
Joined November 2021
- Tweets 272
- Following 102
- Followers 4
- Likes 234
2 Photos and videos


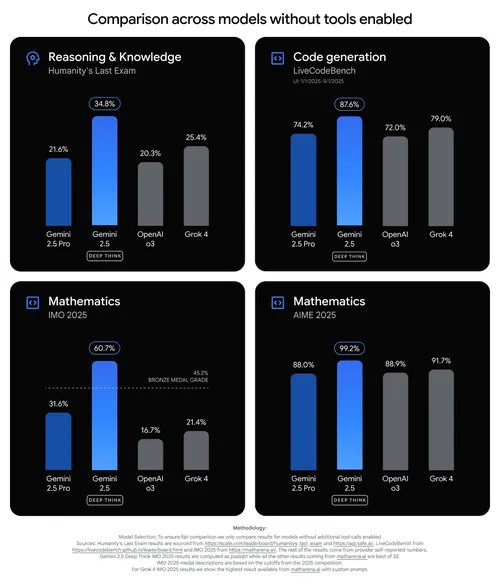
Starting today, we're offering Deep Think in the Gemini app for Google AI Ultra subscribers, and we're giving a collection of mathematicians access to the full version of the Gemini 2.5 Deep Think model that achieved gold medal🏅 level performance in the recent IMO competition. This model excels at complex math, reasoning and coding.
See more at: blog.google/products/gemini/…
43
118
1,013
89,626
vladimirb retweeted

27 Jul 2025
What are humans going to do when AI is doing everything for us? Are you serious?
Dude I’m going to be cycling every day, living in the middle of nowhere, making banger music, running some fun-ass shop that people are going to come hang out at. We can all be fit AF. Even Elon is going to be like 95 and yoked out of his mind.
AI can create art and music and build things etc, but it can’t feel things. Humans will have so much time to feel things again without all the survival bullshit we’ve gotta deal with all the time.
Through all of history humans have figured it out. We’ll figure it out. Seems like it’ll be fucking epic
56
18
333
15,733
vladimirb retweeted

7 Feb 2025
Worst thing to do when you're full of agency is to wake up and browse Twitter
114
435
7,781
255,341

Grok can now analyze posts on 𝕏.
Update your app & tap on the slash icon.
x.com/i/grok/share/L4UCu3cCU…
2,603
2,232
16,980
8,002,742
vladimirb retweeted

30 Nov 2024
If you liked this post, let me know & subscribe. I will continue to post the most interesting & relevant new papers in the longevity field 🧬🙏✌️
x.com/davidasinclair/status/…
30 Nov 2024

A new review is out on the pre-clinical & clinical trials of nicotinamide mononucleotide (NMN) and nicotinamide riboside (NR)
First, some background on these molecules...🧵
iadns.onlinelibrary.wiley.co…

17
13
226
41,657
vladimirb retweeted

25 Nov 2024
⚡️⚡️ CrewAI v0.83.0 is out! ⚡️⚡️ A big one again!
🙏 RT please?
↪️ before_kickoff and after_kickoff crew callbacks
🌱 Support to pre-seed Crews with Knowledge
⌨️Improving IBM integration
🧠 @mem0ai Integration
📃Update Docs
🐞 Bug fixes
And more!
11
56
167
17,181
vladimirb retweeted

17 Sep 2024
We have received Breakthrough Device Designation from the FDA for Blindsight.
Join us in our quest to bring back sight to those who have lost it. Apply to our Patient Registry and openings on our career page neuralink.com/
3,261
5,797
32,470
59,570,045
vladimirb retweeted

