
Solutions Architect · Senior Python & AI Engineer · AI Audits · Helping teams fix what they shipped too fast
Joined July 2021
- Tweets 5,786
- Following 631
- Followers 493
- Likes 1,334
1,085 Photos and videos
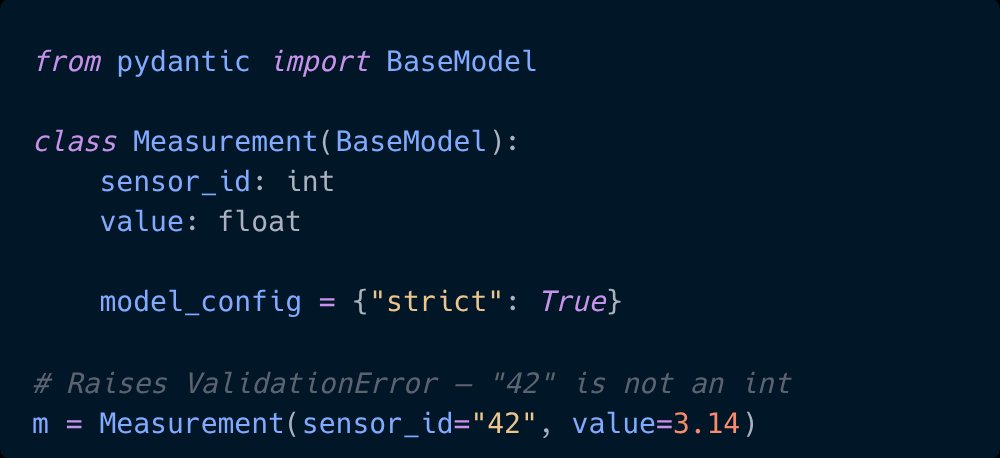

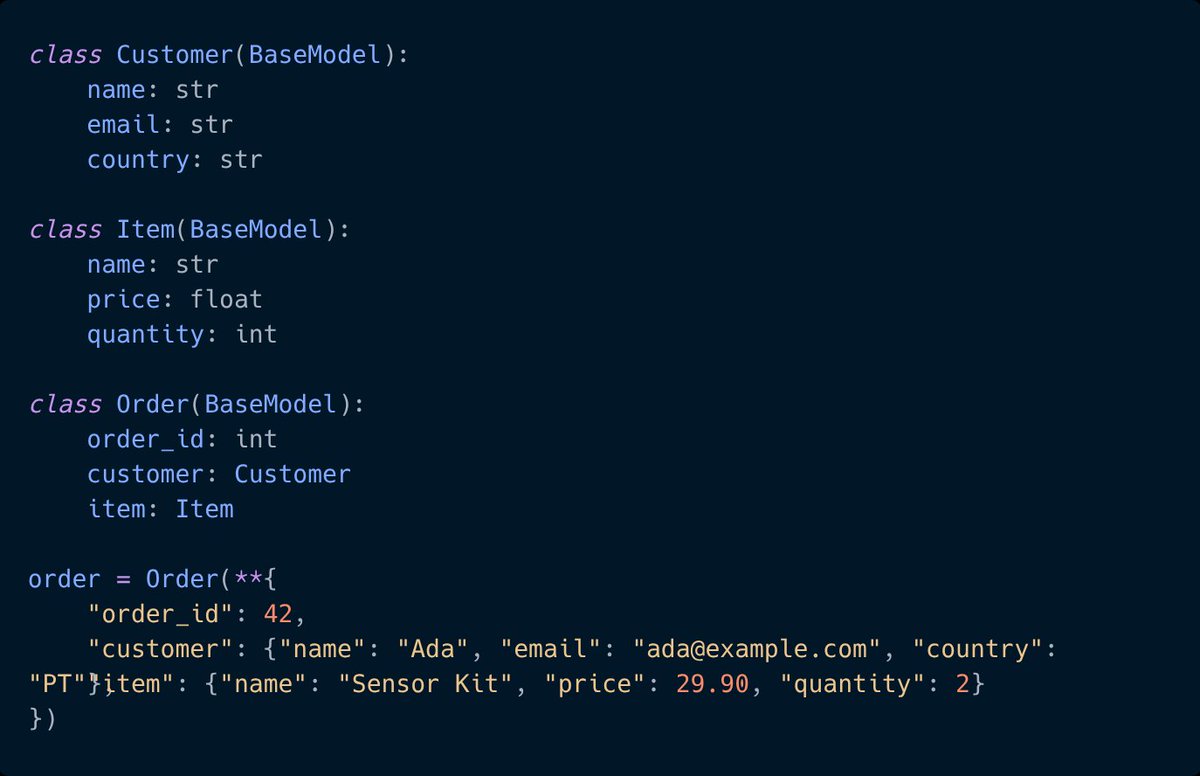

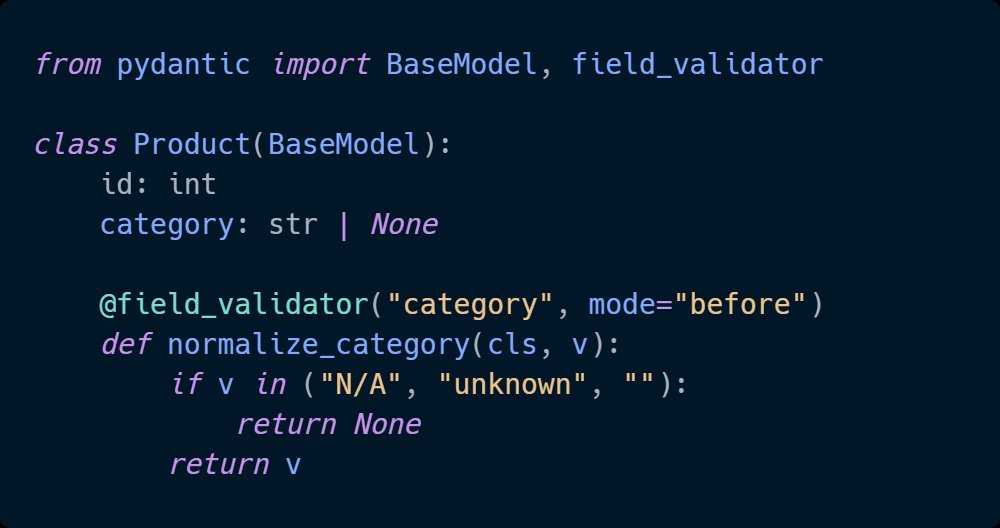
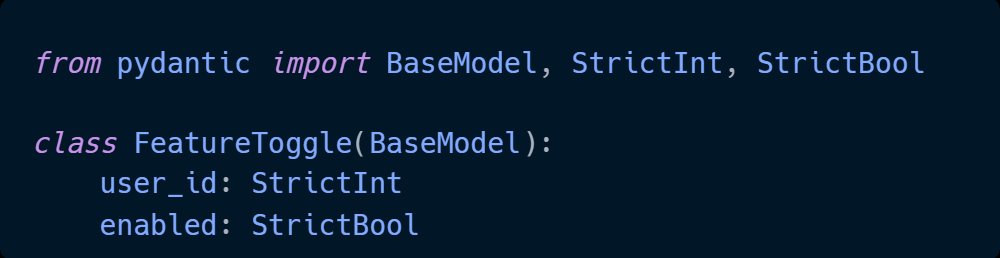





Pinned Tweet

I'm Nuno Bispo, a Senior Software Engineer and Solutions Architect with 15 years building Python systems, AI integrations, and production backends.
I write for Real Python and Unstract. I build and ship hardware. I've seen what breaks in production and what doesn't.
I take on a small number of advisory engagements with teams that are serious about getting their Python and AI stack right.
1
85
Architecture reviews have a translation problem.
