
Joined August 2025
- Tweets 28
- Following 43
- Followers 32
- Likes 61
3 Photos and videos


May 6
Introducing the Lab from the Future!
May 6

What can a dexterous robot do in your wet lab?
Announcing AINORO’s partnership with LabOS @AI4S_Catalyst.
Together, we are exploring a workflow where AI can reason, build protocols, and execute experiments through AINORO’s dexterous robots.
From idea → protocol → robotic execution.
Demo below 👇
@ainoro_labs @AI4S_Catalyst
1
108
Xi Wang retweeted

May 6
20 years ago, lab automation meant: load the plates, press start, walk away.
In 2026, AINORO is bringing that simplicity to the entire wet lab.
Our affordable dexterous robot uses existing instruments, adapts to current lab environments, and helps automate workflows without rebuilding the lab.
The future lab will have robots working side by side with scientists — and with each other.
Introducing AINORO.
Meet us at ainoro-labs.com
22
51
277
11,256
May 1
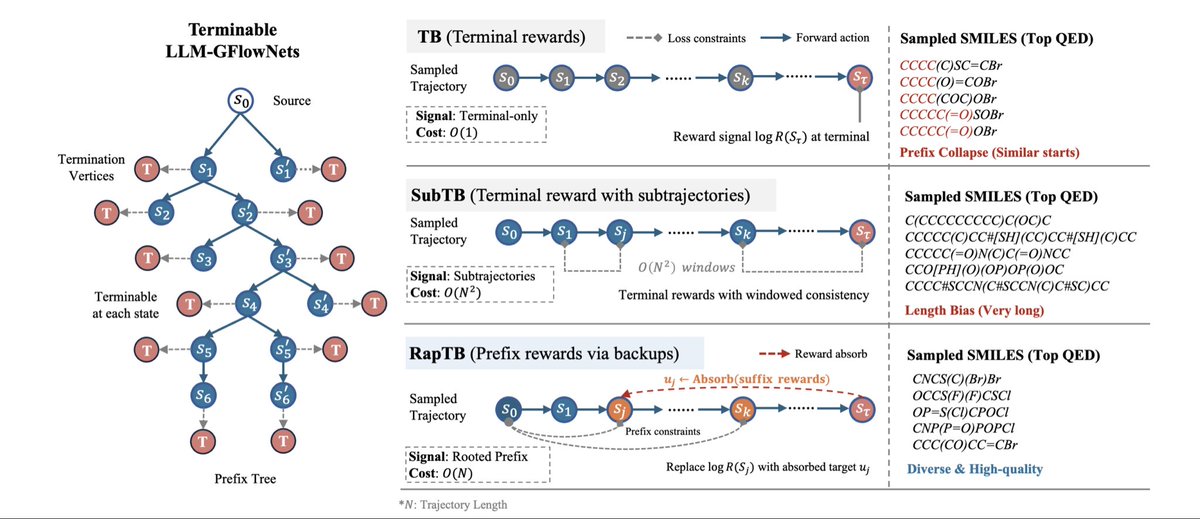
Introducing RapTB ICML2026🎉
Most RL post-training methods are fundamentally mode-seeking: they optimize expected return. In sparse or binary-reward settings, methods like PPO/GRPO can easily collapse to a few high-reward modes, losing solution diversity.
Our work brings GFlowNets to LLM post-training.
Instead of training the model to find one maximum-reward trajectory, we train it to sample solutions with probability proportional to reward. This encourages broad exploration of the solution space, enabling the model to generate samples that are both diverse and high-reward.
Two key contributions:
1. Rooted-prefix training
Improves credit assignment and reduces trajectory-level variance.
2. Submodular replay selection
Lets the model automatically select replay samples that jointly balance diversity, reward, and length, reducing the risk of getting trapped in local modes.
We evaluate on tasks where diversity matters: molecule generation, AMP design, Game of 24 expression synthesis with binary rewards, and natural-language tasks.
Compared with PPO/GRPO and GFlowNet baselines such as TB/SubTB, we observe substantial improvements.
1
2
90
May 1
Robots are moving into wet-labs! Free scientists from laborious and tedious works.