16 Sep 2024
🧬Maximum mammalian lifespan is inversely related to rate of change in methylation at specific DNA regions (bivalent regulatory regions): ROC= 1/maximum lifespan. Several beautiful equations link age-related methylation changes to maximum lifespan. Methylation data bring a dream of many physicists to life: mathematical modeling in aging biology. We previously found only a weak overlap between methylation changes associated with maximum lifespan and those linked to chronological age because species lifespan is genetically fixed and doesn’t vary with age. The final part of our trilogy on mammalian lifespan addresses this counterintuitive result. It took five years to publish because we found that studies linking the rate of change in aging biomarkers to lifespan are inherently biased. Strong negative correlation between the rate of change and lifespan can occur even without any signal! We developed a framework to highlight this bias and collected data from 348 mammalian species.
Zhe Fei (2024) Fundamental equations linking methylation dynamics to maximum lifespan in mammals. nature.com/articles/s41467-0…
@agingbiomarkers #Aging #Methylation #Lifespan #EpigeneticClocks
8
70
277
22,086
vladimirb retweeted
11 Aug 2024
🚀🔥 crewAI 0.51.0 is out 🔥🚀
🧪crewAI Testing / Evaluation
🪟Sliding context window
📄Allowing all attributes on YAML
👯Pipeline Feature to hook multi crews together
⚒️Vision, DALL-E, MySQL and NL2SQL Tools
🪲Bug Fixes and More!
RT please🙏
28
82
314
40,298
vladimirb retweeted
6 Jul 2024
🔥🔥 crewAI v 0.36.0 is out 🔥🔥
RT please?
🔚 Force tool results as final agent result
🥷 Adding @AgentOpsAI native support
🔥 Adding @firecrawl Tools
🧑💻 Improving coding Interpreter tool
➰ Option to create your own converter (docs pending)
📃 Updated Docs
🐛 Bug fixes
12
67
248
25,572
vladimirb retweeted
2 Jul 2024
🔥 CrewAI minor release is out! v0.35.7 🔥
⚡ New @composio integration is out (more tools!!!)
📄 Documentation update
🤖 Custom GPT Updated
🕴️ Adjusting manager verbosity level
🐛 Bug fixes
🙏 RT please? :D We keep on 🚢 ing
7
37
146
7,124
vladimirb retweeted

9 Jun 2024
@aelluswamy summarized the past decade very well.
When I hopped in my friend’s model S in 2015, it hit me in a weird way: that car was running software all around, had a nice big touch screen (finally, an actual “screen”), was receiving frequent feature updates over the air, and came with a mobile app for essential remote controls. How could a big car company build something like this? Didn’t make sense back then (and still today for many).
My interview with the Autopilot team early 2016 was very different than most interviews I’d ever taken. We first had a technical discussion on something I had built before, with several engineers and the executive in charge of the group at the time. An actual white board chat where we were all bouncing ideas on the matter together. The only places I’d ever seen the face of anyone above, at best, a team lead during interviews was at some small startups.
Every 1:1 interview that followed was similarly practical. Real coding situations you’d encounter as an engineer, not useless LeetCode trick questions typically found in other big companies’ interviews. When we got done, the recruiter walked me through the office. Everyone was sitting literally next to each other: autopilot software, hardware, vehicle firmware, and many other teams interacting live without friction. Eventually, we walked past @elonmusk's desk and he was sitting right there, next to the engineering teams. Not in any separate ivory tower.
One week in the job, and I was already in a team meeting with him brainstorming Autopilot technical challenges, exactly how it went during my interview. And that went on almost every single week, for the 8 years that followed.
It soon became pretty clear that Elon was directly behind that culture of pragmatic innovation, percolating through all aspects of the company.
Week after week, I’ve witnessed that relentless drive to build features that make people’s lives better and safer, removing roadblocks and unnecessary layers one after another, systematically drilling down to the fundamental “why” - all of this while sleeping at the factory during Model 3 production hell, designing new vehicles, working on BOM reductions, and launching new factories across the globe. During that entire time, through all these chapters, news headlines and other difficult company-wide moments, and while landing rockets on drone ships in the ocean, Elon was still sitting with us in a room every week, often more, with the only objective of building things that will change humanity for the better.
When he announced Tesla would soon start a humanoid robotics program to fuel a future of abundance at AI Day 2021, many once again laughed and doubted. Two years into the program, and Tesla is actively testing early versions of what could well be the first full-fledged humanoid robots equipped with articulated hands autonomously conducting real tasks in a real factory via an end-to-end neural net, running entirely on the bot’s compute hardware. And again, using 2D cameras only.
Whether at Tesla or not, I’d say the same: without Elon, none of any of these amazing things would have ever happened. I can only imagine what a lesser future we’d be living without his involvement and dedication.
If you own Tesla shares, please find 5 minutes to vote.