Humans can leave a thread of “consider X” and “what about Y” and resolve the rest in a meeting. But if you want an LLM to participate in a workflow that resembles engineering - PRs, ADRs, ticketing, CI gates - fluent feedback isn’t enough. You need output that downstream systems (and humans) can reliably act on.
Most “LLM architecture review” demos stop at persuasive prose. The result reads like an experienced engineer, but it isn’t shaped like an artifact: it’s hard to rank, route, deduplicate, or turn into work without a second manual pass.
Multi-agent helps because architecture review is a bundle of lenses - security, scalability, operability, cost, data integrity, failure recovery - each with its own heuristics and thresholds. But the real differentiator isn’t “one agent vs. many”. It’s contracts. With PydanticAI, you define the schema the system must emit and validate every response; Claude supplies the reasoning, but the contract forces it into a machine-actionable shape.
This article shows how to build a multi-agent architecture reviewer that produces a structured review artifact: normalized findings with severity, evidence, and recommendations, plus clarifying questions and explicit “needs human judgment” flags. Think less chatbot, more review report.
developer-service.blog/why-a…
#Python #AI #Architecture #Claude #AI_Agents
1
1
59
Most AI codebases I review have the same four problems.
Hardcoded secrets. No error handling. No observability. Nobody who understands it six months later.
I now offer formal reviews and advisory retainers for teams who want to fix this before it becomes expensive.
Details → developer-service.blog/work-…
20
Onboarding a new engineer shouldn't require a guided tour of your data layer.
But in most Python codebases, it does.
The shape of the data lives in comments, in tribal knowledge, in a Notion page that was last updated eight months ago. A new hire spends their first two weeks asking questions that shouldn't need to be asked - because the answers aren't in the code.
This is a scaling problem that looks like a people problem. Teams mistake it for poor documentation, or slow onboarding, or engineers who ask too many questions. The real issue is that the system's assumptions are implicit. Nothing enforces them. Nothing surfaces them. They exist only in the heads of the people who built it.
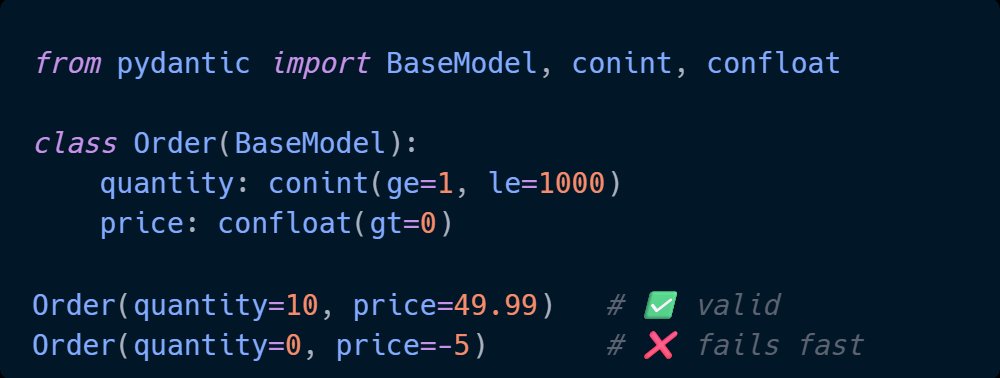
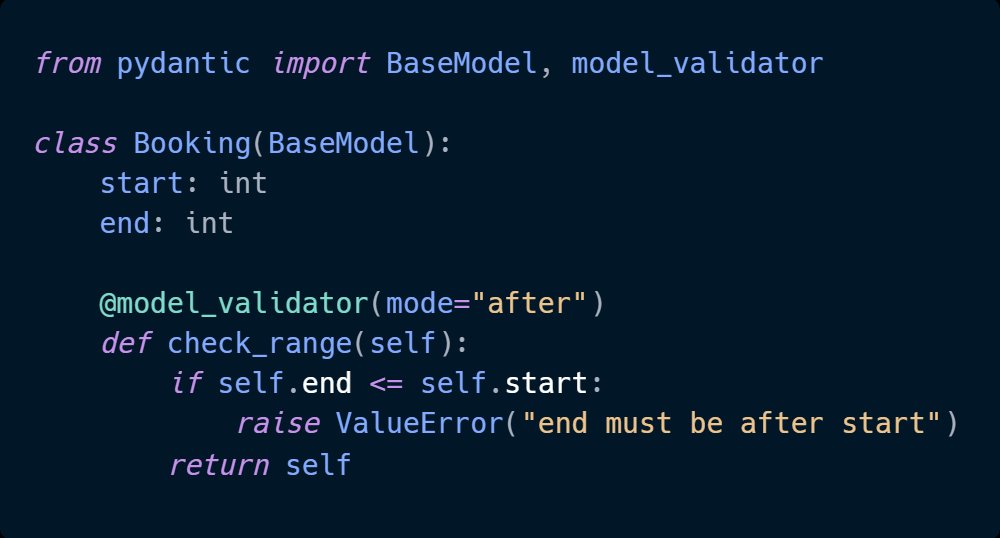
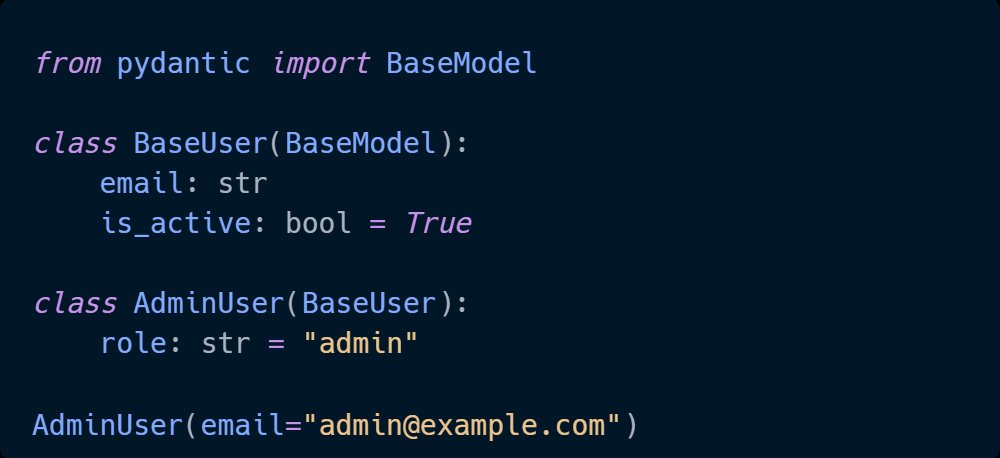
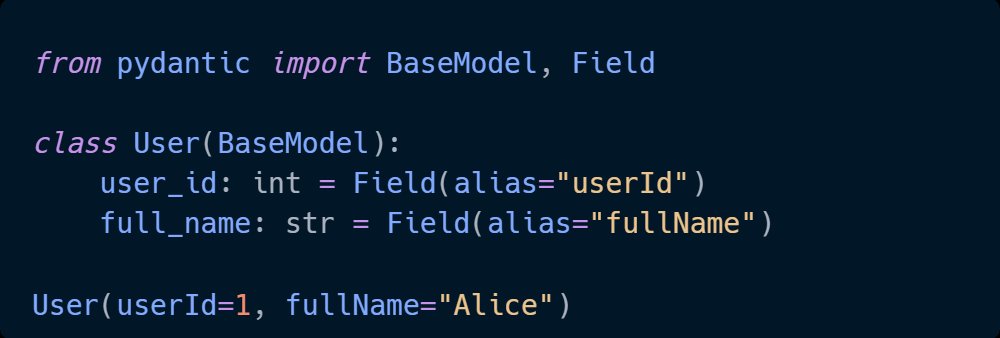
Structured data models change that. When every input, output, and internal data structure is explicitly defined - with types, constraints, and validation - the code becomes the documentation. A new engineer can read a model and know exactly what the system expects and guarantees. No tour required.
