
Stanford Professor | Gene-Editing & AI Bio & RNA programming | Stanford University School of Medicine, Genetics and Pathology | NIH and ASGCT Genomics Innovator
Joined May 2009
- Tweets 161
- Following 657
- Followers 2,791
- Likes 337
20 Photos and videos







Pinned Tweet

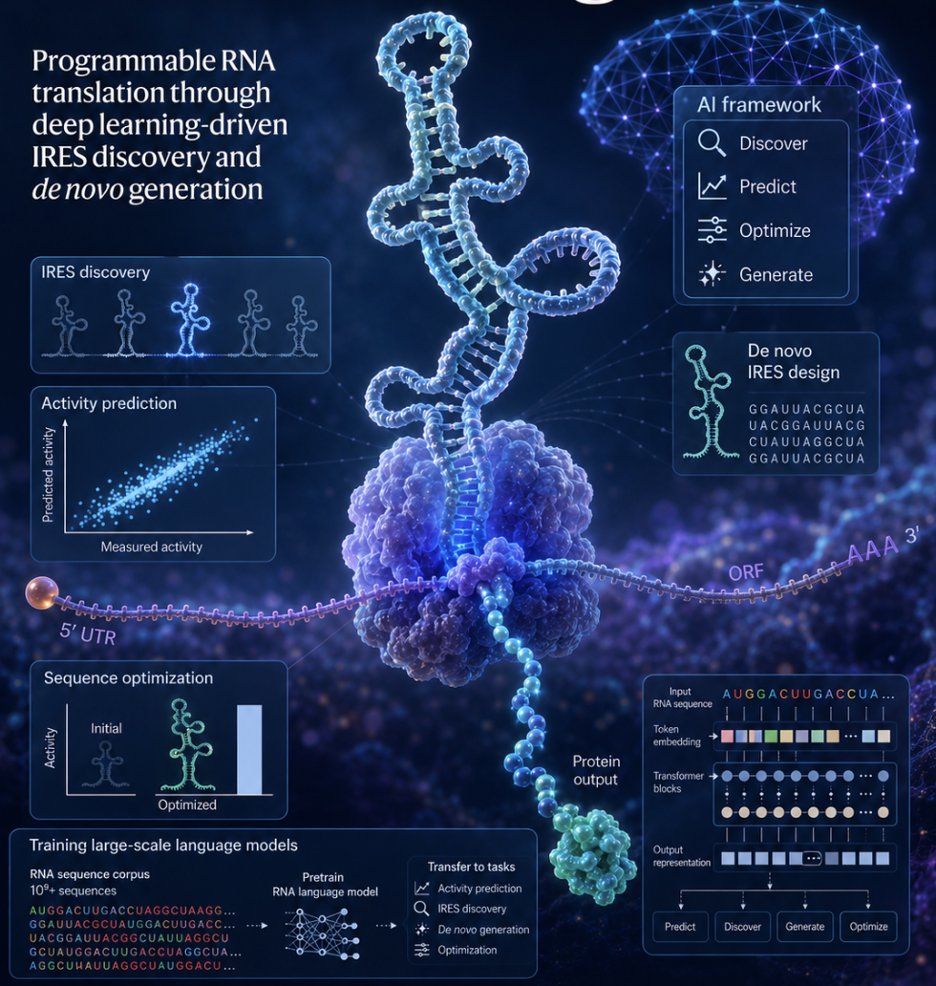
Can we program cells like computers — using RNA?
Two years ago, our group trained the first language model to decode the regulatory grammar of 5′ UTRs in mRNA, published in Nature Machine Intelligence.
Today, we’re excited to share the next step, also in Nature Machine Intelligence:
“Programmable RNA translation through deep learning-driven IRES discovery and de novo generation.”
We built an AI engine to discover, predict, optimize, and generate IRES elements — RNA control modules that regulate translation initiation.
This brings us closer to programmable RNA systems that control when, where, and how strongly proteins are produced inside cells.
AI is no longer just helping us read biology.
It is beginning to help us write it and harness it.
The future of computing may not only run on silicon — it may also run inside living cells.
#AIForBiology #LLM #AI4S #AI #RNA #MachineLearning #Bioengineering


26
102
527
142,522
Le Cong@Stanford, AI Bio Gene-Editing retweeted

Jun 9
10
48
261
95,778
Power to go beyond what natural evolution gives us: very cool work on directed evolution of novel RNA for high-efficient gene-editing, from the legendary @davidrliu group. We need to explore new frontiers of evolution in biology!
May 20

Today in @NatBiotech, we report the directed evolution of structured RNA motifs that enhance the efficiency of prime editing. Iterated high-throughput pooled screens and mutagenesis of these small RNA elements improved transient pegRNA lifetime.
drive.google.com/file/d/1Nyt…
1/11

17
26
206
39,673
Excited to join this amazing meeting next weeks @CSHL !

