patterns, but miss the structure.
Graphs capture the nuanced relationships between entities. This ensures the context retrieved for your Agent is highly accurate and relevant, not just "similar."
And here's what you get with FalkorDB:
↳ Ultra-fast, Multi-tenant Graph Database
↳ Efficient storage using sparse matrix representation
↳ Compatible with OpenCypher (same query language as Neo4j)
↳ Built specifically for LLM applications and agent memory
↳ Runs on Redis for easy deployment
Getting started takes one Docker command. I tested it with their Python client, and the performance difference is immediately noticeable.
If you're building AI agents that need real-time access to connected information, this is worth exploring.
The best part it's 100% open-source!
I've shared the link to their GitHub repo in the next tweet!
44
154
960
86,759
Ded_Coderx retweeted

23 Nov 2025
"Foundations of Machine Learning"
A MUST while starting AI/ML. Absolutely Beginner friendly.
To get: -
1. Follow (So I can DM you )
2. Like & retweet
3. Reply " Send "

622
695
3,271
229,838
Ded_Coderx retweeted

20 Nov 2025
You're in an AI engineer interview at Apple.
The interviewer asks:
"Siri processes 25B requests/mo.
How would you use this data to improve its speech recognition?"
You: "Upload all voice notes from devices to iCloud and train a model"
Interview over!
Here's what you missed:
Modern devices (like smartphones) host a ton of data that can be useful for ML models.
To get some perspective, consider the number of images you have on your phone right now, the number of keystrokes you press daily, etc.
And this is just about one user: you.
But applications have millions of users, so the amount of data is unfathomable.
The problem is that data on modern devices is mostly private.
- Images are private.
- Messages you send are private.
- Voice notes are private.
So it cannot be aggregated in a central location to centrally train ML models.
Federated learning smartly addresses this challenge.
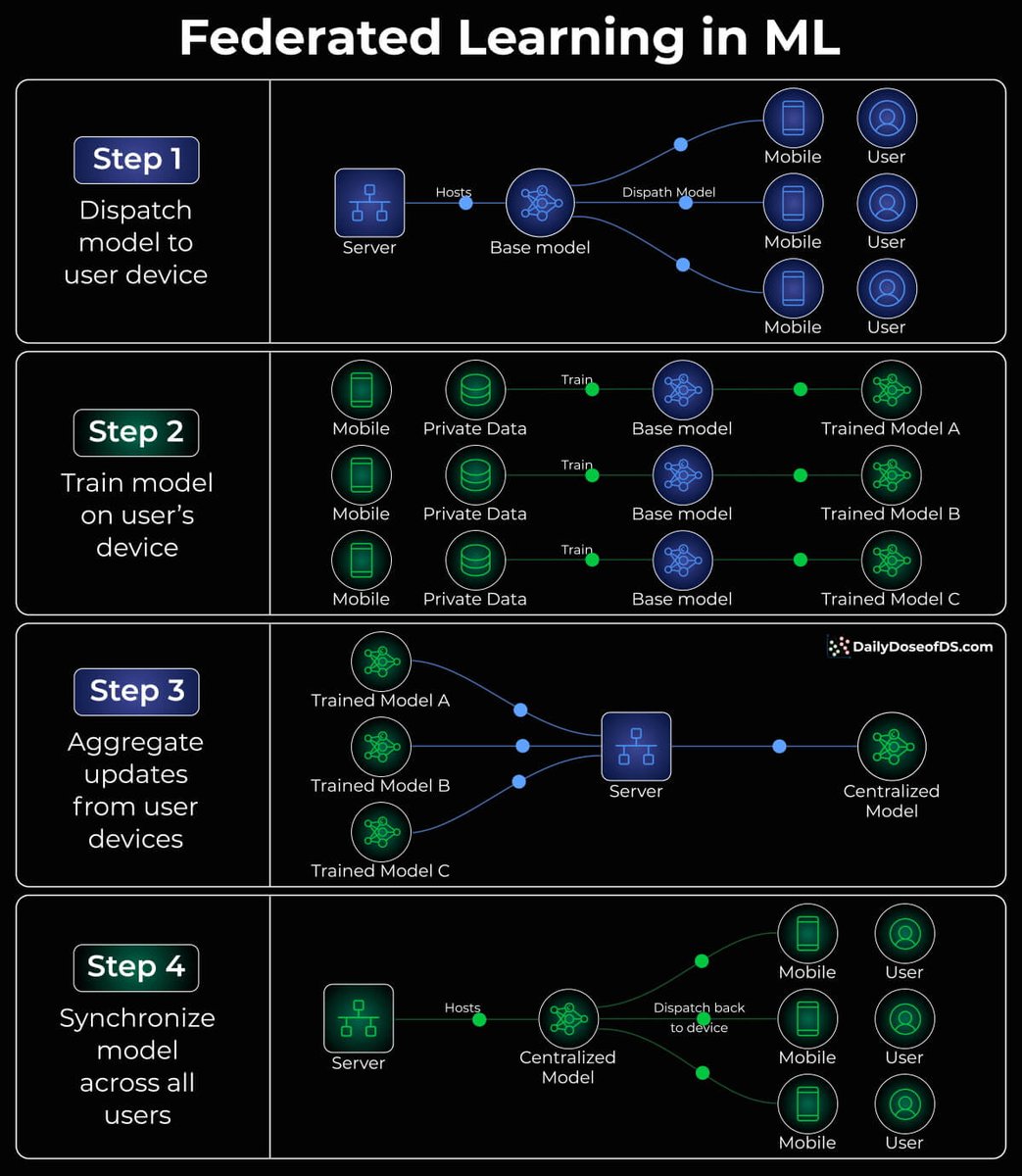
The visual below depicts the core idea:
- Instead of aggregating data on a central server, dispatch a model to an end device.
- Train the model on the user’s private data on their device.
- Fetch the trained model back to the central server.
- Aggregate all models obtained from all end devices to form a complete model.
This setup ensures private data remains exclusively on the user’s device.
Furthermore, federated learning distributes most computation to a user’s device, reducing computation requirements on the server side.
This is how federated learning works!
Of course, this is easier said than done since there are many challenges to federated learning:
- Client devices are constrained with limited RAM, battery-powered, and actively used (so can't hog resources). How do we train within these limits?
- Say we have trained the model somehow. How do we aggregate different models received from the client side to get a central model?
- [IMPORTANT] Privacy-sensitive datasets are always biased with personal likings and beliefs. For instance, in an image-related task:
↳ Some clients may have several pet images.
↳ Some clients may have several car images.
↳ Some clients may love to travel, so most images they have are travel-related.
↳ How do we handle such skewness in client data distribution?
I'll cover the solutions to these challenges in a separate post.
👉 Over to you: What are some other challenges to Federated learning?
____
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
36
68
459
49,941