345
1,398
8,429
22,317,852
vladimirb retweeted

7 Jun 2024
Google presents Open-Endedness is Essential for Artificial Superhuman Intelligence
- Argues that the ingredients are now in place to achieve openendedness in AI systems
- Claims that such open-endedness is an essential property of any ASI
arxiv.org/abs/2406.04268

17
125
535
89,488
How to vote your Tesla shares

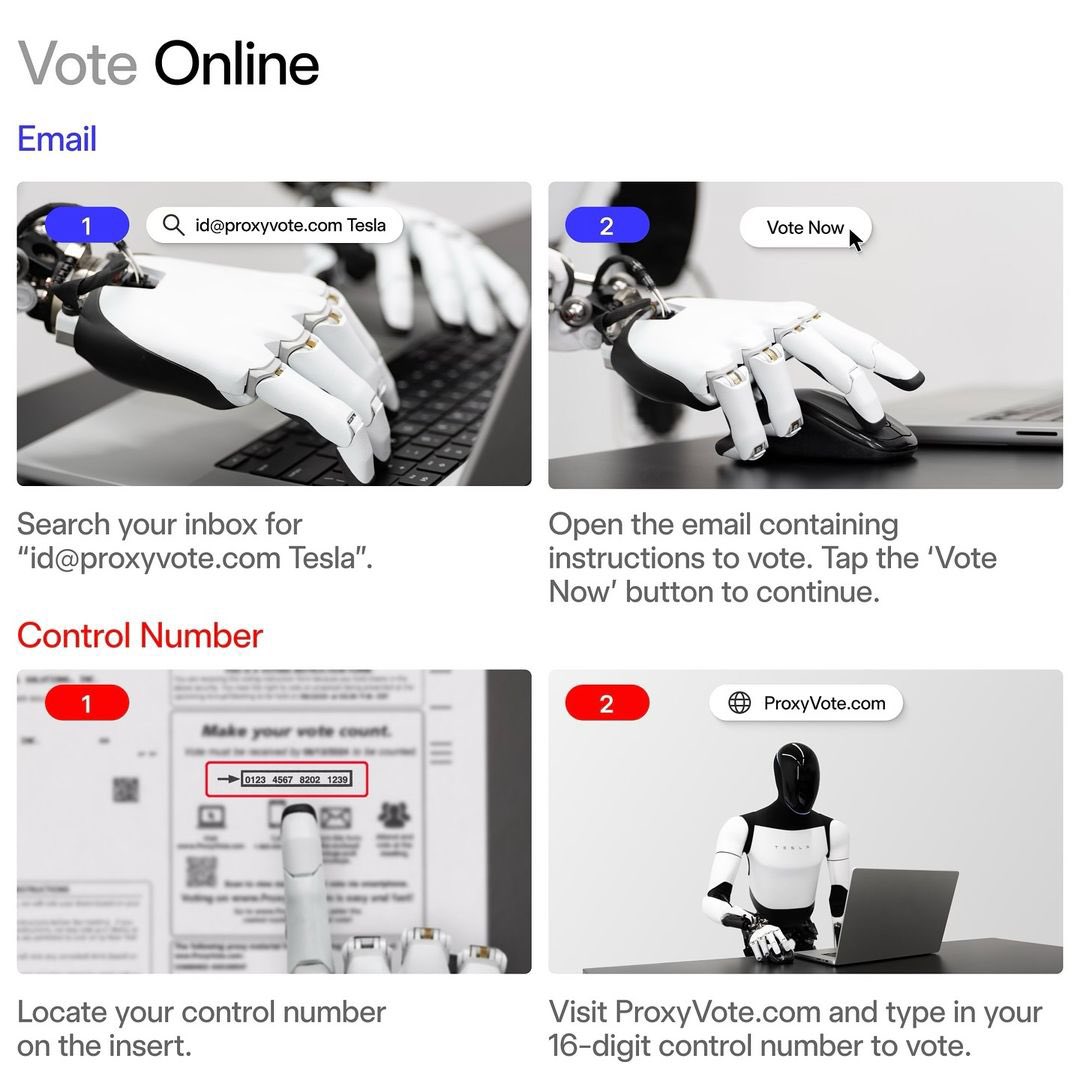
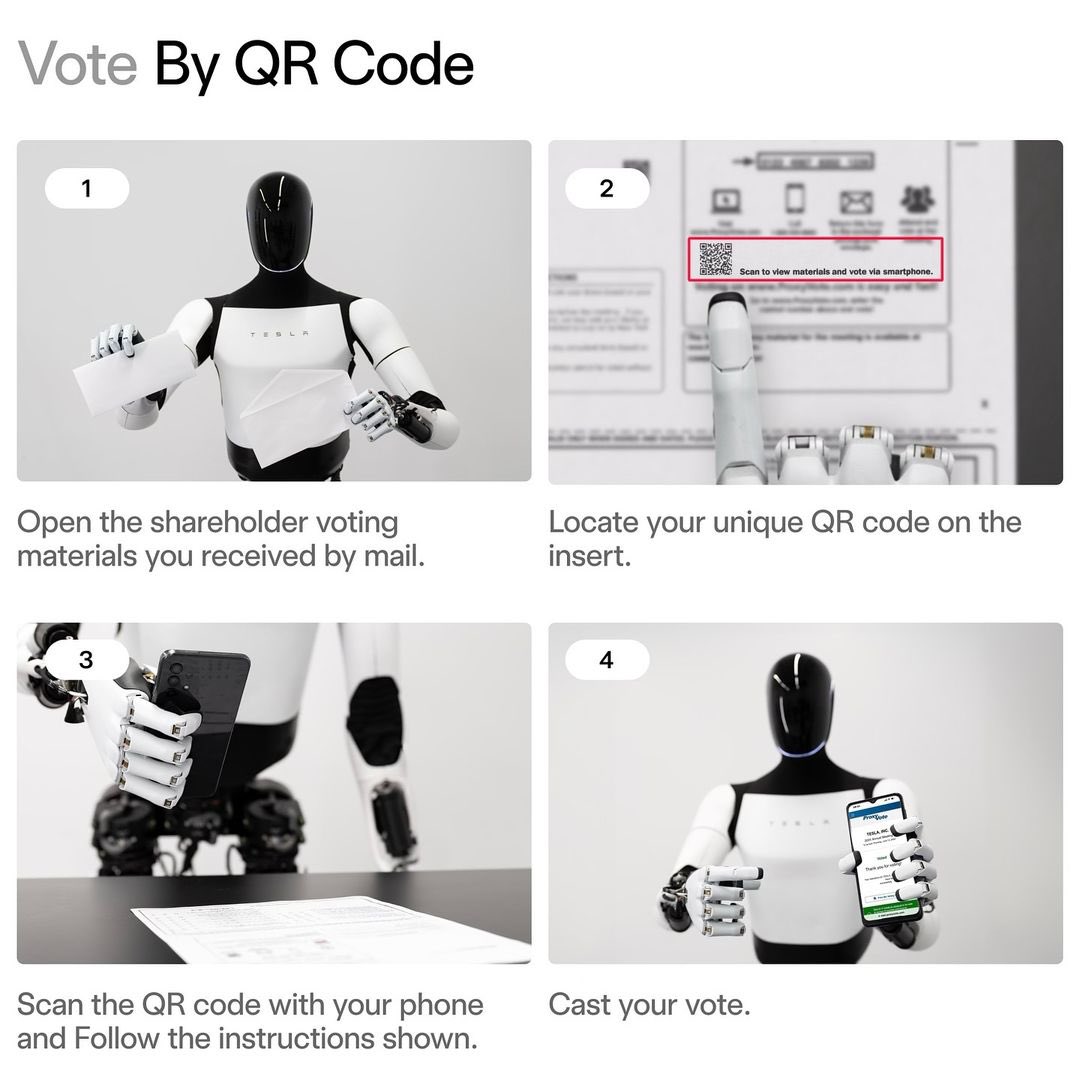