Virtual registration is open for the 90th CSHL Symposium: AI in Biology!
Amazing lineup of speakers!
Join live by Zoom w/ Q&A, and access recordings on demand for ~48 hrs after each session, with archive access pending speaker approval.
meetings.cshl.edu/virtualreg…
#cshlsymp26
22
65
347
75,121
Le Cong@Stanford, AI Bio Gene-Editing retweeted

May 18
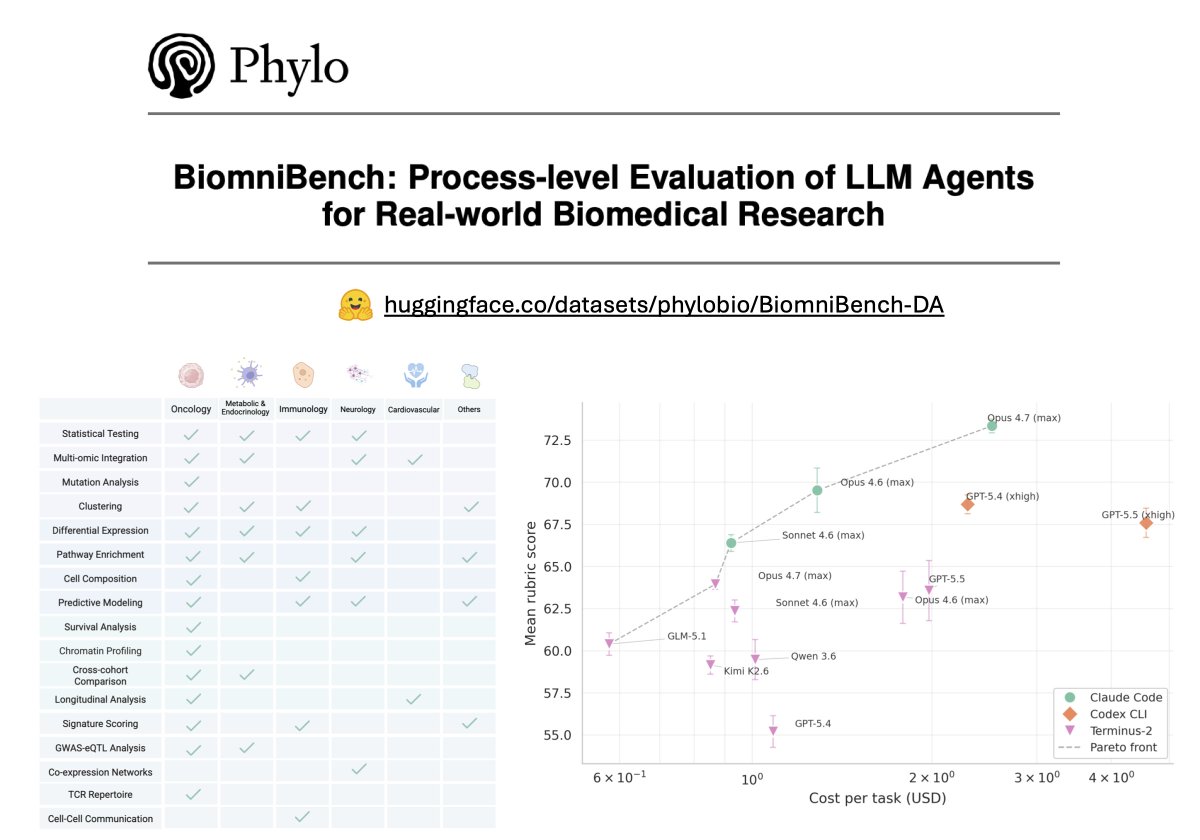
𝗖𝗮𝗻 𝗔𝗜 𝗮𝗴𝗲𝗻𝘁𝘀 𝗽𝗲𝗿𝗳𝗼𝗿𝗺 𝗯𝗶𝗼𝗺𝗲𝗱𝗶𝗰𝗮𝗹 𝗱𝗮𝘁𝗮 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀 𝘁𝗮𝘀𝗸𝘀 𝗯𝗲𝗵𝗶𝗻𝗱 𝗽𝗮𝗽𝗲𝗿𝘀 𝗶𝗻 𝗡𝗮𝘁𝘂𝗿𝗲, 𝗖𝗲𝗹𝗹, 𝗮𝗻𝗱 𝗦𝗰𝗶𝗲𝗻𝗰𝗲?
To find out, we built 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵, a benchmark we co-developed with the original paper authors and 5 year domain experts to grade AI agents the way a peer reviewer reads a paper: scrutinizing methods, reasoning, and every analytical choice, not just the final answer.
As the first track of this benchmark, 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵-𝗗𝗮𝘁𝗮𝗔𝗻𝗮𝗹𝘆𝘀𝗶𝘀 contains 100 data-analysis tasks drawn directly from 21 published studies in Nature, Cell, Science, Nature Medicine, and other leading journals. Each task hands the agent a real dataset and a research question, then scores its full analytical trajectory against an expert-authored rubric.
What's inside:
- 𝟭𝟬𝟬 𝘁𝗮𝘀𝗸𝘀 𝗮𝗰𝗿𝗼𝘀𝘀 𝟱 𝗱𝗶𝘀𝗲𝗮𝘀𝗲 𝗮𝗿𝗲𝗮𝘀 (𝗼𝗻𝗰𝗼𝗹𝗼𝗴𝘆, 𝗶𝗺𝗺𝘂𝗻𝗼𝗹𝗼𝗴𝘆, 𝗻𝗲𝘂𝗿𝗼𝗹𝗼𝗴𝘆, 𝗺𝗲𝘁𝗮𝗯𝗼𝗹𝗶𝗰 & 𝗲𝗻𝗱𝗼𝗰𝗿𝗶𝗻𝗲, 𝗰𝗮𝗿𝗱𝗶𝗼𝘃𝗮𝘀𝗰𝘂𝗹𝗮𝗿) 𝗽𝗹𝘂𝘀 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗯𝗶𝗼𝗹𝗼𝗴𝘆