This isn't about developer experience as a nice-to-have. It's about how fast your team can move as it grows, and how much institutional knowledge walks out the door every time someone leaves.
The teams that scale well are the ones whose systems can explain themselves.
Practical Pydantic is a practical guide to building Python systems that do exactly that - explicit, self-documenting data models that hold up as the team and codebase grow.
leanpub.com/practical-pydant…
If your data layer needs a guide, it needs better structure.
#EngineeringLeadership #TechStrategy #SoftwareArchitecture #TeamScaling #ProductEngineering
2
1
37
Here's a Python snippet that surprises most developers:
x = 10
def show():
print(x)
def modify():
print(x) # UnboundLocalError
x = 20
show() # prints 10
modify() # crashes
Same variable. Same function structure. Two completely different outcomes.
This isn't a bug. This is Python working exactly as designed.
Once you understand scope, this makes perfect sense. Until you do, it looks like the interpreter is making arbitrary decisions.
The LEGB rule explains everything, how Python decides which variable it's reading, why closures remember values, and when global and nonlocal are the right tool versus a design smell.
I put it all in a free guide:
- The complete LEGB lookup chain with annotated examples
- Closures and late binding demystified
- global and nonlocal, mechanics and when to avoid them
- The scope patterns that produce silent, hard-to-trace bugs
python-variable-scope.develo…
#Python #PythonTips #SoftwareEngineering #CodeQuality
13
One of the patterns I keep coming back to in production Python projects is using dependency injection in FastAPI properly, not just for database sessions and configuration, but for the AI layer too.
Most codebases I see treat the LLM client as a global singleton, instantiated at module level and imported wherever it's needed. It works until it doesn't, and when it breaks it breaks in ways that are genuinely hard to debug.
The better approach is to inject your AI client the same way you'd inject any other external dependency. You define it once, you control its lifecycle explicitly, and every route that needs it receives it through FastAPI's dependency system rather than reaching into global state.
The immediate benefits are obvious: easier testing, cleaner separation of concerns, the ability to swap implementations without touching business logic.
But the less obvious benefit is that it makes your AI integration visible in a way that global imports never are. You can see exactly which endpoints touch the LLM, which ones share a client instance, and where the boundaries are.
This becomes especially important when you start adding things like retry logic, rate limiting, token budget management, and observability around your LLM calls.
All of that infrastructure belongs at the dependency level, not scattered across individual route handlers. Getting the structure right early means adding those concerns later is a small change rather than a refactor that touches half your codebase.
It's one of those things that feels like over-engineering on day one and feels like obvious good sense on day ninety.
#Python #FastAPI #AI #SoftwareEngineering #PydanticAI
1
20
Bad data is one of the most overlooked sources of technical debt.
Engineering teams invest heavily in scalability, security, and observability.
But a surprising number of production issues start with invalid, inconsistent, or unexpected data flowing through systems.
As organizations adopt more APIs, automation, and AI, data validation becomes a business concern - not just a developer task.
The teams that scale successfully don't just build features faster.
They build systems that can safely handle imperfect real-world data.
I've been exploring this topic in Practical Pydantic, a practical read for anyone building reliable Python, API, or data-driven systems.
leanpub.com/practical-pydant…
#SoftwareArchitecture #EngineeringLeadership #Python #DataEngineering #AIEngineering
19
Python dependency management is not a developer problem. It is a team productivity problem that shows up as slow CI, painful on-boarding, and a different tool in every repository.
If you run a Python shop with five to thirty engineers, a measurable slice of your payroll quietly funds work that never ships: waiting on dependency installs, re-explaining local setup to new hires, and arbitrating which package manager each team decided to use this quarter. None of it shows up on a road-map. All of it compounds.
uv is a Python package and project manager that replaces pip, pip-tools, and Poetry with a single, faster workflow.