The next generation of biology companies will run 24/7.
AI Scientists never sleep.
More soon. @ainoro_labs
2
62
Xi Wang retweeted

Apr 17
Explore here → labworld-labos.github.io
Great job @Charles_Y_Wu @EscheFlex @wenbolu @JinglinJian @LingYang_PU 👏👏👏
Under the mentorship of
@lecong
@MengdiWang10
@auto_bio_ai
@AI4S_Catalyst
@Stanford
@Princeton

3
5
1,020
Apr 1
We are trying to break the wall between physical and virtual world, accelerating science research!

🔥 AI just got its own infinite laboratory.
Introducing LabWorld — the leap for AI-powered science.
LabOS just turned real biomedical protocols into fully executable, high-fidelity digital simulations.
This changes everything for AI scientists. 🧬⚡
4
8
1,103
Xi Wang retweeted

🔥 AI just got its own infinite laboratory.
Introducing LabWorld — the leap for AI-powered science.
LabOS just turned real biomedical protocols into fully executable, high-fidelity digital simulations.
This changes everything for AI scientists. 🧬⚡
12
47
328
49,298
Xi Wang retweeted
Mar 29
The best claw competition for AI for Science!
Mar 29
Come and win $50,000 🔥🔥🔥🔥🔥🔥
3
5
723
Feb 19
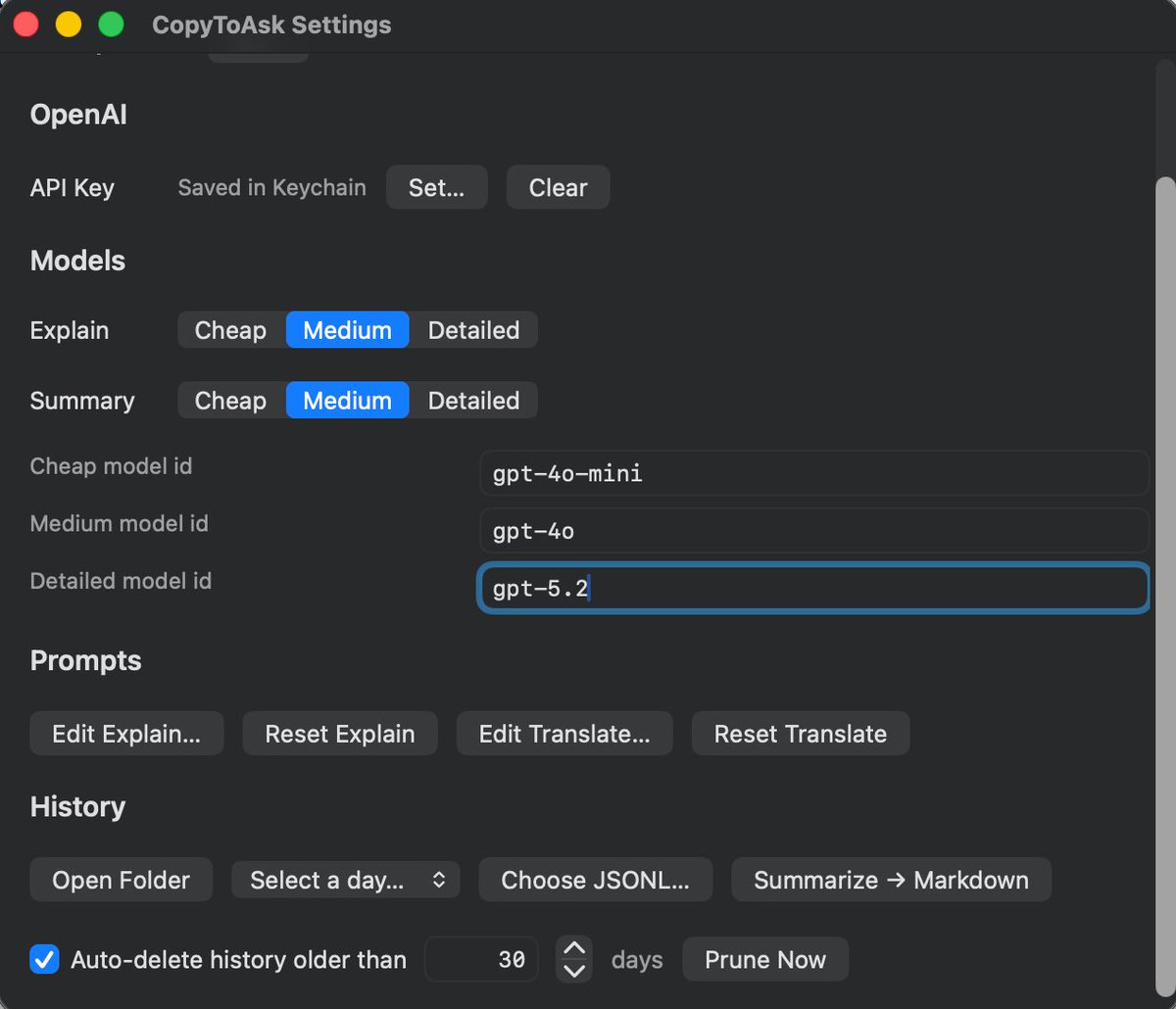
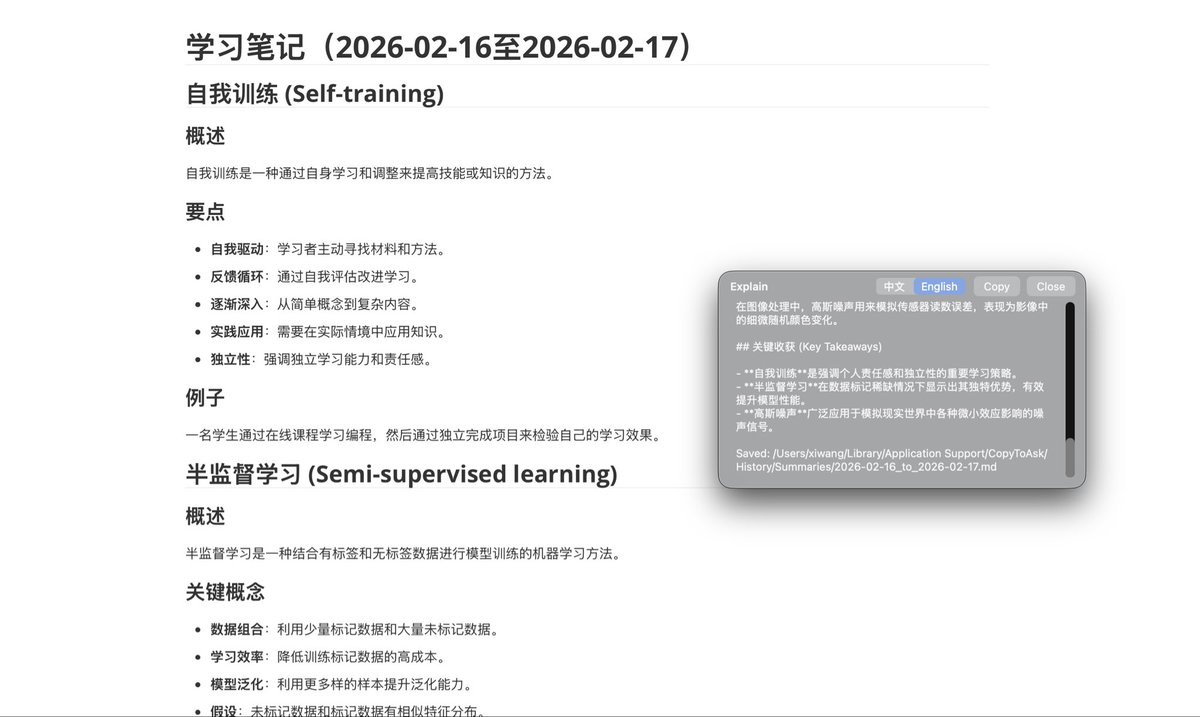
CopyToAsk is a tiny macOS menu bar app that turns any highlighted text into instant understanding.
Select text in any app → hit a hotkey → get:
•Explain panel anchored near your selection
•Ask mode for follow‑up Q&A (streaming)
•Context stacking across multiple selections
•“Translate To” with 8 languages
•Local history one‑click Markdown summaries
•English/中文 UI
Open-source. Built with pure AppKit a simple swiftc build script.
GitHub: github.com/ComDec/CopyToAsk
2
1
54
Jan 29