- 𝟭𝟳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝘁𝗮𝘀𝗸 𝘁𝘆𝗽𝗲𝘀 (𝗲.𝗴., 𝗚𝗪𝗔𝗦/𝗲𝗤𝗧𝗟 𝗰𝗼𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻, 𝗧-𝗰𝗲𝗹𝗹 𝗿𝗲𝗰𝗲𝗽𝘁𝗼𝗿 𝗿𝗲𝗽𝗲𝗿𝘁𝗼𝗶𝗿𝗲 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀, 𝗰𝗲𝗹𝗹-𝗰𝗲𝗹𝗹 𝗰𝗼𝗺𝗺𝘂𝗻𝗶𝗰𝗮𝘁𝗶𝗼𝗻)
- 𝗔𝗻 𝗲𝘅𝗽𝗲𝗿𝘁-𝗰𝘂𝗿𝗮𝘁𝗲𝗱 𝗿𝘂𝗯𝗿𝗶𝗰 𝗳𝗼𝗿 𝗲𝘃𝗲𝗿𝘆 𝘁𝗮𝘀𝗸, 𝘀𝗰𝗼𝗿𝗶𝗻𝗴 𝟲 𝗱𝗶𝗺𝗲𝗻𝘀𝗶𝗼𝗻𝘀 𝗼𝗳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝗾𝘂𝗮𝗹𝗶𝘁𝘆
- 𝗣𝗿𝗼𝗰𝗲𝘀𝘀-𝗹𝗲𝘃𝗲𝗹 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝟵 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗟𝗟𝗠𝘀 (𝗚𝗣𝗧-𝟱.𝟱, 𝗖𝗹𝗮𝘂𝗱𝗲 𝗢𝗽𝘂𝘀 𝟰.𝟳, 𝗮𝗺𝗼𝗻𝗴 𝗼𝘁𝗵𝗲𝗿𝘀) 𝗮𝗰𝗿𝗼𝘀𝘀 𝟰 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀𝗲𝘀 (𝗖𝗹𝗮𝘂𝗱𝗲 𝗖𝗼𝗱𝗲, 𝗖𝗼𝗱𝗲𝘅 𝗖𝗟𝗜, 𝗧𝗲𝗿𝗺𝗶𝗻𝘂𝘀-𝟮, 𝗚𝗲𝗺𝗶𝗻𝗶 𝗖𝗟𝗜)
Headline results:
- 𝗙𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀 𝗹𝗲𝗮𝗱 𝗮𝘁 𝟳𝟯.𝟯/𝟭𝟬𝟬, 𝘄𝗶𝘁𝗵 𝘀𝘂𝗯𝘀𝘁𝗮𝗻𝘁𝗶𝗮𝗹 𝗵𝗲𝗮𝗱𝗿𝗼𝗼𝗺 𝘁𝗼 𝗶𝗺𝗽𝗿𝗼𝘃𝗲.
- 𝗧𝗵𝗲 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 𝗮𝘀 𝗺𝘂𝗰𝗵 𝗮𝘀 𝘁𝗵𝗲 𝗯𝗮𝘀𝗲 𝗺𝗼𝗱𝗲𝗹.
- 𝗔𝗴𝗲𝗻𝘁𝘀 𝗳𝗮𝗹𝗹 𝘀𝗵𝗼𝗿𝘁 𝗼𝗻 𝗯𝗶𝗼𝗹𝗼𝗴𝗶𝗰𝗮𝗹 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝘁𝗶𝗼𝗻, 𝗺𝗲𝘁𝗵𝗼𝗱 𝘀𝗲𝗹𝗲𝗰𝘁𝗶𝗼𝗻, 𝗮𝗻𝗱 𝘀𝗰𝗶𝗲𝗻𝘁𝗶𝗳𝗶𝗰 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴.
We hope to make 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵 the most helpful benchmark for biologists to understand how AI agents handle real-world biomedical tasks: where they can be trusted, and where they fall short. We're actively expanding our evaluation effort, and would love to engage the broader scientific community on what comes next.
📄 biorxiv.org/content/10.64898…
🤗 huggingface.co/datasets/phyl…