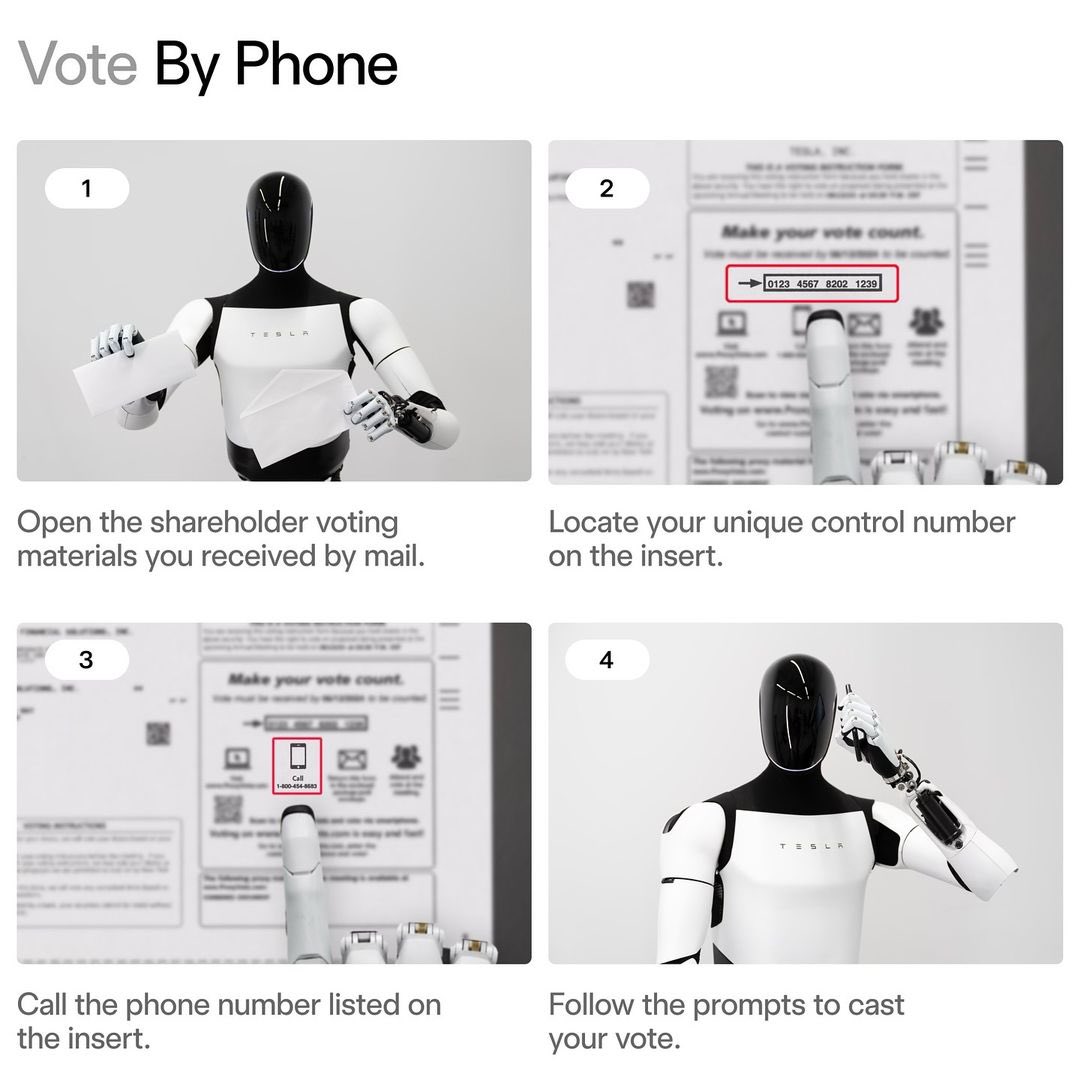
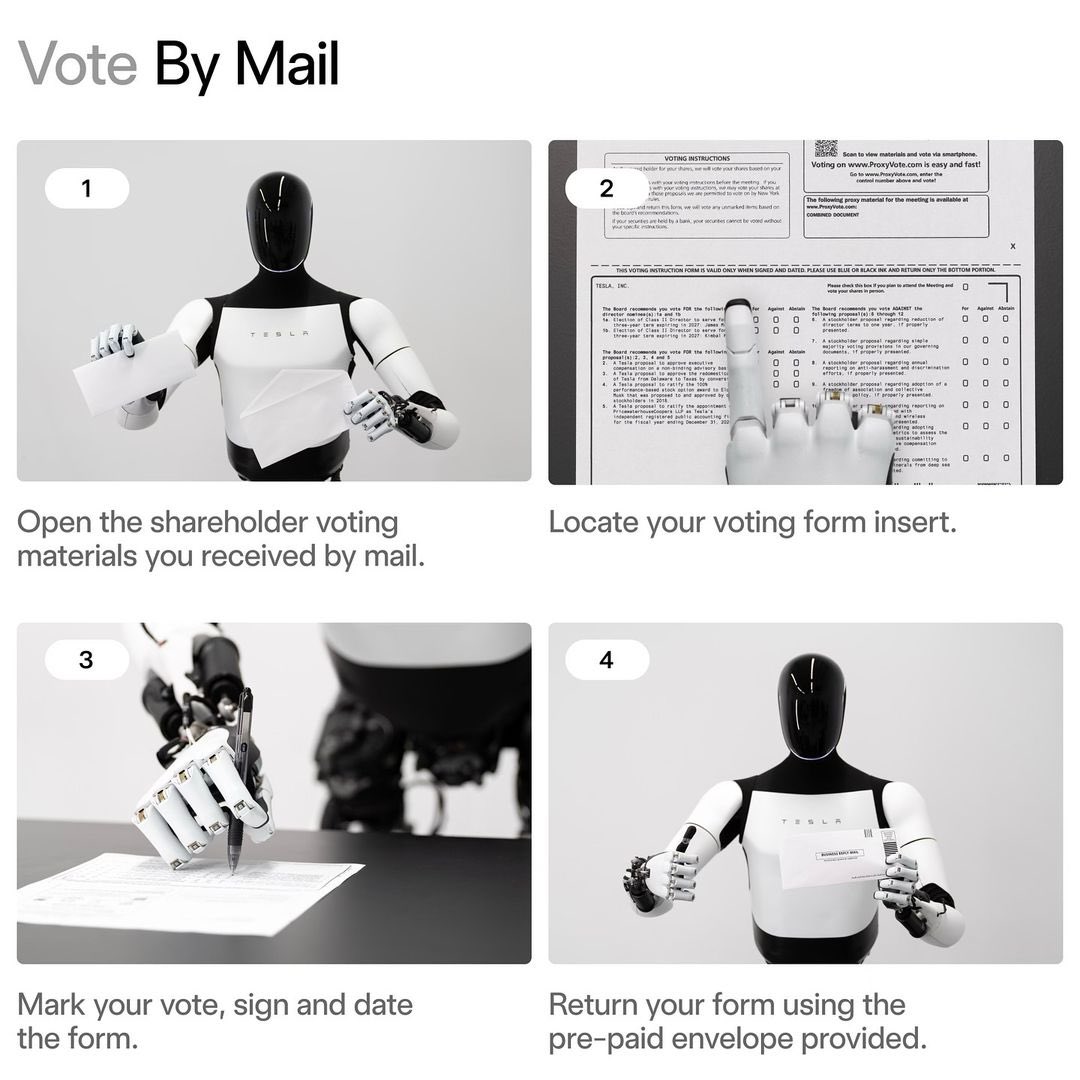
1,828
2,062
19,953
15,096,375
vladimirb retweeted