This article is not a tutorial. It is a business case: what standardizing on uv costs, what it returns, and how to run a one-week pilot without stopping feature work. By the end, you will have a go/no-go framework and a minimal team policy you can paste into your engineering handbook today.
developer-service.blog/uv-fo…
#python #uv #teams
19
Something nobody talks about in the AI hype cycle is that most of the people building AI products right now have never maintained one.
Building is exciting. You're moving fast, the model does impressive things, the demo wows everyone in the room. Maintaining is a different discipline entirely - quieter, less glamorous, and significantly harder when the foundation was laid in a hurry.
We are about twelve to eighteen months away from a very interesting moment in the industry. The products that got shipped fast in 2024 and 2025 are going to start showing their age all at once. Not dramatically. Gradually, then suddenly - a security incident here, a reliability problem there, a codebase that nobody wants to touch because the person who understood it moved on.
I've seen this cycle before. Not with AI, but with every other wave of technology that rewarded speed over substance in the early days. The teams that come out the other side are the ones that treated the post-launch period as seriously as the build.
The ones that didn't have a very bad year instead.
#AI #SoftwareEngineering #TechLeadership #Python #CTO
21
There's a class of Python bugs that never appear in tutorials.
They appear in production.
They're not caused by wrong algorithms or bad data structures. They're caused by a variable resolving to a value the developer didn't intend - because Python's scoping rules weren't fully understood when the code was written.
I've reviewed enough codebases to know this isn't a beginner problem. It's a fundamentals problem. And fundamentals don't expire.
The Python Scope Guide covers the rules that govern how Python resolves every variable name in your code:
- LEGB: Local, Enclosing, Global, Built-in - the complete lookup chain
- How closures work and why late binding surprises even experienced developers
- The role of global and nonlocal and when their presence signals a design smell
- Practical examples drawn from real-world bug patterns
Written for working Python developers. Free to download.
python-variable-scope.develo…
#Python #SoftwareDevelopment #PythonEngineering #CodeQuality
17
Your team has been building an AI feature for six weeks. The demo looks great, the stakeholders are happy, and the pressure to ship is real. So you ship. And for a few weeks everything seems fine - the feature works, users are engaging with it, and the team moves on to the next thing.
Then something quietly breaks. Maybe the LLM starts returning unexpected output that your application handles badly. Maybe a prompt injection vulnerability gets exploited by a user who was just curious. Maybe your API costs suddenly spike because nobody added any guardrails around token usage. You find out not because your system told you, but because someone noticed something wrong and traced it back.
The problem was never the technology. The problem was that shipping and finishing got confused for the same thing. They aren't. Shipping is getting it live. Finishing is making sure it won't embarrass you six months later.
Most AI features that are live in production right now have been shipped but not finished. The teams that built them know it. The CTOs who own them suspect it. And the gap between those two states is exactly where the expensive surprises live.
If that gap is keeping you up at night, it's worth a conversation before it becomes a headline.
#AI #CTO #TechLeadership #SoftwareEngineering #Python
17

Practical Pydantic by Nuno Bispo is on sale on Leanpub! Its suggested price is $39.00; get it for $16.24 with this coupon: leanpub.com/practical-pydant… @DevAsService #fastapi #python #apis #computer_programming
1
1
92
The most expensive line of code in your AI integration isn't the one that's wrong.
It's the one that's wrong and nobody knows it yet.
Most AI systems in production today are built on an implicit assumption that the model will always return something sensible.
No validation, no schema enforcement, no explicit failure handling. Just optimism deployed at scale.
That works fine in development, where you're watching the output and course-correcting manually.
It stops working the moment real users hit edge cases you didn't think to test, at 2am, when nobody is watching.
I'm not against moving fast. But there's a difference between moving fast and building on assumptions you've never written down.
One is a strategy.
The other is a bet.
At some point the bill comes due.
#AI #SoftwareEngineering #Python #TechLeadership
16
Python will never tell you your variable is in the wrong scope.