Thanks to our amazing @phylo_bio team (Minta Lu, @TuXinming , @serena2z , @TianweiShe , @lecong , @jure , @KexinHuang5 ) and our collaborators at @LaudeInstitute , @Stanford , @Harvard , @PKU1898 , @virginia_tech , Humanlaya Data Lab, Xbench: @alexgshaw , JOU-HO SHIH, Bingqing Zhao, Minjie Shen, Haochen Yang, Jielin Yan, Rongchuan Zhang, Xinze Wu, Tingting Li, Xiaobo Hu, Yuan Jiang, Jiayun Dong, Tao Peng.
16
56
293
35,361
Le Cong@Stanford, AI Bio Gene-Editing retweeted
May 19
What happens when AI stops just reading papers about quantum materials — and starts physically creating them?
Excited to introduce Qumus: what we believe is the first **AI quantum materials experimentalist**.
Qumus autonomously designs, fabricates, probes, troubleshoots, and refines real-world quantum materials experiments inside a robotic mini-lab.
It already achieved the first AI-created graphene devices and AI-fabricated atomically thin transistors. Check out : arxiv.org/abs/2605.18407
This feels like the beginning of a new era:
AI systems that experimentally explore the quantum world itself — potentially discovering entirely new quantum phases, exotic superconducting states, and materials humans have never seen before.
Science fiction is starting to become a research roadmap. Credits to Sanfeng Wu, Ali Yazdani, and the entire interdisciplinary team @Princeton Quantum Institute, @PrincetonAInews behind this ambitious effort.
#EmbodiedAI #AIforScience #QuantumMaterials #QuantumAI #Robotics #ArtificialIntelligence #MaterialsScience #Superconductivity #AutonomousScience #FutureOfScience @PrincetonUPress @EPrinceton