16 May 2024
⚠️⚠️HUGE price reduction ⚠️⚠️
check our website for more details!

2
10
595
vladimirb retweeted

2 May 2024
Inexpensive token generation and agentic workflows for large language models (LLMs) open up intriguing new possibilities for training LLMs on synthetic data. Pretraining an LLM on its own directly generated responses to prompts doesn't help. But if an agentic workflow implemented with the LLM results in higher quality output than the LLM can generate directly, then training on that output becomes potentially useful.
Just as humans can learn from their own thinking, perhaps LLMs can, too. For example, imagine a math student who is learning to write mathematical proofs. By solving a few problems — even without external input — they can reflect on what does and doesn’t work and, through practice, learn how to more quickly generate good proofs.
Broadly, LLM training involves (i) pretraining (learning from unlabeled text data to predict the next word) followed by (ii) instruction fine-tuning (learning to follow instructions) and (iii) RLHF/DPO tuning to align the LLM’s output to human values. Step (i) requires many orders of magnitude more data than the other steps. For example, Llama 3 was pretrained on over 15 trillion tokens, and LLM developers are still hungry for more data. Where can we get more text to train on?
Many developers train smaller models directly on the output of larger models, so a smaller model learns to mimic a larger model’s behavior on a particular task. However, an LLM can’t learn much by training on data it generated directly, just like a supervised learning algorithm can’t learn from trying to predict labels it generated by itself. Indeed, training a model repeatedly on the output of an earlier version of itself can result in model collapse.
However, an LLM wrapped in an agentic workflow may produce higher-quality output than it can generate directly. In this case, the LLM’s higher-quality output might be useful as pretraining data for the LLM itself.
Efforts like these have precedents:
- When using reinforcement learning to play a game like chess, a model might learn a function that evaluates board positions. If we apply game tree search along with a low-accuracy evaluation function, the model can come up with more accurate evaluations. Then we can train that evaluation function to mimic these more accurate values.
- In the alignment step, Anthropic’s constitutional AI method uses RLAIF (RL from AI Feedback) to judge the quality of LLM outputs, substituting feedback generated by an AI model for human feedback.
A significant barrier to using LLMs prompted via agentic workflows to produce their own training data is the cost of generating tokens. Say we want to generate 1 trillion tokens to extend a pre-existing training dataset. Currently, at publicly announced prices, generating 1 trillion tokens using GPT-4-turbo ($30 per million output tokens), Claude 3 Opus ($75), Gemini 1.5 Pro ($21), and Llama-3-70B on Groq ($0.79) would cost, respectively, $30M, $75M, $21M and $790K. Of course, an agentic workflow that uses a design pattern like Reflection would require generating more than one token per token that we would use as training data. But budgets for training cutting-edge LLMs easily surpass $100M, so spending a few million dollars more for data to boost performance is quite feasible.
That’s why I believe agentic workflows will open up intriguing new opportunities for high-quality synthetic data generation.
[Original text: deeplearning.ai/the-batch/is… ]
34
231
1,247
204,126
vladimirb retweeted

23 Apr 2024
Working with a small team on investigating more benchmarks/prompt-scaffolding our way to SOTA. Can support on Patreon patreon.com/AIExplained/memb… or just sign up to my free newsletter if you like hype-free AI updates. signaltonoise.beehiiv.com/
1
22
2,694
vladimirb retweeted
23 Apr 2024
Billions of dollars are being spent to get models to beat benchmarks that are hilariously bad. A story in 7 parts.
MMLU Numerology. This benchmark is the flagship one in ML, used to grade Llama 3, GPT-4, Phi-3 (released today) and pretty much every model in between.
But try these real, quoted-in-full, questions yourself:
Q. The complexity of the theory.,?
"1,2,3,4","1,3,4","1,2,3","1,2,4",
Q. Demand reduction.,?
"1,3,4","2,3,4","1,2,3","1,2,4",
Q. Predatory pricing.,?
"1,2,4","1,2,3,4","1,2","1,4",
Q. Cultural homogenization.,?
"1,3,4","1,2,3","1,2,3,4","2,3,4",
Dozens more like this (from just my own browsing) with the numbered options containing none of the source information.
Answers C, D, D, B (lol)
1/8
8
15
89
5,318
vladimirb retweeted
21 Mar 2024
I think AI agentic workflows will drive massive AI progress this year — perhaps even more than the next generation of foundation models. This is an important trend, and I urge everyone who works in AI to pay attention to it.
Today, we mostly use LLMs in zero-shot mode, prompting a model to generate final output token by token without revising its work. This is akin to asking someone to compose an essay from start to finish, typing straight through with no backspacing allowed, and expecting a high-quality result. Despite the difficulty, LLMs do amazingly well at this task!
With an agentic workflow, however, we can ask the LLM to iterate over a document many times. For example, it might take a sequence of steps such as:
- Plan an outline.
- Decide what, if any, web searches are needed to gather more information.
- Write a first draft.
- Read over the first draft to spot unjustified arguments or extraneous information.
- Revise the draft taking into account any weaknesses spotted.
- And so on.
This iterative process is critical for most human writers to write good text. With AI, such an iterative workflow yields much better results than writing in a single pass.
Devin’s splashy demo recently received a lot of social media buzz. My team has been closely following the evolution of AI that writes code. We analyzed results from a number of research teams, focusing on an algorithm’s ability to do well on the widely used HumanEval coding benchmark. You can see our findings in the diagram below.
GPT-3.5 (zero shot) was 48.1% correct. GPT-4 (zero shot) does better at 67.0%. However, the improvement from GPT-3.5 to GPT-4 is dwarfed by incorporating an iterative agent workflow. Indeed, wrapped in an agent loop, GPT-3.5 achieves up to 95.1%.
Open source agent tools and the academic literature on agents are proliferating, making this an exciting time but also a confusing one. To help put this work into perspective, I’d like to share a framework for categorizing design patterns for building agents. My team AI Fund is successfully using these patterns in many applications, and I hope you find them useful.
- Reflection: The LLM examines its own work to come up with ways to improve it.
- Tool use: The LLM is given tools such as web search, code execution, or any other function to help it gather information, take action, or process data.
- Planning: The LLM comes up with, and executes, a multistep plan to achieve a goal (for example, writing an outline for an essay, then doing online research, then writing a draft, and so on).
- Multi-agent collaboration: More than one AI agent work together, splitting up tasks and discussing and debating ideas, to come up with better solutions than a single agent would.
I’ll elaborate on these design patterns and offer suggested readings for each next week.
[Original text: deeplearning.ai/the-batch/is…]