That's the problem.
Other languages enforce boundaries explicitly. Python trusts you to understand them. And when you don't, the result isn't a crash or a compile error - it's a subtle, hard-to-reproduce bug that only shows up under the right conditions.
Scope is the kind of topic that doesn't feel urgent until it is.
I've spent 15 years working with Python across production systems, open-source projects, and technical tutorials. Scope bugs are a constant. Not because they're exotic - but because the underlying rules are never explicitly taught.
So I documented them.
- The complete LEGB lookup model with real examples
- Closures and late binding - one of Python's most misunderstood behaviours
- global and nonlocal: when they're justified and when they're a warning sign
- The scope patterns that survive code review and still break production
Free. No strings.
python-variable-scope.develo…
#Python #SoftwareEngineering #PythonDevelopment
27
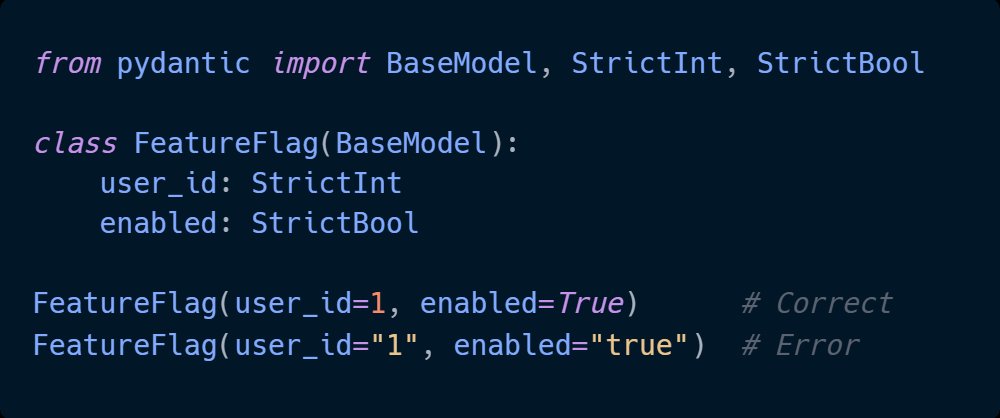
One of the most common mistakes I see in production AI integrations is treating LLM output like a string and hoping for the best.
The model returns something that looks like JSON, you parse it, and everything works fine - until it doesn't. Until the model adds a preamble, wraps the response in markdown, or returns a slightly different structure because your prompt was ambiguous that day.
Then your parser breaks silently, and your application does something unexpected that nobody catches until a user complains.
The root cause is almost always the same. The team that built the integration was focused on making it work, not on making it fail gracefully. Those are two completely different engineering problems, and in the rush to ship, only one of them gets solved.
Structured outputs change this fundamentally. Instead of parsing whatever the model decides to return, you define a strict schema for what you expect and let the SDK enforce it at the boundary.
Invalid responses become explicit errors you can handle, log, and retry - not silent data corruption you discover three sprints later. The integration becomes predictable in a way that raw string parsing never is.
This is one of the first things I look for when reviewing an AI codebase. Not because it's the most exciting problem, but because getting it wrong cascades into everything else - your error handling, your logging, your ability to debug production issues without losing your mind.
#Python #AI #Claude #Pydantic #SoftwareEngineering
1
38
The bug your team keeps fixing is probably not a bug. It's a missing contract.
Service A sends data to Service B. Service B breaks. Someone patches it. Three weeks later, it breaks again - slightly differently. Same root cause, different symptom.
This is one of the most common and least diagnosed sources of engineering slowdown in growing product teams. Not complexity. Not scale. Just two parts of the system that were never formally required to agree on what they were exchanging.
The instinct is to add more tests, more logging, more defensive code. Those help at the edges. They don't fix the underlying problem, which is that there's no single definition of what valid data looks like between these two points - so every change is a potential silent breaking change.
Data contracts solve this. Not as a process, but as code. A shared definition that both sides of the integration validate against, automatically, every time data crosses the boundary.