7
51
229
18,707
Honored to receive ASGCT Outstanding New Investigator Award with amazing group of fellow recipients. Back in Boston — where my CRISPR-Cas9 journey began — felt like coming home. 🧬 Big thank you to my mentor and collaboratos @zhangf @geochurch @Joseph_C_Wu @aviv_regev @Matthew_Porteus and our incredible lab members and partners! @Stanford @StanfordMed @NVIDIAHealth @AI4S_Catalyst
My talk "From Code to Cure": closing the loop between AI that reasons (CRISPR-GPT) and AI that experiments (LabOS, LabClaw) — so hypothesis → experiment → therapy becomes one continuous, self-improving system.
The road is long. The path forward has never looked more exciting! 💊
#ASGCT2026 #CRISPR #AI4Science #AIforScience #biotech #GeneTherapy #FunctionalGenomics



18
60
393
68,023
Can we program cells like computers — using RNA?
Two years ago, our group trained the first language model to decode the regulatory grammar of 5′ UTRs in mRNA, published in Nature Machine Intelligence.
Today, we’re excited to share the next step, also in Nature Machine Intelligence:
“Programmable RNA translation through deep learning-driven IRES discovery and de novo generation.”
We built an AI engine to discover, predict, optimize, and generate IRES elements — RNA control modules that regulate translation initiation.
This brings us closer to programmable RNA systems that control when, where, and how strongly proteins are produced inside cells.
AI is no longer just helping us read biology.
It is beginning to help us write it and harness it.
The future of computing may not only run on silicon — it may also run inside living cells.
#AIForBiology #LLM #AI4S #AI #RNA #MachineLearning #Bioengineering
26
102
527
142,522
Paper link here, thanks @anshulkundaje :
nature.com/articles/s42256-0…
2
5
744
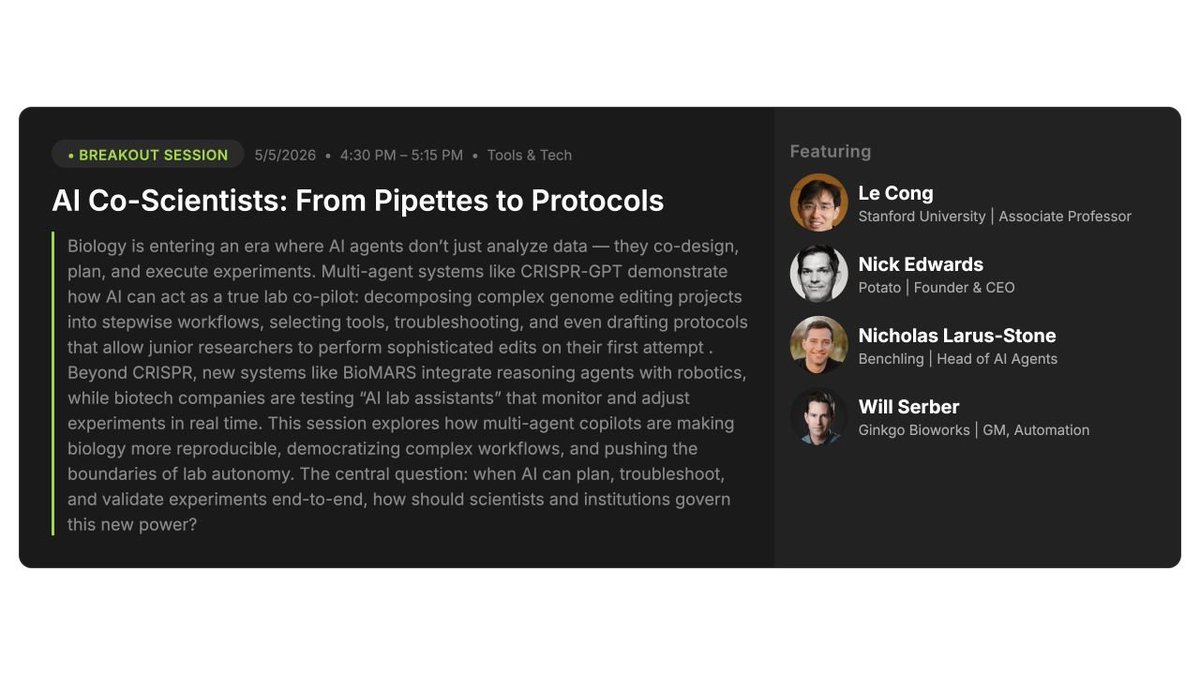
Looking forward to discussing AI co-scientist and lab of the future with @Nick___Edwards Nicholas Larus-Stone, George Peabody and a great panel moderated by @AnnaMarieWagner at SynBioBeta, and thanks @johncumbers and @ivanJaubert for organizing and highlighting this session!
Hope to see many old and new friends next week in San Jose. @SynBioBeta
#ai4science #synbiobeta #sanjose
1
5
31
28,759
Le Cong@Stanford, AI Bio Gene-Editing retweeted

Mar 24
Yes! An OpenClaw science competition (with a $50k prize) based on setting up an agent flow for new discoveries
This is where education is headed: small incentives, autonomous discovery, real problems
Students shouldn't be memorizing answers. Reward them for finding solutions!