196
1,216
5,178
838,439
vladimirb retweeted

21 Mar 2024
1. Before AI, the hardest part about building a startup was finding a problem worth solving and getting people to actually care about your solution. Now there are exciting AI demos solving huge problems everywhere you look, but very few startups have achieved lasting adoption...
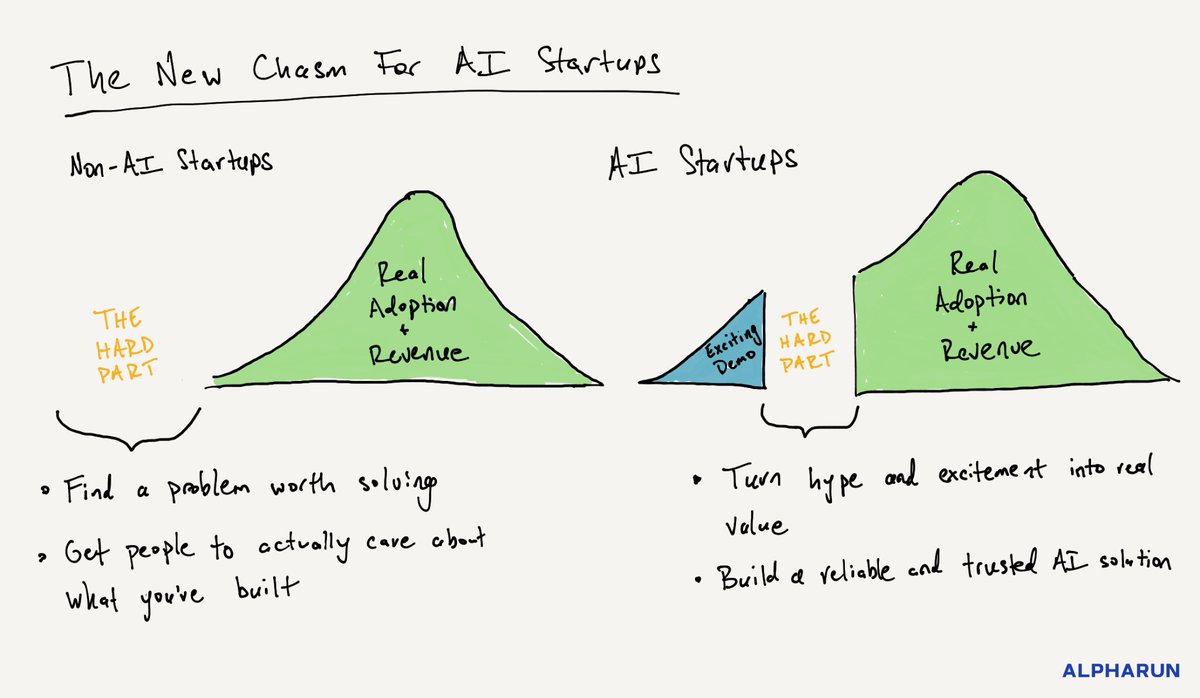
2
3
36
3,989