When something changes - and it always does - the failure is immediate, loud, and localised. Not silent, gradual, and discovered in production two weeks later.
The teams that invest in this early don't have fewer changes. They just spend far less time on the consequences of those changes.
Practical Pydantic is a concise, practical guide to building this kind of structure into Python systems - without slowing down the team that's already shipping.
leanpub.com/practical-pydant…
If the same bug keeps coming back, look for the missing contract.
#EngineeringLeadership #TechStrategy #SoftwareArchitecture #ProductEngineering
11
Your team shipped an AI feature.
It works.
Mostly.
But nobody knows what happens when it doesn't.
No alerts. No logging. No one gets notified when the LLM returns garbage.
No one knows when the API hits its rate limit and silently stops processing.
Your users know before you do.
That's not a technology problem.
That's a visibility problem.
And it's the first thing I find in every AI codebase I review.
The teams that catch this early spend an afternoon fixing it.
The teams that don't spend a week explaining it to stakeholders.
One afternoon or one week.
Your choice.
Wonder what else is hiding in your AI codebase?
#AI #SoftwareEngineering #Python
2
2
40
Code reviews reveal a lot about a developer's understanding of Python.
One of the most common gaps I see - and across all experience levels - is scope.
Not because developers are careless. But because Python's name resolution rules are implicit. The language never forces you to learn them. You can write Python for years and still carry blind spots that surface only under specific conditions.
Until they surface in production.
I put together a free guide specifically for developers who want to eliminate that blind spot:
- The LEGB rule explained with precision, not hand-waving
- How Python handles name resolution in nested functions and closures
- The global and nonlocal keywords - mechanics, use cases, and red flags
- Scope antipatterns that pass code review and cause bugs anyway
Solid foundations make better engineers. This is one of them.
python-variable-scope.develo…
#Python #CodeReview #SoftwareEngineering #PythonDevelopment
21
Your Python script finished.
Or did it crash?
You won't know until you check the logs.
Or until something downstream breaks.
There's a better way.
ntfy.sh sends a push notification to your phone with a single HTTP call from any Python script.
No account. No SDK. Just this:
import requests
requests.post(
"ntfy.sh/your-topic",
data="Backup completed successfully",
)
I use it for:
- AI pipeline completions and failures
- Django cron job alerts
- ESP32 sensor threshold breaches
- Long-running script monitoring
Five minutes to set up.
Zero excuses for silent failures in production.
#Python #DevOps #AI #MicroPython #SoftwareEngineering
17
Your AI feature shipped. Your validation layer didn't.
It's a common pattern. The team moves fast to get an LLM integration out the door. The model works. The demo looks great. The pipeline goes live.
What doesn't ship is the layer that checks whether the AI's output is actually usable before it touches the rest of your system.
The assumption is that the model is reliable enough. And it usually is, until it isn't. A response in an unexpected format. A missing field the downstream service didn't anticipate. A confidence score that should have triggered a fallback but didn't, because nothing was checking.
These aren't model failures. They're integration failures. And they're expensive in a specific way: they're silent. The system doesn't crash. It just produces wrong results, quietly, until someone notices.
The fix isn't complicated. It's a validation layer between your AI output and the rest of your application, one that defines what a valid response looks like, rejects or flags anything that doesn't match, and gives your team a single place to update when the model's behaviour changes.
Teams that build this layer before they need it spend less time firefighting and more time iterating. Teams that skip it tend to rebuild it later, under pressure, after something has already gone wrong.
That's the real cost of skipping validation in AI pipelines. Not the failure itself, the timing of when you fix it.
Practical Pydantic covers how to build this layer in Python, including patterns specific to LLM output validation and structured AI responses.
leanpub.com/practical-pydant…
Ship the AI feature. Ship the validation layer with it.
#EngineeringLeadership #TechStrategy #SoftwareArchitecture #AIEngineering #ProductEngineering
1
25