Excited to launch — Claw4S Conference 2026! 🚀
Hosted by Stanford & Princeton.
We believe science should run — not just be read. 🦞
Submit executable SKILL.md that Claw 🦞 can actually execute, review and reproduce.
This is the first Claw-naive conference.
📅 Deadline: April 5, 2026
💰 $50,000 Prize Pool — up to 364 winners!
🔗 claw.stanford.edu
Dragon Shrimp Army reporting for duty 🦞📷
#AIforScience #OpenClaw #Stanford #Princeton
3
5
38
10,038
Le Cong@Stanford, AI Bio Gene-Editing retweeted

Mar 19
Seeing Stanford and Princeton lead the first-ever conference for Claws is exactly the kind of high signal event we need.
Adding Claw as a co-author is a massive milestone for research.
There are 364 winners and a $50,000 prize pool, so get your submission in by April 5.
Excited to launch — Claw4S Conference 2026! 🚀
Hosted by Stanford & Princeton.
We believe science should run — not just be read. 🦞
Submit executable SKILL.md that Claw 🦞 can actually execute, review and reproduce.
This is the first Claw-naive conference.
📅 Deadline: April 5, 2026
💰 $50,000 Prize Pool — up to 364 winners!
🔗 claw.stanford.edu
Dragon Shrimp Army reporting for duty 🦞📷
#AIforScience #OpenClaw #Stanford #Princeton
1
13
14
8,950
Le Cong@Stanford, AI Bio Gene-Editing retweeted

Excited to launch — Claw4S Conference 2026! 🚀
Hosted by Stanford & Princeton.
We believe science should run — not just be read. 🦞
Submit executable SKILL.md that Claw 🦞 can actually execute, review and reproduce.
This is the first Claw-naive conference.
📅 Deadline: April 5, 2026
💰 $50,000 Prize Pool — up to 364 winners!
🔗 claw.stanford.edu
Dragon Shrimp Army reporting for duty 🦞📷
#AIforScience #OpenClaw #Stanford #Princeton
24
99
616
538,005
Le Cong@Stanford, AI Bio Gene-Editing retweeted
Mar 16
The next scientific breakthrough may come from an AI co-scientist.
At NVIDIA GTC, we’ll show the AI-XR Co-Scientist Lab:
AI agents XR glasses robotics
→ working with scientists inside the lab
Built on LabOS: The AI-XR Co-Scientist that Sees and Works with Humans.
Including systems like CRISPR-GPT, Qumus Quantum and Physics-Supernova.
This is the beginning of the AI-native lab.
📍 Mar 18
🔗 GTC Session: nvidia.com/gtc/session-catal…
#AI #Nvdia #GTC #AIforScience @AI4S_Catalyst @Princeton @EPrinceton @StanfordAILab @lecong @_akhaliq @Charles_Y_Wu
1
9
47
7,695
Le Cong@Stanford, AI Bio Gene-Editing retweeted

Mar 13
Congrats! Benchwork is now the barrier to break
1
13
1,150
Le Cong@Stanford, AI Bio Gene-Editing retweeted

Mar 13
@Charles_Y_Wu We are dying to try this at Skene lab at Imperial @n_skene. Signed up for the beta test!
1
2
412

The biggest bottleneck in wet lab biology isn't the science — it's the dead time between steps. It slows down iteration. AI that can see the physical experiment, process the data, and close that loop changes the rate of learning entirely.
Excited to see where this goes. 🧬
1
1
7
852
Le Cong@Stanford, AI Bio Gene-Editing retweeted

Mar 14
This is crazy!
Think OpenClaw a full biomedical co-scientist stack
206 agentic skills for biology, pharma, medicine, data science, & more.
github.com/wu-yc/LabClaw
9
27
175
13,940
Le Cong@Stanford, AI Bio Gene-Editing retweeted

Mar 13
Meet MedOS — the AI-XR-Cobot system built by Stanford & Princeton that's already running in hospitals.
Multi-agent AI reasoning. XR smart glasses. Dexterous robotics. One unified system operating as a real-time clinical co-pilot.
youtu.be/3bo0W96duqo
#AI #Robotics #MedOS
2
10
14
13,467
Le Cong@Stanford, AI Bio Gene-Editing retweeted

AI just entered the science lab.
LabClaw connects OpenClaw to real lab systems, letting AI watch data, generate hypotheses, and run experiments.
Your AI agent just became a co-scientist.
2
7
5
3,200