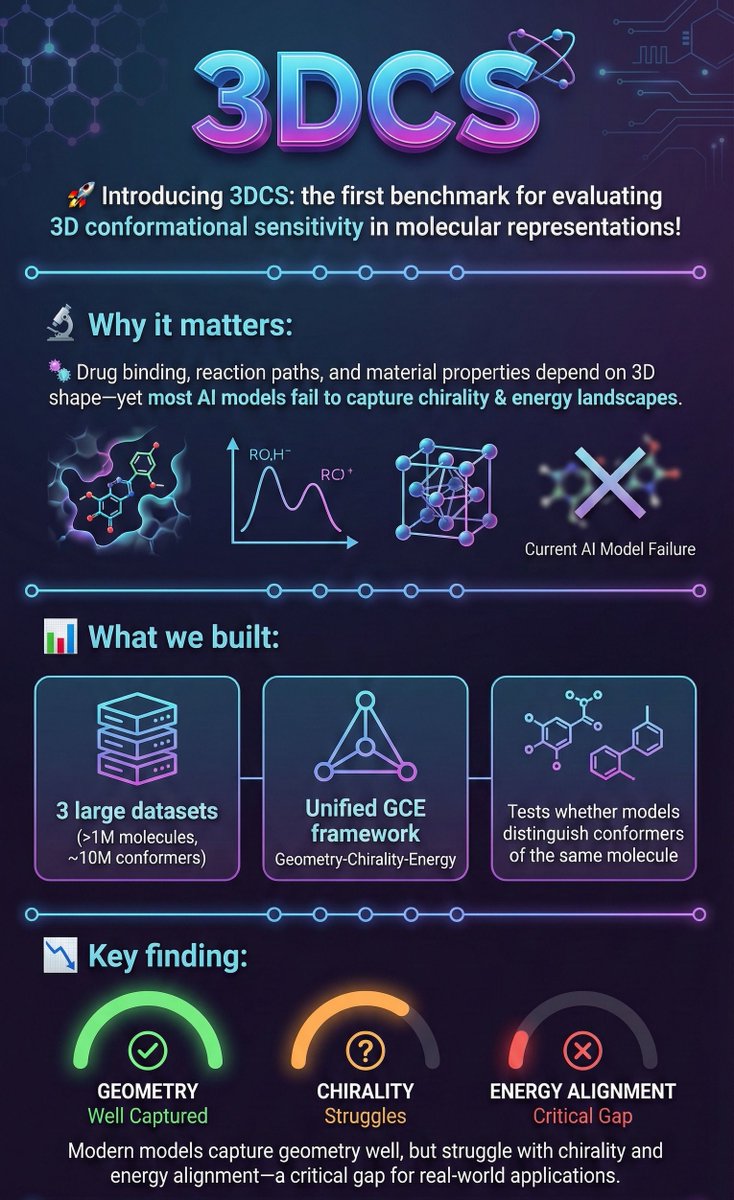
🚀 Introducing 3DCS: the first benchmark for evaluating 3D conformational sensitivity in molecular representations! Accepted by ICLR2026🥳
🔬 Why it matters:
Drug binding, reaction paths, and material properties depend on 3D shape—yet most AI models fail to capture chirality & energy landscapes.
📊 What we built:
3 large datasets (>1M molecules, ~10M conformers)
Unified GCE framework (Geometry-Chirality-Energy)
Tests whether models distinguish conformers of the same molecule
📉 Key finding:
Modern models capture geometry well, but struggle with chirality and energy alignment—a critical gap for real-world applications.
🔗 We will release code and data soon. Let’s build better molecular AI together!
openreview.net/forum?id=JAb0…
#3DMolBench #AI4Science #DrugDiscovery #MachineLearning #ChemistryAI
68